掌握MySQL:数据库管理的艺术
发表时间: 2022-07-26 16:46
mysql下载地址:
https://dev.mysql.com/downloads/installer/
Navicat下载地址
:https://pan.baidu.com/s/1ScIFDQ7F8bl512Wz9wFZ-w 密码:j42l
存储、查找。
官网:https://www.mysql.com/
数据库排名网站:
https://db-engines.com/en/ranking
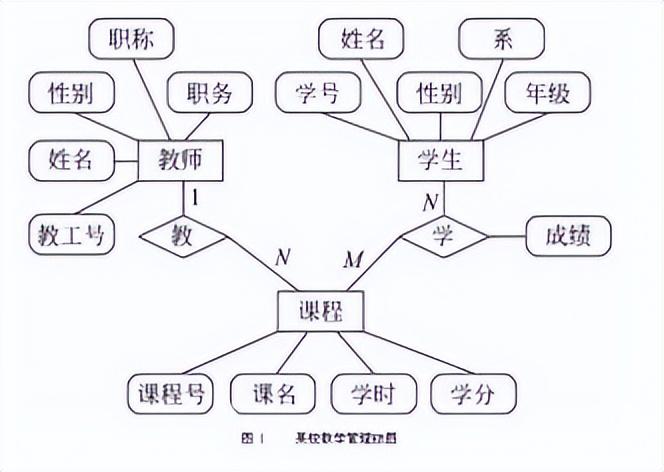
E-R模型
E显示Entity,实体
R表示Relationship,关系
一个实体转换为数据库中的一个表
关系描述两个实体之间的对应规则:(关系的存储)
三范式
1NF:列不可拆分
2NF:唯一标识,不存在对主键的部分依赖
3NF:引用主键,列不传递依赖于主键
数据完整性:
字段类型,约束
字段类型,常用:
数字:int,decimal(浮点数)decimal(5,2):整数5位,小数点后2位
字符串:char(长度固定),varchar(长度可变),text(大文本),char(8),verchar(8)
日期:datetime
布尔:bit
int 默认11位,char默认1位,varchar默认空着会报错,单引号,双引号没区别。
约束,常用:
主键primary key
非空not null
唯一unique(不能重复)
默认default
外键foreign key
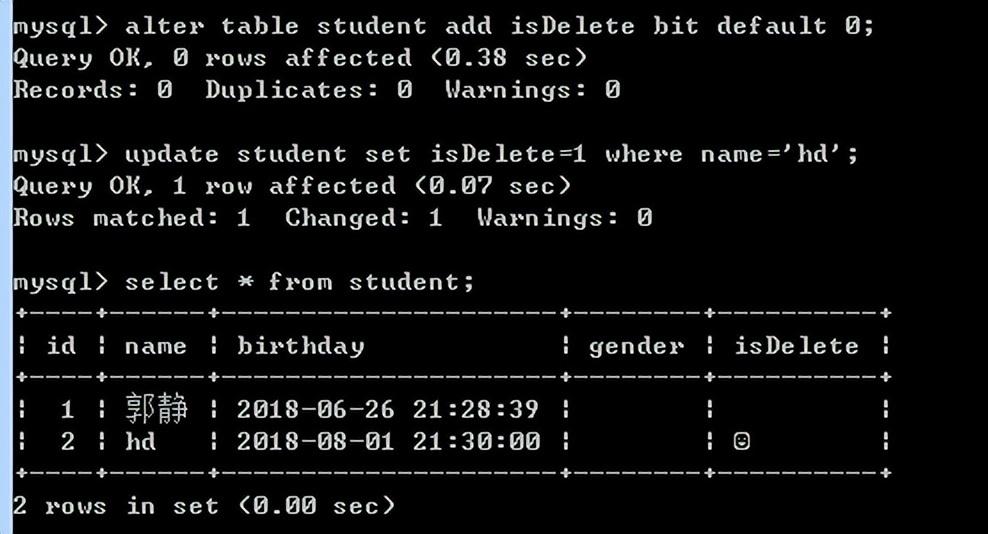
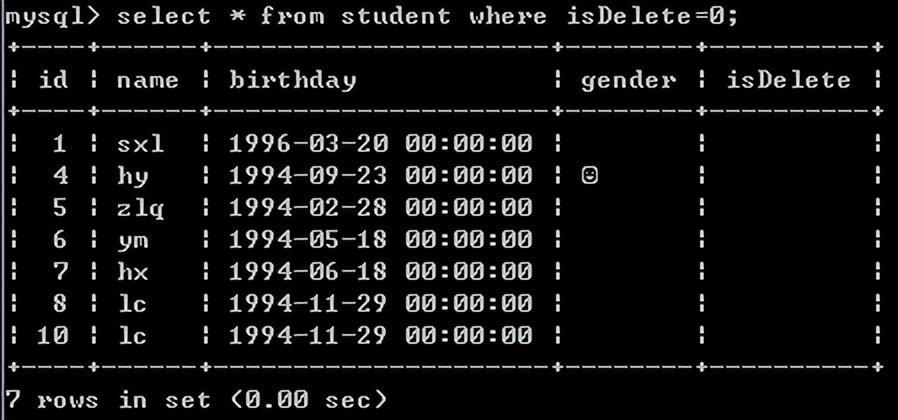
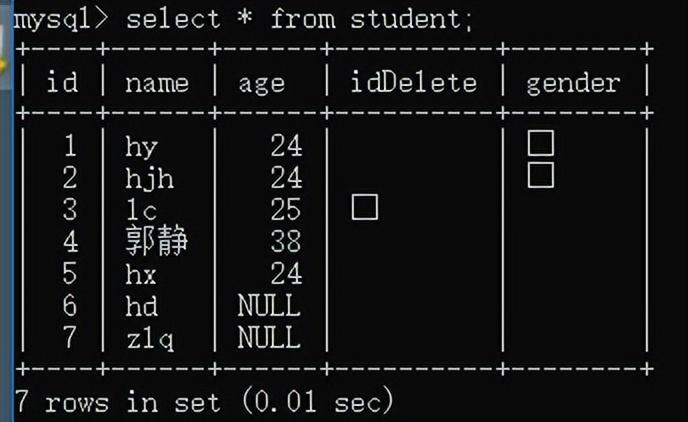
逻辑删除:
删除表中的数据的时候,不是直接真实的删除,而是加一栏isDelete标识,默认为0,要删除的时候把isDelete置为1,我们就明白它是被删除了。
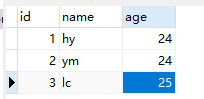

使用下面的-是直接删除。
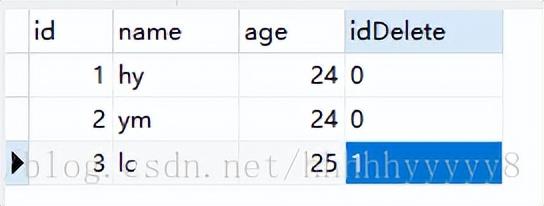
加一个isDelete=1表示删除了。
命令脚本操作:
链接数据库服务器:mysql -hlocalhost -uroot -p
回车后输入密码

退出:exit/quit
查看当前版本:select version();
查看当前时间:select now();
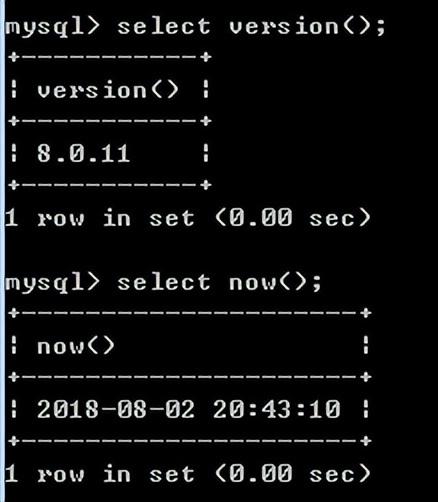
注意语句结束要输入分号
查看存在的所有数据库:show databases;
创建数据库:create database 数据库名;
删除数据库:drop database 数据库名;
切换数据库:use 数据库名;
查看当前选择的数据库:select database();
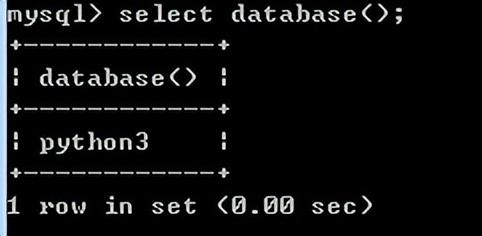
查看数据库下的表: show tables;
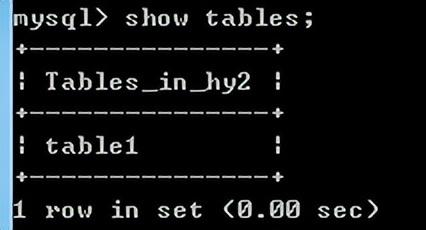
创建表:
create table 表名(列及类型);
例如:
create table student(
id int auto_increment primay key not null,
name varchar (20) not null,
gender bit default 1,
birthday datetime);
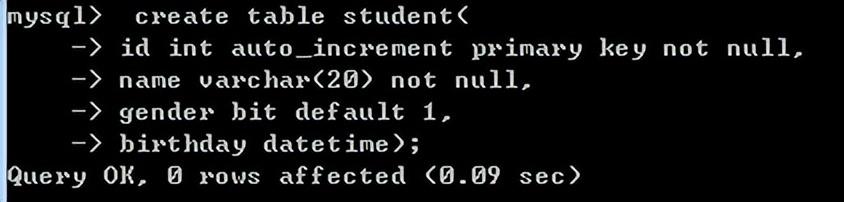
查看表的结构:desc 表名;
修改表:
alter table 表名 add/change/drop 列名 类型;
例如:alter table student add isDelete bit default 0;
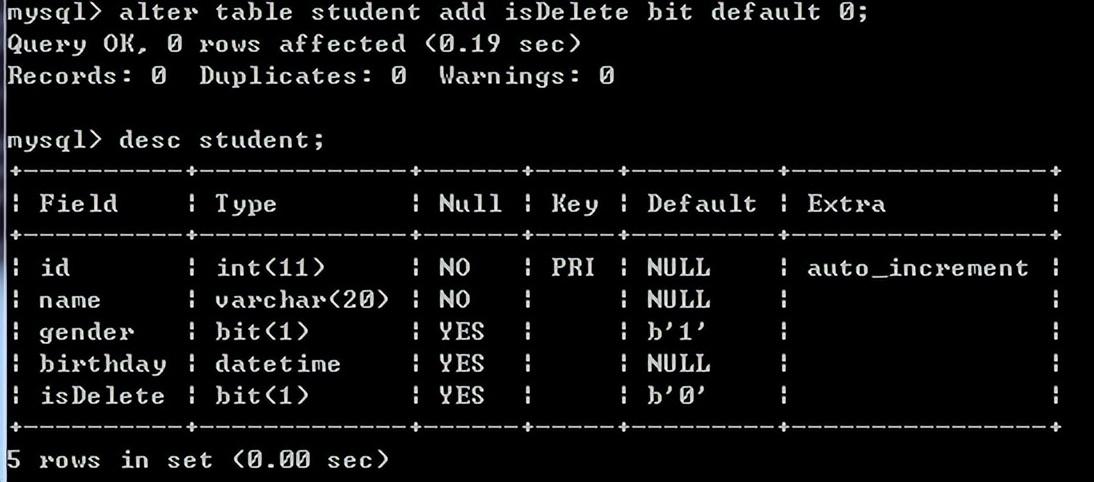
删除表:drop table student;

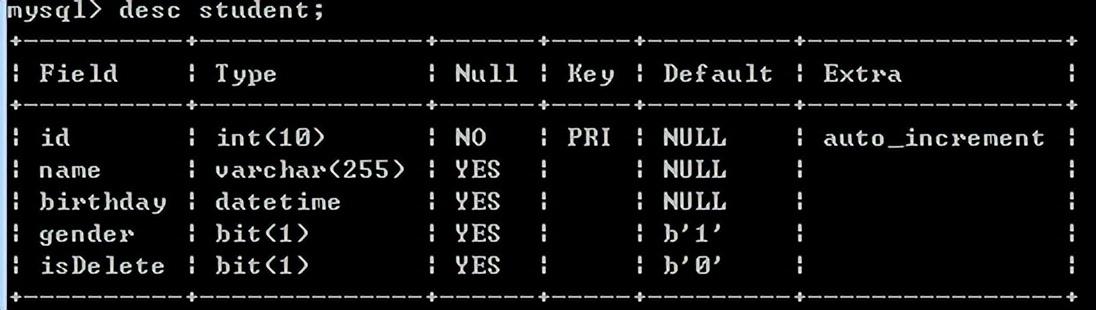
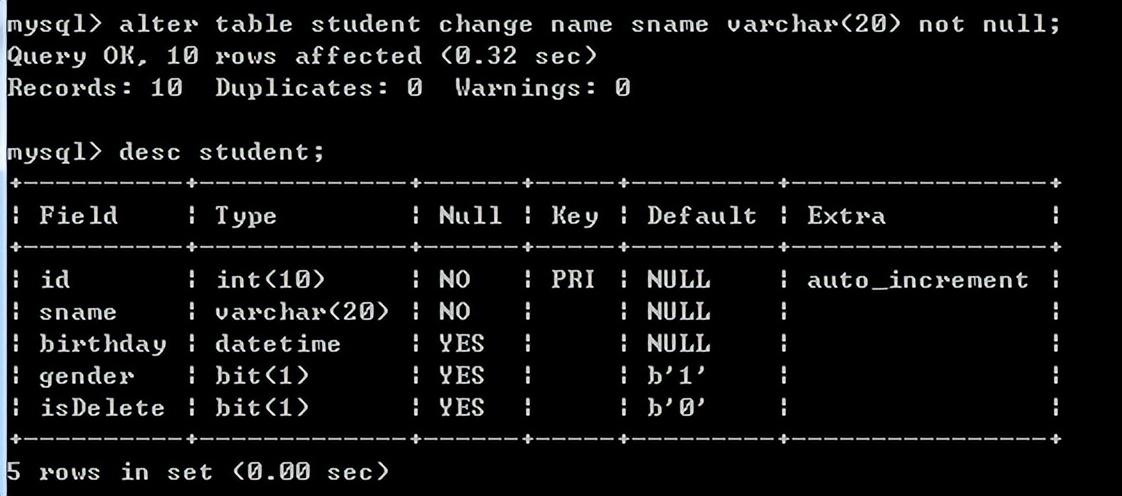
修改表:alter table student change name sname varchar(20) not null;
修改字段名,可以同时修改字段类型。
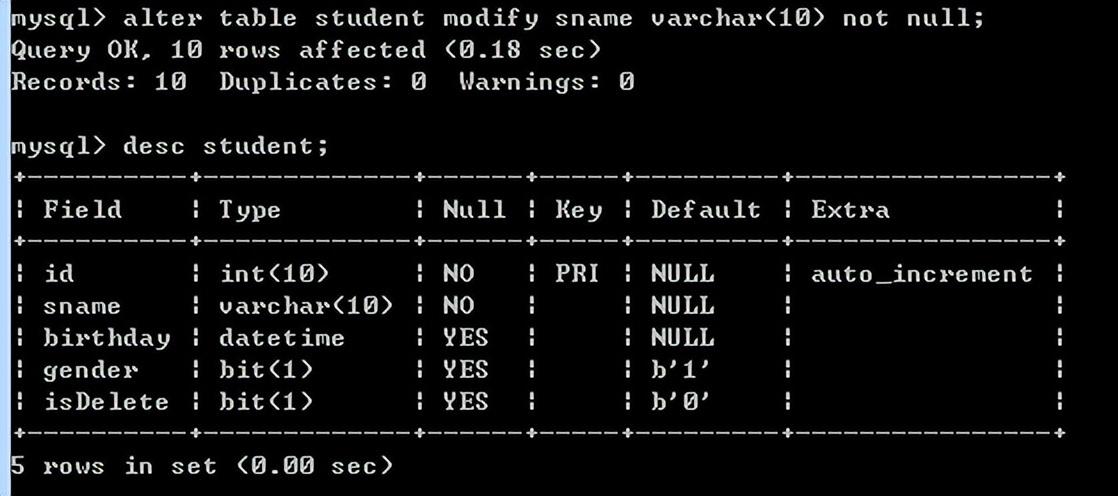
修改表字段类型,不能修改字段名
alter table student modify sname varchar(10) not null;
更改表名称:rename table 原表名 to 新表名;
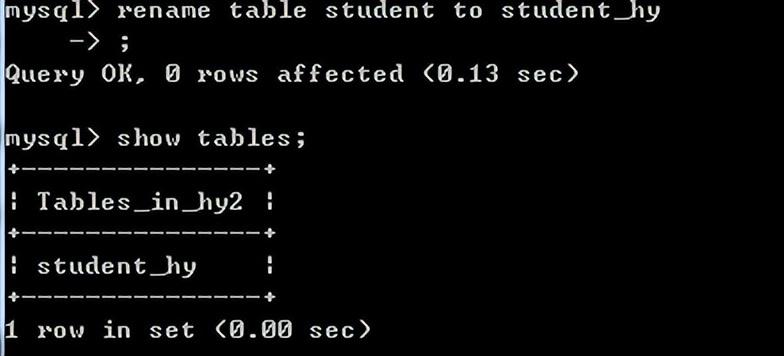
查看表的创建语句:show create table 表名;
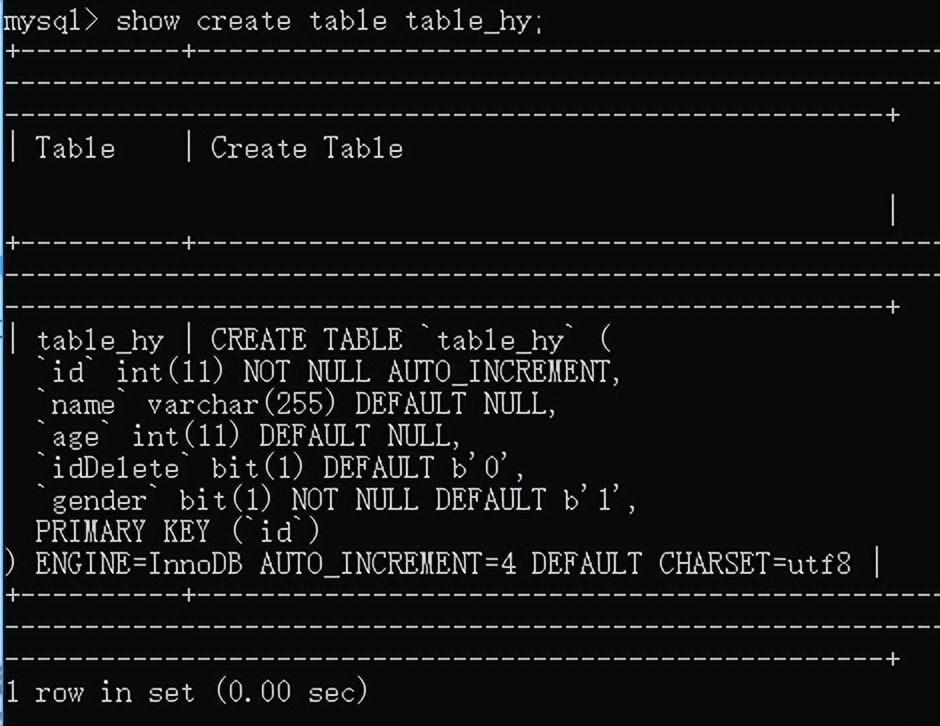
自己写的比系统的要简单点,因为有些东西是默认的不用写。
查询:select * form 表名;
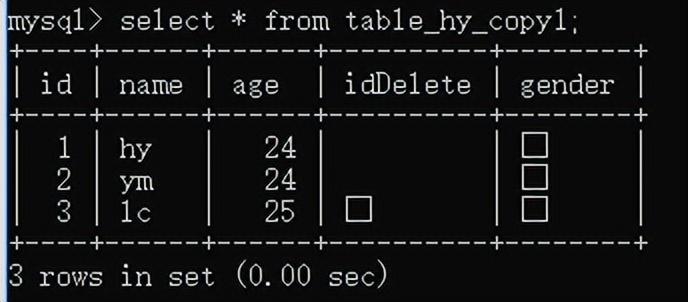
增加:
全列插入:insert into 表名 values(...);值的顺序和表中列的顺序严格对应。
就算是有默认的数据的值也需要插入,值的个数得和表格的列的个数一样。不然会报错

主键列是自动增长,但是在全列插入的时候需要占位,通常使用0,插入成功后以实际数据为准。
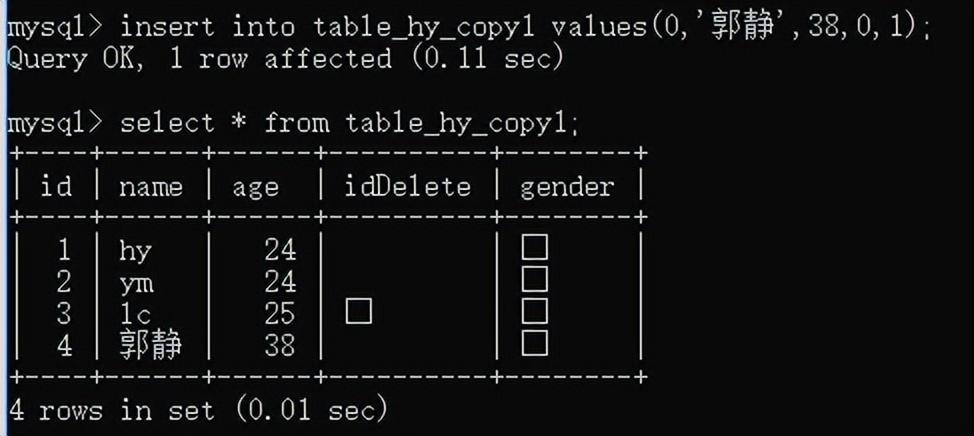
缺省插入:insert into 表名(列1...) values(值1...);可以不按顺序,值和列对应就可以了。
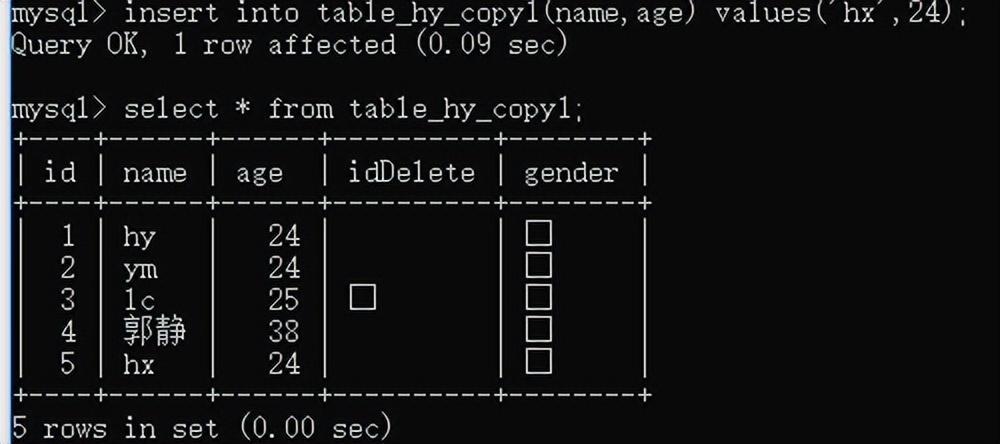
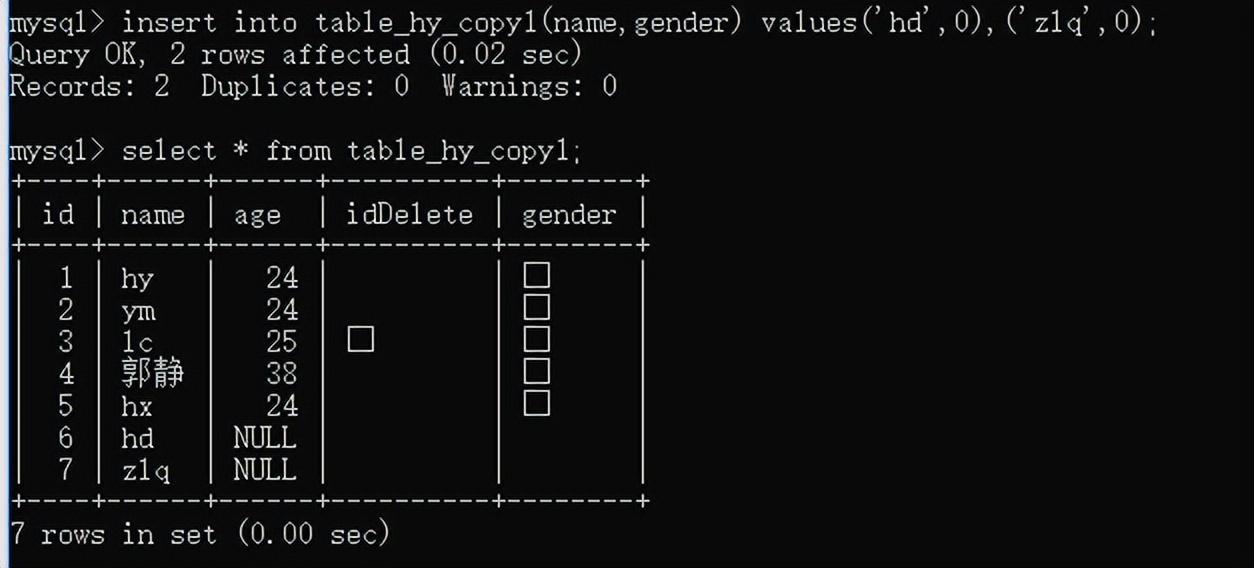
同时插入多条数据:insert into 表名 values(...),(...)...;
或insert into 表名(列1...) values(...),(...)...;
修改:
update 表名 set 列1=值1,列2=值2,...where 条件

删除
delete from 表名 where 条件(物理删除)
逻辑删除(本质上就是修改)
alter table 表名 add isDelete bit default 0;
update 表名 isDelete=1 where 条件;
数据库备份:mysqldump -uroot -p 待备份数据库名 > 存储路径/备份名.sql
mysqldump和mysql路径一致,前提是加入了系统路径中。

恢复
方法一、mysql中
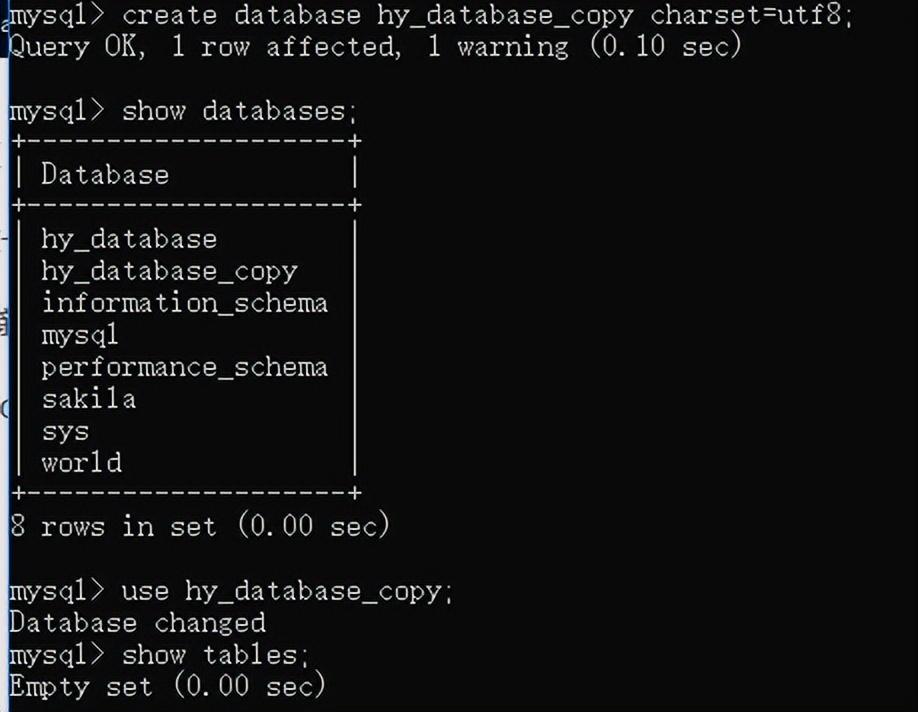
创建一个新的数据库名,用于接收要恢复的数据库:cerate database hy_database_copy charset=utf8;
use 新的数据库:use hy_database_copy;
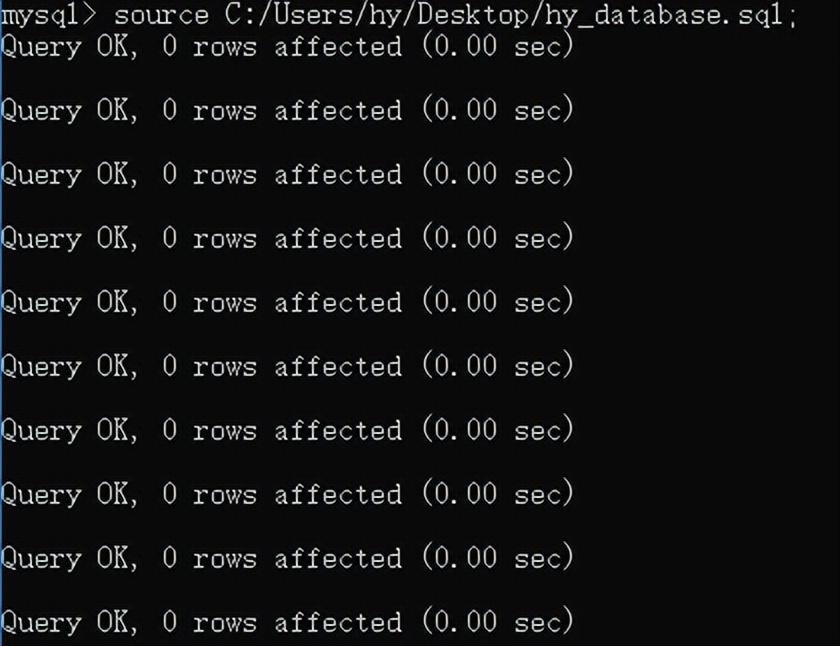
source 文件名:source
C:/Users/hy/Desktop/hy_database.sql; 注意这里不能输入\,只能是/
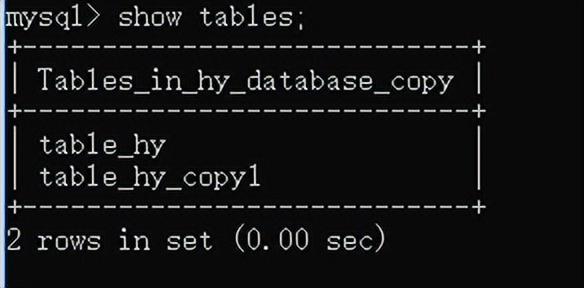
方法二 、cmd中
mysql -u root -p --default-character-set=utf8 -f databasename<
C/Users/hy/Desktop/hy_database.sql 注意这里没有分号结尾
databasename是自己新创立的接收的数据库名。

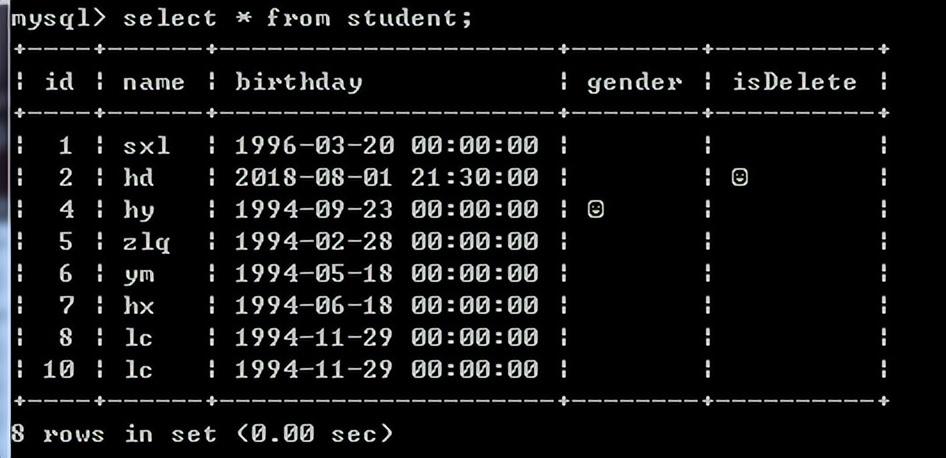
查询
查询一张表的所有内容:
selece * from 表名;
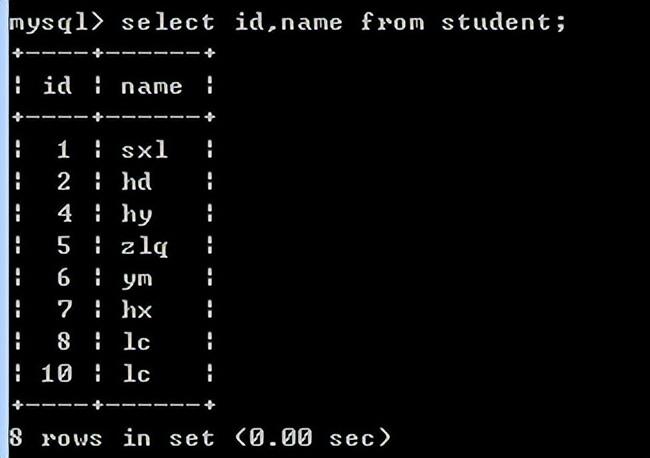
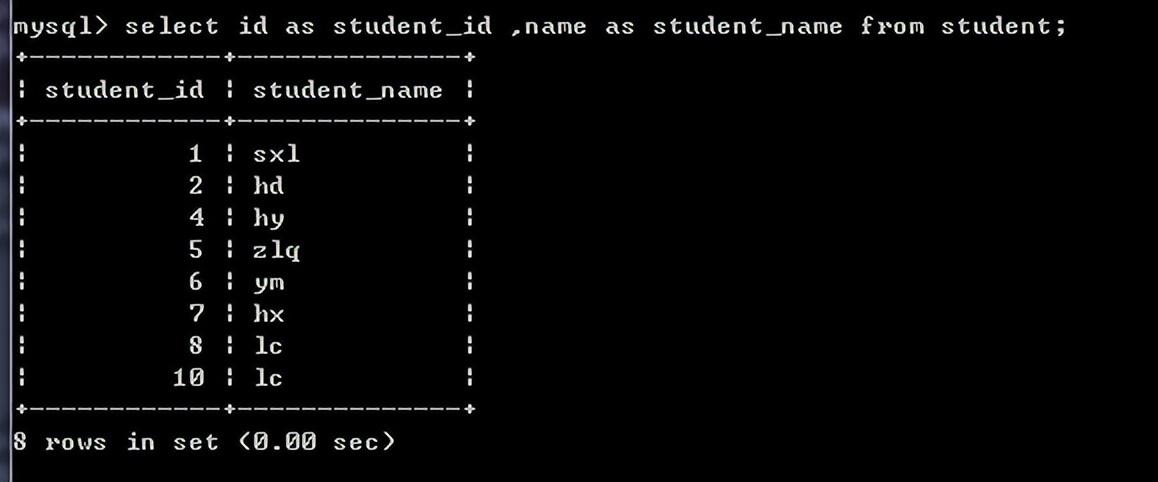
查询部分字段:
select后面写表中的列名,可以使用as为列其别名,这个别名出现在结果中,如果要查询多个列,之间用逗号分割;
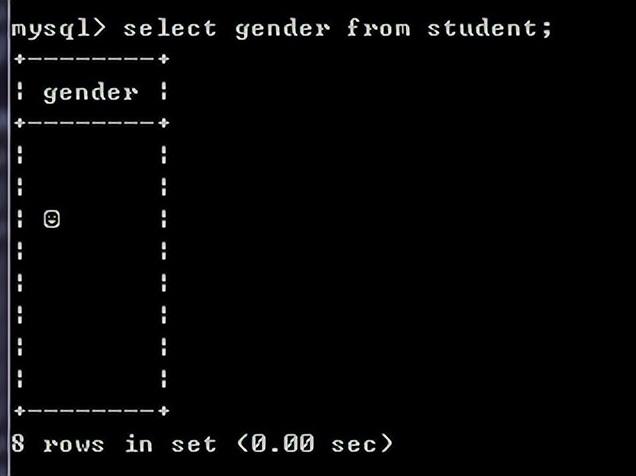
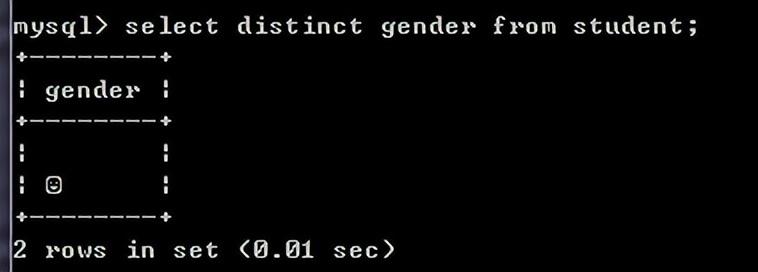
删除查询结果中重复的行:
在select后面列前面使用distinct可以消除重复的行
select distinct gender from student;
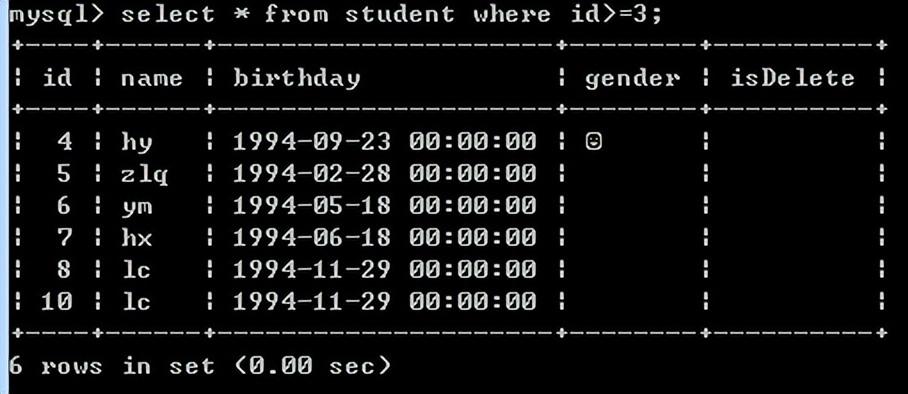
条件:
select选列,where选行;
比较运算符:=、>、<、>=、<=、!=、<>
逻辑运算符 and 、or、 not
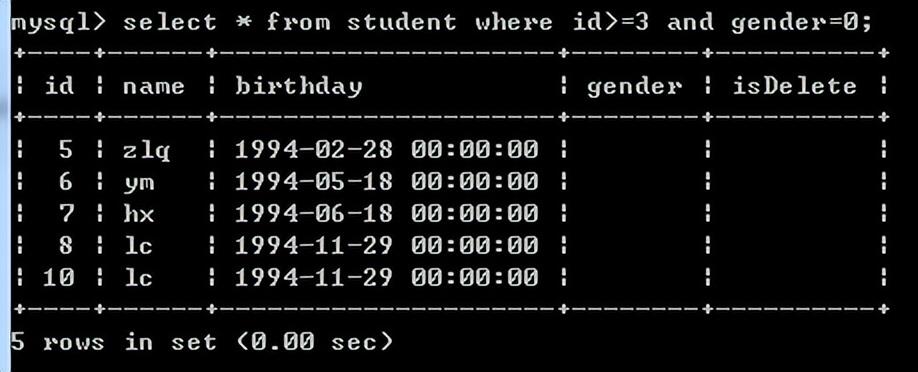
查询id大于3的女同学
模糊查询 :like
%表示任意多个字符
_表示一个任意字符
例如:'h_'、'_h'、'h__'、'_h_'、‘h%’、'%h'、‘%h%’。
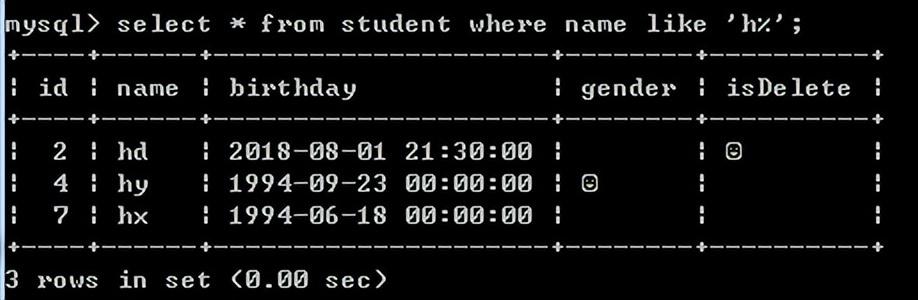
例如:查询name字段h开头的学生
select * from student where name like 'h%'
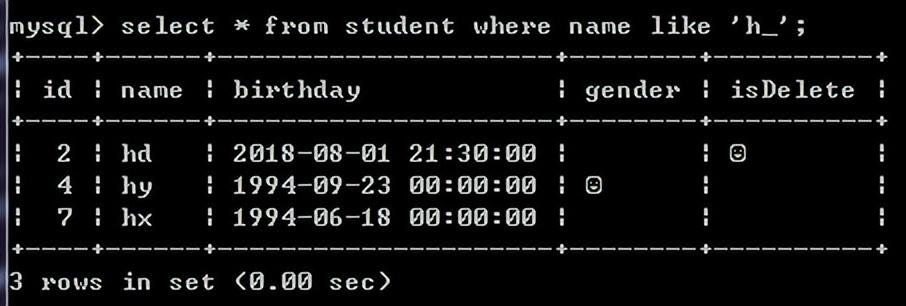
例如:查询name字段h开头,且只有两个字符的学生
select * from student where name like 'h_'
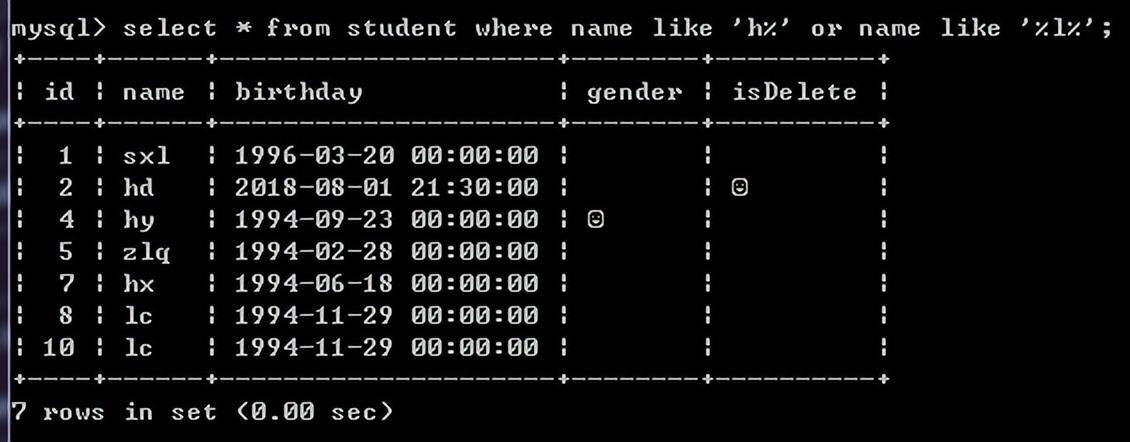
例:查询name字段h开头或者包含l的同学
select * from student where name like 'h%' or name like '%l%';
范围查询:
in:表示在一个非连续的范围内
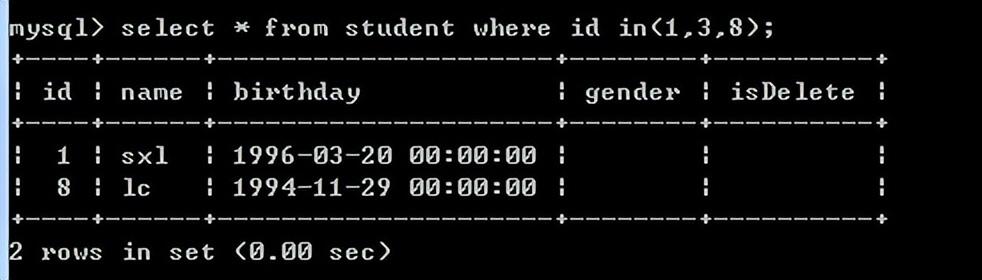
例如:查询编号是1或3或8的学生
select * from student where id in(1,3,8);
between .. and ..表示在一个连续的范围
例如:插入id是3-8的学生
select * from student where id between 3 and 8;

空判断
注意:null与‘’是不同的
判空:is null;非空:is not null
例如:查询没有生日的学生
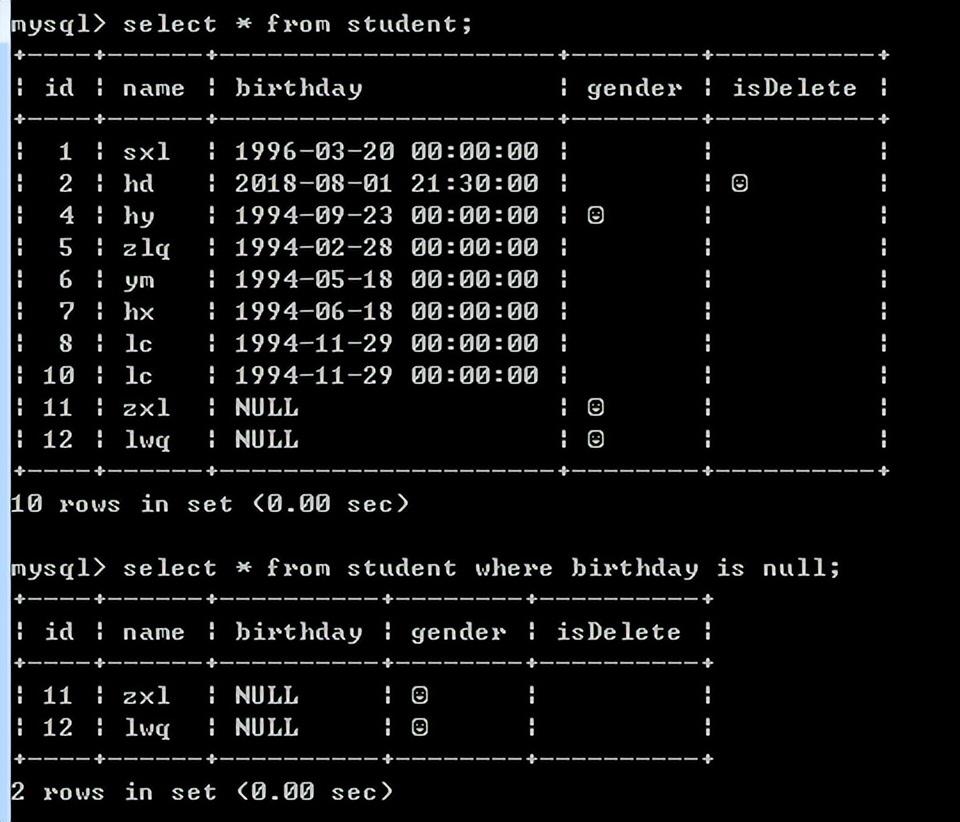
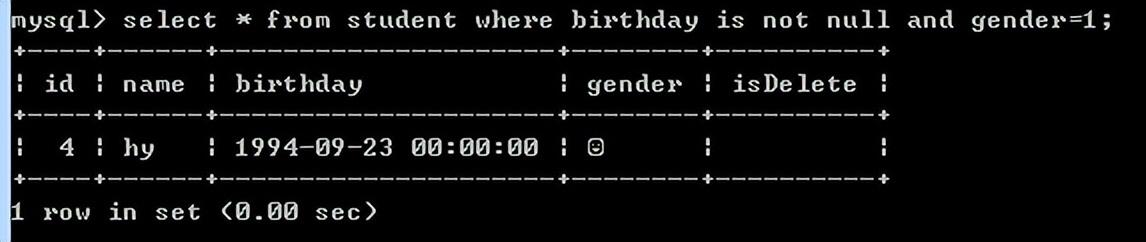
查询填写了生日的男生
优先级
小括号,not,比较运算符,逻辑运算符
and比or先运算,如果同时出现并希望先算or,需要结合()使用。
聚合
为了快速得到统计数据,提供了5个聚合函数
count(*)表示计算总行数,括号中写星与列名,结果是相同的
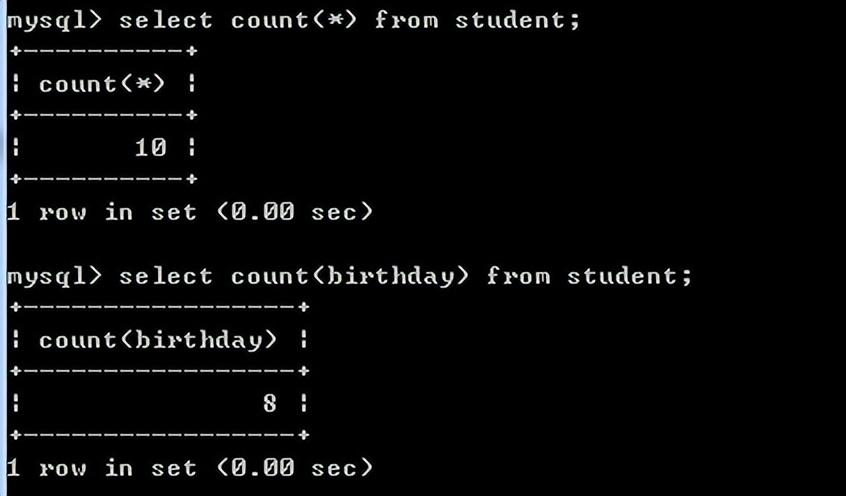
例如:查询学生总数
select count(*) from student;
查询有生日的人的总数:select count(birthday) from student;
max(列)表示求此列的最大值
例如:查询男生的编号最大值
select max(id) from student where gender=1;
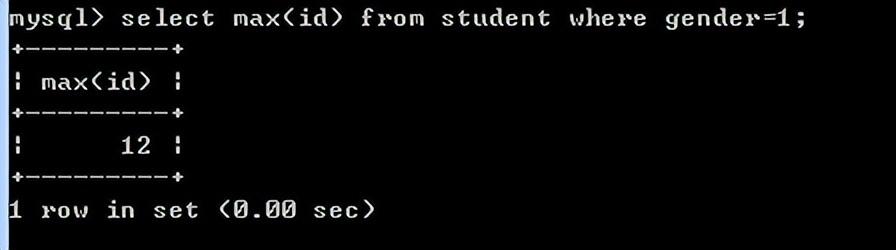
min(列)表示求此列的最小值

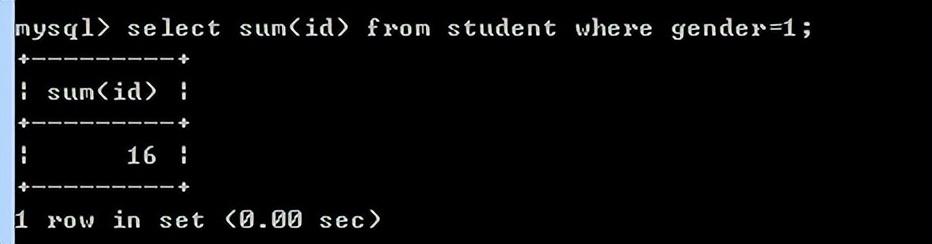
sum(列)求该列的和
例如:求男生的id和
select sum(id) from student where gender=1;
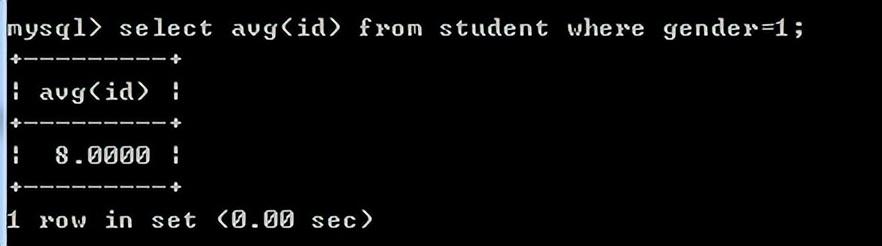
avg(列)求该列的平均值
例如:求男生id的平均值
select avg(id) from student where gender=1;
分组
按照字段分组,字段相同的数据会被放到同一个组
分组后,只能查询出相同的数据列,对于有差距的数据列无法出现在结果中
可以对分组后的数据进行统计,做聚合运算
语法:
select 列1,列2,列3 聚合... from 表名 group by 列1,列2,列3...
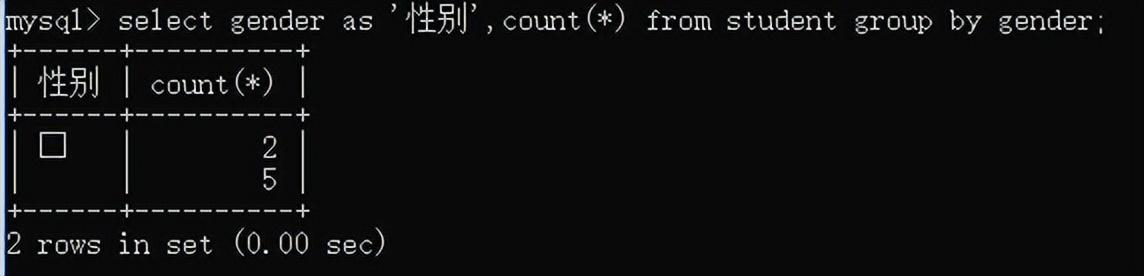
例如:查询男女生总数
select gender as '性别',count(*) from student group by gender;
对分组结果进行删选:
select 列1,列2,列3,聚合... from 表名 group by 列1,列2,列3... having...
having:也是对行进行筛选,只不过它最后执行,
例如:查询男生信息
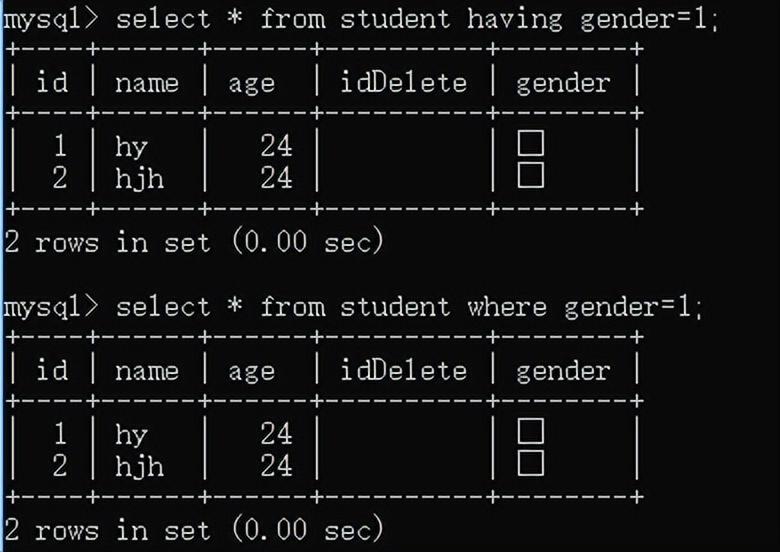
where是对原数据表student进行筛选,having是对select * from student之后的结果进行筛选,顺序不一样。
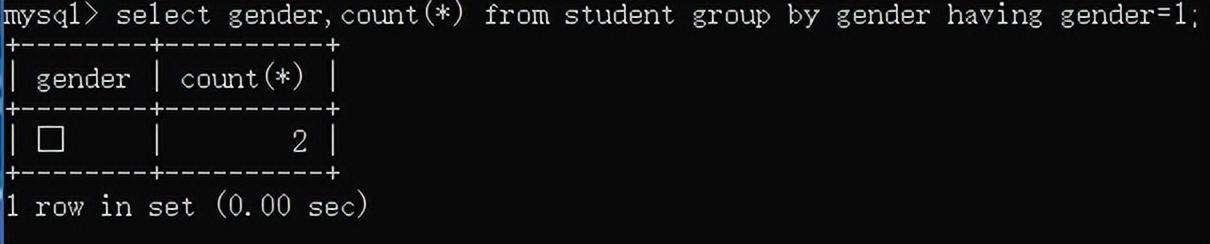
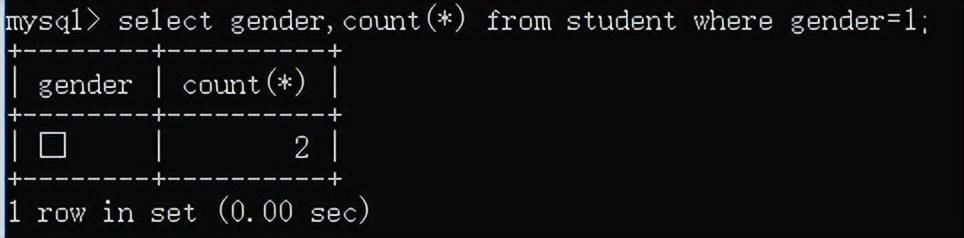
例如:查询男生总人数:
排序
select * from 表名 order by 列1 asc|desc,列2 asc|desc,...
将数据按照列1进行排序,如果列1相同,则再按照列2进行排序,以此类推
默认按照列值从小到大排列
asc:从小到大排列,升序
desc:从大到小,降序
例如:查询女生信息,按照id降序排列
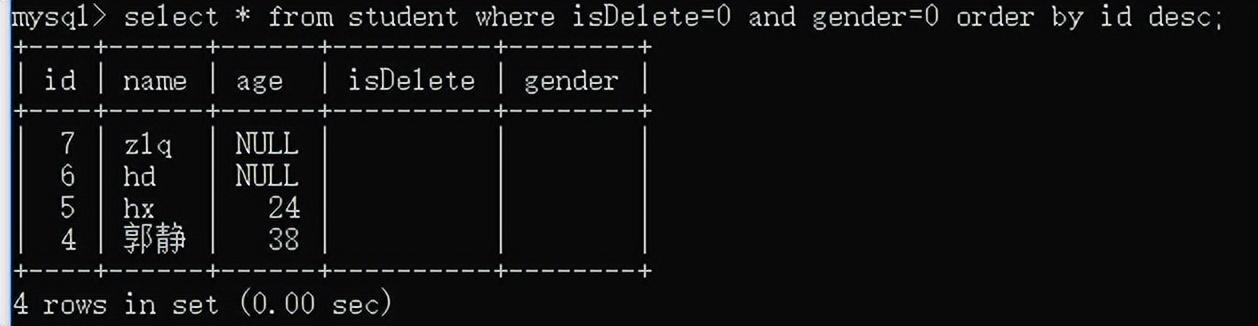

注意order by要放在where后面
分页
当数据量过大时,在一页中查看数据时一件非常麻烦的事
select * from 表名 limit start,count
从start开始,获取count条数据,start索引从0开始,这个start与存储的id无关,存储的第一条数据就是第0条数据。
例如:已知每页显示m条数据,现在想获取地n也的数据(n从1开始)
select * from student limit (n-1)*m,m;
假设n=2,m=3
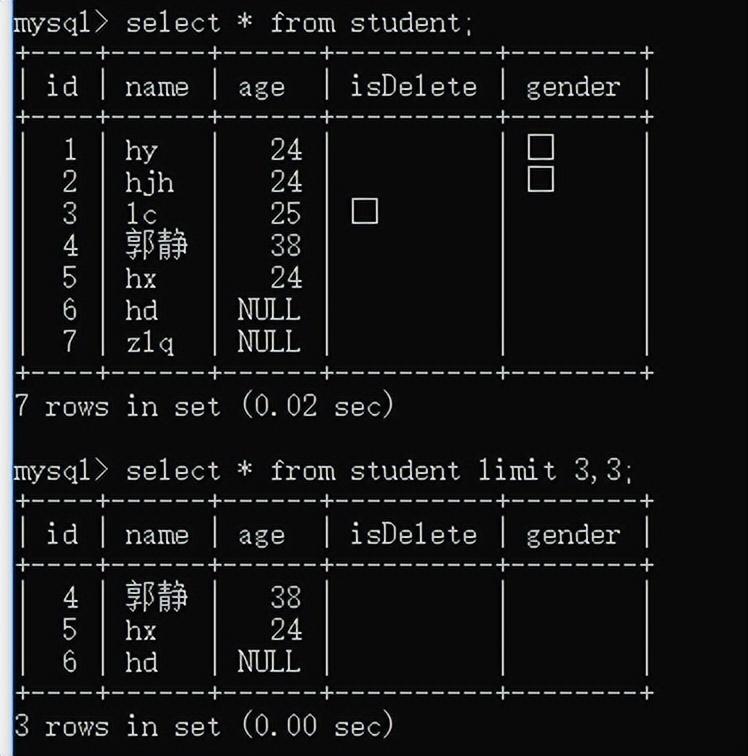
完整的select语句
select distinct *
from 表名
where ...
group by...having...
order by...
limit start,count;
执行顺序为:
from 表名
where...
group by..
select distinct *
having..
order by...
limit start,count
实际使用中,只是语句中某些部分的组合,而不是全部。
关系:
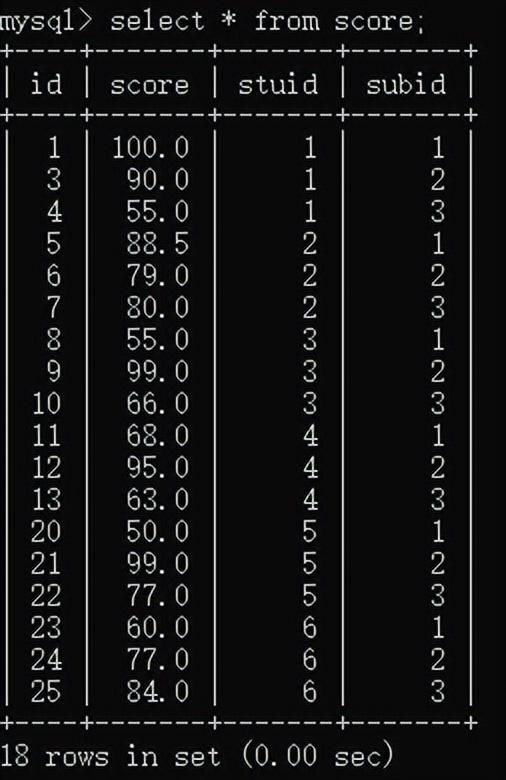
假设现在已经存在了一个学生表和一个科目表,现在要建立一个成绩表。
成绩表score结构如下:
id
学生
科目
成绩
思考:学生列应该存储什么信息?
学生列的数据不是在这里新建的,而是从学生表引用过来,关系也是一条数据,根据范式3要求应该存储学生的id,而不是学生的姓名等其他数据;
同理,科目也是列,引用科目表中的数据
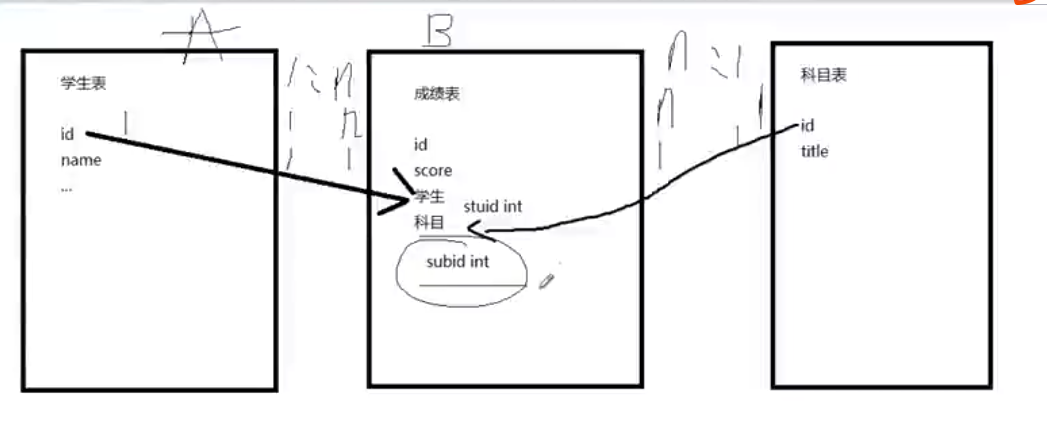
A和B的关系是1:1时,关系存储在A或者B都可以
A:B时1:n时,关系存储在B中
A:B时n:n时,要新建立一张表存储关系。
上图中,学生:成绩为1:n,科目:成绩也是1:n,关系都存储在成绩表中,
以后常见的关系也是1:n的。
关系的闭合,A和B,A和C,B和C都有关系,要断开其中一个关系。
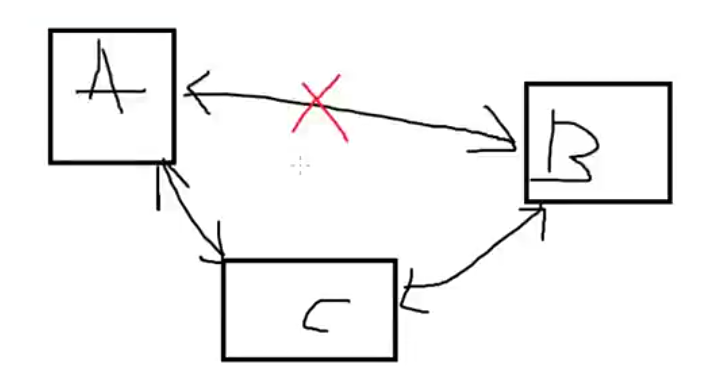
外键
思考:怎么保证关系列数据的有效性了?任何整数都可以么?
必须是学生表中id存在的数据,可以通过外键约束进行数据的有效性验证
为stuid添加外键约束
create table score_test(
-> id int auto_increment not null primary key,
-> score decimal(4,1),
-> stuid int,
-> subid int);
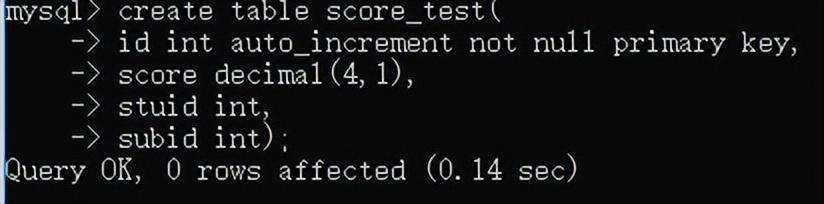
alter table score add constraint stu_sco foreign key(stuid) references student(id);

直接创建score:
create table score(
-> id int auto_increment not null primary key,
-> score decimal(4,1) not null,
-> stuid int,
-> subid int,
-> foreign key(stuid) references student(id),
-> foreign key(subid) references subject(id));
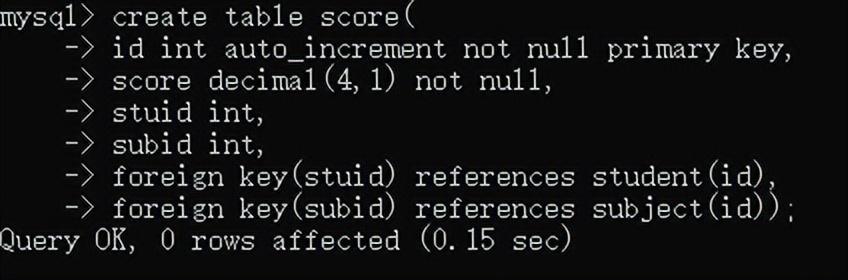
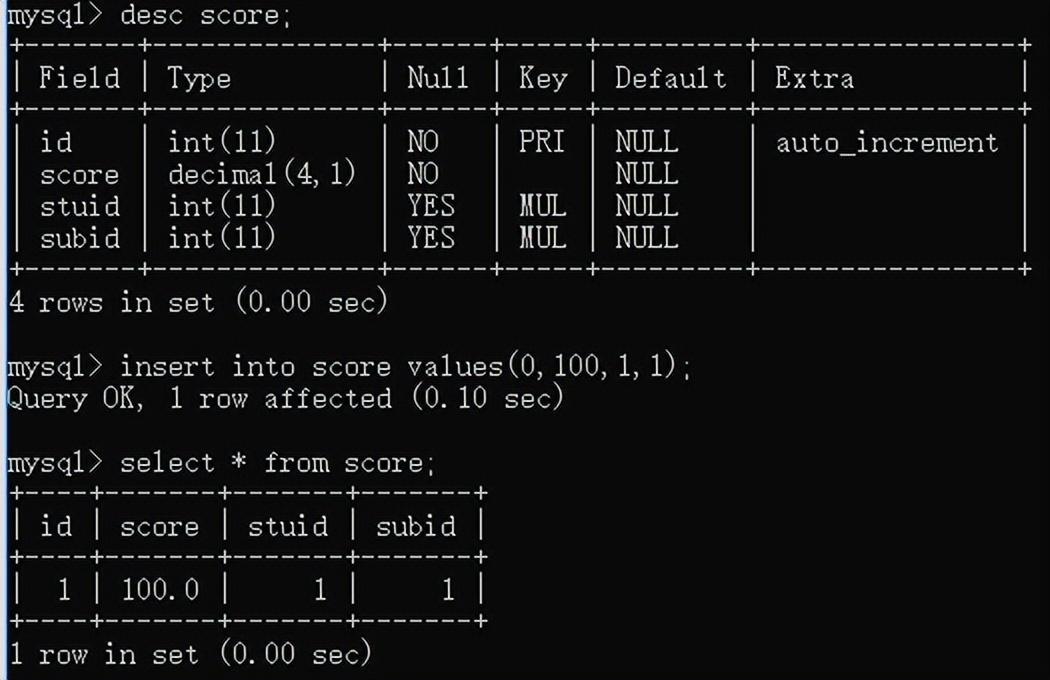
当插入的stuid或者subid不在student和subject的id范围内时,就会报错。

外键的级联操作
在删除student表的数据时,如果这个id值在score中已经存在,则会抛出异常
推荐使用逻辑删除,还可以解决这个问题
级联操作的类型:
语法:
alter table score add constraint std_sco foreigh_key(stuid) references student(id) on delete cascade on update cascade;
连接查询:
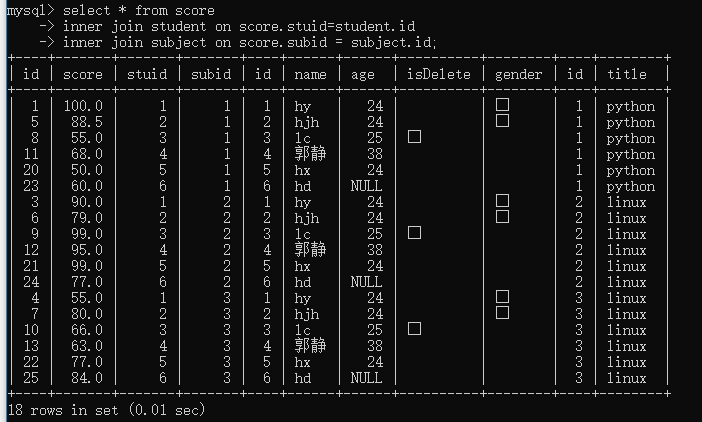
例如:查询每个学生每个科目的分数:
学生的姓名来源于student表,科目来源于subject表,分数来源于score表,怎么讲三个表放到一起,并将结果显示在同一个结果集中了?
答:当查询结果来源于多张表时,需要使用连接查询
关键:找到表间的关系,当前的关系是:
student.id------score.stuid
subject.id------score.subid
在查询或条件中推荐使用“表名.列名”的方式
如果多个表中列名不重复可以省略“表名.”部分
则:
select student.name,subject.title,score.score
from score
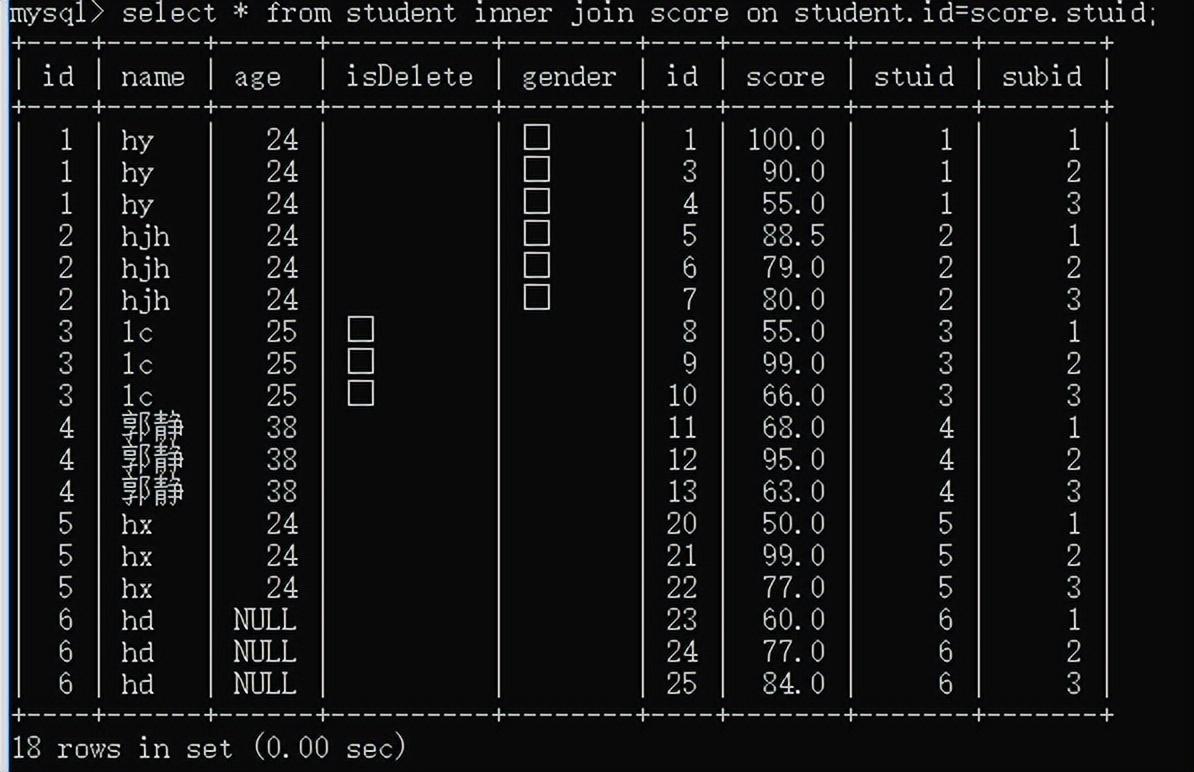
inner join student on score.stuid=student.id
inner join subject on score.subid=subject.id;
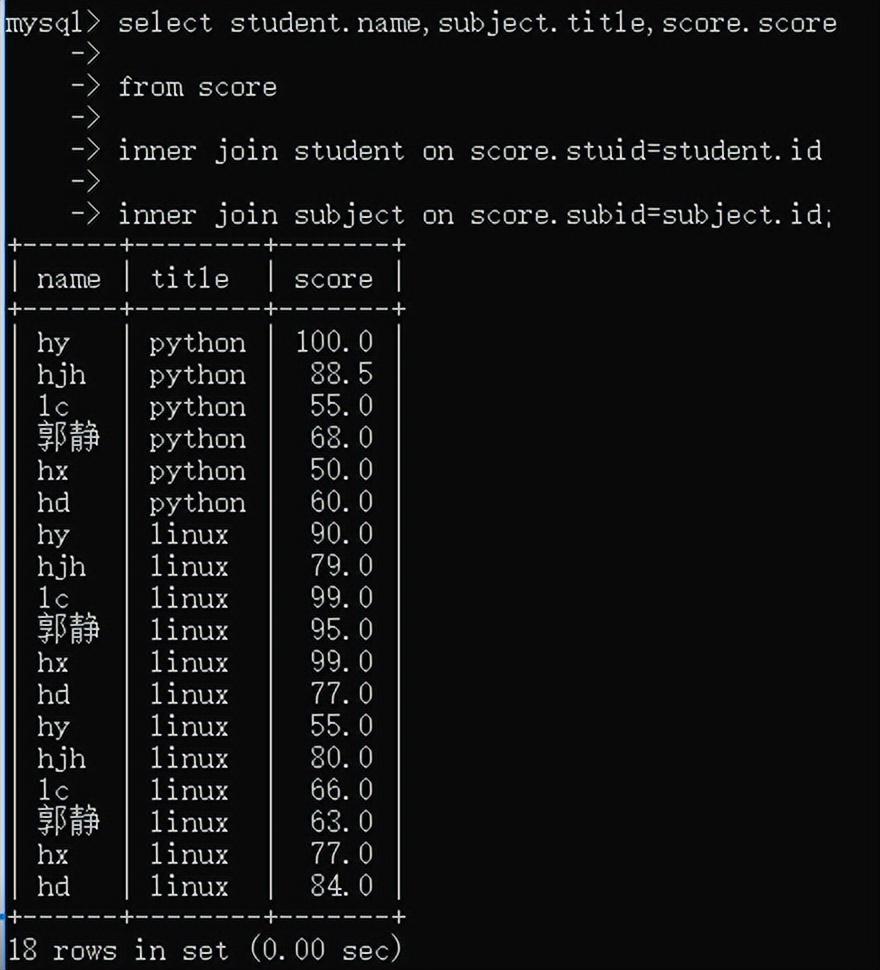
下面这种写法也是一样的, 反正就是把表连起来
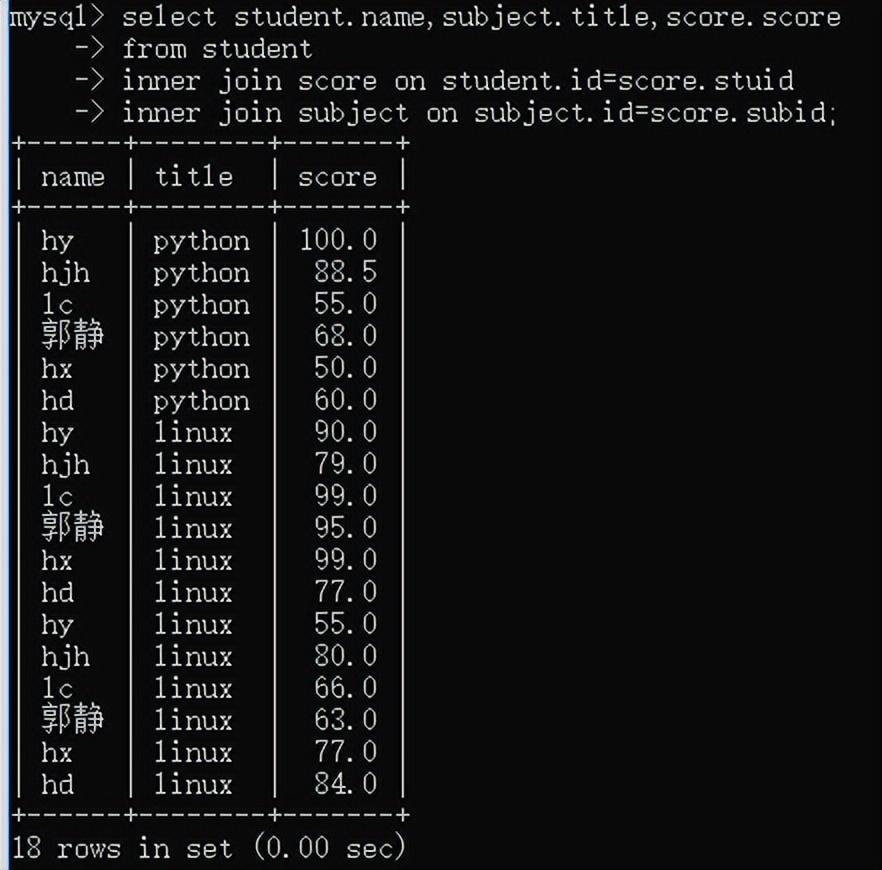
注意:inner语句后面没有逗号
当需要查询的数据来自两个表或者多个表时,需要使用连接查询。
连接查询分类:
内连接:表A inner join 表B:表A与表B匹配的结果会出现在结果集中
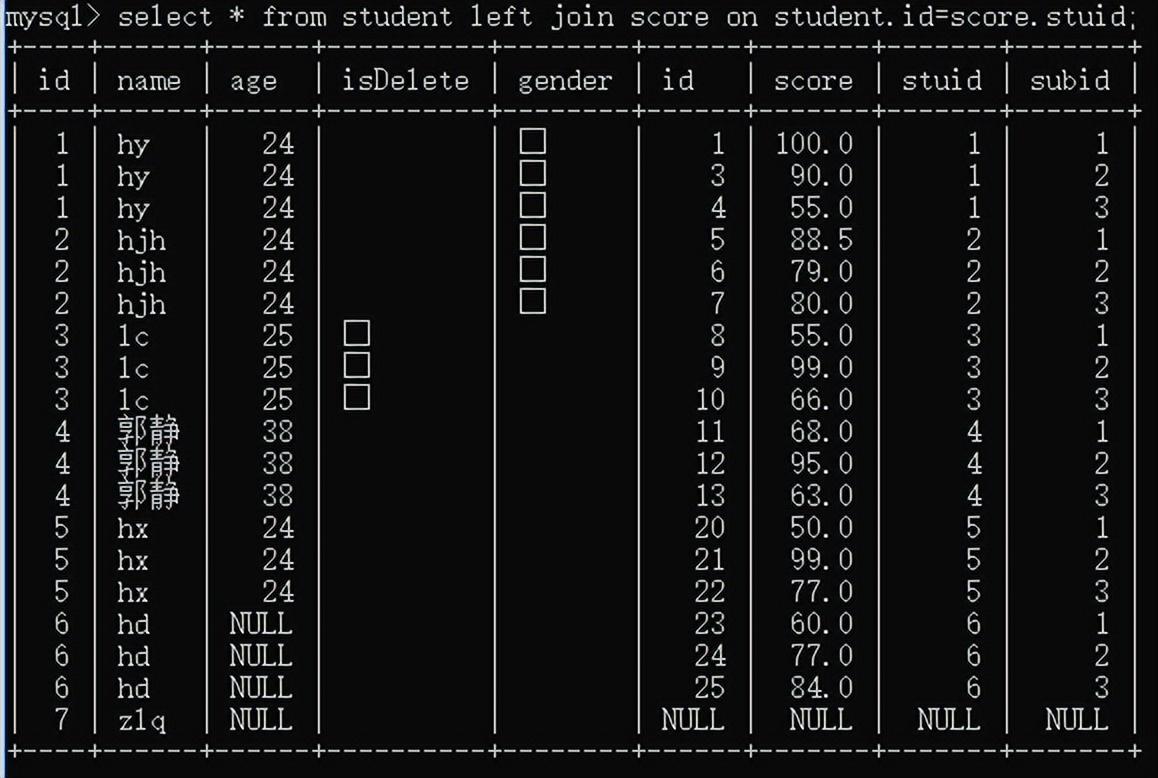
左外连接表:A left join 表B:表A与表B匹配的结果会出现在结果集中,外加表A独有的数据,未对应的数据用null填充
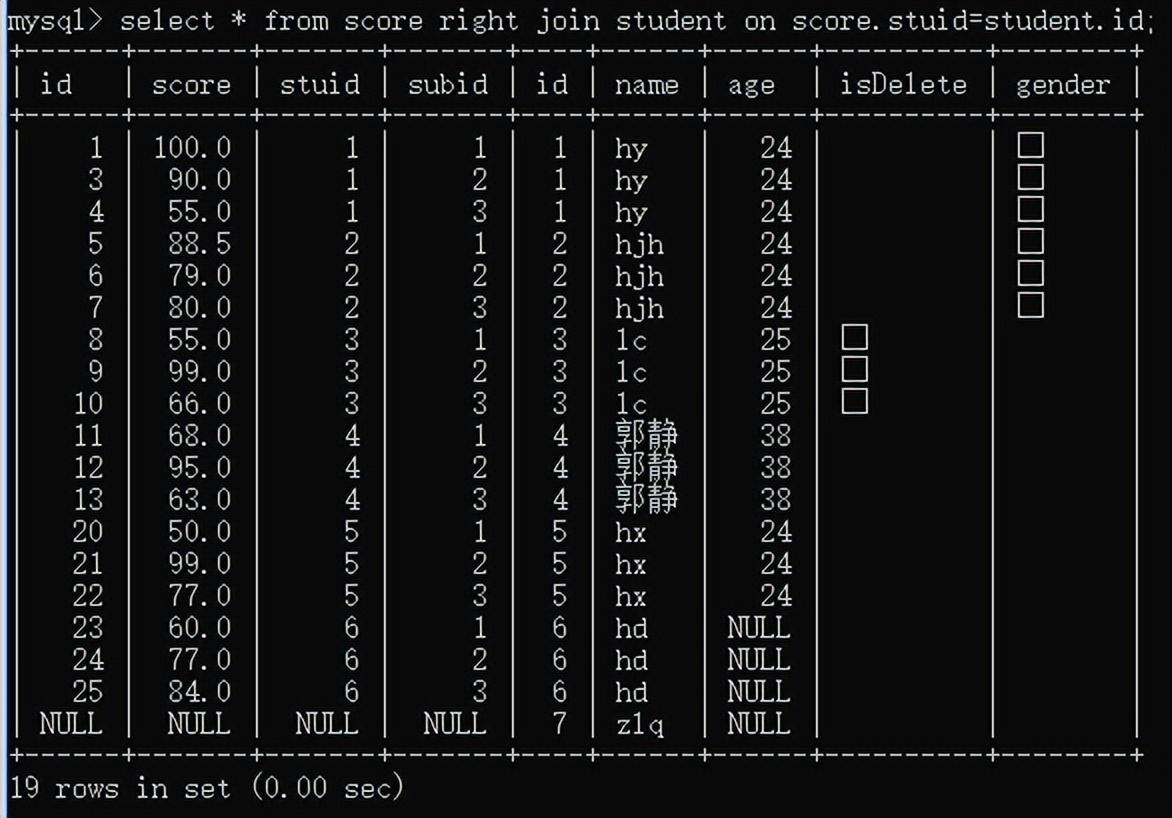
右外连接:表A right join 表B:表A与表B匹配的结果会出现在结果集中,外加表B独有的数据,为对应的用null填充
完全外连接:表A full join 表B:表A和表B匹配的结果会出现在结果集中,外加表A和表B独有的数据,为对应的数据用null填充。(mysql中不支持)
交叉连接(笛卡尔积):表A cross join 表B;
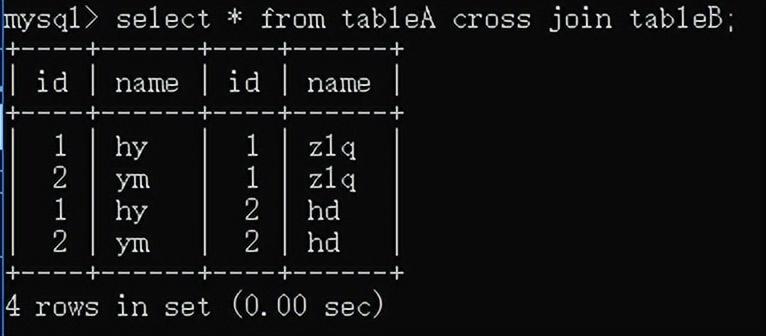

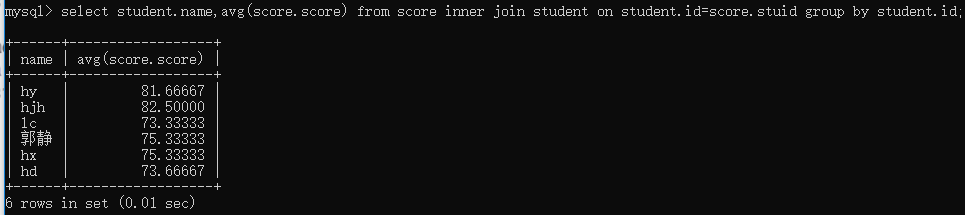
查询学生的平均成绩:

自关联
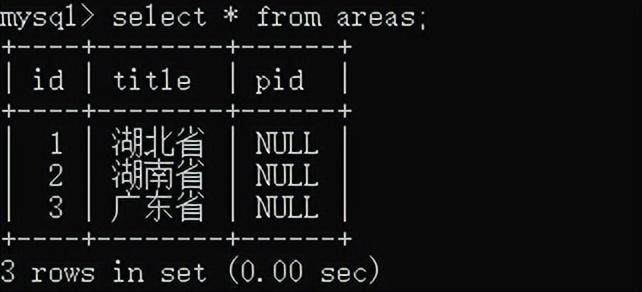
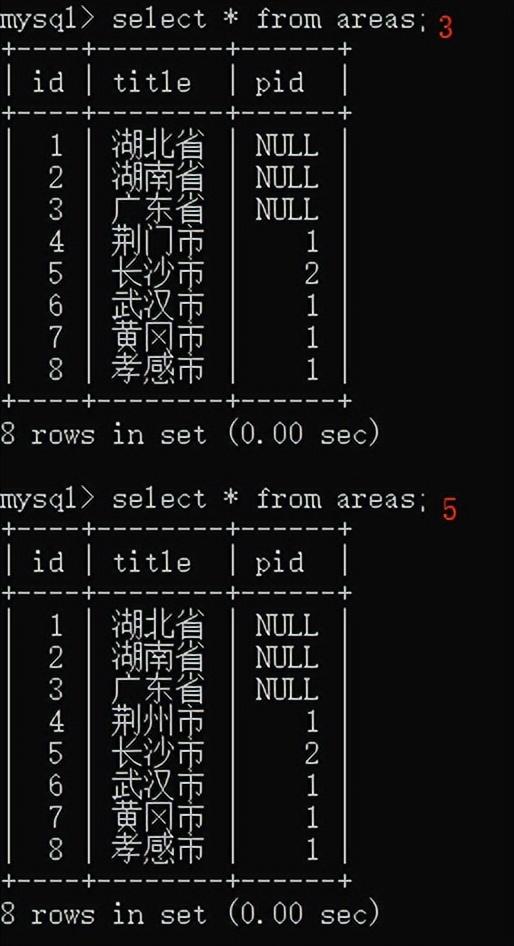
设计一个省表:
包括id,ptitle
设计一个市表:
包括id,ctitle,,proid
市表中的proid表示城市所属的省,对应着省表的id值
问题:能不能将两个表合并为一个表了?
定义一个areas表,结构如下:
id
atitle
pid
因为省没有所属了省份,所以可以填写为null
城市所属的省份pid,填写省对应的编号id
这就是自关联,表中的某一列,关联了这个表中的另一个列,但是它们的业务逻辑含义是不一样的。
在这个表中,结构不变,可以添加区县,乡镇等信息。
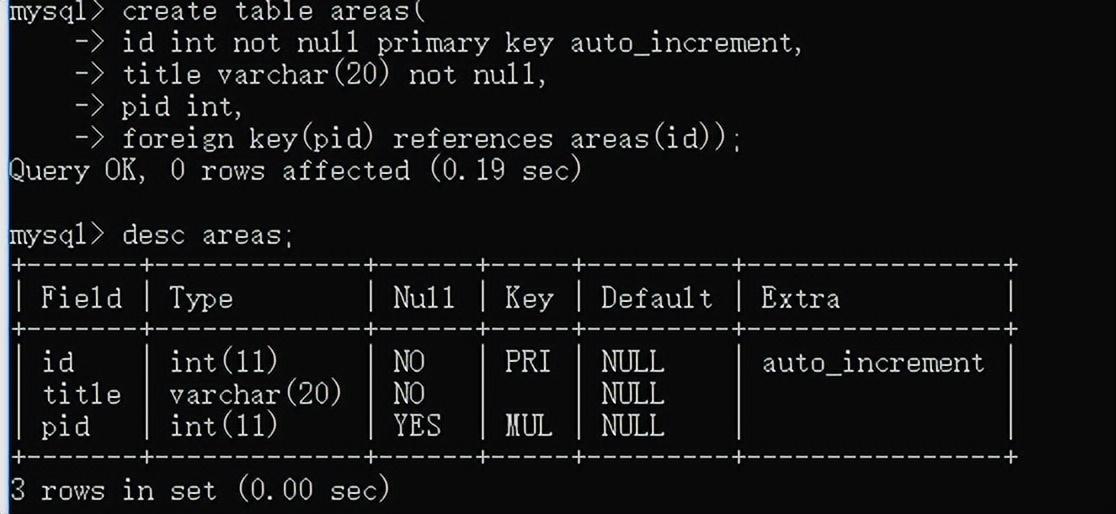
创建areas表的语句如下:
create table areas(
-> id int not null primary key auto_increment,
-> title varchar(20) not null,
-> pid int,
-> foreign key(pid) references areas(id));

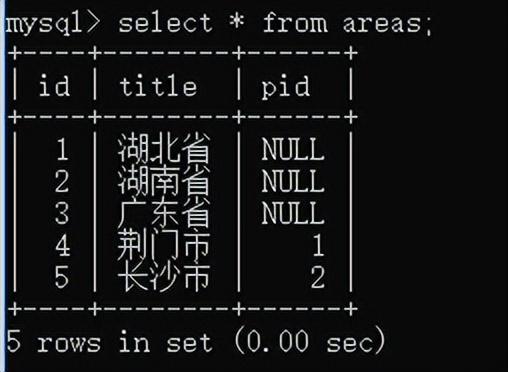
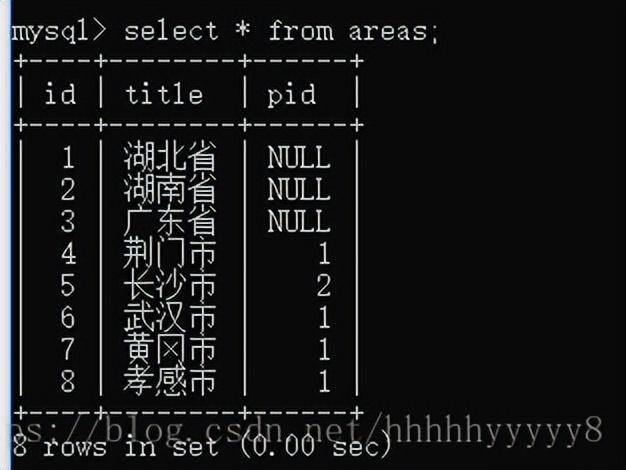
查询一共有多少个省:
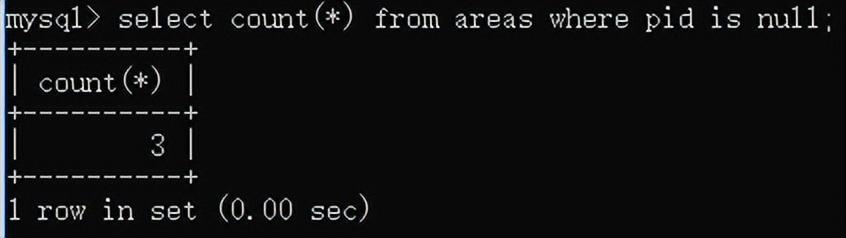
查询湖北省有哪些市:
1.嵌套查询,子查询
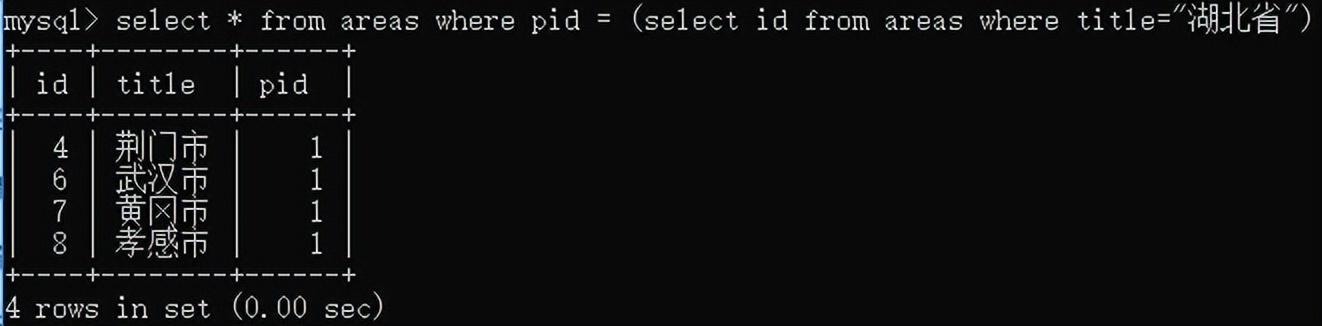
2.自关联查询
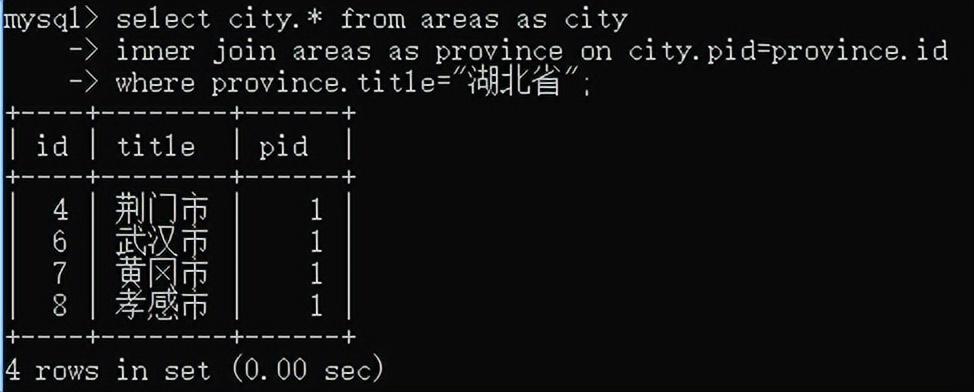
这里得给areas起别名,不然会报错

视图
对于复杂的查询,每次查询的时候都要敲一遍代码很麻烦,可以定义一个视图存储复杂的查询
视图本质就是对查询的一个封装
原始查询:
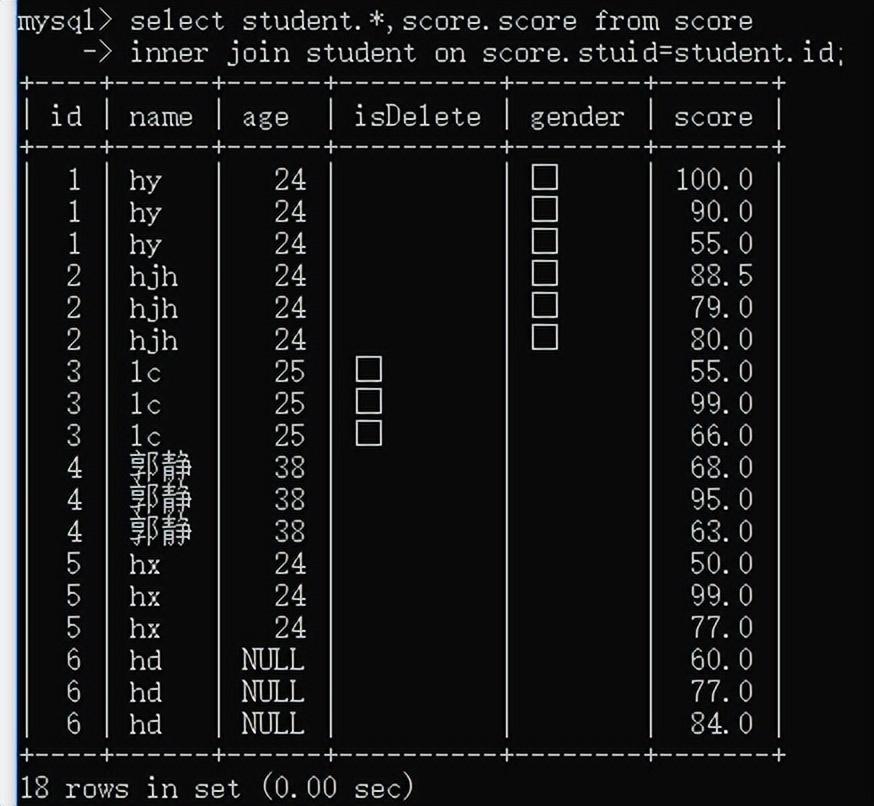
定义视图:
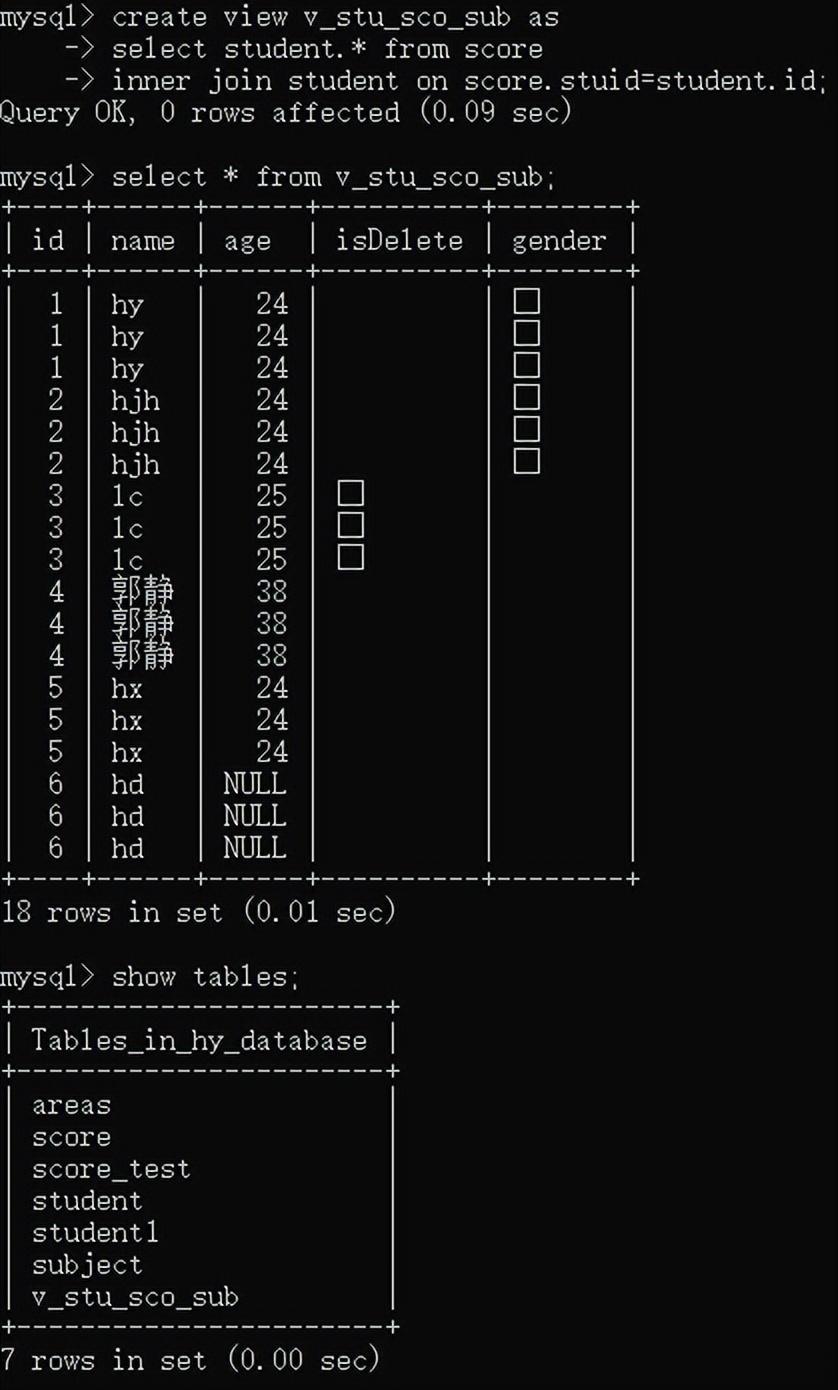
定义视图之后,视图也会当做一个表显示在表集合中,在创建视图的时候,一般在前面加上一个v。
视图中 不能有重复的字段,不然以后使用的时候就没法用了。这和直接查询显示结果不一样。

事务
ACID特性:
原子性:事务中的全部操作在数据库中是不可分割的,要么全部完成,要么都不做。
一致性:事物执行顺序不同时,结果得一致
隔离性:事务的执行不受其他事务的干扰,例如银行转账,A和B同时给C转账,加锁。
持久性:对于已提交的事务,系统必须保证该事务对数据库的改变不能丢失
要求:表的类型必须是innodb或bdb类型,才可以对此表使用事务
默认创建表的时候就是使用的innodb引擎,使用show create table 表名; 查看
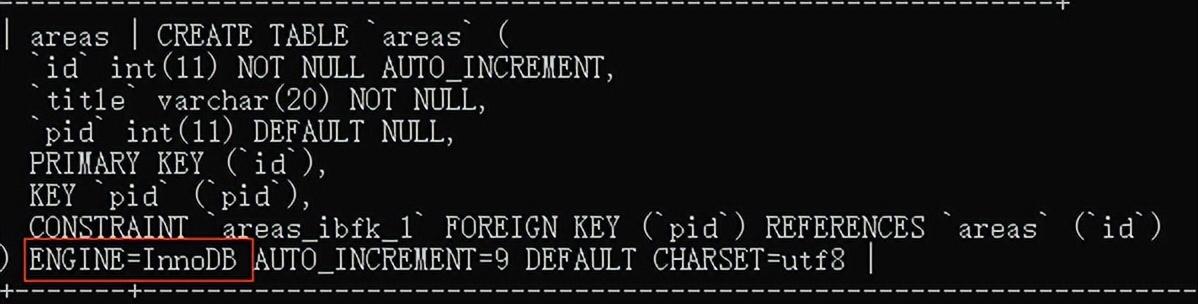
修改表的引擎


默认是innodb也不需要修改,但是修改为bdb时报错。
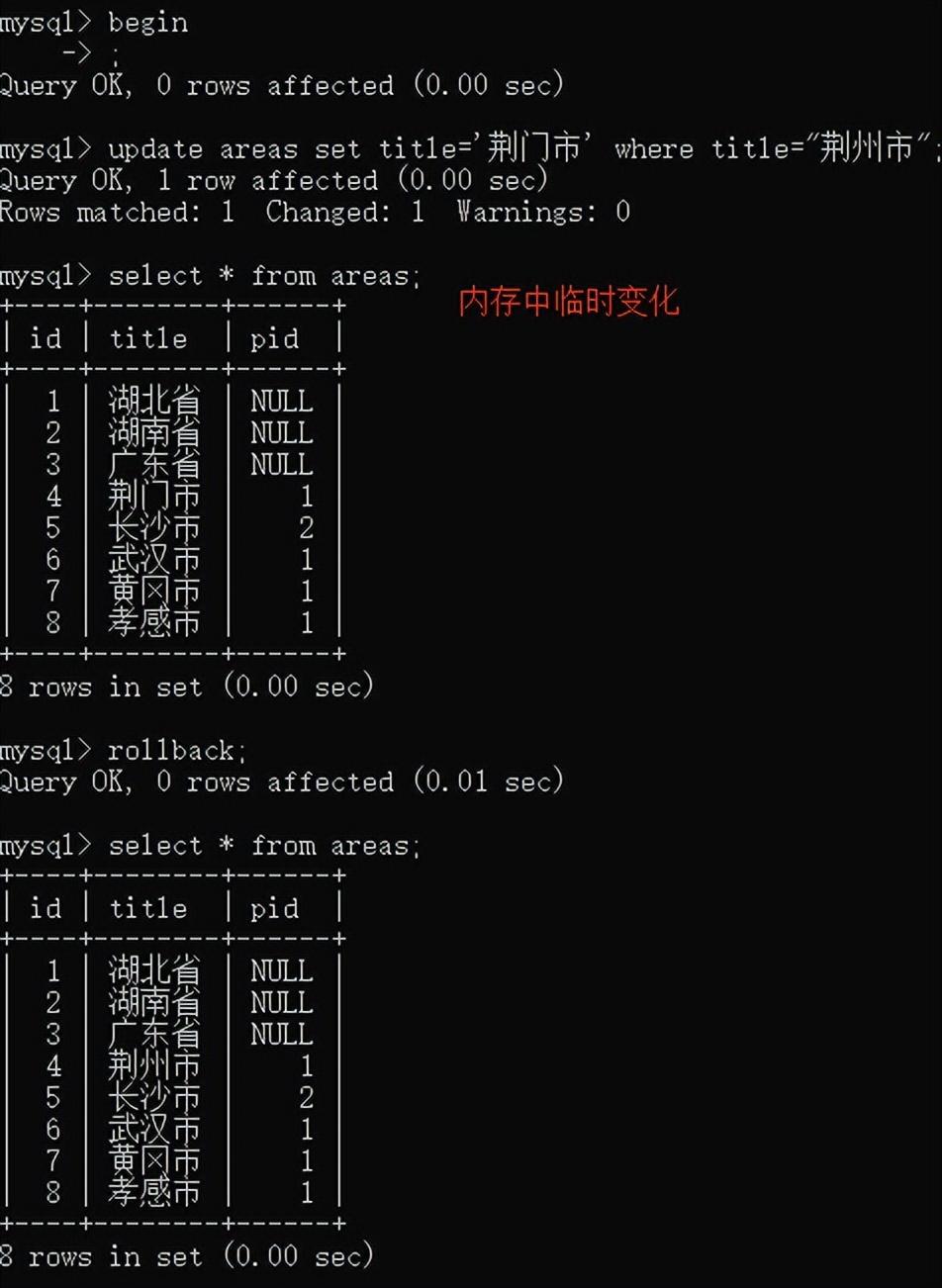
事务语句
开启:begin
提交:commit
回滚:rollback
使用事务的情况:当数据被更改时,包括insert,update,delete。

commit之后,begin后面的事务才生效
rollback会回滚begin后面的所有操作
练习:
终端1上,

终端2上
索引
一般的应用系统,读写比例在10:1左右,而且插入操作和更新操作很少出现性能问题,遇到最多的,也是最容易出现问题的,还是一些复杂的查询操作,所以查询语句的优化是重中之重。
当数据库中的数据量很大时,查询数据会变得很慢
索引能提高数据访问性能
主键和唯一索引,都是索引,可以提高查找速度
选择列的数据类型:
越小的数据类型通常更好,越小的数据类型通常在磁盘,内存和CPU缓存中都需要更少的空间,处理起来更快;
简单的数据类型更好:整形数据比起字符,处理开销更小,因为字符串的比较更复杂;
尽量避免null;应当制定列为not null,除非你想存储null。在mysql中,含有空值的列很难进行查询优化,应该用0,一个特殊的值或一个空字符串值。
索引分单列索引和组合索引
单列索引:即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引
组合索引:即一个索引包含多个值
查看索引:
show index from table_name;

创建索引:
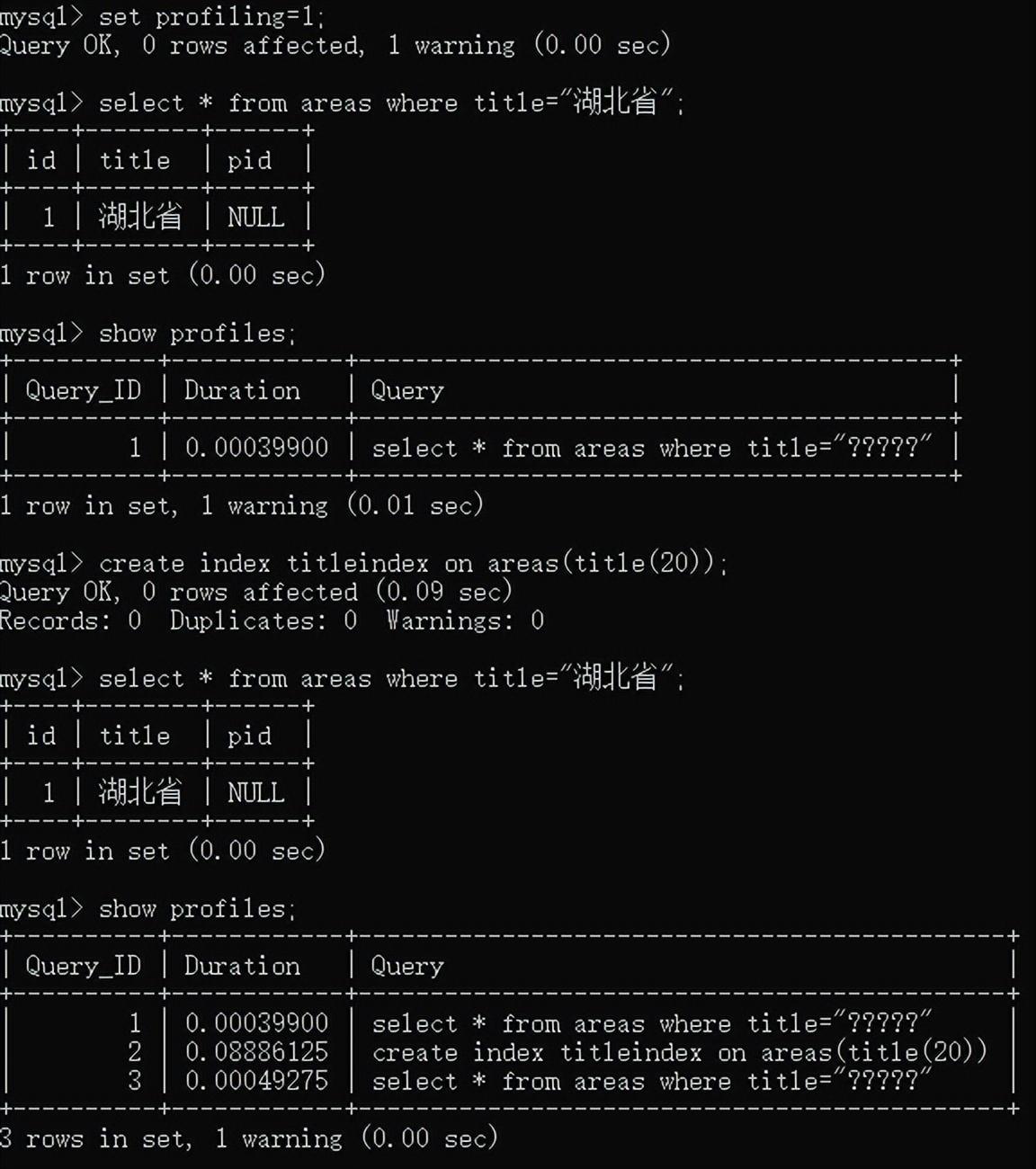
哈哈哈,这里查询的数据太少,创建索引反而话费的时间更久,不说说明什么,应该数据多的时候再试。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号