音视频架构的构建与超视频时代的演变
发表时间: 2022-06-23 15:25
作者 | 王一鹏
如果说,在以音视频为载体传输信息、进行交互的技术领域,始终飘着一朵“乌云”,那么这朵“乌云”的名字,很可能既不是低延时,也不是高可靠,而是不断变化的应用场景。
从 Web 2.0 到移动端基础设施全面建成,我们完成了文字信息的全面数字化;而从 2016 “直播元年”至今,图像、语音信息的全面数字化则仍在推进中。最简单的例证是,对于早期的流媒体直播而言,1080P 是完全可接受的高清直播;但对于今天的流媒体而言,在冬奥会这样的直播场景下,8k 可能是个刚性需求,相比于 1080P,像素数量增长 16 倍。
而且,今天的流媒体业务,对视频流的要求不仅停留在分辨率上,也表现在帧率上。以阿里文娱 2019 年底推出的“帧享”解决方案为例,它将画面帧率推至 120 FPS,同时对动态渲染的要求也很高。过往人们总说,帧率超过 24 FPS,人眼就无法识别,因此高帧率没有实际意义。但高帧率是否能提升观看效果,与每帧信息量密切相关,近几年游戏开发技术的进步,以及以李安为代表的一众电影导演,已经彻底打破这一误解。
对于 RTC 来说,问题情境和对应的软件架构又截然不同。早期大家看赛事直播,20s 的延迟完全可以接受。但在 RTC 场景下,人与人的即时互动让使用者对延迟的忍耐度急剧降低,从 WebRTC 方案到自研传输协议,相关尝试从未停止。
当我们以为,所谓的场景问题,终于可以被抽象为有限的几个技术问题,并将延迟压入 100ms 以内,可靠性提升至 99.99%,新的场景又出现了。全景直播、VR 全球直播,云游戏……其中又以云游戏最为典型——云游戏简直是过去那些音视频场景性能要求的集大成者:有的游戏要求延时低至 50ms 以内;有的要求 FPS 60 以上;分辨率不消说,肯定是越高越好。同时云游戏场景夹杂着大量的动态渲染任务,无一不在消耗着服务器资源,增大着全链路的传输延时。
那么,如果从云游戏场景的性能要求出发,进而扩展至整个超视频时代的架构体系,该以怎样的思路来进行架构设计呢?只关注软件,可能不太行的通;硬件成为必须纳入考虑的一环。
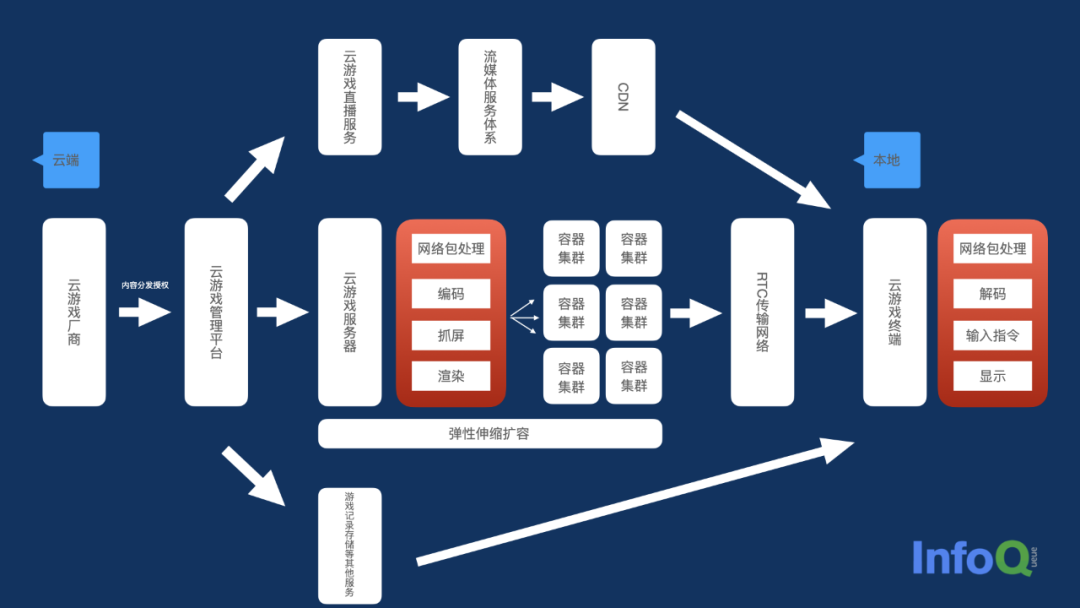
要解释这个问题,必须重新回顾下常规的云游戏技术架构。下图主要参考自英特尔音视频白皮书、华为云游戏白皮书,并做了相应调整,基本与当前环境下,大部分云游戏架构的设计相符。
InfoQ 版权所有
在这一架构内,至云游戏终端前,所有服务都在云端、公共网络上完成,保证用户无需下载游戏或是为了玩游戏购置高性能终端。游戏玩家的终端,主要负责对网络包进行处理、对渲染后的游戏画面进行解码、显示,并相应地输入指令,回传给服务器。
而在服务器端,链路相对复杂。云游戏管理平台是服务的起点,上下两条链路,都是云游戏的周边技术服务,与业务场景强相关,包括云游戏的直播录制、游戏日志 / 记录存储等。前者对时延忍耐度较高,可以走正常的流媒体服务体系,使用 CDN 分发音视频内容;后者属于正常的游戏服务器设计范畴,正常提供服务即可。
关键在于中间一层,也就是云游戏容器集群。这一部分要实现的设计基础目标是保障 1s 至少完成 24 张游戏画面(24 帧)的计算、动态渲染和编码传输,部分高要求场景需要帧率达到 60 FPS,同时保证时延尽可能得低。
这部分的技术挑战非常大,以至于若仅以软件为中心思考,很难做出真正突破。从相关指标的演进历史来看,仅仅在 4 年前,移动端游戏本地渲染的基础目标还是 30 FPS,如今虽然能实现 60 FPS 甚至更高,但讨论的场景也从本地渲染切换成了云端渲染。在软件上,除非出现学术层面的突破,否则很难保证性能始终保持这样跨度的飞跃。
此外,渲染本来就是严重倚仗硬件的工作,渲染速度和质量的提升,主要依赖于 GPU 工艺、性能以及配套软件的提升。

3D 游戏渲染画面
而更为复杂的游戏性能以及整体时延的控制,则对整个处理、传输链路提出了要求。仅以时延为例,它要求在编码、计算、渲染、传输等任何一个环节的处理时间都控制在较低范围内。同样是在 3 - 4 年前,有业界专家分享,他们对 RPG 类云游戏的传输时延容忍度是 1000 ms,但事实证明,玩家并不能忍受长达 1s 的输入延迟。反观今日,无论是通过公有云 + GA 方案,还是通过自建实时传输网络方案,即便是传输普通音视频流的 RTC 服务也只能保证延时 100ms 以内,而云游戏的计算量和带宽需求数倍于普通音视频服务。
以上仅仅是冰山一角。对于架构设计而言,除了高性能、高可用、可扩展性三类设计目标外,成本也是必须要考虑的平衡点——需要 1000 台服务器的架构,和需要 100 台服务器的架构,压根不是一个概念。2010 年前后,云游戏基本不存在 C 端商业化可能,虽然整体时延和性能指标可以满足当时的要求,但代价是一台服务器只能服务一个玩家,单个玩家服务成本上万。云游戏“元老” Onlive 公司的失败,在当时非常能说明问题。
而到了 2020 年,行业硬件的整体性能提升后,一台服务器可支持 20 - 50 路并发,性能提升了几十倍。
那么,如果我们将硬件变成架构设计的核心考虑要素,会是什么样的呢?大致如下图所示(为了不让图示过于复杂,我们只保留了云游戏核心服务链路,以作代表)。

InfoQ 版权所有
可以看到,仅在云服务器部分,就有大量的硬件和配套软件需要参与进来,要关注的性能点也相对复杂。而这仅仅是云游戏一个应用场景下的音视频架构,当我们将场景抽象并扩展,最终覆盖到整个超视频时代的时候,以下这张来自英特尔技术团队的架构图,可能更加符合实际。英特尔将音视频体系架构在软件和硬件层面分别进行了展示:一部分叫做 Infrastructure(基础设施层),如图一所示;另一部分则称其为 Infrastructure Readiness (基础设施就绪),指的是基础设施就绪后,建立在其上的工作负载,如图二所示。两张图的首尾有一定重合,表示其头尾相接。

图一:基础设施层
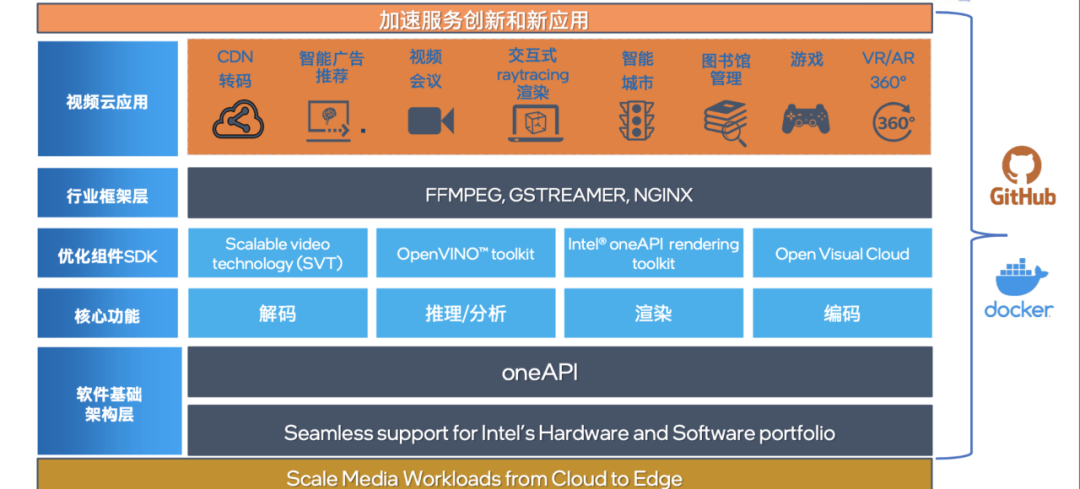
图二:基础设施就绪后的工作负载
可以看到,基础设施层主要包括硬件、配套云服务、云原生中间件以及各类开源基础软件。而在工作负载层面,是大量的软件工作,包括核心的框架、SDK 以及开源软件贡献(UpStream)。这也是为什么英特尔以硬件闻名,却维持着超过一万人的软件研发团队。
基础设施层
在基础设施层,我们的首要关注对象就是硬件,尤其是对于音视频服务来说,硬件提升对业务带来的增益相当直接。
但相比于十年前,当前的硬件产品家族的复杂度和丰富度都直线上升,其核心原因无外乎多变的场景带来了新的计算需求,靠 CPU 吃遍天下的日子已经一去不复返了。以前面展示的英特尔硬件矩阵为例,在音视频场景下,我们主要关注 CPU、GPU、IPU,受限于文章篇幅,网卡一类的其他硬件不在重点讨论范围内。
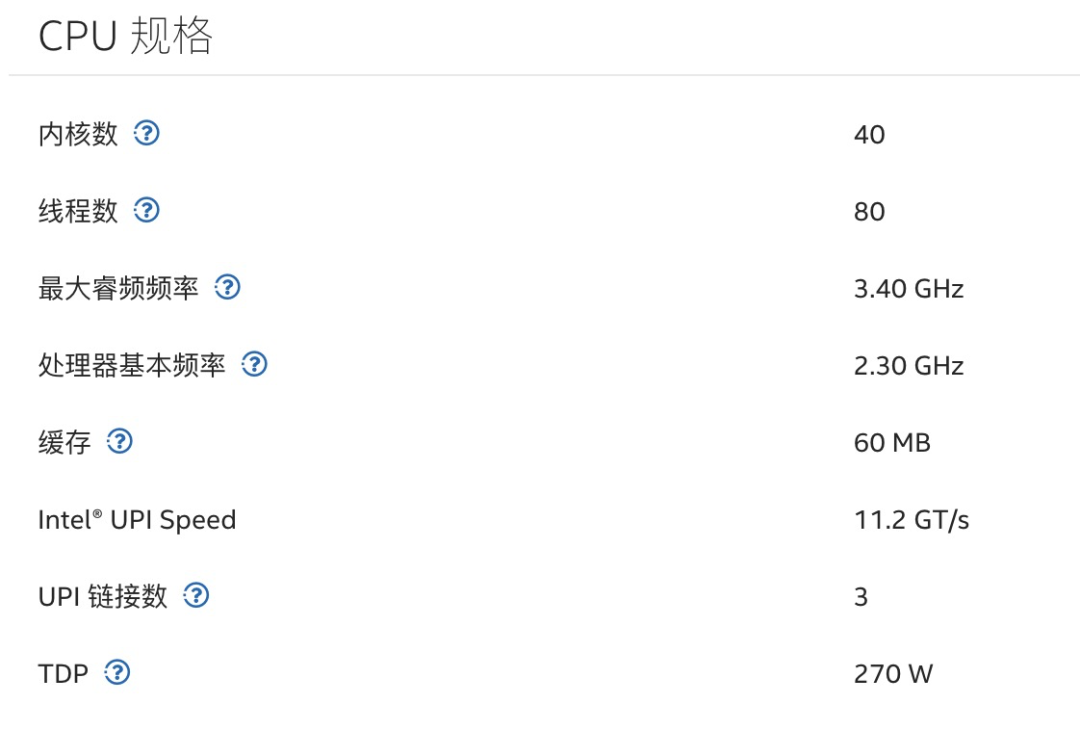
在 CPU 方面,英特尔已更新至强® 第三代可扩展处理器,相比第二代内存带宽提升 1.60 倍,内存容量提升 2.66 倍,采用 PCIe Gen 4,PCI Express 通道数量至多增加 1.33 倍。其中,英特尔® 至强® Platinum 8380 处理器可以达到 8 通道、 40 个内核,主频 2.30 GHz,英特尔支持冬奥会转播 8k 转播时,CPU 侧的主要方案即是 Platinum 8380。这里贴一张详细参数列表供你参考(https://www.intel.cn/content/www/cn/zh/products/sku/212287/intel-xeon-platinum-8380-processor-60m-cache-2-30-ghz/specifications.html):
英特尔 CPU 另外一个值得关注的特点,在于其配套软件层面,主要是 AVX-512 指令集。AVX-512 指令集发布于 2013 年,属于扩展指令集。老的指令集只支持一条指令操作一个数据,但随着场景需求的变化,单指令多数据操作成为必选项,AVX 系列逐渐成为主流。目前,AVX-512 指令集的主要使用意义在于使程序可同时执行 32 次双精度、64 次单精度浮点运算,或操作八个 64 位和十六个 32 位整数。理论上可以使浮点性能翻倍,整数计算性能增加约 33%,且目前只在 Skylake、 Ice Lake 等三代 CPU 上提供支持,因此也较为独特。
在视频编解码、 转码等流程中,因为应用程序需要执行大规模的整型和浮点计算,所以对 AVX-512 指令集的使用也相当关键。
而 GPU 方案在云游戏场景中,通常更加引人瞩目,英特尔® 服务器 GPU 是基于英特尔 Xe 架构的数据中心的第一款独立显卡处理单元。英特尔® 服务器 GPU 基于 23W 独立片上系统(SoC)设计,有 96 个独立执行单元、128 位宽流水线、8G 低功耗内存。
所谓片上系统 SoC,英文全称是 System on Chip,也就是系统级芯片,SoC 包括但不仅限于 CPU、GPU。就在今年,前 Mac 系统架构团队负责人、苹果 M1 芯片的“功臣” Jeff Wilcox 宣布离开苹果,担任英特尔院士(Intel Fellow)、设计工程事业群(Design Engineering Group)CTO,并负责客户端 SoC 架构设计,也在行业内引起了众多关注。
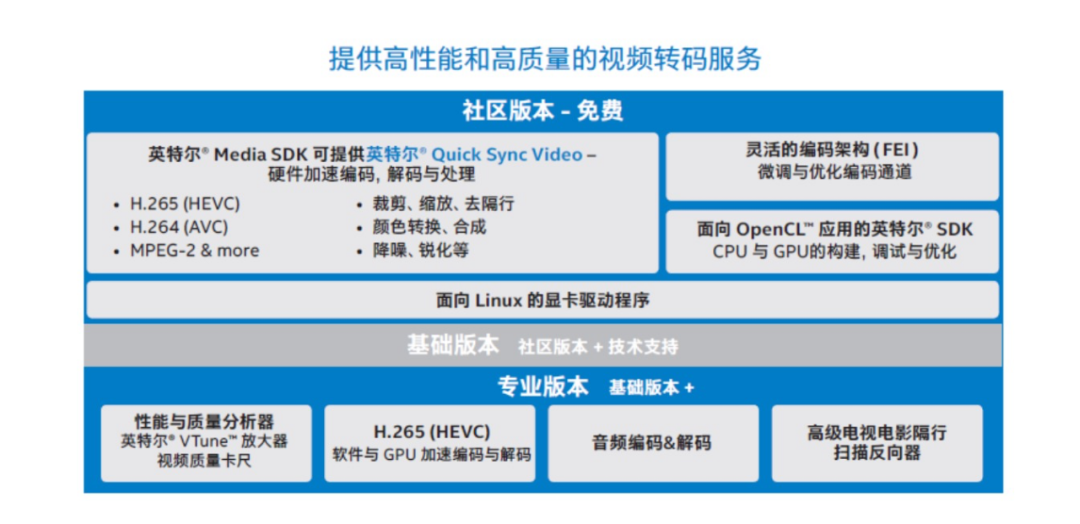
当然,只有 GPU 硬件本身是不够的,英特尔® Media SDK 几乎是搭配 GPU 的必选项。英特尔® Media SDK 提供的是高性能软件开发工具、库和基础设施,以便基于英特尔® 架构的硬件基础设施上创建、开发、调试、测试和部署企业级媒体解决方案。
其构成可参考下图:
IPU 是为了分担 CPU 工作负载而诞生的专用芯片,2021 年 6 月,英特尔数据平台事业部首席技术官 Guido Appenzeller 表示:“IPU 是一种全新的技术类别,是英特尔云战略的重要支柱之一。它扩展了我们的智能网卡功能,旨在应对当下复杂的数据中心,并提升效率。”
具体落地在音视频场景里,IPU 要负责处理编码后的音视频流的传输,从而解放 CPU 去更多关注业务逻辑。所以,CPU + GPU + IPU 的组合,不仅是在关注不同场景下的需求满足问题,实际上也在关注架构成本问题。
工作负载层
从基础设施过渡到工作负载,实际上有一张架构图,更详细的展示了相关技术栈的构成:
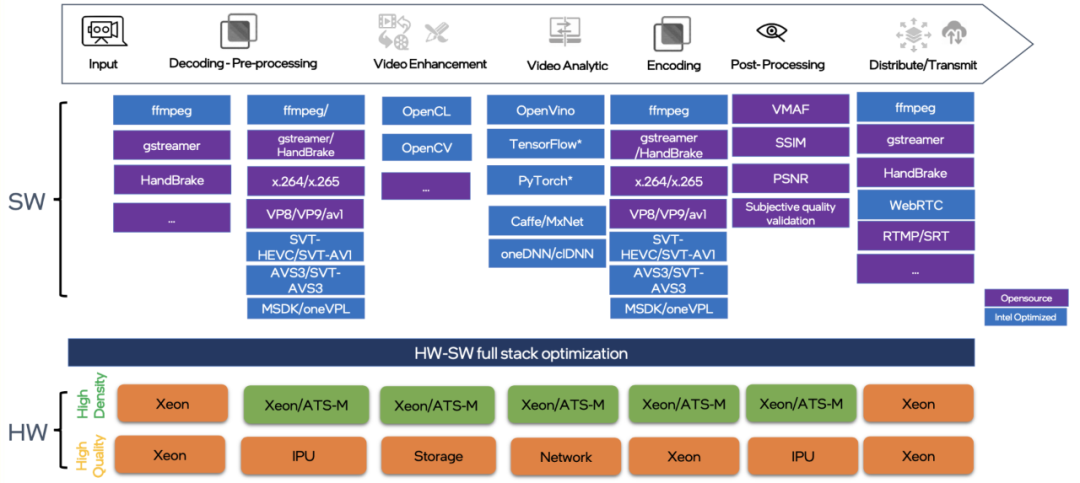
在这张架构图中,横向是从源码流输入到分发的整个流程,期间包含了编码、分析等处理动作;而纵向则展示了要服务于这条音视频处理流程,需要搭配的硬件和软件体系。
OneAPI 作为异构算力编程模型,是桥接基础设施和上层负载的关键一层,这不必多言。而到了负载层,软件则分成了蓝色和紫色两个色块。蓝色代表直接开源软件,紫色则代表经过英特尔深度优化,再回馈(Upstream)给开源社区的开源软件。
在蓝色部分,OpenVino 是个很有意思的工具套件,它围绕深度学习推理做了大量的性能优化,并且可以兼容 TensorFlow、Caffe、MXNet 和 Kaldi 等深度学习模型训练框架。当音视频体系需要加入 AI 技术栈以服务超分辨率等关键需求时,OpenVino 会起到关键作用。
紫色部分的 x.264/x.265 是一个典型。作为音视频行业最主流的编码标准,英特尔使其开源的主要贡献者,而且 AVX-512 指令集也专门围绕 x.264/x.265 做了优化和性能测试。
另一个值得关注的核心是编码器,它横跨了蓝色区域和紫色区域,既有行业通用的 ffmpeg,也有英特尔自研的 SVT,二者同样引人关注。
在流媒体时代,著名开源多媒体框架 ffmpeg 是业界在做编解码处理时,绝对的参考对象。说白了,很多编解码器就是 ffmpeg 的深度定制版本。到了 RTC 时代,出于更加严苛的及时交互需求,自研编解码器尽管难度颇高,但也在研发能力过硬的企业中形成了不小的趋势。
可归根结底,在推进以上工作时,软件始终是思考的出发点,从业者们多少有些忽略对硬件的适配。
SVT 的全称是 Scalable Video Technology ,是开源项目 Open Visual Cloud 的重要组成部分,针对英特尔多个 CPU 进行了高度优化,因此在英特尔硬件体系上,性能表现非常突出。SVT 设计最朴素的初衷,是针对现代 CPU 的多个核进行利用率方面的提升,比如依仗硬件上的多核设计并行对多个帧同时处理,或对一张图像分块进而并行处理,大大加快处理速度,避免多核 CPU 空转。
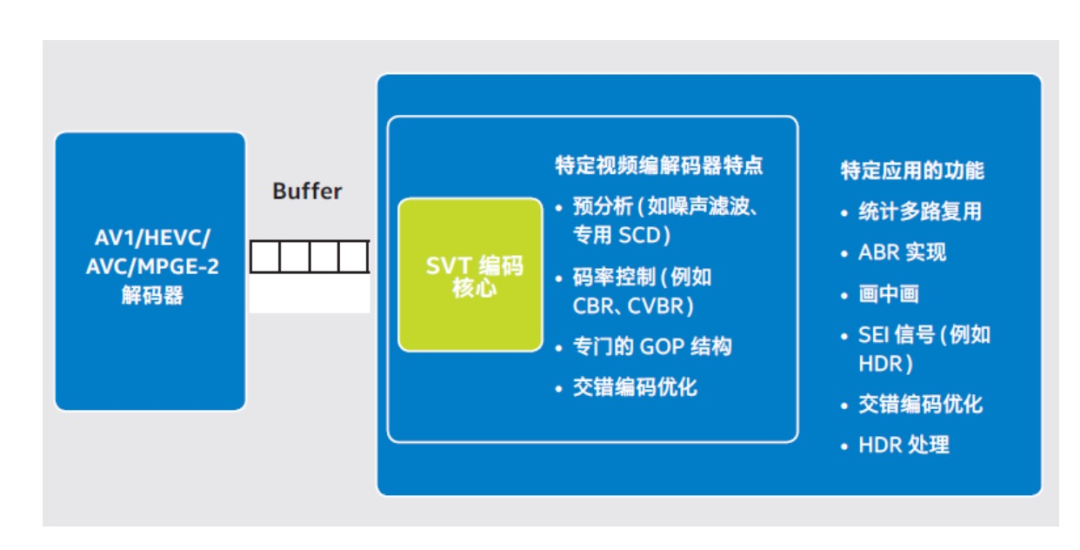
更为人所熟知的可能是后来这个叫做 SVT-AV1 的开源项目(GitHub 地址:
https://github.com/AOMediaCodec/SVT-AV1),AV1 开源视频编码,由英特尔、谷歌、亚马逊、思科、苹果、微软等共同研发,目的是提供相比 H.265 更高效的压缩率,降低数据存储和网络传输的成本。
而就在今年上半年,英特尔发布了其用于 CPU 的开源编解码器 SVT-AV1 的 1.0 版,相比 0.8 版本,性能上有着巨大提升。
归根结底,尽管“摩尔定律”还在继续,但当下已过了靠吃“硬件红利”就能搞定新应用场景的“甜蜜期”。
今天,我们需要了解的是以 CPU 、GPU、加速器和 FPGA 等硬件为核心的复合架构,也被称之为由标量、矢量、矩阵、空间组成的 SVMS 架构。这一概念由英特尔率先提出,并迅速成为业内最主要的硬件架构策略。
位于硬件之上的开发者工具也存在同样的趋势,英特尔的 oneAPI 就是一个典型作品。只是对于开发者工具来说,目前最主要的工作不是性能提升,而是生态和整合。
从硬件到基础软件,再到开发者工具,整个基础设施层呈现高度复杂化的架构演进趋势,既是对架构师工作的严峻挑战,也给了所有架构师更大的发挥空间。对于架构师来说,如何为自己的企业算清楚成本,在追求高性能、高可用的同时,将硬件一并纳入考虑并高度重视,才是重中之重。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号