掌握SQLite事务模型:性能优化技巧与常见误区解析
发表时间: 2019-09-25 14:04
本文主要介绍sqlite的事务模型,以及基于事务模型的一些性能优化tips,包括事务封装、WAL+读写分离、分库分表、page size优化等。并基于手淘sqlite的使用现状总结了部分常见问题及误区,主要集中在多线程的设置、多线程下性能优化的误区等。本文先提出以下几个问题(作者在进行统一存储的关系存储框架优化过程中一直困惑的问题,同时也是客户端开发者经常搞错的问题)并在正文中进行解答:
在深入了解sqlite之前,最好先对sqlite的主要数据结构有个概要的理解,sqlite是一个非常完备的关系数据库系统,由很多部分组成(parser,tokenize,virtual machine等等),同时sqlite的事务模型相对简化,是入门学习关系数据库方法论的一个不错的选择;下文对事务模型的分析也基于这些核心数据结构。下面这张图比较准确的描述了sqlite的几个核心数据结构:
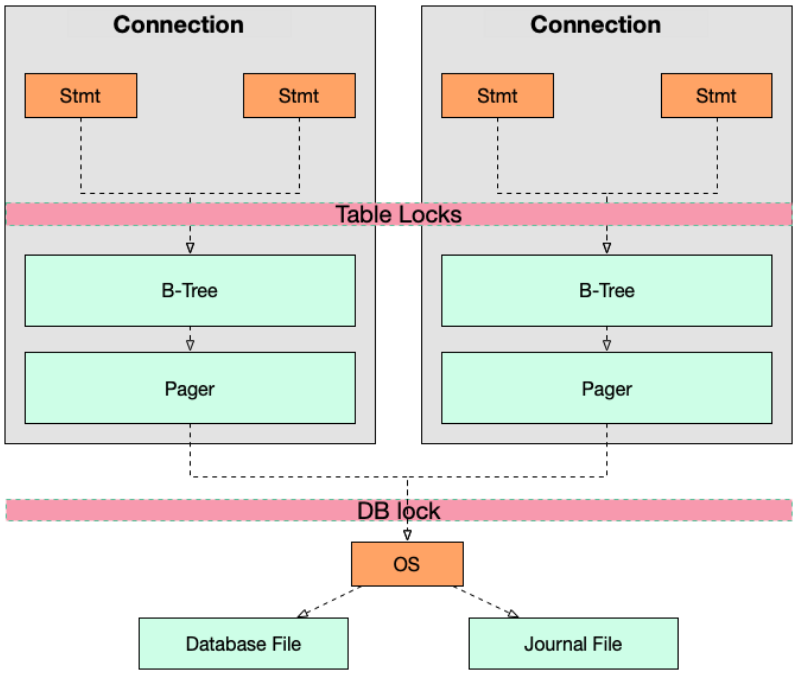
1.1 Connection
connection通过sqlite3_open函数打开,代表一个独立的事务环境(这里及下文提到的事务,包括显式声明的事务,也包括隐式的事务,即每条独立的sql语句)
1.2 B-Tree
B-Tree负责请求pager从disk读取数据,然后把页面(page)加载到页面缓冲区(page cache)
1.3 Pager
Pager负责读写数据库,管理内存缓存和页面(即下文提到的page caches),以及管理事务,锁和崩溃恢复
2.1 sqlite多进程安全及Linux & windows文件锁
2.1.1 结论
sqlite的文件锁在linux/posix上基于记录锁实现,也就是说sqlite在文件锁上会有以下几个特点:
2.2 事务模型(Without WAL)
sqlite对每个连接设计了五钟锁的状态(UNLOCKED, PENDING, SHARED, RESERVED, EXCLUSIVE), sqlite的事务模型中通过锁的状态保证读写事务(包括显式的事务和隐式的事务)的一致性和读写安全。sqlite官方提供的事务生命周期如下图所示,我在这里稍微加了一些个人的理解:
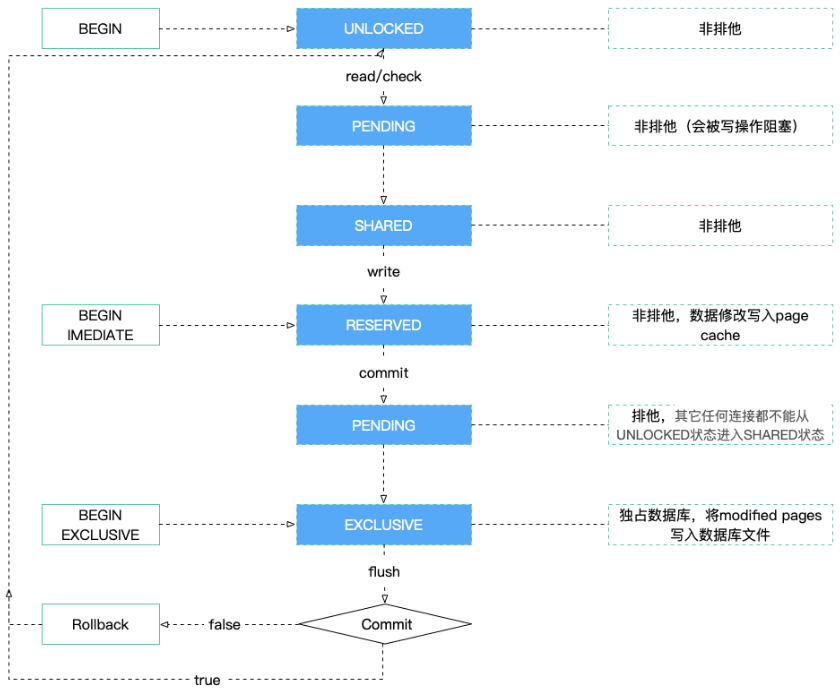
这里有几点需要注意:
2.2.1 结论

2.3 WAL对事务模型的影响
按照官方文档,WAL的原理如下:
对数据库修改是是写入到WAL文件里的,这些写是可以并发的(WAL文件锁)。所以并不会阻塞其语句读原始的数据库文件。当WAL文件到达一定的量级时(CheckPoint),自动把WAL文件的内容写入到数据库文件中。当一个连接尝试读数据库的时候,首先记录下来当前WAL文件的末尾 end mark,然后,先尝试在WAL文件里查找对应的Page,通过WAL-Index来对查找加速(放在共享内存里,.shm文件),如果找不到再查找数据库文件。
这里结合源码,有下面几个理解:
2.3.1 结论
2.4 多线程设置
// 多线程的设置的实现:设置bCoreMutex和bFullMutex#if defined(SQLITE_THREADSAFE) && SQLITE_THREADSAFE>0 /* IMP: R-54466-46756 */ case SQLITE_CONFIG_SINGLETHREAD: { /* EVIDENCE-OF: R-02748-19096 This option sets the threading mode to ** Single-thread. */ sqlite3GlobalConfig.bCoreMutex = 0; /* Disable mutex on core */ sqlite3GlobalConfig.bFullMutex = 0; /* Disable mutex on connections */ break; }#endif#if defined(SQLITE_THREADSAFE) && SQLITE_THREADSAFE>0 /* IMP: R-20520-54086 */ case SQLITE_CONFIG_MULTITHREAD: { /* EVIDENCE-OF: R-14374-42468 This option sets the threading mode to ** Multi-thread. */ sqlite3GlobalConfig.bCoreMutex = 1; /* Enable mutex on core */ sqlite3GlobalConfig.bFullMutex = 0; /* Disable mutex on connections */ break; }#endif#if defined(SQLITE_THREADSAFE) && SQLITE_THREADSAFE>0 /* IMP: R-59593-21810 */ case SQLITE_CONFIG_SERIALIZED: { /* EVIDENCE-OF: R-41220-51800 This option sets the threading mode to ** Serialized. */ sqlite3GlobalConfig.bCoreMutex = 1; /* Enable mutex on core */ sqlite3GlobalConfig.bFullMutex = 1; /* Enable mutex on connections */ break; }#endifif( isThreadsafe ){ // bFullMutex = 1 db->mutex = sqlite3MutexAlloc(SQLITE_MUTEX_RECURSIVE); // 每个数据库连接会初始化一个成员锁 if( db->mutex==0 ){ sqlite3_free(db); db = 0; goto opendb_out; } }/* If the xMutexAlloc method has not been set, then the user did not ** install a mutex implementation via sqlite3_config() prior to ** sqlite3_initialize() being called. This block copies pointers to ** the default implementation into the sqlite3GlobalConfig structure. */ sqlite3_mutex_methods const *pFrom; sqlite3_mutex_methods *pTo = &sqlite3GlobalConfig.mutex; if( sqlite3GlobalConfig.bCoreMutex ){ pFrom = sqlite3DefaultMutex(); }else{ pFrom = sqlite3NoopMutex(); } pTo->xMutexInit = pFrom->xMutexInit; pTo->xMutexEnd = pFrom->xMutexEnd; pTo->xMutexFree = pFrom->xMutexFree; pTo->xMutexEnter = pFrom->xMutexEnter; pTo->xMutexTry = pFrom->xMutexTry; pTo->xMutexLeave = pFrom->xMutexLeave; pTo->xMutexHeld = pFrom->xMutexHeld; pTo->xMutexNotheld = pFrom->xMutexNotheld; sqlite3MemoryBarrier(); pTo->xMutexAlloc = pFrom->xMutexAlloc;sqlite3_mutex_methods const *sqlite3NoopMutex(void){ static const sqlite3_mutex_methods sMutex = { noopMutexInit, noopMutexEnd, noopMutexAlloc, noopMutexFree, noopMutexEnter, noopMutexTry, noopMutexLeave, 0, 0, }; return &sMutex;}// CoreMutext未打开的话,对应使用的锁函数均为空实现static int noopMutexInit(void){ return SQLITE_OK; }static int noopMutexEnd(void){ return SQLITE_OK; }static sqlite3_mutex *noopMutexAlloc(int id){ UNUSED_PARAMETER(id); return (sqlite3_mutex*)8; }static void noopMutexFree(sqlite3_mutex *p){ UNUSED_PARAMETER(p); return; }static void noopMutexEnter(sqlite3_mutex *p){ UNUSED_PARAMETER(p); return; }static int noopMutexTry(sqlite3_mutex *p){ UNUSED_PARAMETER(p); return SQLITE_OK;}static void noopMutexLeave(sqlite3_mutex *p){ UNUSED_PARAMETER(p); return; }粗略看了一下,通过db->mutex(sqlite3_mutex_enter(db->mutex);)保护的逻辑块和函数主要如下列表:
sqlite3_db_status、sqlite3_finalize、sqlite3_reset、sqlite3_step、sqlite3_exec、sqlite3_preppare_v2、column_name、blob操作、sqlite3Close、sqlite3_errmsg...
基本覆盖了所有的读、写、DDL、DML,也包括prepared statement操作;也就是说,在未打开FullMutex的情况下,在一个连接上的所有DB操作必须严格串行执行,包括只读操作。
sqlite3中的mutex操作函数,除了用于操作db->mutex这个成员之外,还主要用于以下逻辑块(主要是影响数据库所有连接的逻辑):
shm操作(index for wal)、内存池操作、内存缓存操作等
2.4.1 结论
3.1 合理使用事务
由#2.2的分析可知,写操作会在RESERVED状态下将数据更改、b-tree的更改、日志等写入page cache,并最终flush到数据库文件中;使用事务的话,只需要一次对DB文件的flush操作,同时也不会对其他连接的读写操作阻塞;对比以下两种数据写入方式(这里以统一存储提供的API为例),实测耗时有十几倍的差距(当然对于频繁的读操作,使用事务可以减事务状态的切换,也会有一点点性能提升):
// batch insert in transaction with 1000000 records//AliDBExecResult* execResult = NULL;_database->InTransaction([&]() -> bool { // in transaction auto statement = _database->PrepareStatement("INSERT INTO table VALUES(?, ?)"); for (auto record : records) { // bind 1000000 records // bind record ... ... statement->AddBatch(); } auto result = statement->ExecuteUpdate(); return result->is_success_;});// batch insert with 1000000 records, no transaction//auto statement = _database->PrepareStatement("INSERT INTO table VALUES(?, ?)");for (auto record : records) { // bind 1000000 records // bind record ... ... statement->ExecuteUpdate();}3.2 启用WAL + 读写(连接)分离
启用WAL之后,数据库大部分写操作变成了串行写(对WAL文件的串行操作),对写入性能提升有非常大的帮助;同时读写操作可以互相完全不阻塞(如#2.3所述)。上述两点比较好的解释了启用WAL带来的提升;同时推荐一个写连接 + 多个读连接的模型,如下图所示:
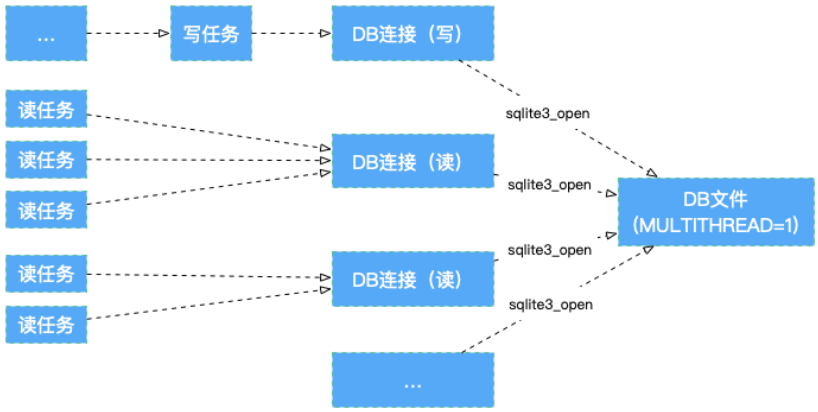
3.2.1 读写连接分离的细节
// two transactions: void Transaction_1() { connection_->Exec("BEGIN"); connection_->Exec("insert into table(value) values('xxxx')"); connection_->Exec("COMMIT");}void Transaction_2() { connection_->Exec("BEGIN"); connection_->Exec("insert into table(value) values('xxxx')"); connection_->Exec("COMMIT");}// code fragment 1: concurrent transactionthread1.RunBlock([]() -> void { for (int i=0; i< 100000; i++) { Transaction_1(); }});thread2.RunBlock([]() -> void { for (int i=0; i< 100000; i++) { Transaction_2(); }});thread1.Join(); thread2.join();// code fragment 2: serial transactionfor (int i=0; i< 100000; i++) { Transaction_1();}for (int i=0; i< 100000; i++) { Transaction_2();}3.3 针对具体业务场景,设置合适的WAL SIZE
如#2.3提到,过大的WAL文件,会让查找操作从B-Tree查找退化成线性查找(WAL中page连续存储);但大的WAL文件对写操作较友好。对于大记录的写入操作,较大的wal size会有效提高写入效率,同时不会影响查询效率
3.4 针对业务场景分库分表
分库分表可以有效提高数据操作的并发度;但同时过多的表会影响数据库文件的加载速度。现在数据库方向的很多研究包括Auto sharding, paxos consensus, 存储和计算的分离等;Auto
application-awared optimization,Auto hardware-awared optimization,machine
learning based optimization也是不错的方向。
3.5 其他
包括WAL checkpoint策略、WAL size优化、page size优化等,均需要根据具体的业务场景设置。
4.1 线程安全设置及误区
4.1.1 误区一:多线程模式是线程安全的
产生这个误区主的主要原因是官方文档里的最后一句话:
SQLite will be safe to use in a multi-threaded environment as long as no two threads attempt to use the same database connection at the same time.
但大家往往忽略了前面的一句话:
it disables mutexing on database connection and prepared statement objects
即对于单个连接的读、写操作,包括创建出来的prepared statement操作,都没有线程安全的保护。也即在多线程模式下,对单个连接的操作,仍需要在业务层进行锁保护。
4.1.2 误区二:多线程模式下,并发读操作是安全的
关于这一点,#2.4给出了具体的解释;多线程模式下(SQLITE_CONFIG_MULTITHREAD)对prepared statement、connection的操作都不是线程安全的
4.1.3 误区三:串行模式下,所有数据库操作都是串行执行
这个问题比较笼统;即使在串行模式下,所有的数据库操作仍需遵循事务模型;而事务模型已经将数据库操作的锁进行了非常细粒度的分离,串行模式的锁也是在上层保证了事务模型的完整性
4.1.4 误区四:多线程模式性能最好,串行模式性能差
多线程模式下,仍需要业务上层进行锁保护,串行模式则是在sqlite内部进行了锁保护;认为多线程模式性能好的兄弟哪来的自信认为业务层的锁实现比sqlite内部锁实现性能更高?
作者:hamsongliu
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号