重磅新闻!OpenAI 发布 GPT-3.5 Turbo 微调,网友热议:减少 prompt 更划算
发表时间: 2023-08-25 10:46
作者 | 褚杏娟、核子可乐
当地时间 8 月 22 日,OpenAI 宣布企业现在可以使用自己的数据对 GPT-3.5 Turbo 进行微调,OpenAI 声称最终的定制模型可以赶上甚至超过 GPT-4 执行某些任务的能力。今年秋天 OpenAI 将开放更先进的 GPT-4。
该公司表示,此次更新将使开发人员能够自定义更适合实际用例的模型,并大规模运行这些自定义模型。OpenAI 强调,传入和传出微调 API 的数据归客户所有, OpenAI 或任何其他组织不会使用这些数据来训练其他模型。
OpenAI 此举似乎挽回了一些针对其开源的质疑,有网友评价称,“许多人支持开源人工智能,并批评 OpenAI 不够开放。但最重要的是,OpenAI 在不断创新。”
GPT-3.5 Turbo 是 OpenAI 推出的一种先进的语言模型,它能够准确理解并生成自然语言的文本。相比于之前的版本,GPT-3.5 Turbo 在多个方面有了极大的改进。比如,它具备更加出色的上下文理解能力,能够更好地理解用户的问题或指令,从而提供更准确的回答。它还能够产生更流畅、连贯的文本,仿佛是由人类写就的一样。最重要的是,GPT-3.5 Turbo 具备更快的响应速度,使得用户可以即时得到答案或帮助。
自 GPT-3.5 Turbo 发布以来,开发人员和企业纷纷要求开放模型自定义功能,以便为用户创造独特且差异化的体验。通过此次发布,开发人员现可运行监督微调,使得该模型在不同用例中表现更好。
微调的基本思想是,先在大规模文本数据上预训练一个大型的语言模型,例如 GPT-3.5,然后使用特定任务的数据集(如法律、医疗),进一步对模型进行训练,以适应特定的任务。在这个过程中,模型的参数会进行微小的调整,使其在特定业务场景上的性能更好。
在 OpenAI 的内部 beta 测试中,微调客户已经能够在各类常见用例中显著提高模型性能,例如:
除了提高性能之外,微调还能帮助企业缩短提示词长度,并保证性能基本不变。OpenAI 表示,GPT-3.5 Turbo 的微调可处理 4k 个 tokens——可达之前微调模型的 2 倍。早期测试人员还对模型本身的指令进行了微调,从而将提示词长度缩短达 90%,成功加快每次 API 调用的速度并降低了执行成本。
价格问题是开发者们普遍关注的问题之一。根据 OpenAI 说法,微调成本分为两个部分:初始训练成本与使用成本:
例如,一个 gpt-3.5-turbo 微调作业中包含 10 万个 token 的训练文件。经过 3 个 epoch 训练轮次,预计成本为 2.40 美元。
此前,OpenAI 宣布各初版 GPT-3 基础模型(ada、babbage、curie 和 davinci)将于 2024 年 1 月 4 日正式关闭。OpenAI 如今发布了 babbage-002 和 davinci-002 作为这些模型的替代方案,用户可将其用作基础模型或微调模型。这些模型可以使用新 API 端点/v1/fine_tuning/jobs 进行微调。下面是各基础/微调 GPT-3 模型的定价:
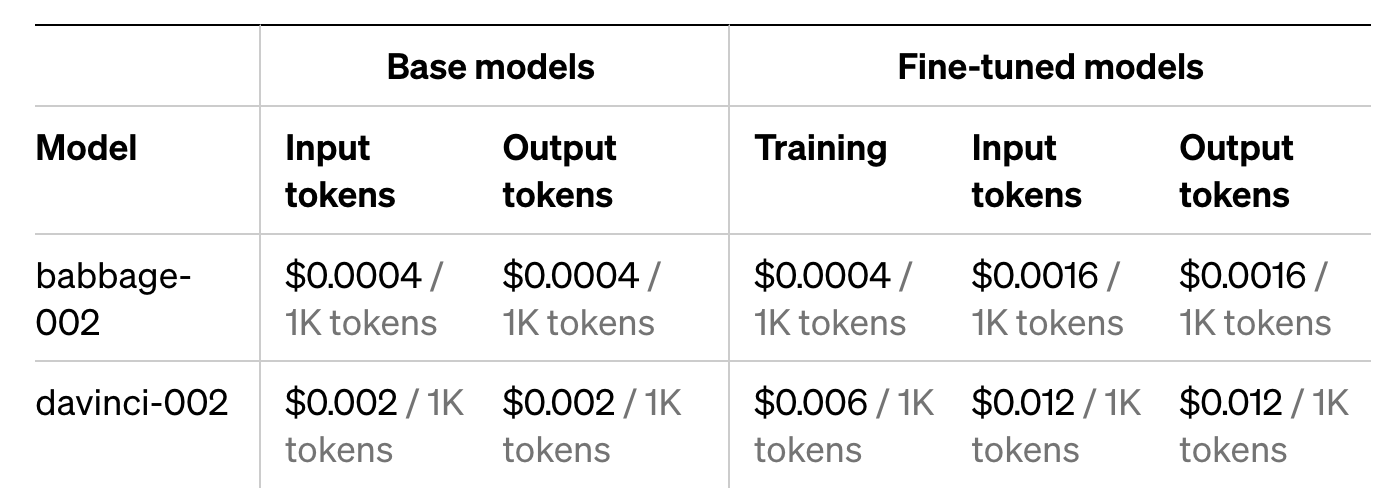
对此,有网友算了一笔账:微调的 GPT 3.5 Turbo 生成成本是基本模型生成成本的 8 倍,因此用户确实必须处于 OpenAI 提到的“将提示大小减少 90%”的范围内,才能从中获得成本效益。
微调定价,每 16 次用户交互的成本将超过 1 美元:16 次交互 *(0.012 美元*4 输入 + 0.016 美元输出)= 1.02 美元。
本质上,一个简短的提示,如“打个招呼”,比一个长提示“给黄鼠狼宠物起五个可爱的名字”要花费更少的钱。“要想对一个花费 8 倍以上的微调模型来获得纯粹的财务胜利,需要您将输入和输出提示的大小减少 8 倍或更多。”开发者 simonw 表示。有开发者猜测,这是由于 OpenAI 需要存储和加载模型,即使他们或许也在使用类似 LoRA 的方式来微调模型。
对此,也有网友表示,如果进行大量检索增强,那么 8 倍的成本可能仍然比在注入的上下文上消耗大量令牌便宜。
曾基于 OpenAI API 做过 GPT-3 开发的 drcode 分享称,GPT 的“微调”与 Llama2 之类的微调不同,因为它可能不会调整网络的所有权重,只是会调整网络的一小部分。代价是 OpenAI 微调的成本较低,但它的功能也没有“真正的”微调强大。
目前微调需要准备数据、上传必要的文件并通过 OpenAI 的 API 创建微调作业,步骤如下:
{ "messages": [ { "role": "system", "content": "You are an assistant that occasionally misspells words" }, { "role": "user", "content": "Tell me a story." }, { "role": "assistant", "content": "One day a student went to schoool." } ]}复制代码
curl -https://api.openai.com/v1/files \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "purpose=fine-tune" \ -F "file=@path_to_your_file" 复制代码
curl https://api.openai.com/v1/fine_tuning/jobs \-H "Content-Type: application/json" \-H "Authorization: Bearer $OPENAI_API_KEY" \-d '{ "training_file": "TRAINING_FILE_ID", "model": "gpt-3.5-turbo-0613",}'复制代码
在模型完成微调过程之后,可以立即在生产环境下使用,且具有与基础模型相同的共享速率限制。
curl https://api.openai.com/v1/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer $OPENAI_API_KEY" \-d '{ "model": "ft:gpt-3.5-turbo:org_id", "messages": [ { "role": "system", "content": "You are an assistant that occasionally misspells words" }, { "role": "user", "content": "Hello! What is fine-tuning?" } ]}'复制代码
该公司表示,所有微调数据都必须通过“审核”API 和 GPT-4 支持的审核系统,以查看是否与 OpenAI 的安全标准相冲突。OpenAI 还计划在未来推出一个微调 UI,其中包含一个仪表板,用于检查正在进行的微调工作负载的状态。
OpenAI 表示,在与其他技术(例如提示词工程、信息检索和函数调用)结合使用后,微调的潜力才能得到充分发挥。对函数调用和 gpt-3.5-turbo-16k 微调的支持也计划于今年秋季推出。
对于 OpenAI 开放 GPT-3.5 Turbo 微调,您有什么想法?欢迎在评论区发表您的观点!
参考链接:
https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates
https://news.ycombinator.com/item?id=37227139
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号