异步流复制:实现Postgresql数据库的高可用性
发表时间: 2021-01-24 18:03
文章开始之前,我们首先得明确几个问题:
问题1:什么是数据库高可用(high availability)
问题2:数据库高可用是必须的吗
问题3:PG的高可用是啥子模样
首先理一理高可用。如图所示,来自维基百科的释义:高可用性,IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。
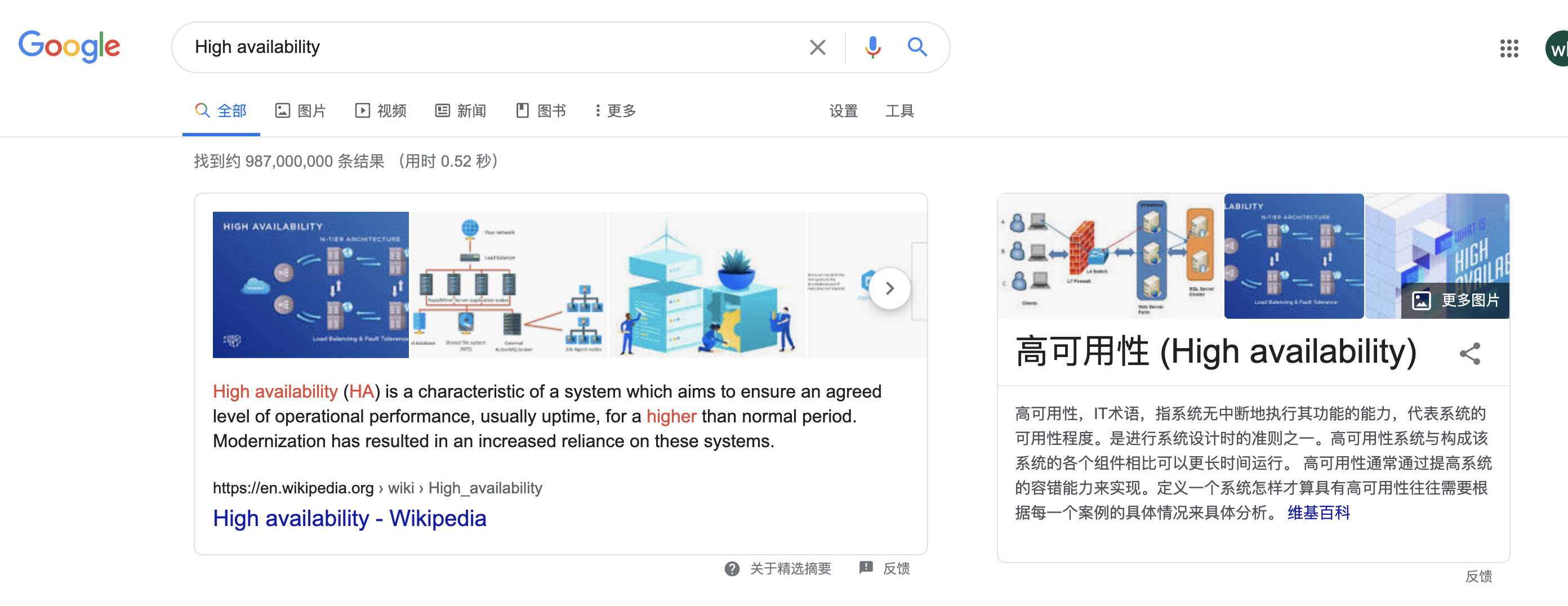
HA释义
简单来说,高可用就是当某一个服务(比如服务器)挂掉了,对外提供的服务不能中断。一般是由众多服务节点构成一个服务集群。普通用户是感知不到服务发生了中断。
那数据库需要高可用吗?当然是需要的,数据库也是重要的服务之一,虽然它不是直接对外服务。试想一下,如果只有一个数据库,达不到高可用状态,发生意外挂掉了,那么所有服务都不能使用了。比如头条或微博的数据库挂了,那么我们就不能愉快地吃瓜玩耍了。所以,数据库高可用是必须的。
作为大名鼎鼎的开源数据库,postgresql又是怎么做到高可用呢。我们直接使用搜索引擎搜索一下。ps:关于技术查找,国内各种论坛是一锅炖,建议直接使用官网。
搜索结果

pg ha
可见pg官方有自己的高可用解决方案。pg要怎么解决高可用呢?
1)数据库集群,并保证数据一致性。
2)管理数据库集群,比如故障转移。
本文先学习PG数据库集群。数据库集群一般是主从模式,即是一个master,多个slave。主从的数据是一样的。这样同样可以做到读写分离。关于读写分离,暂时按下不表,后面专门写。pg有个Streaming Replication,即流复制。流复制是使用WAL(预读写日志文件)从主库传输到从库实现的。
复制方式分为同步流复制和异步流复制。同步流复制,主库需要等从库写完才能释放锁,因而对大量数据写入等情况不适合,另外从库挂掉了也会导致主库写入数据失败。而异步流复制则没有上述问题。延迟通常也不会太多,网络良好的情况,一般不会超过1秒。
下面开始搭建两个数据库分别作为主库和从库,演示下配置异步流复制。
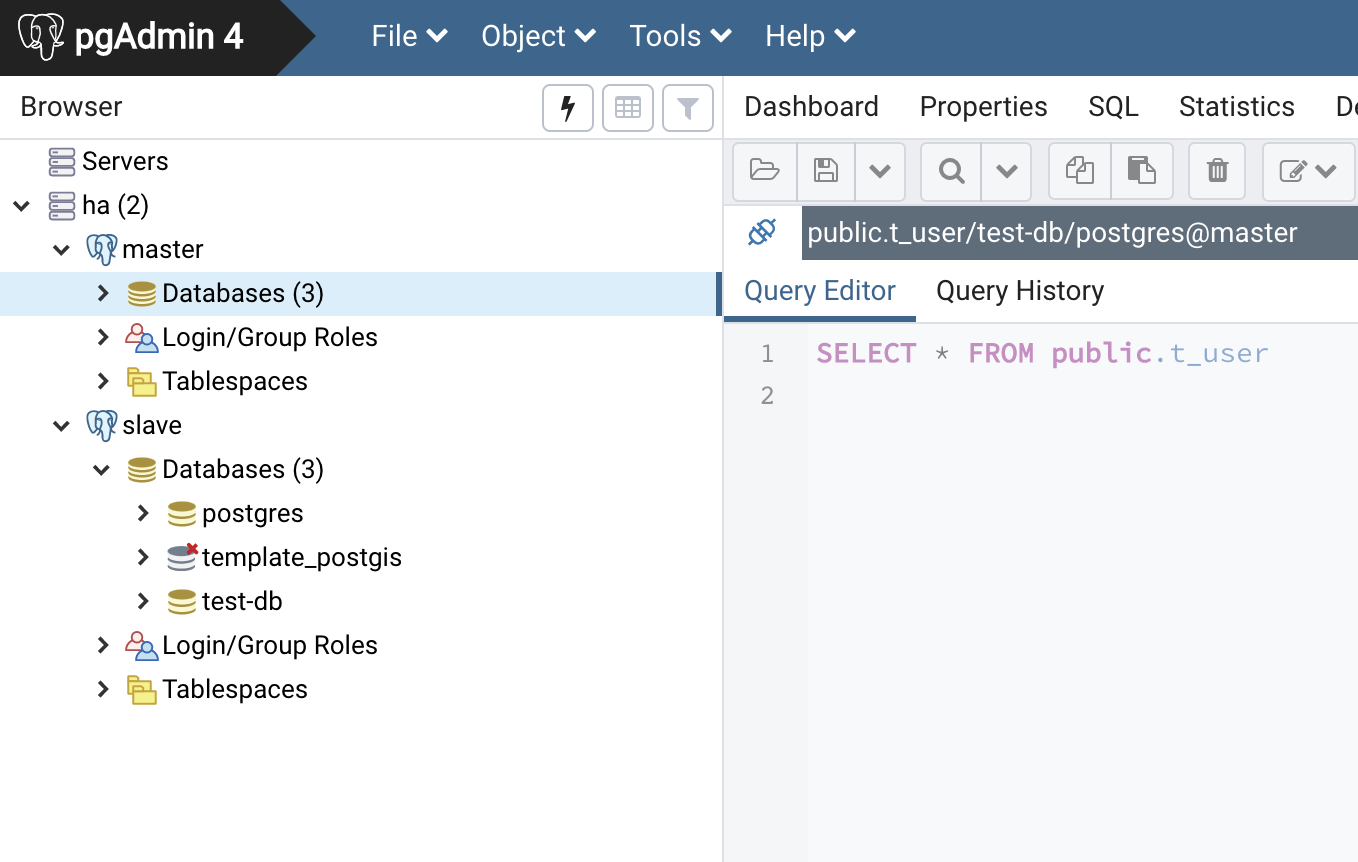
pg db
上图是用docker快速搭建的两个数据库。首先配置下主库:
1)修改 pg_hba.conf,允许从库从不同网络连接和复制
# allow replicationhost replication all 0.0.0.0/0 md52)修改 postgresql.conf,开启流复制模式
listen_addresses = '*'wal_level = replicamax_wal_senders = 8 以上配置完成后需要重启下数据库。
接下来,配置下从库:
1)从主库获取现有的数据到从库
# pg_basebackup -h [ip] -U [username] -p [port] -F p -P -R -D [pgdata file path]pg_basebackup -h 192.168.0.101 -U postgres -p 15446 -F p -P -R -D /home/master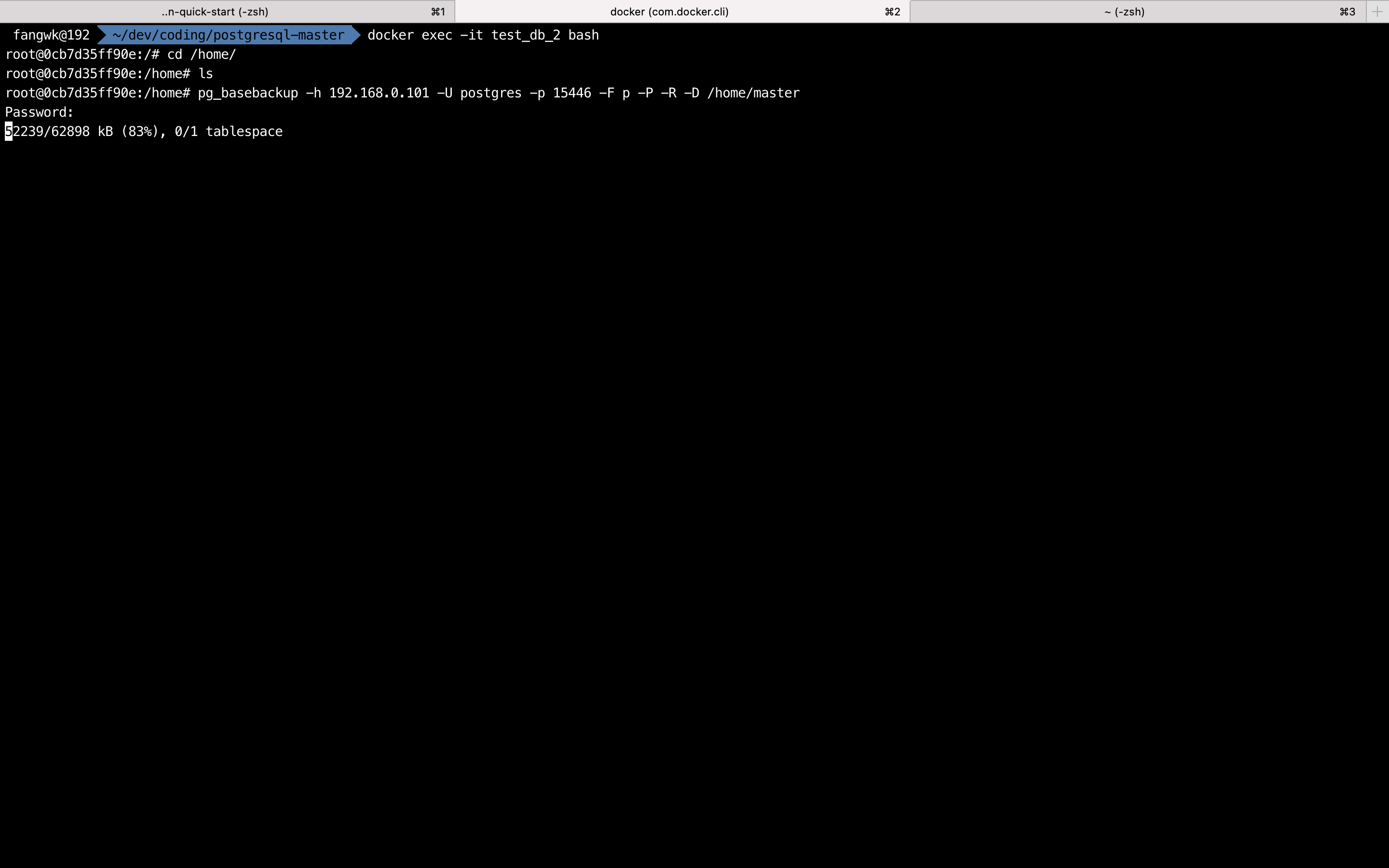
2)拷贝到从库pg的data目录
cp -r /home/master/* /var/lib/postgresql/data/3)赋予权限
chown -R postgres:postgres /var/lib/postgresql/data/4) 修改postgresql.conf
hot_standby = on以上配置完成后需要重启下数据库。
我们可以看到从库的数据和主库的数据是一样的。
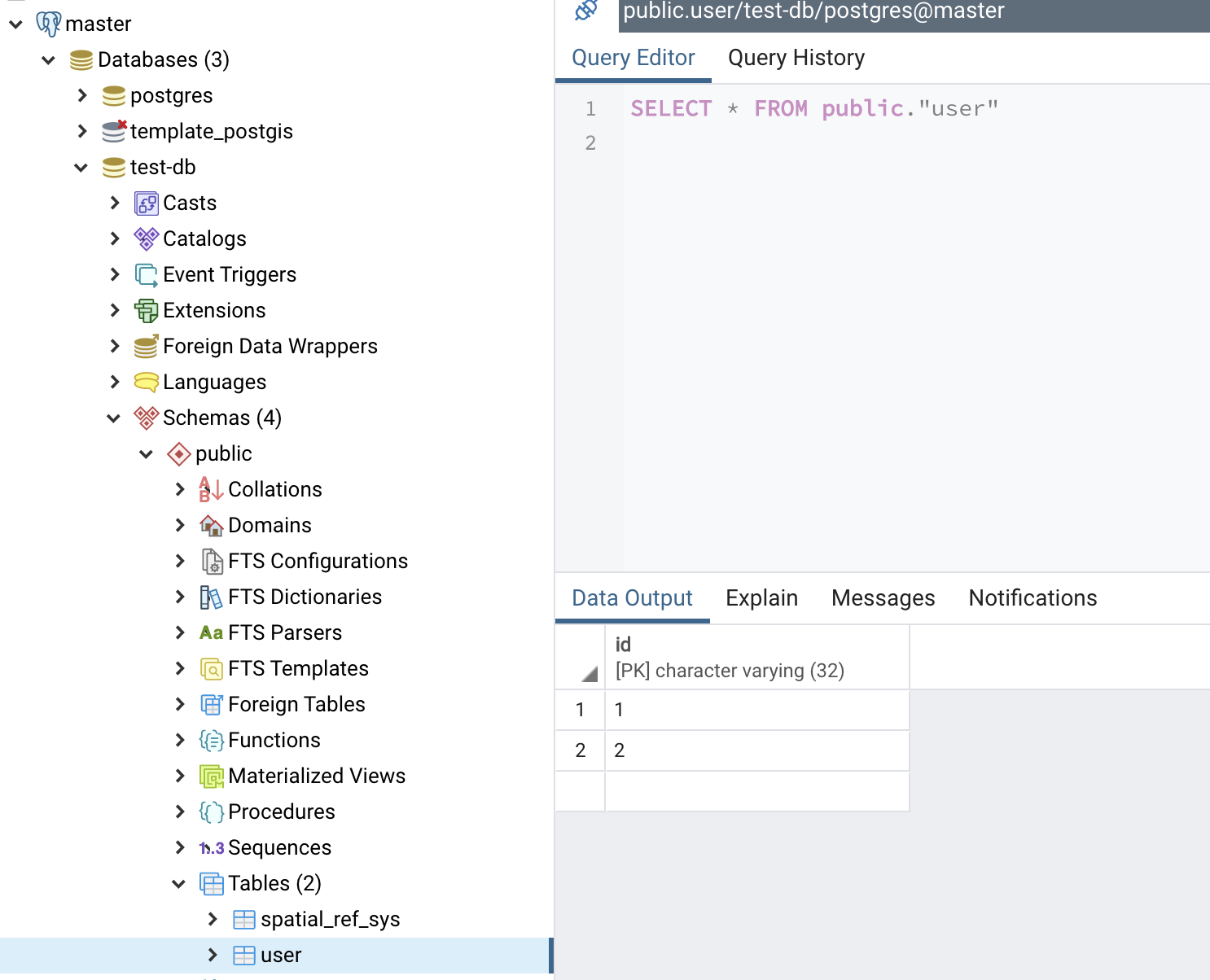
主库user表
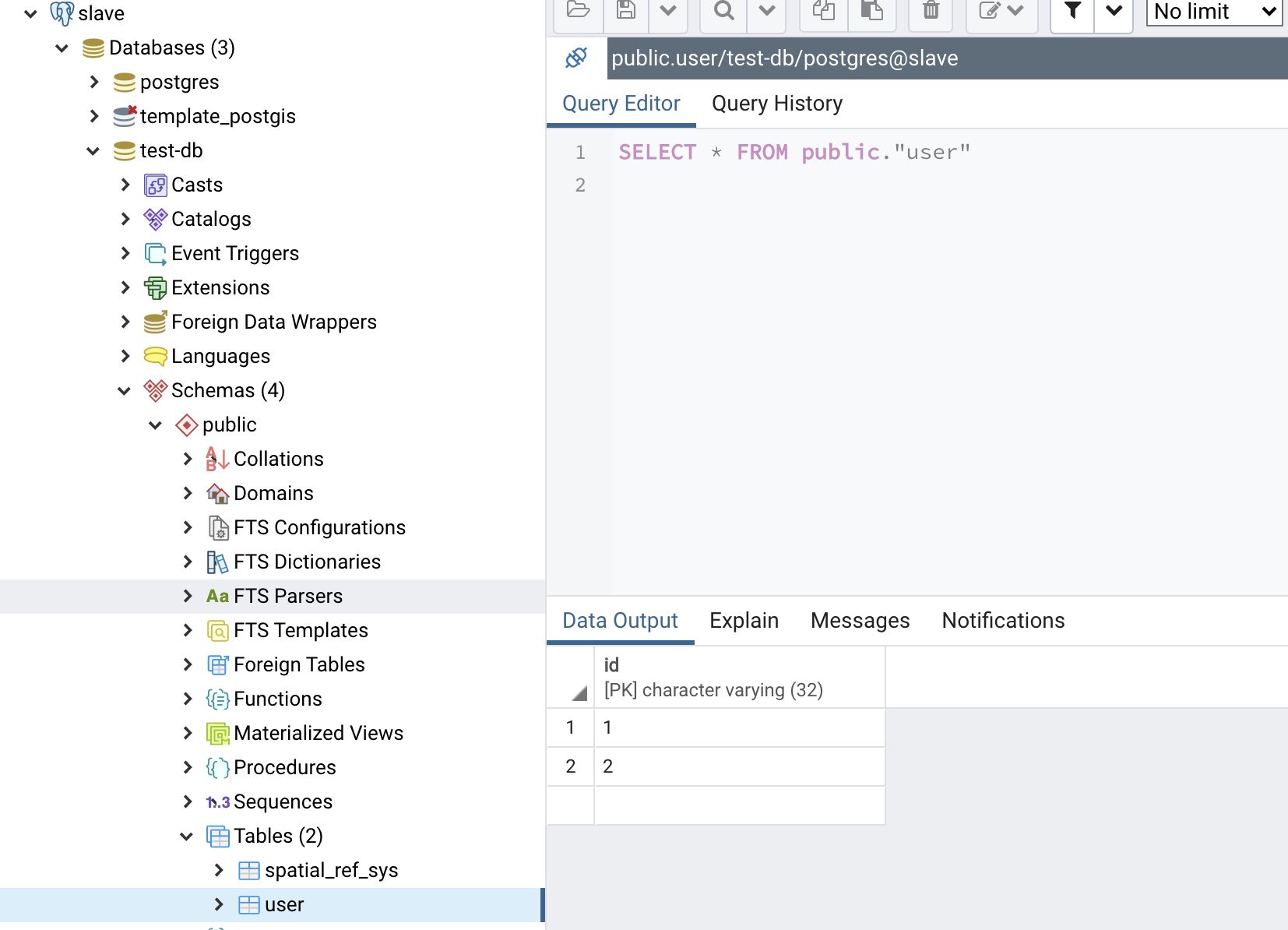
从库user表
我们新增下主库的数据,发现从库也同步了。

主库新增记录

从库同步成功
至此,pg的异步流复制已完成。下一篇,我们将继续介绍和学习pg高可用的其它内容,敬请期待。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号