Andrej Karpathy:未来计算机将由神经网络驱动的新构想
发表时间: 2024-07-02 16:50

作者:付奶茶
昨天凌晨,知名人工智能专家、OpenAI的联合创始人Andrej Karpathy提出了一个革命性的未来计算机的构想:完全由神经网络驱动的计算机,不再依赖传统的软件代码。
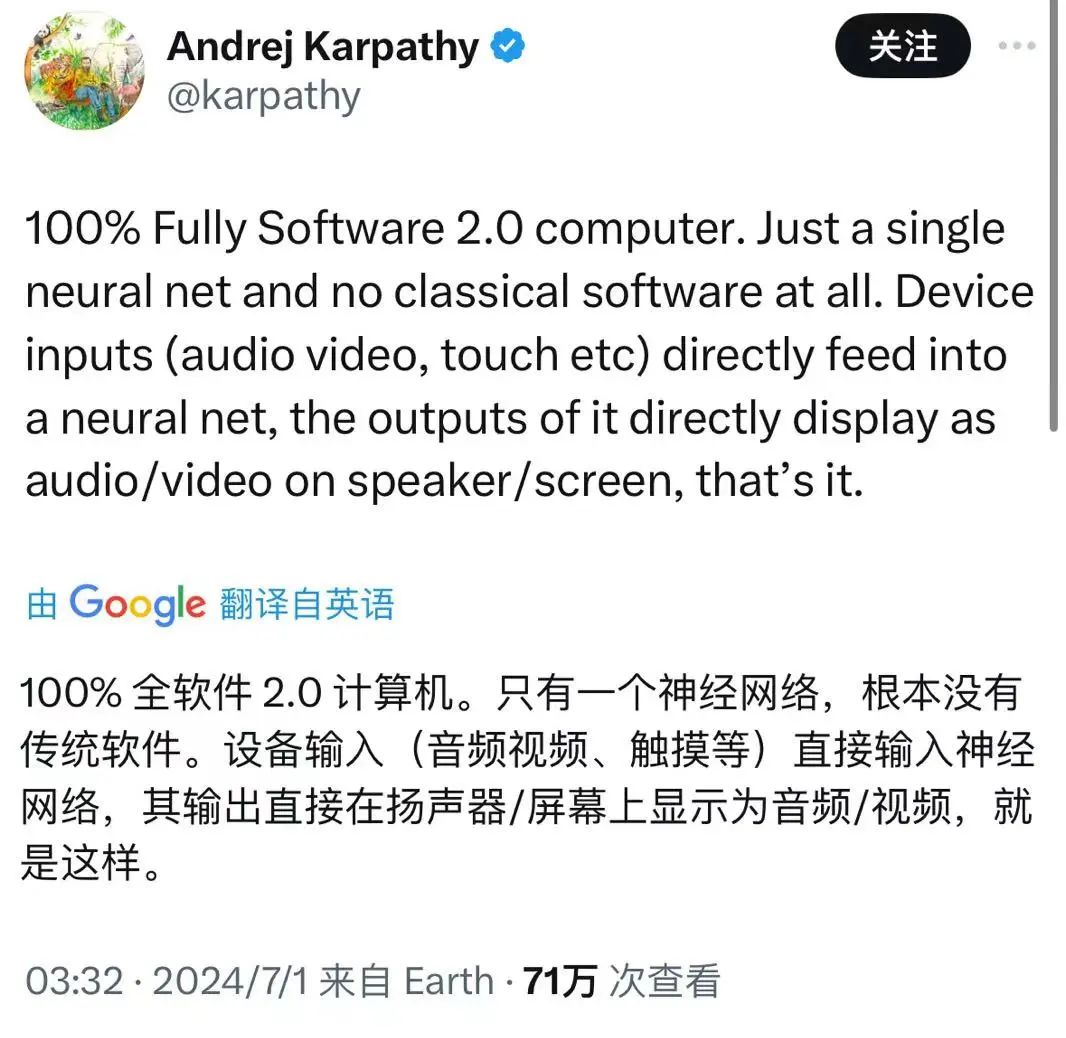
嗯,这是什么意思?全部原生LLM+硬件设备的意思吗?
这一概念的提出,引发了网友广泛的讨论和巨大关注,奶茶觉得这个设想看上去会不会太宏观而且不切实际,于是查看了Karpathy 在帖子下的回复,试图找到支撑性的证据:
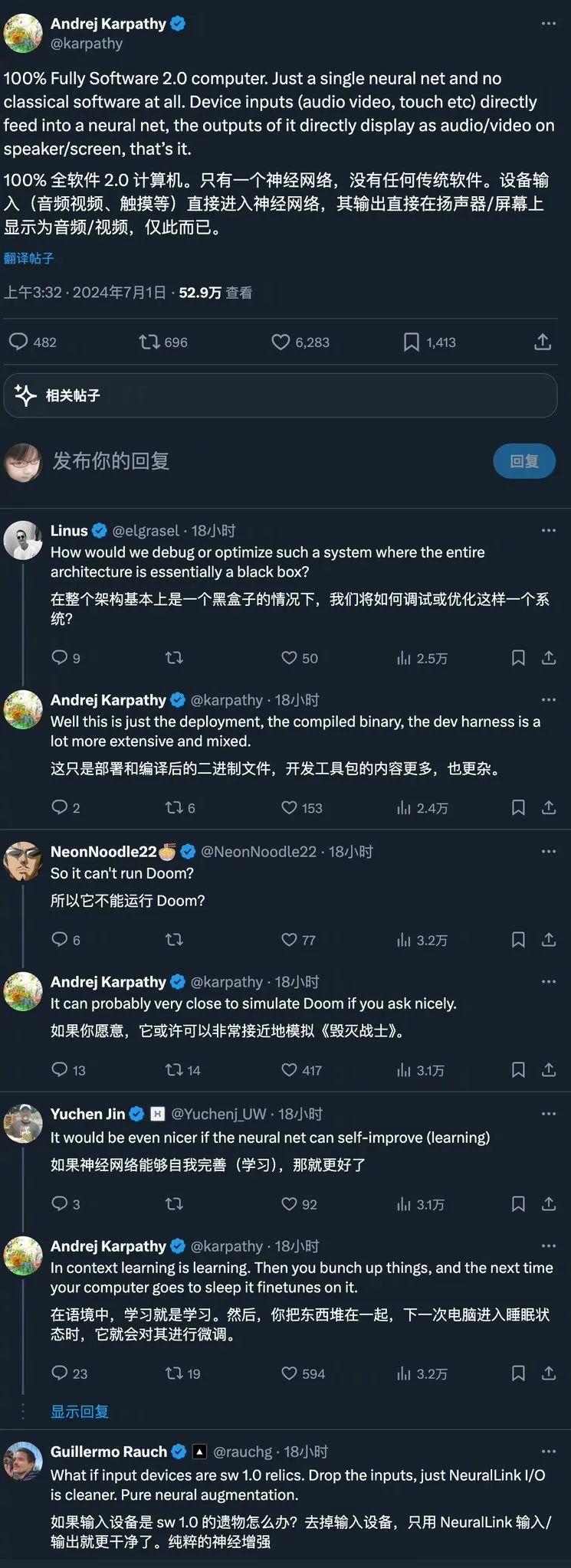
根据Karpathy的解释,在这种架构下,设备的输入(如音频、视频、触摸,甚至自然语言)将直接传递给神经网络,输出则直接显示为结果,可能是音频/视频,也可能是交互界面在屏幕上。整个计算过程完全依赖于神经网络的处理能力,这种简化的架构将彻底改变计算机的工作方式。
有网友形象地比喻,这类似于人类大脑和躯体的关系:大脑负责处理,而躯干(外设)负责执行输出。
奶茶总结了一下网友们对这个设想的担忧:
透明度和可解释性:完全依赖神经网络的系统可能难以解释其决策过程,导致“黑匣子”问题,增加了监管和信任的难度。
算力和能源消耗:如此大规模的神经网络计算需要极高的算力和能源,可能对资源和环境造成巨大压力。(哈哈,虽然但是,最后的赢家不还是英伟达)
安全性和隐私:神经网络驱动的系统可能容易受到攻击,尤其是如果数据输入未经严格验证,可能导致安全和隐私问题。
技术依赖:过度依赖神经网络技术可能限制计算机的灵活性和适应性,尤其在面对非结构化或突发性问题时。
大家怎么看捏!这个设想究竟是不是可以看得到的未来呢~
他爱死了Apple Intelligence!
Andrej Karpathy提出的未来计算机构想有没有让大家联想到前几天发布的Apple Intelligence?
奶茶觉得Andrej Karpathy提到的未来愿景与Apple Intelligence有着异曲同工之妙。于是我查找了Karpathy对Apple Intelligence的看法,果然,他公开坦言对这个概念爱不释手。以下是他之前的发言:

“事实上,我非常非常喜欢苹果公司发布的 Apple Intelligence。在苹果公司,人工智能成为整个操作系统的基础,这是一个非常激动人心的时刻。有几个主要的主题:
多模态I/O:支持文本、音频、图像和视频的读写功能,可以说这些都是原生的人类API。
Agentic:允许操作系统和应用程序的所有部分通过‘函数调用’进行互操作。用于核心进程的LLM(大语言模型)可以根据用户查询安排和协调各部分的工作。
无摩擦:高度无摩擦、快速、‘始终在线’和情景化地全面集成这些功能。无需四处复制粘贴信息、提示工程等,根据需要调整用户界面。
主动性:不只是根据提示执行任务,而是预测提示、提出建议并主动行动。
授权分级:尽可能使用设备端算力(苹果芯片非常有用且适合),但也允许将工作分派到云端。
模块化:允许操作系统访问并支持不断增长的LLM生态系统(例如ChatGPT合作公告)。
隐私:保障用户隐私。
我们很快就会进入这样一个世界:你可以打开手机,随便说点什么。它会回应你,而且它认识你。一切都很顺利。这太令人兴奋了,作为一名用户,我非常期待。”
Karpathy说清醒梦很像Sora
Andrej Karpathy不仅在技术上有深厚造诣,而且非常擅长进行内心观察。他之前就写过一个很出圈的帖子,谈到了断网的感受。最近,他除了发表争议与希望并存的未来计算机构想,还发表了一个Sora相关的描述也很热门!他记录了自己的一次清醒梦体验~
何为清醒梦呢,就是指做梦者意识到自己在做梦,并且能够在一定程度上控制梦境中的场景、角色或自己的行为。一位网的描述很准确:清醒梦的梦境会根据你的关注点生成细节,而你没有直接审视的部分则呈现得不准确。这种现象有点像游戏的图形渲染,为了节省资源,只渲染必要的部分。
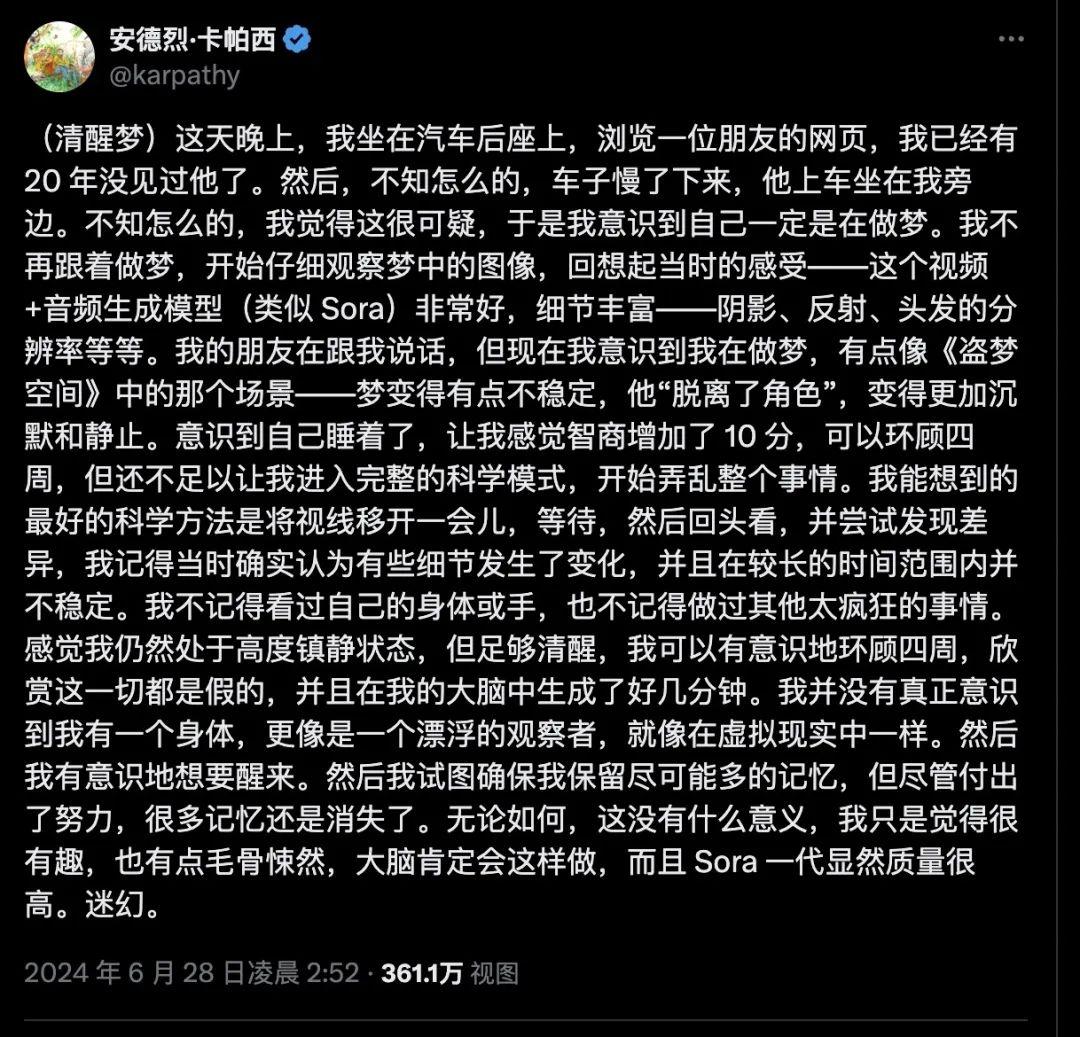
Karpathy在帖子中提到,他感觉梦境像一个Sora模型,充满了丰富的细节,而且自己的智商突然提高了10点。
清醒梦这个比喻还蛮有趣的!把Sora模型只渲染必要部分的原理和清醒梦的体验联系在一起,既浪漫又贴切,很妙!!

我相信而且践行了一万小时
奶茶最近还看了Andrej Karpathy在州大学伯克利分校的AI hackathon做的演讲。Karpathy讲了几点还蛮有意思的,和大家分享下:

计算的本质正在改变,我们正在进入一个新的计算范式,这种情况非常罕见。我几乎觉得像是回到了 1980 年代的计算机时代,不再是中央处理器 (CPU) 处理指令和字节,而是大语言模型 (LLM) 处理 Token,我们有 Token 的上下文窗口,而不是 RAM 中的字节,并且有磁盘等的等效物。这有点像计算机,但现在大语言模型是新的核心,这就是为什么我称之为大语言模型操作系统LLM OS
OpenAI的成立的初衷是为了与Google形成某种平衡,那时,Google就像一只拥有700亿自由现金流的巨兽,几乎雇用了半个AI研究行业。我们只有八个人和一台笔记本电脑,这种对比真的很有趣,也非常符合我的背景。OpenAI最初探索了大量内部项目,我们招聘了一些非常优秀的人才,其中许多项目并没有走太远,但有些确实成功了,例如在最早期我们开发了一个Reddit聊天机器人试图与Google竞争,当Transformer出现后,它被转化为一个更好的东西,领域从Reddit扩展到许多其他,而随后有了GPT-1、GPT-2、GPT-3、GPT-4,甚至有了GPT-4o。我见证了这些“小雪球”的发展过程~直到今天,OpenAI的市值达到了可能接近1000亿美元,许多你们在过去两天中也在做的小项目,也许它们不会成功,但其中一些可能会成功。你们应该继续推动你们的小雪球,也许它们会发展成一个真正的大雪球~
我很相信Malcolm Gladwell提出的1万个小时的概念。我相信这个理论,成功来自于重复练习,我们应该非常愿意投入那1万个小时,不要太在意自己在做什么,是否成功或失败,简单地计算你投入了多少时间。即使是那些我失败的项目,它们没有发展成任何东西,但它们也增加了我开发专业知识的时间总数,让我能够自信地承担这些项目并使其成功!
大家如果感兴趣Andrej Karpathy全部演讲的内容,可以在评论区告诉我们~我们安排更详细的汇报
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12


 鲁公网安备37020202000738号
鲁公网安备37020202000738号