Llama 3.1全新发布:参数模型开源革新引领科技风潮
发表时间: 2024-07-24 07:33
文|邓咏仪 周鑫雨
编辑|苏建勋
GPT-4o的王座还没坐热乎,小扎率领开源大军火速赶到——
如此前传闻一样,美国太平洋时间7月23日,Meta正式发布Llama 3.1。这是如今开源领域使用者最广泛,性能最顶级的大模型系列。
无独有偶,发布前一天,Llama 3.1又在开发者社区中“惨遭泄露”,除了模型信息外,还包括405B模型的磁力链接,开发者们已经玩儿得热火朝天。
Llama 3.1正式发布的信息,也和爆料别无二致:共有8B、70B 和 405B 三个尺寸,上下文长度都提升到了128K。
根据Meta提供的基准测试数据,最受关注的405B(4050亿参数),从性能上已经可媲美GPT-4和Claude 3.5。

△与GPT-4和Claude 3.5对比
在目前一水的顶尖模型面前,Llama 3.1也是不带怕的:
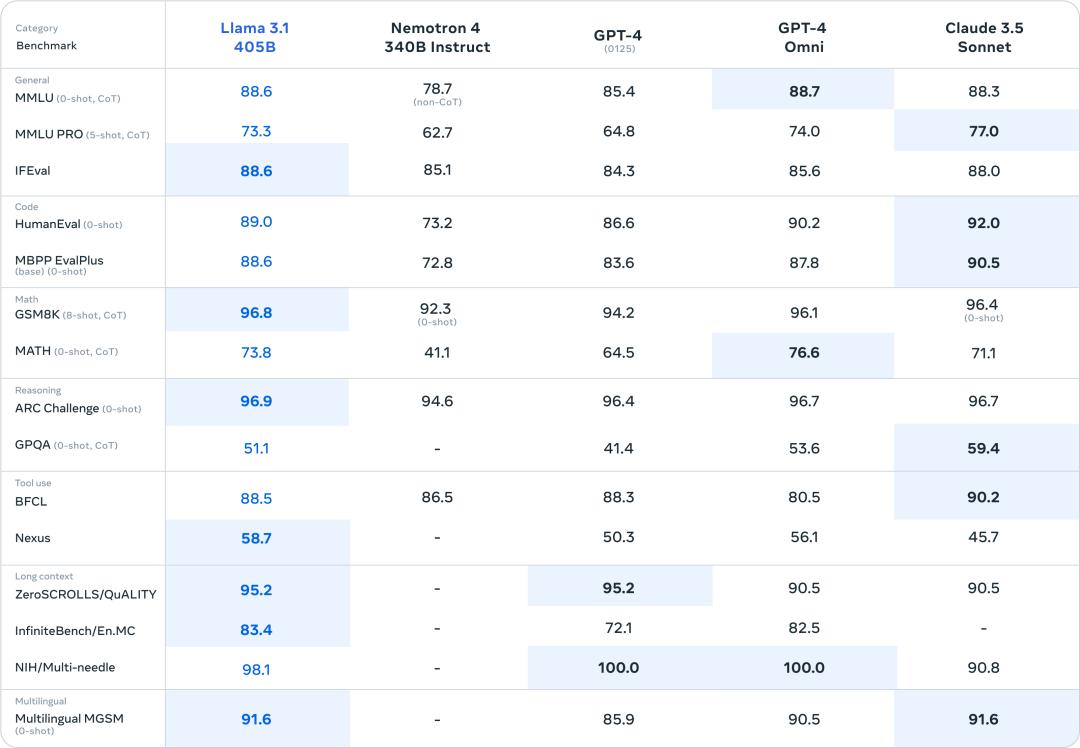
△与闭源模型对比
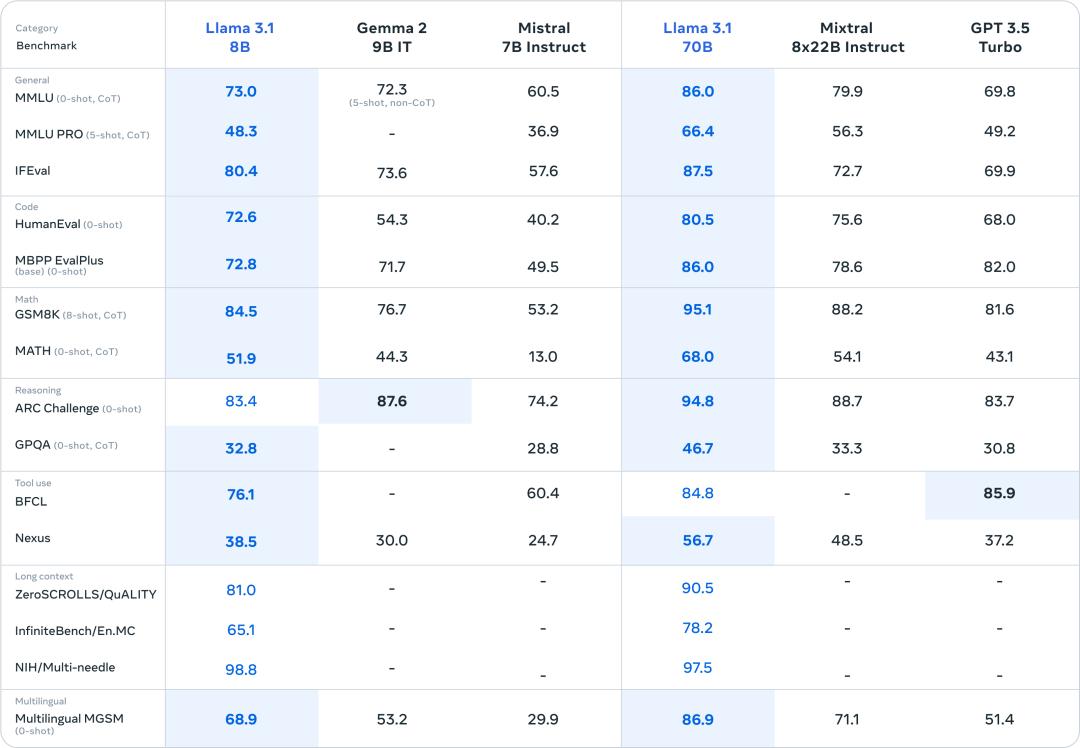
△与开源模型对比
可以说,Llama 3.1的发布,为最近火热的开源闭源路线之争,写下里程碑式的一笔:顶尖的开源模型,真正与顶尖的闭源模型会师了。
“到目前为止,开源大型语言模型在功能和性能方面大多落后于封闭式模型。现在,我们正迎来一个由开源引领的新时代。”Meta表示。
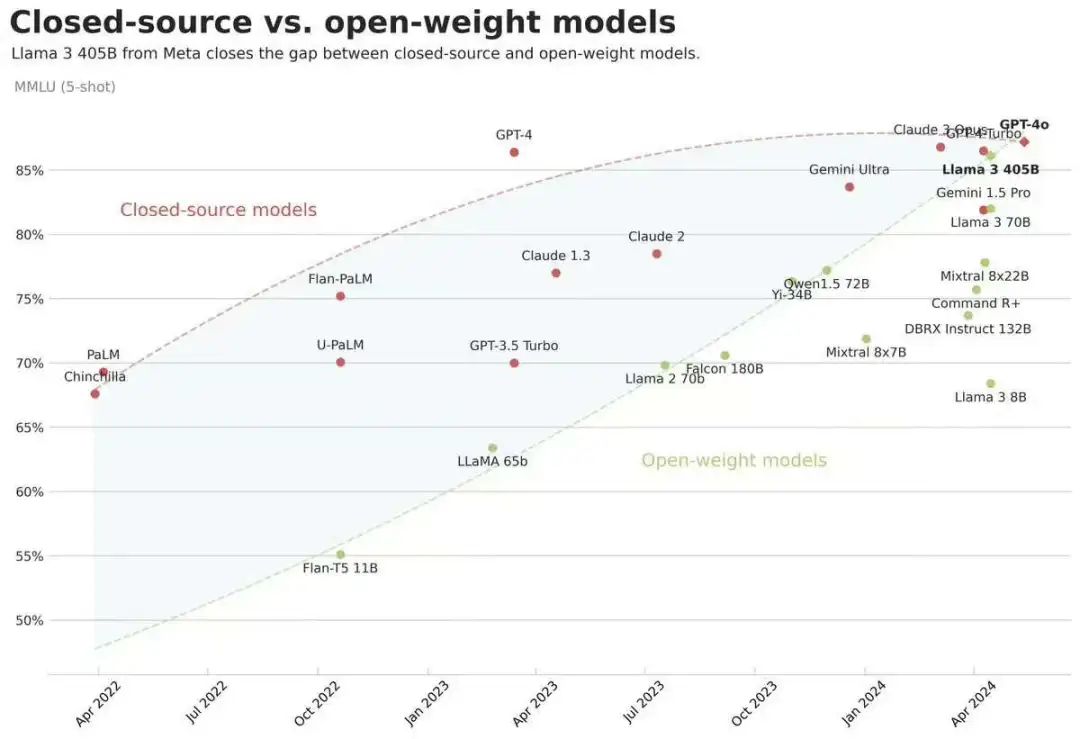
△近期火爆AI圈的一张图,开源模型赶上闭源模型
Meta在正式发布里也附上了长达92页的论文,透露了训练细节:
Llama 3.1 在超过 15 万亿个 token的数据上进行训练,用了16000块H100。使用的预训练数据,截至到2023年12月。
为了保证训练稳定性,只用了Transformer 模型架构进行调整,而不是现在流行的混合专家模型(MoE)架构。
这也导致,Llama 3.1即使扩展到128K上下文长度,也能保持短上下文窗口的高质量输出,再也不是“长文本特供”,而是“长短自如”。
达到如此训练规模的开源大模型,目前全世界独此一份。
更多细节,我们也在数小时前的推送中有详细介绍,此处不再赘述,请戳这里。
而2024年,随着模型训练规模越来越大,开发者们也在犯嘀咕:付出了巨大训练成本的大公司们,还会继续开源吗?
毕竟,OpenAI就是前车之鉴——早期曾秉持开放开源精神,但自从GPT3.5爆火后开始商业化,OpenAI再无开源,被群嘲为Closed AI。
但在Llama 3.1发布的当下,扎克伯格再次强调:
把开源进行到底!
除了发布模型,小扎还发表了一篇语重心长,富有理想主义的开源宣言,阐释Meta为什么要开源、为什么开源对开发者有利。
值得注意的是,他认为尽管美国与中国面临激烈的AI竞争,但选择开源路线,仍然利大于弊。
好了,Llama 3.1已经这样了,又要搬出那个问题:OpenAI,GPT-5啥时候来?
《开源AI是前进之路(Open Source AI Is the Path Forward)》
在高性能计算的早期,当时的主要技术公司都投入巨资开发自己的闭源Unix版本。在当时,很难想象还有其他方法可以开发出如此先进的软件。
尽管如此,开源Linux最终还是流行了起来——最初是因为它允许开发人员以他们想要的方式修改它的代码,而且更便宜;随着时间的推移,它变得更先进、更安全,并且拥有比任何闭源的Unix更广泛的生态系统,支持更多的功能。今天,Linux是云计算和运行大多数移动设备的操作系统的工业标准基础——我们都得益于它的卓越产品。
我相信人工智能将以类似的方式发展。如今,几家科技公司正在开发领先的闭源模型。但开源正在迅速缩小这一差距。去年,Llama 2只能与落后于前沿的老一代车型相媲美。今年,Llama 3与最先进的车型竞争,并在一些领域领先。从明年开始,我们预计未来的Llama将成为业内最先进的。但在此之前,Llama已经在开源性、可修改性和成本效率方面领先。
今天,我们将朝着开源AI成为行业标准的方向迈出下一步。我们将发布Llama 3.1 405B——第一个领先行业水平的开源AI模型,以及新的和改进的Llama 3.1 70B和8B模型。除了相对于闭源模型具有更好的成本/性能外,405B模型是开源的这一事实将使其成为微调和提取较小模型的最佳选择。
除了发布这些模型,我们还与一系列公司合作,以发展更广泛的生态系统。Amazon、Databricks和Nvidia正在推出全套服务,以支持开发人员微调和提炼他们自己的模型。Groq(AI芯片初创企业)等创新企业为所有新模型构建了低延迟、低成本的推理服务。
这些模型将在所有主流云上可用,包括AWS、Azure、谷歌、Oracle等。Scale.AI、戴尔、德勤和其他公司已经准备好帮助企业部署Llama,并使用他们自己的数据训练定制模型。随着社区的发展和越来越多的公司开发新服务,我们可以共同使Llama成为行业标准,并将人工智能的好处带给每个人。
Meta致力于开源AI。我将概述为什么我认为开源对人们来说是最好的开发栈,为什么开源Llama对Meta有好处,为什么开源AI对世界有好处,以及正因为如此,开源社区将会长期存在。
当我与世界各地的开发者、CEO和政府官员交谈时,我通常会听到以下几个主题:
我们需要训练、微调和提炼我们自己的模型。
每个组织都有不同的需求,不同规模的模型可以最好地满足这些需求,这些模型使用特定的数据进行训练或微调。设备上任务和分类任务需要较小的模型,而更复杂的任务需要较大的模型。
现在,你将能够使用最先进的Llama模型,继续使用你自己的数据训练它们,然后将它们提炼为你的最佳大小的模型——而我们或其他任何人都不会看到你的数据。
我们需要控制自己的命运,而不是被一个闭源的供应商所束缚。
许多组织不希望依赖于无法运行和控制的模型。他们不希望闭源模型提供者能够更改他们的模型、更改他们的使用条款,甚至完全停止为他们提供服务。他们也不想被锁定在一个对某个模型拥有独占权的单一云中。开源为众多公司的生态系统提供了兼容的工具链,你可以轻松地在它们之间切换。
我们需要保护我们的数据。
许多组织处理的敏感数据需要保护,并且无法通过云API传输到闭源模型。其他组织只是不信任闭源模型提供商的数据。开源通过使你能够在你想要的任何地方运行模型来解决这些问题。开源软件因为开发更透明,所以更安全,这一点被广泛接受。
我们需要一种高效且负担得起的运行模式。
开发人员可以在自己的基础设施上在Llama 3.1 405B上运行推理,成本大约是使用GPT-4o等闭源模型的50%,用于面向用户的和离线推理任务。
我们押注了一个能够成为长期标准的生态系统。
很多人看到开源比闭源模型发展得更快,他们希望构建他们的系统的架构能给他们带来最大的长期优势。
Meta的商业模式是为人们建立最好的体验和服务。要做到这一点,我们必须确保我们总是能够获得最好的技术,而不是被锁定在竞争对手的闭源生态系统中,他们会限制我们构建的内容。
我的一个形成经验是,我们的服务受到苹果允许我们在他们平台上构建的限制。他们向开发者征税的方式,他们应用的武断规则,以及他们阻止发布的所有产品创新,很明显,如果我们能够构建我们产品的最佳版本,而竞争对手无法限制我们可以构建的内容,那么Meta和许多其他公司将会自由地为人们构建更好的服务。在哲学层面上,这是我如此坚定地相信在AI和AR/VR中为下一代计算构建开源生态系统的主要原因。
人们经常问我是否担心开源Llama会放弃技术优势,但我认为这忽略了一些重要的原因:
首先,为了确保我们能够获得最好的技术,而不是长期被锁定在一个闭源的生态系统中,Llama需要发展成一个完整的生态系统,包括工具、效率提高、硅优化和其他集成。如果我们是唯一使用Llama的公司,这个生态系统就不会发展,我们也不会比闭源的Unix变体好到哪里去。
其次,我预计随着智能的发展,竞争将加剧,这意味着在那个时候,开源任何特定模型,人们都不会放弃对下一个具有更大优势的模型。Llama成为行业标准的道路是通过始终如一的竞争,高效和开源一代又一代模型。
第三,Meta和闭源模型提供商之间的一个关键区别是,销售AI模型的访问权不是我们的业务模式。这意味着,公开发布Llama并不会削弱我们的收入、可持续性或投资研究的能力,就像它对闭源供应商所做的那样。(这是几个闭源的提供商一直游说政府反对开源的原因之一。)
最后,Meta有很长的开源项目历史和成功经验。通过开源计算项目发布我们的服务器、网络和数据中心设计,并在我们的设计上实现供应链标准化,我们节省了数十亿美元。我们受益于生态系统的创新,开源的领先工具,如PyTorch, React和更多的工具。当我们长期坚持时,这种方法一直对我们有效。
我相信开源对于积极的人工智能未来是必要的。人工智能比任何其他现代技术都有更大的潜力来提高人类的生产力、创造力和生活质量,并在加速经济增长的同时促进医学和科学研究的进步。
开源将确保世界各地更多的人能够获得人工智能的好处和机会,权力不会集中在少数公司手中,技术可以在社会上更均匀、更安全地部署。
关于开源人工智能模型的安全性一直存在争论,我的观点是,开源人工智能将比替代方案更安全。我认为政府会得出结论,支持开源符合他们的利益,因为它会使世界更加繁荣和安全。
我对安全的理解框架是,我们需要防范两类伤害:无意伤害和有意伤害。非故意伤害是指人工智能系统可能造成伤害,即使运行它的人没有这样做的意图。
例如,现代人工智能模型可能会无意中给出糟糕的健康建议。或者,在更未来的场景中,一些人担心模型可能会无意中自我复制或过度优化目标,从而损害人类。故意伤害是指不良行为者以造成伤害为目标使用人工智能模型。
值得注意的是,无意伤害涵盖了人们对人工智能的大多数担忧——从人工智能系统将对数十亿将使用它们的人产生的影响到人类的大多数真正灾难性的科幻场景。在这方面,开源应该要安全得多,因为系统更透明,可以广泛检查。
从历史上看,开源软件因为这个原因更加安全。同样,使用Llama及其安全系统(如Llama Guard)可能比闭源模型更安全。因此,大多数关于开源人工智能安全的讨论都集中在故意伤害上。
我们的安全流程包括严格的测试和红队,以评估我们的模型是否能够造成有意义的伤害,目标是在发布之前降低风险。由于模型是开源的,任何人都可以自己进行测试。
我们必须记住,这些模型是由互联网上已经存在的信息训练出来的,所以在考虑伤害的时候,我们的出发点应该是,一个模型是否比那些可以从谷歌或其他搜索结果中快速检索到的信息更容易造成伤害。
在推理故意伤害时,区分个人或小规模行为者可能做的事情与拥有大量资源的民族国家等大规模行为者可能做的事情是有帮助的。
在未来的某个时候,个别不良行为者可能会利用人工智能模型的智能,从互联网上提供的信息中制造出全新的危害。在这一点上,力量平衡将对人工智能的安全至关重要。
我认为生活在一个广泛部署人工智能的世界里会更好,这样大的参与者就可以制衡小的坏人的力量。这就是我们在社交网络上管理安全的方式——我们更强大的人工智能系统识别并阻止那些经常使用规模较小的人工智能系统的不太复杂的攻击者的威胁。
更广泛地说,大规模部署人工智能的大型机构将促进整个社会的安全和稳定。只要每个人都能使用类似的模型——这是开源所促进的——那么拥有更多计算资源的政府和机构将能够用更少的计算来检查不良行为者。
下一个问题是美国和民主国家应该如何应对像中国这样拥有大量资源的国家的威胁。美国的优势在于去中心化和开源式创新。
有些人认为,我们必须封锁我们的模型,以防止中国获得这些模型,但我的观点是,这不会起作用,只会使美国及其盟友处于不利地位。我们的对手很擅长间谍活动,窃取U盘上的模型相对容易,而且大多数科技公司的运营方式远没有让这变得更困难。
一个只有闭源模型的世界似乎最有可能导致少数大公司加上我们的地缘政治对手能够获得领先的模型,而初创公司、大学和小企业则错过了机会。
此外,将美国的创新限制在闭源的发展中会增加我们根本无法领先的可能性。相反,我认为我们最好的战略是建立一个强大的开源生态系统,并让我们的领先公司与我们的政府和盟友密切合作,以确保他们能够最好地利用最新的进展,并实现长期可持续的先发优势。
当您考虑未来的机会时,请记住,当今大多数领先的技术公司和科学研究都是建立在开源软件之上的。如果我们共同投资,下一代公司和研究将使用开源人工智能。这包括刚刚起步的初创公司,以及可能没有资源从头开始开发自己最先进的人工智能的大学和国家的人们。
最重要的是,开源AI代表了世界上利用这项技术为每个人创造最大的经济机会和安全的最佳机会。
对于过去的Llama模型,Meta为自己开发了它们,然后发布了它们,但并没有过多地关注于构建更广泛的生态系统。
我们在这次发布中采取了不同的方法。我们正在内部组建团队,让尽可能多的开发者和合作伙伴能够使用Llama,我们也在积极建立合作伙伴关系,这样生态系统中的更多公司也可以为他们的客户提供独特的功能。
我相信Llama 3.1的发布将成为行业的一个转折点,大多数开发人员开始主要使用开源,我希望这种方法只会从这里开始发展。我希望你能加入我们的旅程,把人工智能的好处带给世界上的每一个人。
获取Llama 3.1的链接为:https://llama.meta.com/
??,
MZ(马克·扎克伯格)
欢迎交流

欢迎交流
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号