01 Gemma模型架构和参数计算
上一篇文章《原创 | 大模型扫盲系列——初识大模型》从比较宏观的角度初步介绍大模型领域的相关知识,旨在带领读者构建一个大模型知识框架。近期,大模型相关的技术和应用层出不穷,各个方向的论文百花齐放,底层的核心技术是大家公认的精华部分。本文从技术的角度聚焦大模型的实战经验,总结大模型从业者关注的具体方向以及相关发展,帮助打算参与到大模型工作的人高效上手相关工作。
基座模型参数
在动手实践之初,首要任务便是选取一款市场上表现卓越的基座模型,为各种任务打下坚实的基础。在这个领域,OpenAI的ChatGPT-4以其独特的优势领跑,一时间,普通企业难以望其项背。因此,其他顶尖科技公司不得不寻找新的道路,争相进入开源领域,竞争打造出最强效果的大型模型。随着大模型技术成为热门趋势,无论是从学术论文的频繁引用还是商业应用实践来看,业界对这些基座模型的效果已达成广泛共识。
目前,业内普遍认可且实用性最高的四个基座模型分别为:Meta的Llama系列,被誉为欧洲"OpenAI"的Mistral AI所开源的Mistral系列,国内表现优秀的Qwen系列,以及最近发布、在同等参数级别中表现最佳的开源模型——Google的Gemma系列。本文将从模型的参数、网络结构和效果等多个方面进行深入分析,旨在提供一套适用于理解和评估任何开源模型的方法论和关注点。这里会以目前同量级效果最好的谷歌的Gemma系列作为举例来说明整体流程,具体模型见
https://huggingface.co/docs/transformers/en/model_doc/gemma
Gemma:
谷歌发布了一系列的Gemma模型(如下表格),以最常用的7B模型为例子具体剖析:
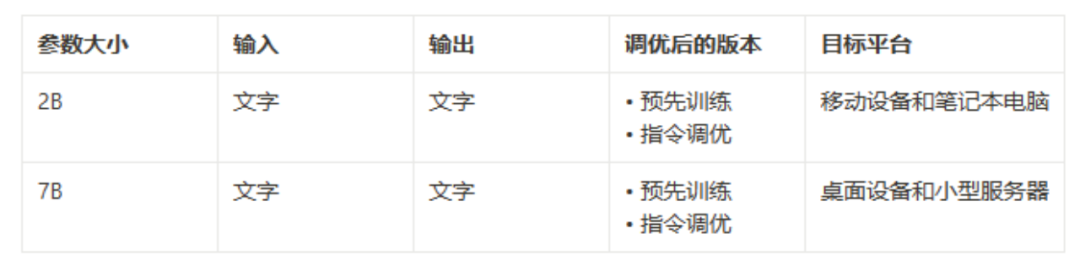
从模型卡(model card)中,能快速了解整个模型的架构以及在现有公开数据集上训练的效果,这里用大部分篇幅介绍计算模型参数,掌握这步计算对模型结构深入理解以及模型部署的推理优化都有非常重要的意义。
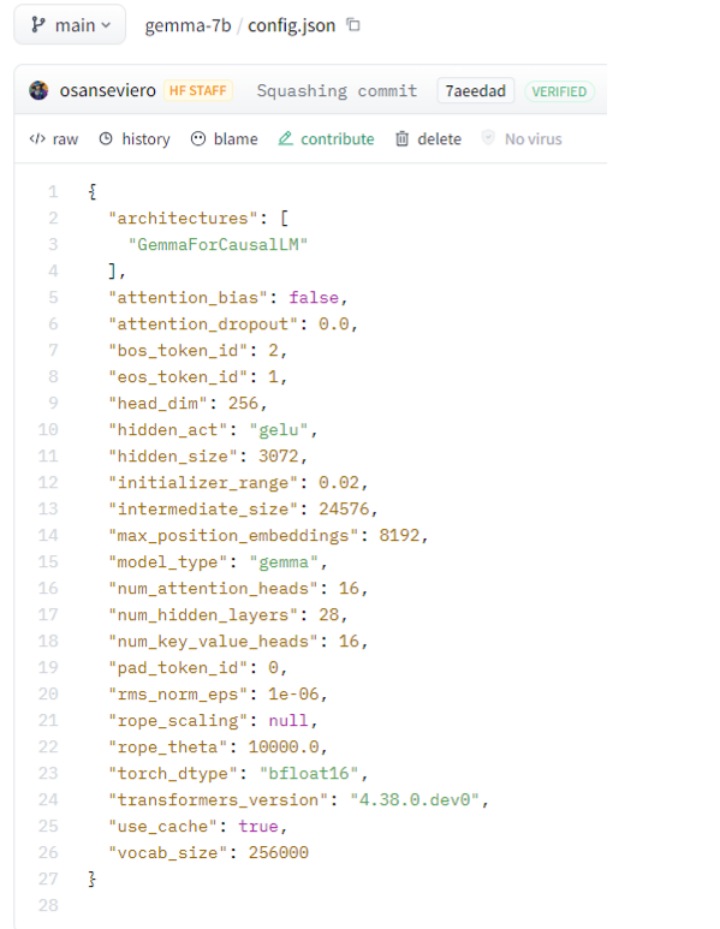
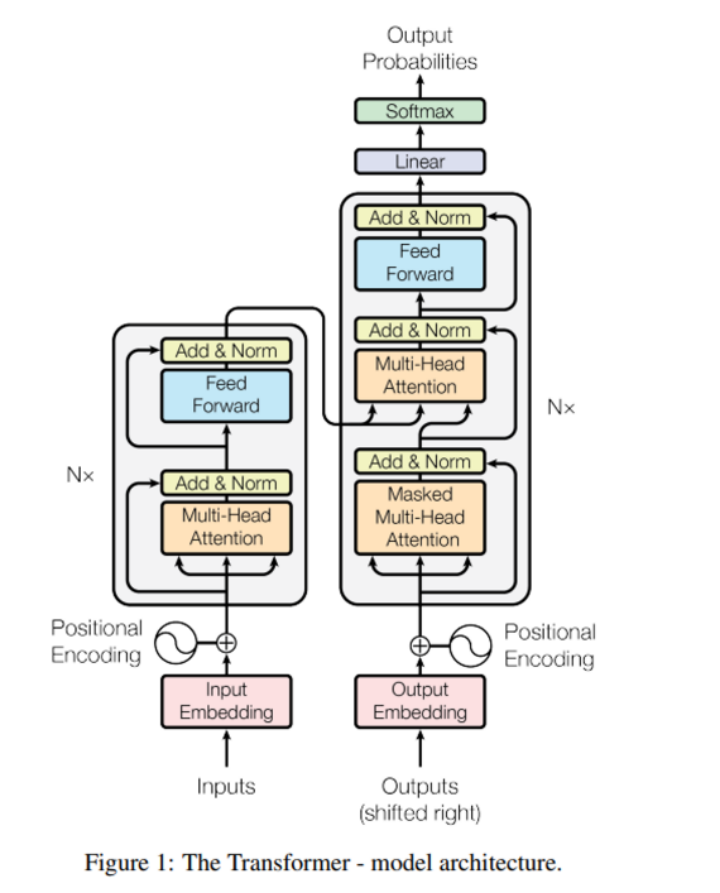
图1
参数估算
7B的意思是模型参数的数量为70亿,这个数据包含嵌入层(Embedding)的参数,模型网络结构中的权重(weight)和偏差(bias)的总和,从官方发布的报告(https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf)来看,所有参数总和应该是85亿(Table2中嵌入层参数+非嵌入层参数),这里的7b命名可能也是考虑到与差不多量级的Llama2进行对比。

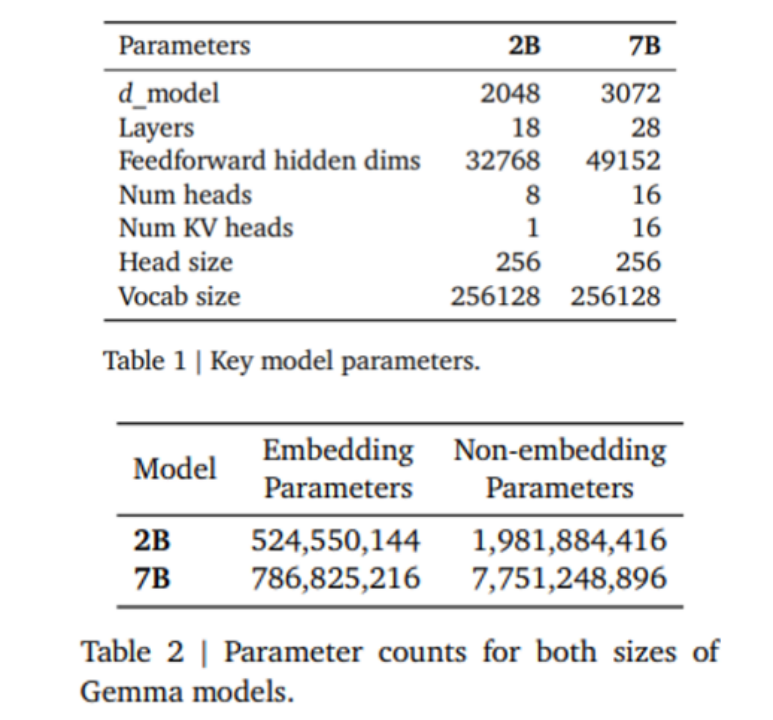
对于Table 1的7B模型,结合图1中的config.json文件中的参数得到具体计算流程
Part 1:嵌入层参数(Embedding Parameters)
注意Table 1中的dmodel就是指隐藏层的维度大小,对应json文件中的hidden size,而Gemma采用的是RoPE的位置编码方式,所以实际上位置嵌入的参数不算入嵌入层的参数,所以最后代入具体对应的数值有:256128 * 3072 = 786,825,216Part 2:非嵌入层参数(Non-Embedding Parameters)这次Gemma使用的是Multi-Head attention,由上图得知Transformer结构由多个相同的层组成(Gemma是decoder-only模型,我们只需要关注decoder部分的网络结构就行),每个层分为三大部分:- 多头注意力层(Multi-head attention)
- 前馈网络(Feed-forward network)
- 归一化层(Layer normalization)
- 查询(query)权重:dmodel * dq *
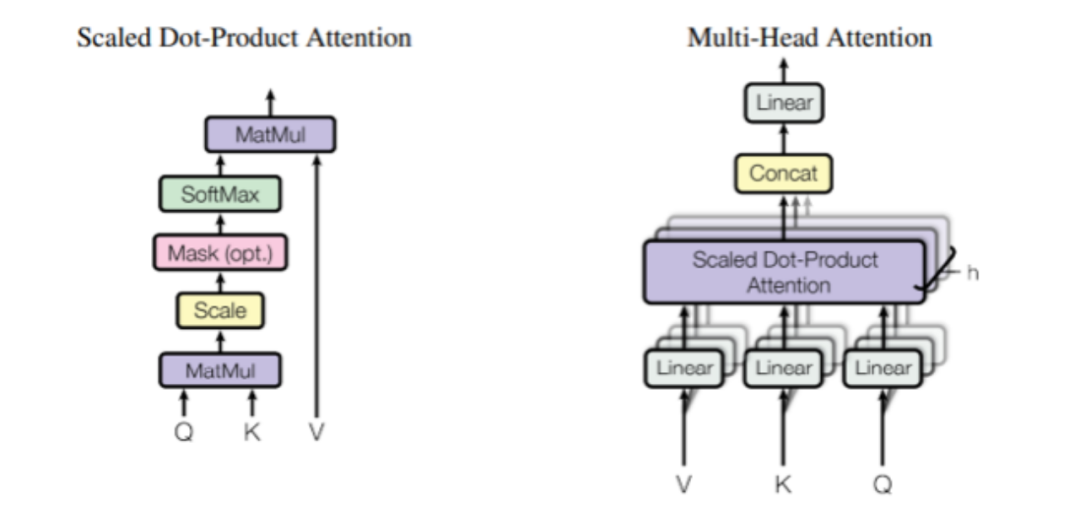
注意力层总参数量:3* * dmodel * dkqv + (dmodel * * dkqv)这里注意一下注意力输出权重的计算是用Multi-head Attention的方式,从图2的Multi-Head Attention组件结构可知,Q、K、V做完 Scaled Dot-Product Attention之后,将得到的加权值(Values)通过一个线性变换来生成最终的输出。在一个典型的Transformer模型中,每个头会输出一个dmodel维的向量,然后把所有头的输出被拼接起来,形成一个更长的向量,这个向量随后会通过一个线性层的权重矩阵W_O实现的,它的维度是dmodel*dmodel,以将拼接后的向量重新投影回原来的维度。7B一共是16个头,以及每个头是256维,所以最后的结果经过化简近似于:4 * dmodel * 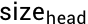 *
* = 50,331,648
= 50,331,648- gate_proj 的权重:intermediate_size * dmodel
- up_proj 的权重:dmodel * intermediate_size
- down_proj 的权重:intermediate_size * dmodel
前馈网络层总参数量:intermediate_size * dmodel * 324576 * 3072 * 3 = 226,492,416- Gemma用了RMSNorm,源码中只有一个weight缩放参数进行学习
每个decoder模块有两个归一化层,所以总参数量:2 * 1 * dmodel可以看到这个参数太小了,在近似计算中可以忽略不计。- 每层的总参数量:注意力层总参数量 + 前馈网络层总参数量 + 层归一化总参数量
- 所有层的总参数量:每层的总参数量 * num_hidden_layers
最后可以得到非嵌入层参数:(50,331,648 + 226,492,416 + 6144 ) * 28 = 7,751,245,824这部分参数是模型参数最后一个组成部分,模型的最后一层是一个分类头,这层主要功能就是输出对所有tokenizer分类的概率,一般都是由一个线性层构成,也是模型最后输出结果的层。从代码可以知道,这层的参数量是:3072 * 256128 = 786,825,216总参数量: 嵌入层参数 + 非嵌入层参数 + LM Head786,825,216 + 7,751,245,824 + 786,825,216 = 9,324,896,256 ≈ 9.3b最后我们可以看到显式的参数是在9.3b左右,但由于使用了权重共享(weight tying),最后整体参数在8.5b左右,这种类似操作也出现在GPT-2 和XLNet等模型中,利用输入嵌入层和最后输出的LM Head分类层中共享相同的权重,总的来说还是比Llama2要大一些。从这个计算步骤下来,会发现基本上理清楚了Gemma的整体模型结构,这里再从多方面对模型结构进行一个总结,同时也可以当做回顾主流大模型结构的一个总结。Attention形式
Gemma7B用的是最经典的Transformer论文中的Multi-head attention(MHA)结构,而2B版本则用了Multi-Query attention(MQA)的结构,这也是基于在较小规模下的性能和计算效率考虑 。标准的注意力机制中,查询(query)、键(key)和值(value)是三个核心组件,计算的是一个查询和所有键之间的相似度,然后这个相似度被用来加权相应的值。而在Multi-query attention中,可以同时处理一组查询,让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而可以共享键和值的表示,提高计算效率。另外还有比较常见的是Grouped-query attention(GQA),是MQA的一个变形结构,这个结构出来的原因也是因为实验表明MQA在训练的质量上会其实相对于MHA会有衰减。该结构简单来说可以理解为Multi-head attention和Multi-Query attention的"中间结构",相对于MHA的每个query都有其各自的Key和Value,以及MQA的所有query都共享一份Key和Value,GQA则是把query进行分组,每个组的query共享一份key和value,这种方式巧妙的兼顾了训练的速度和质量的平衡。在论文中的实验数据可以看出,GQA在大多数任务上表现和MHA差不多,并且评估效果优于MQA。由于MHA独立处理每个头部的查询(Q)、键(K)和值(V),它在训练时需要更多的参数和内存。MQA和GQA通过共享K和V的投影减少了参数量,从而减少了模型训练时的内存需求。当前主流的基模型基本上都是使用变形的attention机制,比如Llama2中最后选择了GQA给出的思路则是通过消融证明了GQA在平均性能上与MHA相当,且优于MQA。GQA在为更大模型的推理缩放提供效率的同时,还考虑了分布式设置中的操作考虑,强调了在不损害模型性能的前提下提高计算效率的战略采用。Tokenizer算法
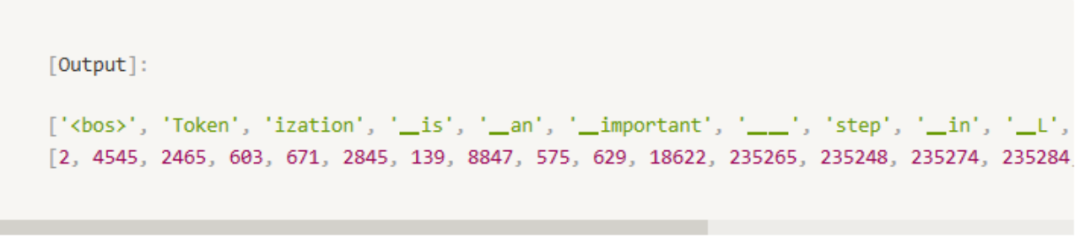
当前大语言模型的效能很大程度上依赖于其能力去理解和处理自然语言,而这一过程的基石就是有效的文本tokenization。Tokenization是将文本分解为更小单元(如单词、子词或字符)的过程,这些单元随后被用于模型训练。但是切分的时候需要考虑以什么粒度去切分?1. 尽可能避免Out-of-vocabulary(OOV)现象带来的问题,这个问题可以用更细粒度的字符级去解决,只要对词再分的足够细,就可以表达一些生僻词;但是同时会带来序列长度的增长,导致计算成本变大很多。2. 又需要高效地来表示所有的语义,比如用小规模的词库也能表达一些长尾的生僻字;以及相似词之间的关系,不会导致相似词语义上的割裂。这时就需要平衡词粒度(word)和字符粒度(character)的方法来进行分词,也就是子词(subword)粒度的分词,该方法核心理念是,常见词保留完整形态,而较为罕见的词则分解为更小的子单元,以此实现对token空间的高效共享,通过一定程度拆解的方式解决性能和效果的平衡。当前Byte-Pair Encoding (BPE)、Byte-level BPE 、Unigram language model和WordPiece是构建大型语言模型时最主流的四种subword分词方式。- WordPiece (BERT,DistilBERT,MobileBERT,Funnel Transformers,MPNET) 将单词分解为更小的单元,这些单元要么是整个单词,要么是子单词。通过迭代过程逐渐构建词汇表。在每一步,它选择合并词汇表中的一对符号,这对合并将最大限度地减少语言模型的损失(通常是基于n-gram频率),通过合并频繁共现的字符对来构建词汇。实践中会看到“##”,表示是前一个token的延续,比如Tokenizer会分成“To”, “##ken”,“##izer”这三个表示。
- Byte-Pair Encoding(GPT系列,LLaMA系列,ChatGLM-6B,Baichuan) 通过迭代合并最常见的字节对来减少序列长度,提高编码效率,有助于有效处理未知词汇和稀疏数据问题,提高模型的泛化能力。
- Byte-level BPE (RoBERTa)在BPE基础上,以字节为基本单位来构建词汇表,而非传统的字符。该过程从将文本以UTF-8格式编码开始,其中每个符号可能占用1至4个字节。随后,在这些字节序列上应用BPE算法,执行基于字节级别的相邻合并操作,以此方式优化词表的生成和文本的表示。这种方法不仅提高了模型对文本的理解能力,还增强了对多种语言及其特殊字符的支持,从而为模型提供了更丰富、更精确的文本表示方式。
- Unigram language model (AlBERT,T5,mBART,Big Bird,XLNet) 基于单个词的出现概率来进行文本分割,它通过统计大量文本数据来预测每个可能的单词(包括子词)的出现频率或概率。在分词过程中,算法尝试将句子分解成一系列单词或子词,来最大化整个句子的概率,适用于处理未知或罕见词汇。通过剪枝最不可能的分割来达到最终的词汇表。
这里提一下,实践中主流的大模型都是用的SentencePiece处理Tokenizer,这个算法工具包是支持BPE和unigram两种算法,为Tokenizer处理提供了极大的灵活性,也基本上是谷歌家族标配的处理方式。为了方便读者对比各个算法的差异,下图是对同一句话不同Tokenizer算法得到的结果,这个句子包含了大小写、标点符号、特殊符号、两个空格和数字,可以当做一个典型case供大家对比:Gemma这次延用了PaLm中与SentencePiece兼容的tokenizer,报告中说这同时也是从Gemini模型的词库中取了一部分。这份词库的tokenizer是完全来源于训练数据,所以整体训练的时候会更加高效。另外,整个词汇表是完全无损和可逆的,这意味着词汇表中完全保留了空格(对代码类的数据尤其重要),词汇表外的 Unicode 字符被拆分为 UTF-8 字节,每个字节都有一个词汇标记。数字则会被拆分为单独的数字标记,例如123.5→1 2 3 . 5。总体来看就是tokenizer做的粒度更细,且更倾向于保留原始数据的语义。并且从词表量级角度,相对于其他基模型(Llamma2 7b和mistral 7b都是32000)所用的256k量级的tokenizer词汇表还是大很多的,猜测也是对比同等量级模型效果好的原因之一。03 向量位置编码
由于主流的语言模型基本都是基于Transformer结构,其中的自注意力机制造成它们本身不处理输入数据的顺序,所以位置编码成为了提供序列中每个元素位置信息的关键手段,它们能使模型能够捕捉到序列中单词的顺序信息。位置编码通过增加额外的信息到每个单词的表示中,使模型能够区分单词在句子中的位置,从而理解词序和语法结构,这对于理解句子含义至关重要(见下面例子)。这次Gemma中采用的是被多个主流模型验证兼顾处理长序列的能力,同时保持较低的计算复杂度的旋转位置编码Rotary Positional Embeddings (RoPE)。首先我们回顾一下主要位置编码的方式,一种是之前Bert和Transformer用的绝对位置编码,Bert把位置的Embedding作为模型训练的一部分,通过训练学习的方式来表征每个token的位置信息,该位置向量只与输入的位置有关,这类编码方式理解起来非常直观,实现也比较容易。但是这里有一个明显的缺陷就是对于模型处理长序列的能力有限,由于绝对位置编码是预先定义的,这可能导致模型难以泛化到比训练时见过的序列更长的情况。也就是所说的没有外推能力。这就会影响模型捕捉序列内长距离依赖关系的能力,特别是会在处理复杂的语言结构或需要细腻理解序列内关系的任务上,会表现比较差。后来Transformer又进行了优化,利用三角函数的周期性来表示位置编码(Sinusoidal Positional Encoding),本质可以总结成,通过在不同维度应用正弦和余弦函数的不同频率,产生了能够代表不同位置的高维位置向量。公式中的pos代表当前token在句子中的位置,dmodel与上文算参数的表示是一个意思,就是代表总的向量维度,i则代表其中一个向量维度。论文中提到使用这种方式主要原因是在实验效果差不多的情况下,三角函数位置编码对训练中没见过的词也有很好的外推能力。RoPE Embeddings
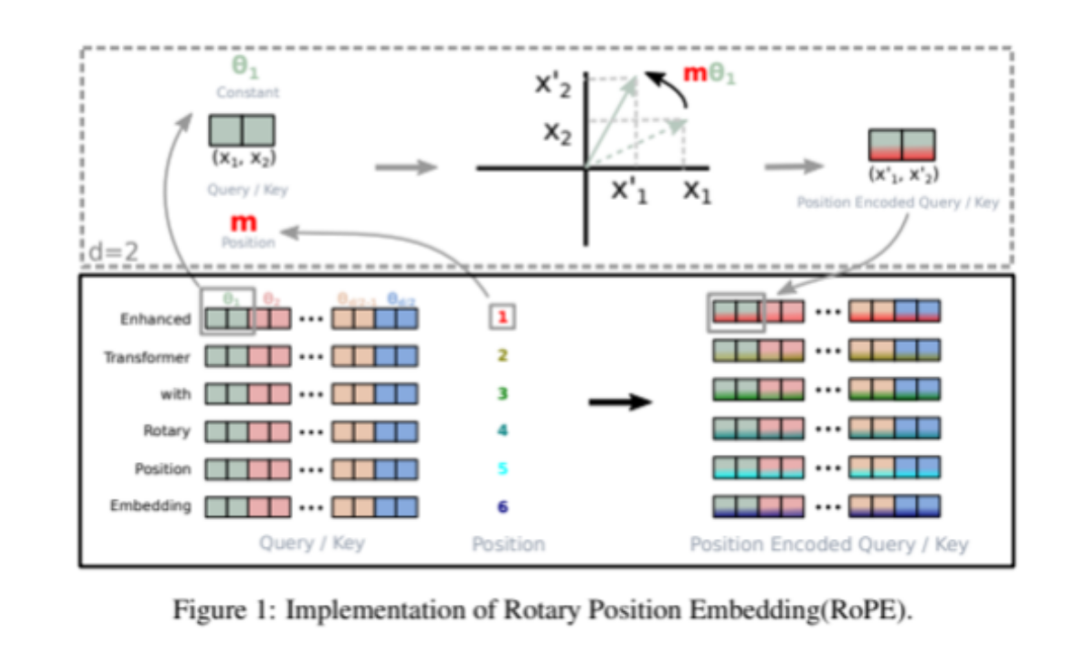
然而以上编码本质还是绝对位置的形式,都还不够高效,接下来就要重点说到Gemma及现在主流的基模型中都会使用的相对位置编码方式,其中主流是Rotary Position Embedding,RoPE,这种方式是集合相对和绝对编码的优势设计出来的,通过对词嵌入进行旋转变换,以一种高效且紧凑的方式捕捉序列中元素的相对位置信息。用原作者概括的话就是“配合Attention机制能达到‘绝对位置编码的方式实现相对位置编码’的设计”,这个计算是在模型的自注意力(Self-Attention)计算步骤中进行。在这一步骤中,模型会根据序列中各元素之间的相对位置关系,动态调整它们之间的注意力权重,从而有效捕捉和利用位置信息来理解文本内容。与传统的位置编码方法相比,RoPE 的优势在于它能够在不显著增加计算复杂度的情况下,有效处理长序列数据,并保持了对相对位置关系的敏感性。这种方法在提高模型对长距离依赖关系捕捉能力的同时,还能减少模型训练和推理过程中的资源消耗。核心:利用数学上的旋转操作来模拟单词嵌入随位置变化的动态,进而在Attention计算中隐式地表达单词之间的相对位置关系。这里以2维的向量作为例子进行说明,方法可以直接推广到高维。1. 给定一个二维的查询或键的向量(x1,x2),它代表未经位置编码的原始嵌入。其中,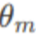 是与位置 m 相关的旋转角度。旋转矩阵Rm是线性的,这意味着旋转操作可以通过矩阵乘法应用于向量上,保持了向量之间的线性关系。实际中,即使在长句子中,模型也能够有效地理解和利用单词之间的相对位置信息。
是与位置 m 相关的旋转角度。旋转矩阵Rm是线性的,这意味着旋转操作可以通过矩阵乘法应用于向量上,保持了向量之间的线性关系。实际中,即使在长句子中,模型也能够有效地理解和利用单词之间的相对位置信息。- 第一行 x1'=x1cos(
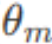 )-x2sin(
)-x2sin(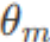 )计算的是旋转后向量的x1坐标。
)计算的是旋转后向量的x1坐标。 - 第二行 x2'=x1sin(
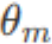 )+x2cos()计算的是旋转后向量的x2坐标。
)+x2cos()计算的是旋转后向量的x2坐标。
旋转后的向量(x1,x2)表示了经过位置编码的查询或键,即原始向量绕原点旋转角度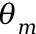 后的新位置。在这个过程中,每一维度的查询或键都被视作二维空间中的点,并通过相应的旋转矩阵进行旋转。对每个位置应用相应的旋转矩阵,模型可以嵌入单词的相对位置信息,使得Attention机制能够利用这些信息来更好地理解单词之间的关系。同时三角函数本身具有的周期性性质在处理长序列时表现出更高的灵活性。想象一下,你在一个广阔的旋转餐厅里用餐。你的位置是固定的,但是通过旋转,你可以看到餐厅里的每个角落。这和在语言处理中理解单词的“位置”有些相似。每个单词都像是餐厅里的一个顾客,他们的“位置”对于他们如何相互交流是非常重要的。在模型理解语言时,我们需要告诉它每个单词不仅是什么,还在哪里。传统的做法就像是给每个顾客一个编号,号码越小表示越接近餐厅的入口。这种方法很直接,但是当餐厅扩大,或者当顾客移动位置时,这些编号就不太有用了。RoPE这种编码方式,就像是通过观察顾客是如何相对于入口旋转来定位他们。而不是说“这个顾客在第5号桌”,我们会说“从入口开始,逆时针转90度,你会看到这个顾客。”这样的好处是,无论餐厅多大,或者顾客如何移动,描述都是有效的。这也意味着即使在餐厅扩建之后,我们依然能够描述新顾客的位置。在实际的语言模型中,RoPE允许模型更好地理解单词之间的关系,就像是能够理解顾客之间在旋转餐厅中的相对位置一样。即使句子变得很长,或者模型遇到了新的、更长的句子,这种编码方式仍然能帮助模型准确地“看到”每个单词的位置,就像你能够看到餐厅中每个顾客的位置一样。
后的新位置。在这个过程中,每一维度的查询或键都被视作二维空间中的点,并通过相应的旋转矩阵进行旋转。对每个位置应用相应的旋转矩阵,模型可以嵌入单词的相对位置信息,使得Attention机制能够利用这些信息来更好地理解单词之间的关系。同时三角函数本身具有的周期性性质在处理长序列时表现出更高的灵活性。想象一下,你在一个广阔的旋转餐厅里用餐。你的位置是固定的,但是通过旋转,你可以看到餐厅里的每个角落。这和在语言处理中理解单词的“位置”有些相似。每个单词都像是餐厅里的一个顾客,他们的“位置”对于他们如何相互交流是非常重要的。在模型理解语言时,我们需要告诉它每个单词不仅是什么,还在哪里。传统的做法就像是给每个顾客一个编号,号码越小表示越接近餐厅的入口。这种方法很直接,但是当餐厅扩大,或者当顾客移动位置时,这些编号就不太有用了。RoPE这种编码方式,就像是通过观察顾客是如何相对于入口旋转来定位他们。而不是说“这个顾客在第5号桌”,我们会说“从入口开始,逆时针转90度,你会看到这个顾客。”这样的好处是,无论餐厅多大,或者顾客如何移动,描述都是有效的。这也意味着即使在餐厅扩建之后,我们依然能够描述新顾客的位置。在实际的语言模型中,RoPE允许模型更好地理解单词之间的关系,就像是能够理解顾客之间在旋转餐厅中的相对位置一样。即使句子变得很长,或者模型遇到了新的、更长的句子,这种编码方式仍然能帮助模型准确地“看到”每个单词的位置,就像你能够看到餐厅中每个顾客的位置一样。激活函数
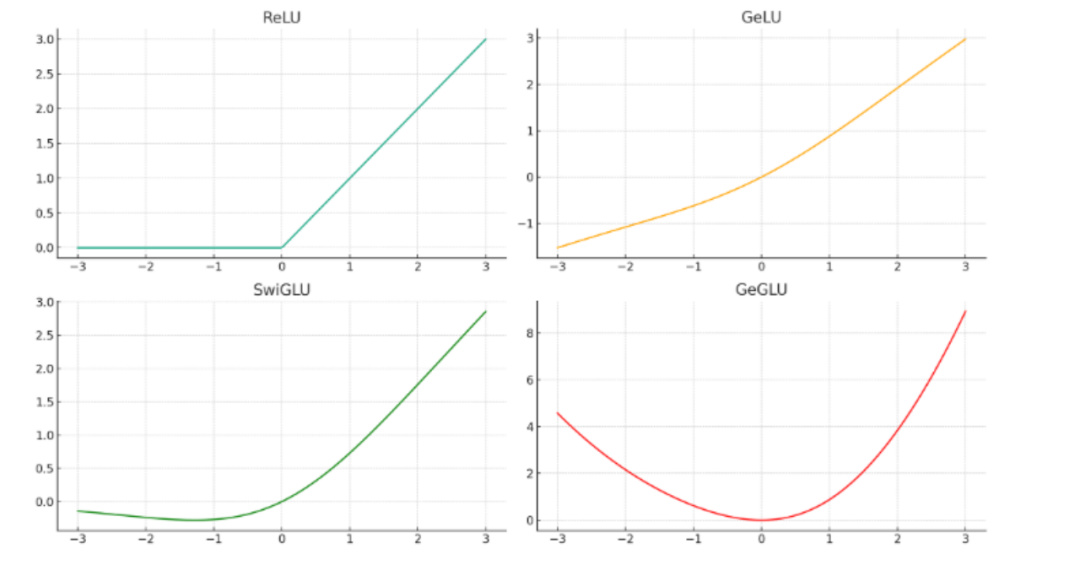
模型中的激活函数主要目的是为网络引入非线性,使得神经网络能够学习和模拟复杂的、非线性的函数映射。如果没有激活函数,即使网络拥有很多层,每层有很多神经元,网络整体仍然只能表示线性的函数关系,极大限制了网络模型的表达能力和复杂度。通过引入非线性激活函数,神经网络能够学习到更加复杂的数据模式,特别大模型这类参数量很大的复杂模型,选择合适的激活函数对模型学习数据非线性表达至关重要。以下主要介绍基模型主流的激活函数:
1. ReLU(Rectified Linear Unit)
从公式知,输入是正的,则直接输出该值;如果输入是负的,则输出0。ReLU因其简单性和效率在深度学习中非常流行。它有助于解决梯度消失问题,加速了神经网络的收敛,并且计算简单。- 解决梯度消失问题:对于正输入,梯度恒为1,因此不会发生梯度消失问题。
- 死亡ReLU问题:如果输入为负,则梯度为0,该神经元可能再也不会更新,称为“Dead ReLU”。
2. GeLU(Gaussian Error Linear Unit)
其中P(X<=x)是基于高斯分布的输入小于输出的概率,也可以用误差函数(erf)来表示。原理是输入通常是呈现正态分布,通过输入的概率计算决定是否置为0(被丢弃)。如果有时候为了计算快速,也可以用近似的计算:GeLU通过引入输入数据的概率分布,可以自适应地调整其非线性程度,从而在某些任务中提供比ReLU更好的性能。- 自适应非线性:根据输入数据的分布调整激活函数的形状。
- 解决梯度消失问题:对于大部分输入值,其导数不为零,有助于缓解梯度消失问题。
- 计算复杂度较高:相对于ReLU,GeLU的计算更复杂。
目前大模型更流行的是门控类型的激活函数,首先简单补充一下最基础的GLU(Gated Linear Unit)。GLU由两部分组成,a和b,其中a是原始输入,b用于计算门控信号。注意这里的a和b其实都是输入x的变换,始终输入就一个x(见下面代码),门控信号是通过对b使用Sigmoid函数得到,这个信号介于0和1之间,然后与a相乘(⊗表示逐元素乘法),从而动态调整每个元素的传递。GLU允许部分信息根据门控信号的强度传递,而抑制其他信息。3. SwiGLU(Switched Gated Linear Unit)
SwiGLU是GLU的一个变体,它将输入分为两部分,一部分通过线性变换,另一部分由新的线性变换(通过权重$W_b$和偏置$B_b$,先对b应用一个额外的线性变换)然后套个sigmoid函数得到,允许门控信号不仅仅依赖于原始输入的状态,还依赖于通过训练学到的变换,使得模型可以学习到更加复杂的非线性表示。- 提高模型复杂度:通过门控机制,模型可以捕捉更复杂的特征。
- 计算复杂度增加:由于增加学习参数W和b,SwiGLU的计算成本更高。
4. GeGLU(Gated Linear Unit with Gaussian Error Linear Unit)
GeGLU是GeLU的一个变体,结合了门控机制。它通常包括两个并行的分支,一个应用线性变换,另一个应用GeLU变换,然后将两者相乘。GeGLU综合了GeLU的自适应性和门控机制的优点,旨在提供更加强大和灵活的激活功能。- 增强表示能力:通过结合GeLU和门控机制,提供更强大的模型表示能力。
- 计算复杂度:同样的,计算成本较高,特别是在大型模型中。
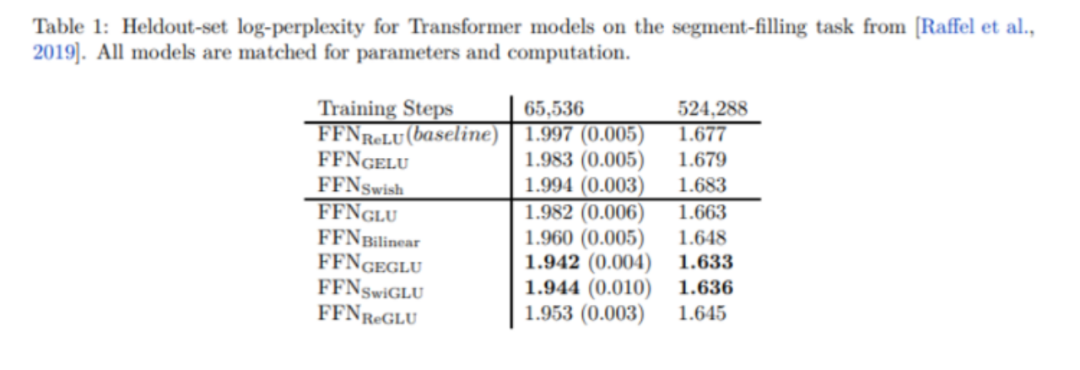
在Gemma中就是采用GeGLU Activations,从代码中可以看到,门控机制是通过输入数据$x$的变换作为门控信号的生成方式,然后再与另一个变换的输入数据进行元素级别的乘法操作,最终通过另一个线性变换调整输出维度。关于使用选择问题,提出GLU变形的作者在T5模型上做过不同激活函数的消融实验效果对比,从这个实验看,GeGLU和SwiGLU综合来看是效果最好的,这两个激活函数也是目前主流基座大模型被采用的。
归一化方式
模型中使用归一化(Normalization)技术,主要是为了提高深度学习网络的训练效率、稳定性和泛化能力。归一化通过对输入数据或网络层的激活值进行处理,使其分布更加规范,从数学的角度来看,这个操作有助于优化损失函数的几何特性。没进行归一化的数据可能导致损失函数表面出现尖锐的曲率,这使得找到最优解变得困难。归一化有助于使损失函数的等高线更加规则,从而使梯度下降等优化算法更容易找到全局最小值。此外,对于深度学习模型来说,每一层的输出都依赖于前一层的参数。如果不进行归一化,这种依赖关系可能导致激活值在网络深层中累积偏差,归一化通过规范这些值,确保了网络深层依然可以接收到有效的梯度信息,提高模型学习效率,不会导致梯度爆炸或消失等问题。接下来介绍一下主流的大模型使用的归一化方式。Batch Normalization (Batch Norm)Batch Norm核心思想是在网络的输入的每一个batch上应用归一化,使得该批数据输入分布保持相同。由于其与图像数据特性比较契合,特别是在处理大规模图像数据集和训练深层网络时,通常会有比较好的效果。假设一个层的输入为X={x1,x2,...,xm},其中m是批量大小。Batch Norm 归一化步骤如下:- 计算批量均值:
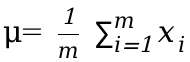 ;
; - 计算层方差:
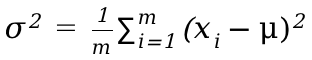 ;
; - 归一化:
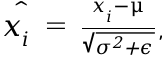 ,其中ϵ是一个很小的数,防止分母为零;
,其中ϵ是一个很小的数,防止分母为零; - 位移和缩放:
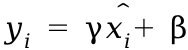 ,其中γ和β是可学习的参数,用于恢复归一化可能丢失的表示能力。
,其中γ和β是可学习的参数,用于恢复归一化可能丢失的表示能力。
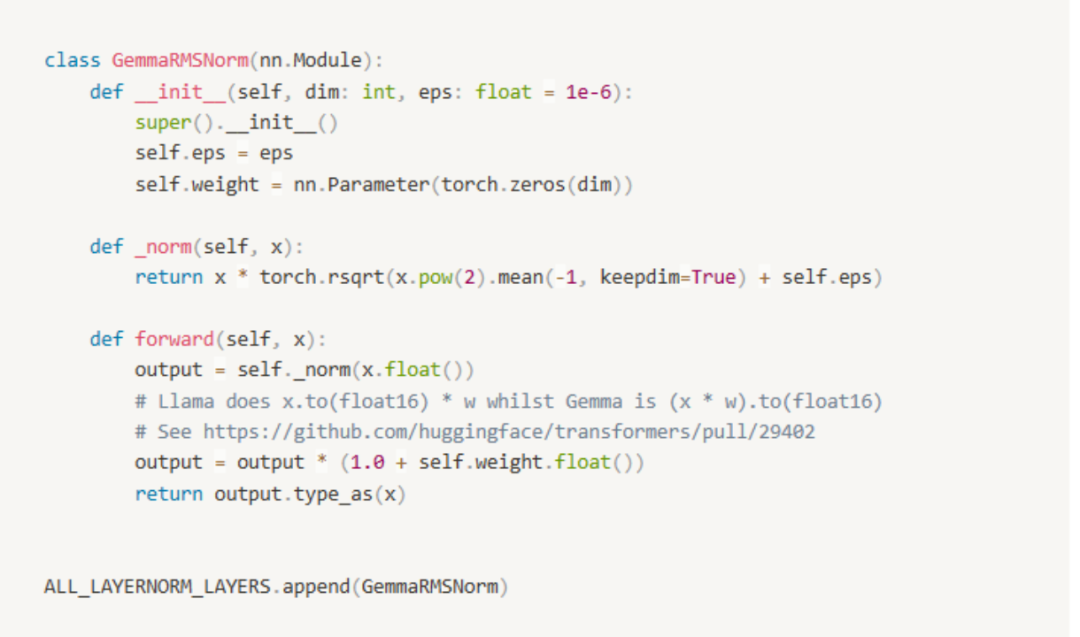
但是批归一化也有一些明显问题。比如对批量大小敏感,较小的批量大小会导致估计的均值和方差不准确,影响模型性能;另外在类似语言的可变长序列模型中应用不够灵活,因为批的每条样本序列长度必须保持一致,在语言的样本中经常会有batch中句子长短不一,如果用这个方法则需要对token空的对应位置进行padding操作,导致效率低下。所以现在很多语言模型会采用Layer Normalization,来解决了对批量大小敏感的问题,通过在特征维度上进行标准化而不是批量维度,使得它适用于小批量和可变长度序列的处理。Layer Normalization (Layer Norm)主要用于解决 RNNs 和其他序列模型中的训练问题。与 Batch Norm 最大的不同,Layer Norm 在单个样本的所有维度的输入上进行归一化,而不是在一个批量的维度上进行归一化。公式:基本与batch norm步骤一样,最大区别就是输入的X的m维换成向量或者特征的维度数值,按照这个维度对每个x进行归一化计算。值得注意的是,layer norm是针对单个样本的每个特征进行的(类比NLP任务中句子转换成的每个token),而不是跨样本。这使得 Layer Norm 特别适用于处理时间序列数据和循环神经网络,可以不依赖于批次的大小,稳定的处理不同时间步长的序列数据。本次Gemma采用的就是RMSNorm,这种方式基于每层激活的均方根(Root Mean Square)来进行归一化。RMS Norm 其实在简化 Layer Norm 的计算,通过省略均值的计算,直接使用方差进行归一化。虽然简化了计算,但是从效果上看,基本与Layer Norm持平,并且拥有更快的收敛速度(从计算角度容易理解)。该公式简化了Layer Norm 的计算,降低了计算复杂度。也有文章(见Ref: 2102.11972)做了很多对比实验证明这种方式的有效性,从而使得众多主流大模型都采取这种方式。
03 总结
该文旨在带领想要深入了解大模型技术领域的同学进行一个回顾形式的总结,在大模型发展迅速的时代,以上的内容几乎是每个技术同学接触大模型的人必须掌握的知识,只有从原理出发理解大模型,才能更好地使用大模型为我们提供更大的价值。从微调大模型实践来看,这些知识也在细节上对能否成功训练好一个模型产生比较大的影响,很可能因为上面的某个点理解不到位,导致在具体任务上产生loss相关问题或者测试效果不及预期。下一篇文章将从实践技术角度介绍模型效果优化相关知识。Vaswani, A.et al. (2017) Attention Is All You Need, arXiv.org. Available at: https://arxiv.org/abs/1706.03762.Ainslie, J.et al. (no date) GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. Available at: https://arxiv.org/pdf/2305.13245.pdf.Su, J.et al. (2021) ‘RoFormer: Enhanced Transformer with Rotary Position Embedding’. Available at: https://doi.org/10.48550/arxiv.2104.09864.Google, N. (2020)GLU Variants Improve Transformer. Available at: https://arxiv.org/pdf/2002.05202.pdf.Xiong, R.et al. (2020) On Layer Normalization in the Transformer Architecture. Available at: https://arxiv.org/pdf/2002.04745.pdf.Narang, S.et al. (no date) Do Transformer Modifications Transfer Across Implementations and Applications? Available at: https://arxiv.org/pdf/2102.11972.pdf (Accessed: 1 April 2024).





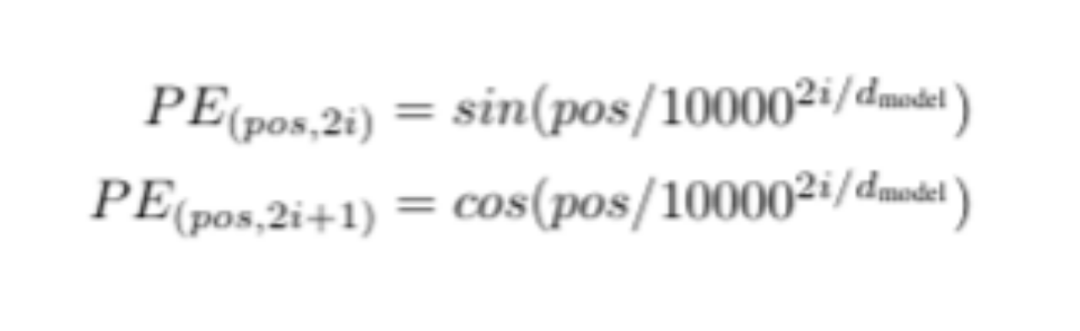
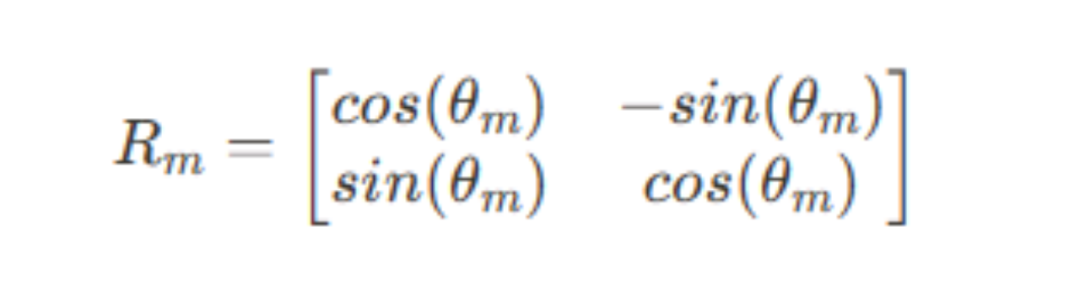
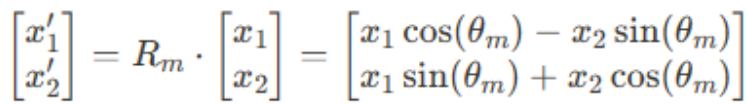
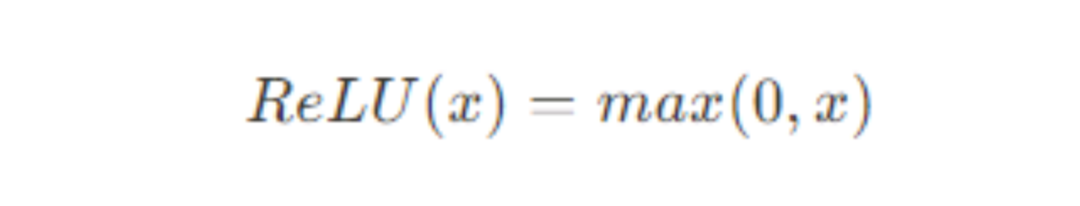
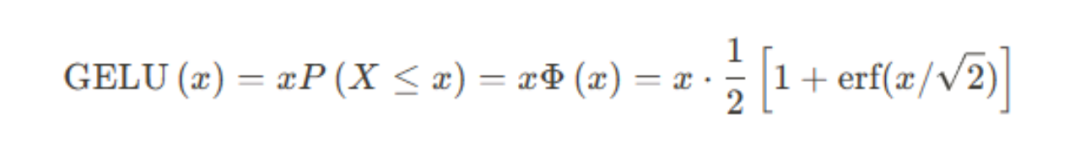
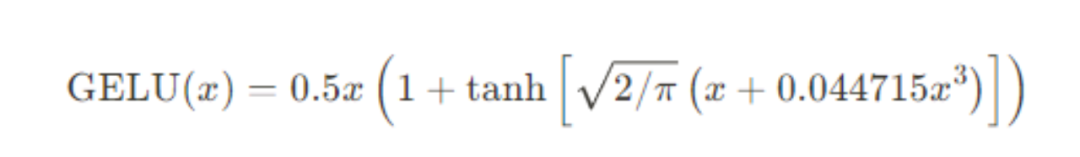
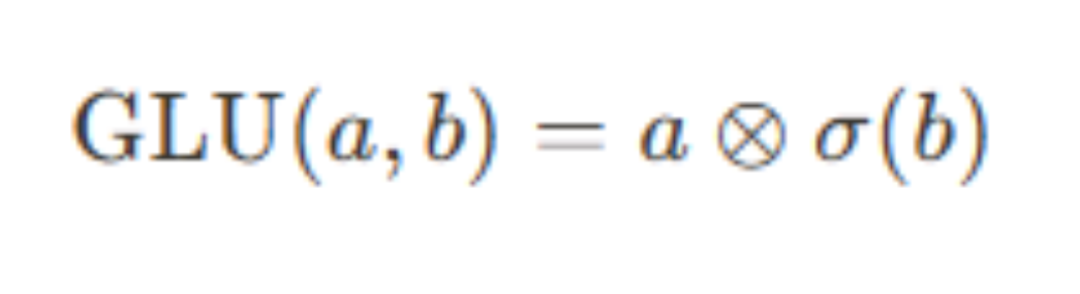
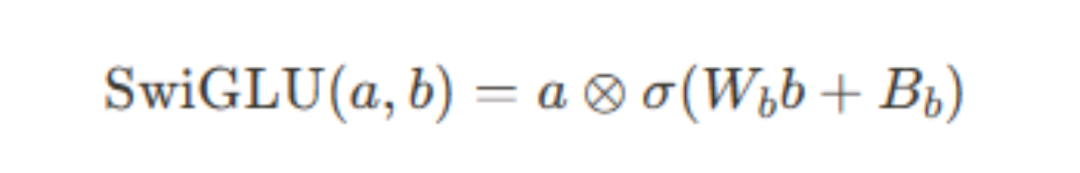
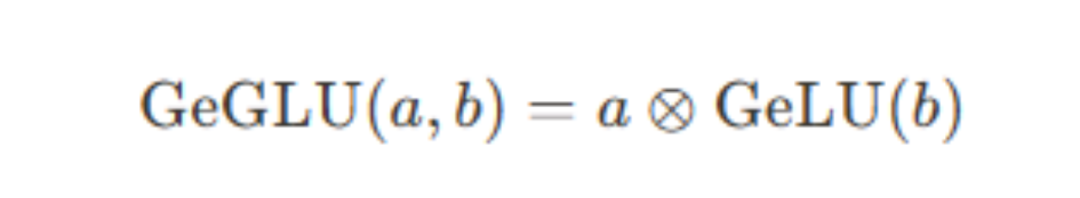



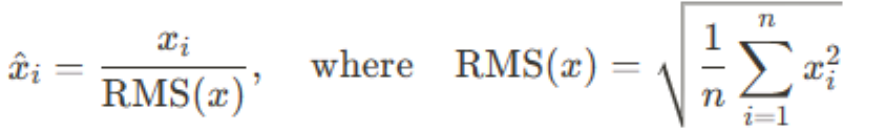


 鲁公网安备37020202000738号
鲁公网安备37020202000738号