揭秘PostgreSQL:为何它如此受欢迎?
发表时间: 2019-11-22 10:18
分享主要围绕以下三个方面:

如果99%的开源数据库都是商业公司
那么PG是那1%
首先,PG是开源数据库,但还要给它再加一个前缀“PG是社区开源数据库”。如下图所示,PG的SPONSOR中,占比最高的是最终用户,也就是说使用PG的用户贡献的代码量是最多的。之后是服务提供商、数据库厂商和云厂商。
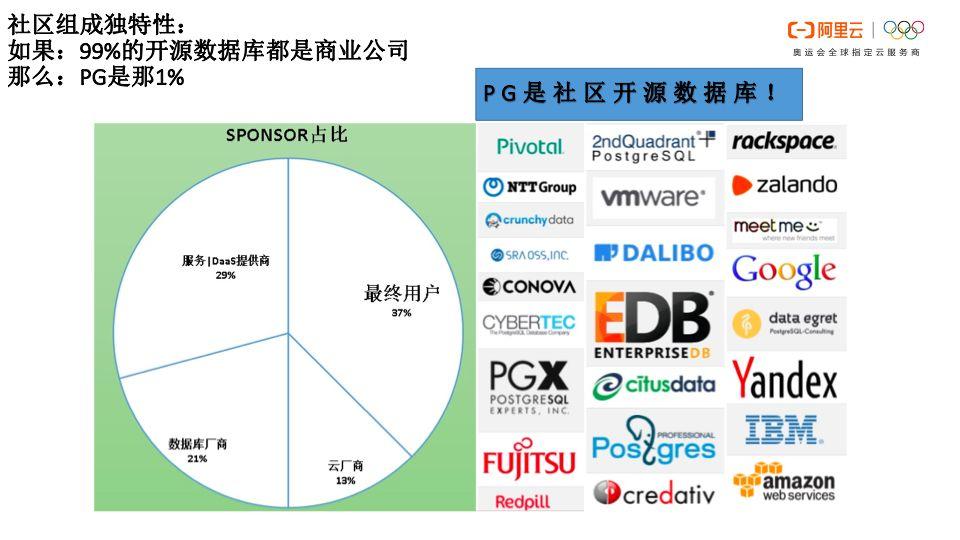
因此,大家可以发现PG并没有主体所有者,它不是被某一家公司控制的开源数据库,因此可以称之为“社区开源数据库”。不像是被公司控制的开源数据库的目的在于营收,PG开源的目的是传播,就像是人类繁衍一样。
那么,为何很多数据库厂商的数据库是基于PG的,并且也向PG贡献代码呢?他们不是应该敝帚自珍吗?
首先要从数据库格局说起,如今的数据库市场基本掌握在几家商业数据库巨头手中,如果想要向市场推出一款新数据库需要找用户背书。
如果数据库厂商希望推出一款很快能够被用户接受的数据库,最好基于开源生态,因此可以向PG贡献代码,使得全世界的PG用户为你背书。
其次,之前数据库厂商和服务提供商只需要安装、优化、排错和解决用户问题即可。在闭源时代这样还可以,但是在开源时代,这些就远远不够了。
如今,只有能够掌握数据库的内核代码,在市场里面才能体现出优势。而证明能力的最简单途径就是贡献代码,成为SPONSOR。
再次,PG的最终用户之所以贡献代码,是因为他们将PG用在核心业务中,也希望PG开源数据库能够更好地发展,只有PG社区长久,才可以享受免费的、可持续发展的、开源的、稳定的、不被任何商业公司、任何国家控制的企业级的数据库。所以:
1、PG用的人越多,越多人背书,使用越靠谱。
2、抛砖引玉,企业投入2个研发持续贡献(一年可能一两百万),实际上整个PG社区有全球成千上万的开发者在贡献,对最终用户来说,简直赚到了。
使用商业数据库,除了LICENSE等成本,依旧需要投管理、研发、外包资源,一年数千万。公司越大,越有动力去贡献社区(事实证明如此)。从趋势来看,给PG贡献代码的大客户会越来越多。
所以社区会像滚雪球一样越来越大,算清这笔账,企业是非常愿意给PG社区贡献代码的。
最后,云厂商之所以向PG贡献代码是因为他们输出自研数据库,同样也会涉及到背书和生态构建的问题。而基于开源构建自研数据库,可以避免重复造轮子。
PG是有组织有纪律的开源数据库
PG是有组织、有纪律的开源数据库,有专门负责筹款、基金管理的准则,也有负责生成行为准则的委员会和负责赞助商管理的委员会。正因为有组织、有纪律,PG才能经久不衰。
PG是活雷锋
开源许可证独特性-活雷锋
PG还是一个“活雷锋”,大家可以随意使用、拷贝、修改和分发。PG的许可证非常友好,因此可以将PG作为解决方案或者软件资产的一部分进行打包输出。

PG是全方位可扩展数据库
技术架构独特性
PG具有非常独特的技术架构,允许拓展新的数据类型,PG 12甚至开放了存储接口的后台,可以增加行列混合存储等。此外,PG还可以扩展出很多衍生的数据库或者插件。
因此,PG是一个可以真正做到全方位扩展的数据库,用户可以直接使用,当用户觉得无法满足业务需求时也可以扩展,而扩展未必需要自己实现,可以在社区里面寻找相应插件。
PG是基石
商业趋势
目前,提高正版化、安全、合规等意识已经成为一个全球趋势。而PG因为它的开源协议,成为了一个很好的选择。并且PG的稳定性和可靠性也非常优秀,能够很好地兼容Oracle数据库,因此将会成为企业“去O”的首选。
PG是趋势
技术趋势
如今,业务对数据库的要求越来越高,不仅需要存储关系型数据,也可能需要存储多模数据。基于PG的可扩展性,可以扩展出各种功能,既能够满足SQL的通用性,又能够满足NoSQL的扩展性,同时还具有多模开发的便捷性。
PG是学术界与工业界的先进代表
PostgreSQL荣誉
PG获得了DB-engines 2017和2018年的年度数据库,并且在2019年获得OSCON终身成就奖,成为了Linux后第二个获得该奖的开源产品。
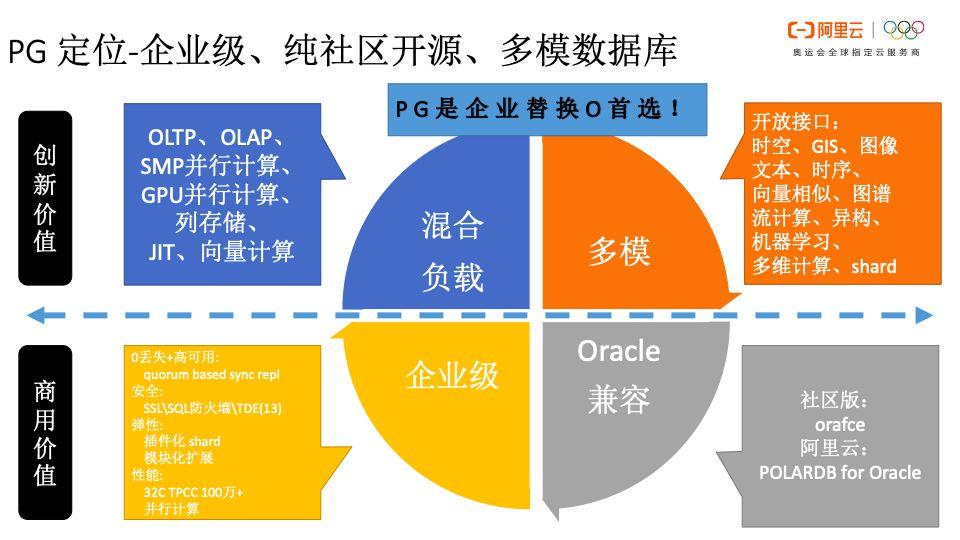
PG是企业替换Oracle首选
PG定位-企业级、纯社区开源、多模数据库
对于数据库系统而言,需要关注其商业价值和创新价值。而且PG能够兼容大多数Oracle使用场景。另外,阿里云提供了POLARDB兼容Oracle语法版本,具有更高兼容度,PG将会成为代替Oracle的首选。
大家可以回忆一下PG数据库的发布节奏,从最早1973年Michael Stonebraker发表的论文,到1994年SQL解析系统重新启动以后开源,就有了现在看到的PG版本。之后,PG每年都会发一个大版本,每一两个月左右发一个小版本。这就相当于是股市中的蓝筹股,非常稳定。
PG是生态
PG的生态非常完善,从用户、高校、软件开发商、云厂商、服务提供商、开源社区、培训机构到硬件厂商,整个生态一应俱全。
上述这么多只是为了回答一个问题,那就是PG到底是什么?可以说,PG重新定义了开源数据库。这才是企业心目中的开源数据库。
PG 11在并行计算部分做了较大增强,还做了btree index include索引叶子附加属性,并且添加字段速度更快(无论多大的表加减字段都是毫秒级)。
并行计算增强
自动并行计算不需要改写SQL,而是根据SQL代价自动规划并行数量,并且能够覆盖几乎所有复杂查询。
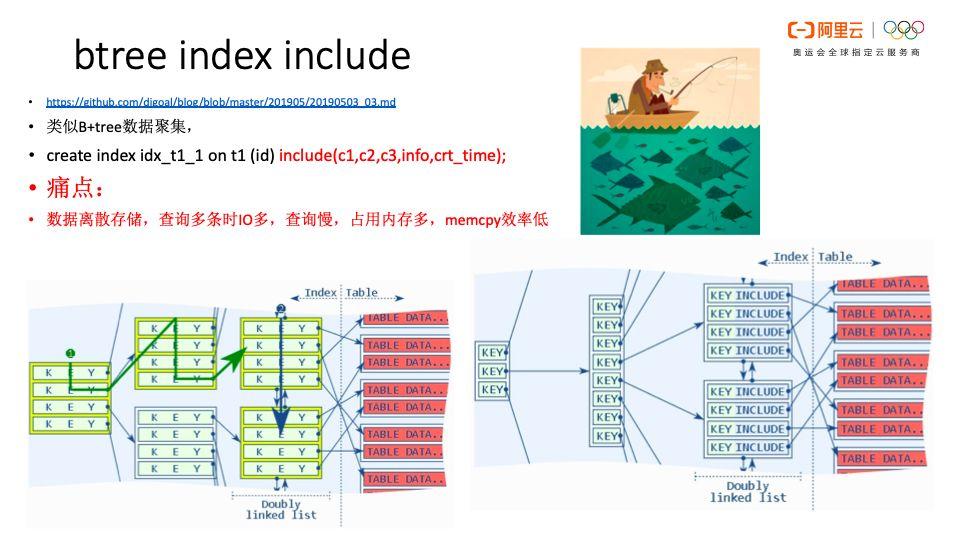
btree indexinclude
btree index include功能非常有用。很多用户非常在意数据库有没有聚集表的功能,所谓聚集表是数据存储以某个KEY的顺序去组织的,但不能以多种KEY顺序来组织。
因此,PG提供了btree index include功能可以支持任意维度的聚集存储组织形态,对于开发者非常友好。
添加字段更快
PG 11无论是否加默认值修改原数据,而且不管这个表多大,都不需要修改数据,因此对数据特别友好。
PG 12增加了几个非常重要的功能,比如AM接口使得可以在PG增加存储引擎,分区表大幅度性能提升,GiST index include索引叶子附加属性,日志采样,自定义统计信息支持MCV,Reindex concurrently不堵塞读写操作,SQL/JSON path language,Generated columns以及case-insensitive and accent-insensitive grouping and ordering。
最后将PG和Oracle做一个全方位对比。就像是双11购买空调一样,我们需要精心对比一下。首先,从口碑和版本的发布节奏来看, PG一定稳赢。
以下几张图中标黄的部分是具有的优势。其中,价格很明显不用比,因为PG“不要钱”。
在核心技术方面,Oracle具有Rac,比原生PG强。但是PG的生态非常强大,用整个生态去PK Oracle,输赢就不好说了。
在优化器方面,Oracle确实做得特别好。对于内存表而言,PG表空间对应到文件系统,一个文件一个表空间。而Oracle通过datafile加进去,可以理解为在多个block devs上面组合出一个大表空间,在这个大表空间里面可以横向去扩展对象。而PG如果想要整出一个特别大的表空间则需要借助存储的能力或文件系统的能力。
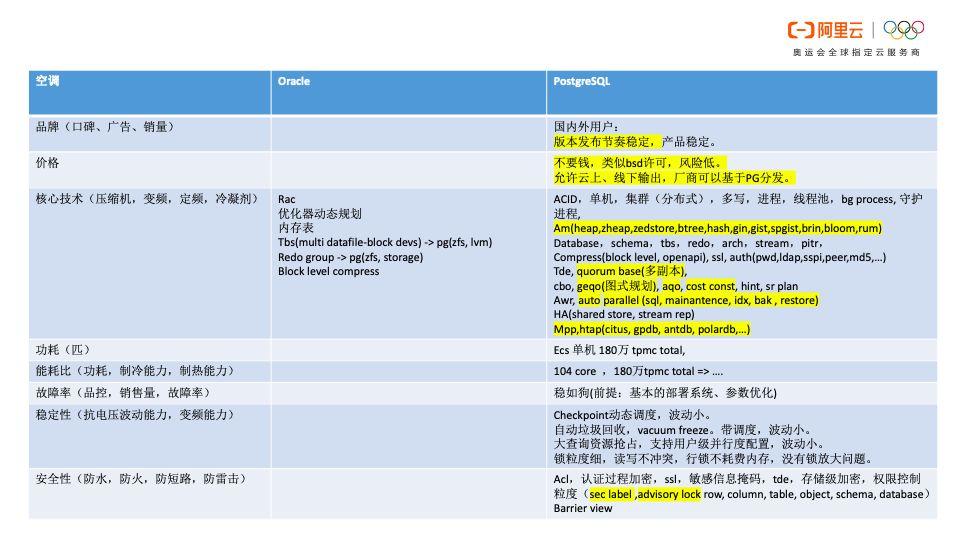
Oracle强调它有维度group,也就是一个维度可以写到多个文件里面形成多个副本。这是因为很早以前Oracle的存储不是特别可靠,需要通过多个副本方式来保证数据可靠。
而今天文件系统非常强大,存储本身的可靠性也已经很强大了,所以存储或者文件系统可以保证可靠性,因此PG没有做这部分的工作,可以借助生态实现(例如文件系统块设备镜像、存储镜像等)。Oracle支持块级压缩,而PG 13版本中也应该会支持块级压缩。
PG的存储引擎是可插拔的,可以支持很多组件、引擎和索引,可拓展性比Oracle好很多。PG具有quorumbase能力,而Oracle不具备。此外,PG还具有较好的横向扩展能力,例如MPP能力。

另外,PG支持的数据类型比Oracle多,支持数组、json、kml、kv、GIS、多维向量、图像等。对于外部访问接口而言,Oracle有getv,PG有逻辑订阅和资源隔离可以支持访问外部源。
在增值功能方面,Oracle的闪回做得确实非常好。但PG增值功能可以做的更好,比如GPU加速,语言扩展性。
PG维护成本相对低很多,因为其诊断工具比较多,并且问题上报给社区,通常在24小时内就会收到回复。PG的产品限制也很少,可以无限地创建db、user、schema和table。
至于“售后服务”,Oracle的第三方的支持公司遇到无法解决掉问题只能交给原厂,但是使用PG,不仅支持公司能够帮助修复,社区也可以。
PG的代码可读性堪称教科书级别,即使不懂C语言也没有关系,代码注释非常清晰,模块归类也很清晰,甚至技术引用哪个论文都会直接告诉你。PG的细节处理比较好,例如Psql是dba用得最多的黑屏操作,支持补齐功能、命令帮助功能、简单编程功能等,而Oracle往往没有补齐的功能。
而且,PG是纯C代码的,效率是最高的,没有偷工减料。在产能方面,PG的发行频率更是Oracle没法比的,每年一个大版本,小版本每个月左右发布一个。
对于公司的资本组成或者社区的sponsor组成、企业运作而言,PG来自于全球社区背后有很多的商业巨头的支撑,并且在社区化运作方面,PG也更具有优势。
德哥PPT获取方式
关注微信公众号“阿里数据库技术”回复“PG”即可获取德哥演讲PPT资料啦!
作者:Roin123
本文为云栖社区内容,允许提供不得转载。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号