掌握MySQL优化技巧,一步步提升性能
发表时间: 2022-09-09 16:34
在日常工作中你会从哪些维度进行MySQL性能优化呢?
所谓的性能优化,一般针对的是MySQL查询的优化。既然是优化查询,我们自然要先知道查询操作要经过哪些环节,然后思考可以在哪些环节进行优化。
我用一张图展示查询操作需要经历的基本环节。
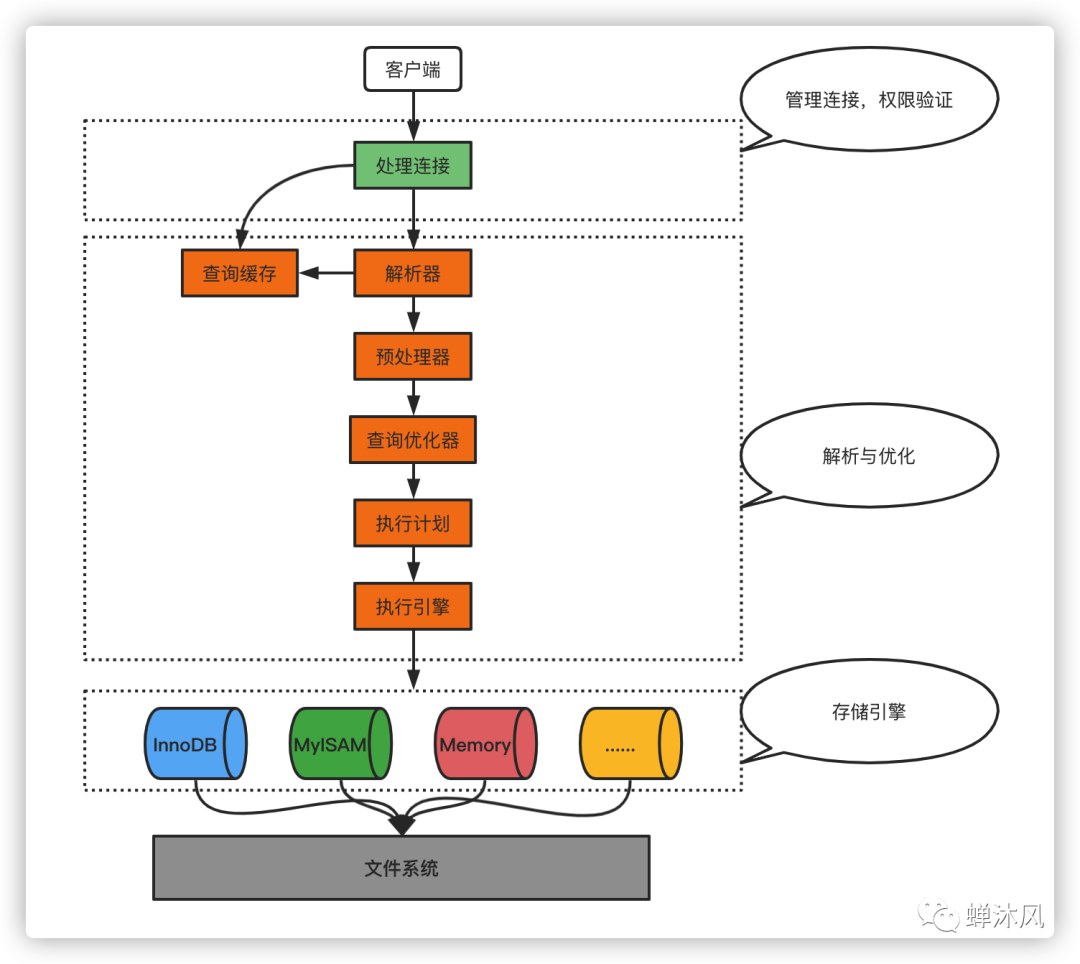
SQL查询的环节
下面从5个角度介绍一下MySQL优化的一些策略。
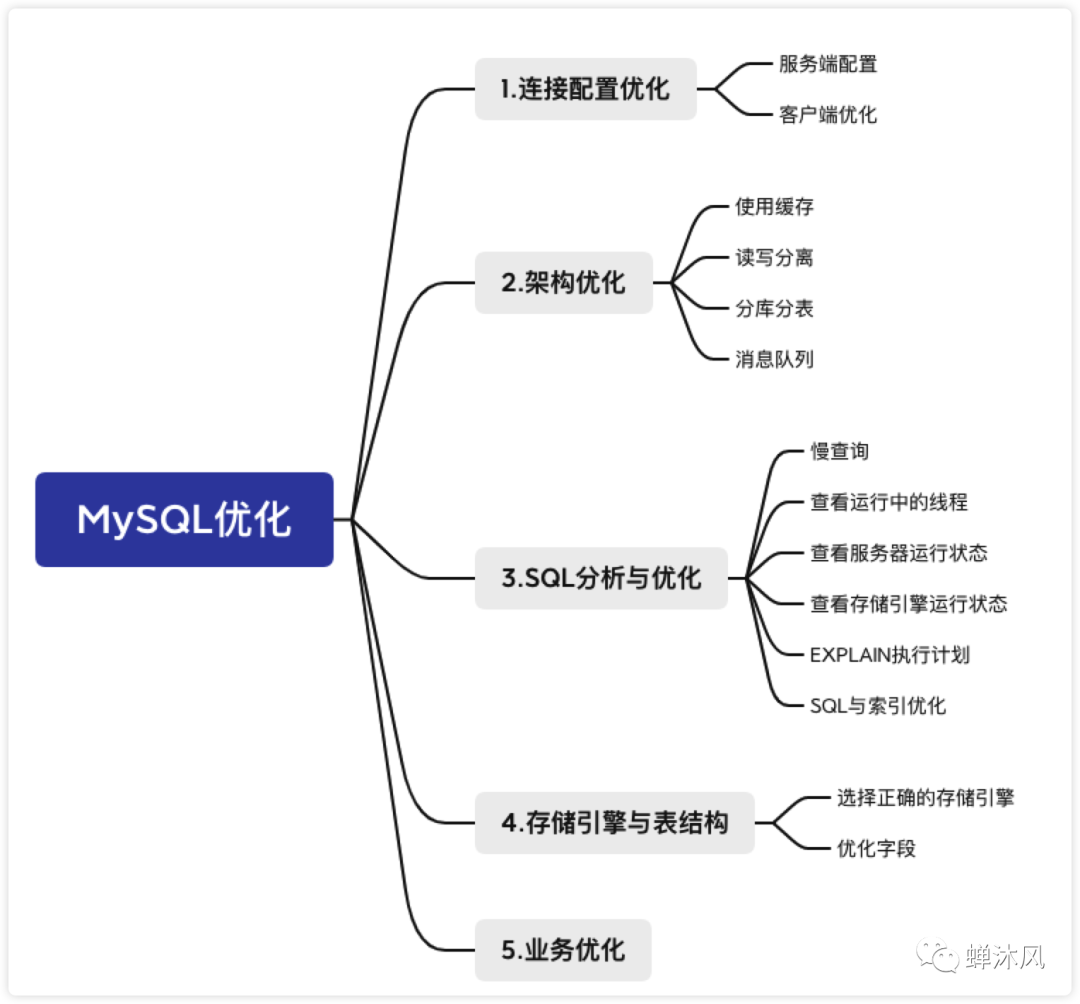
处理连接是MySQL客户端和MySQL服务端亲热的第一步,第一步都迈不好,也就别谈后来的故事了。
既然连接是双方的事情,我们自然从服务端和客户端两个方面来进行优化喽。
服务端需要做的就是尽可能地多接受客户端的连接,或许你遇到过error 1040: Too many connections的错误?就是服务端的胸怀不够宽广导致的,格局太小!
我们可以从两个方面解决连接数不够的问题:
mysql> show variables like 'max_connections';+-----------------+-------+| Variable_name | Value |+-----------------+-------+| max_connections | 151 |+-----------------+-------+1 row in set (0.01 sec)mysql> show variables like 'wait_timeout';+---------------+-------+| Variable_name | Value |+---------------+-------+| wait_timeout | 28800 |+---------------+-------+1 row in set (0.01 sec)MySQL有非常多的配置参数,并且大部分参数都提供了默认值,默认值是MySQL作者经过精心设计的,完全可以满足大部分情况的需求,不建议在不清楚参数含义的情况下贸然修改。
客户端能做的就是尽量减少和服务端建立连接的次数,已经建立的连接能凑合用就凑合用,别每次执行个SQL语句都创建个新连接,服务端和客户端的资源都吃不消啊。
解决的方案就是使用连接池来复用连接。
常见的数据库连接池有DBCP、C3P0、阿里的Druid、Hikari,前两者用得很少了,后两者目前如日中天。
但是需要注意的是连接池并不是越大越好,比如Druid的默认最大连接池大小是8,Hikari默认最大连接池大小是10,盲目地加大连接池的大小,系统执行效率反而有可能降低。为什么?
对于每一个连接,服务端会创建一个单独的线程去处理,连接数越多,服务端创建的线程自然也就越多。而线程数超过CPU个数的情况下,CPU势必要通过分配时间片的方式进行线程的上下文切换,频繁的上下文切换会造成很大的性能开销。
Hikari官方给出了一个PostgreSQL数据库连接池大小的建议值公式,CPU核心数*2+1。假设服务器的CPU核心数是4,把连接池设置成9就可以了。这种公式在一定程度上对其他数据库也是适用的,大家面试的时候可以吹一吹。
系统中难免会出现一些比较慢的查询,这些查询要么是数据量大,要么是查询复杂(关联的表多或者是计算复杂),使得查询会长时间占用连接。
如果这种数据的实效性不是特别强(不是每时每刻都会变化,例如每日报表),我们可以把此类数据放入缓存系统中,在数据的缓存有效期内,直接从缓存系统中获取数据,这样就可以减轻数据库的压力并提升查询效率。
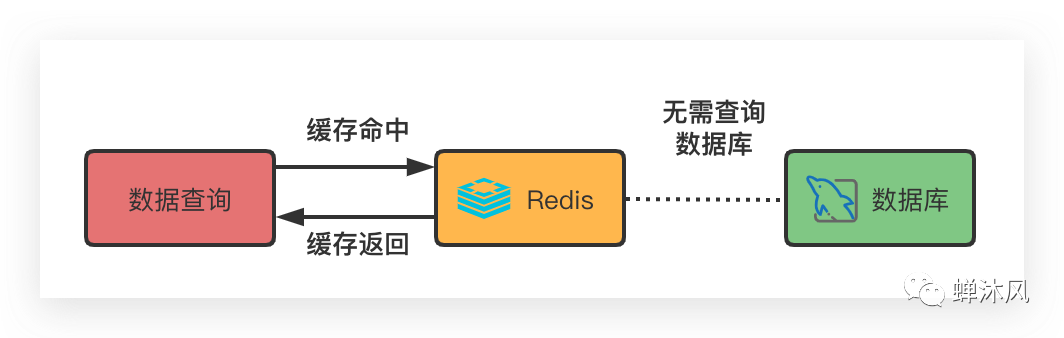
缓存的使用
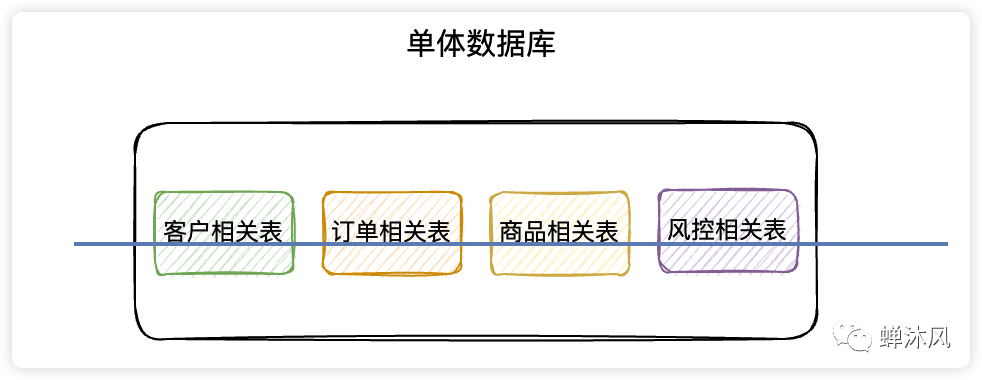
项目的初期,数据库通常都是运行在一台服务器上的,用户的所有读写请求会直接作用到这台数据库服务器,单台服务器承担的并发量毕竟是有限的。
针对这个问题,我们可以同时使用多台数据库服务器,将其中一台设置为为小组长,称之为master节点,其余节点作为组员,叫做slave。用户写数据只往master节点写,而读的请求分摊到各个slave节点上。这个方案叫做读写分离。给组长加上组员组成的小团体起个名字,叫集群。
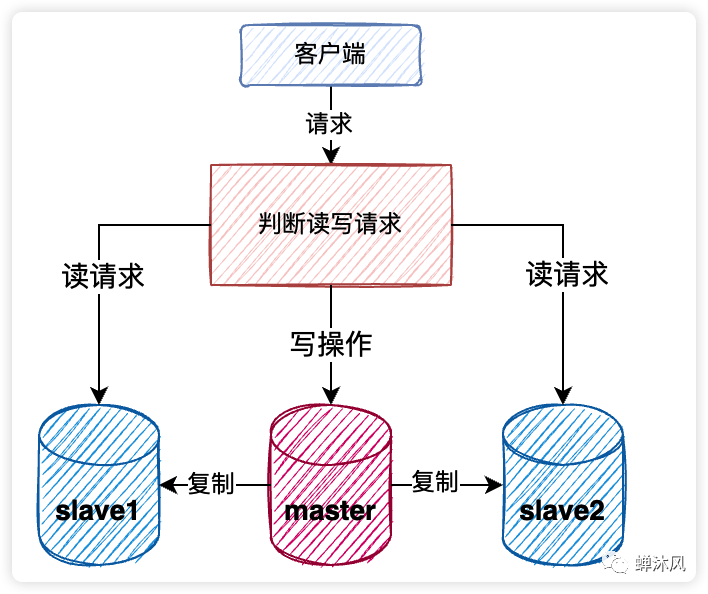
这就是集群
注:很多开发者不满master-slave这种具有侵犯性的词汇(因为他们认为会联想到种族歧视、黑人奴隶等),所以发起了一项更名运动。
受此影响MySQL也会逐渐停用master、slave等术语,转而用source和replica替代,大家碰到的时候明白即可。
使用集群必然面临一个问题,就是多个节点之间怎么保持数据的一致性。毕竟写请求只往master节点上发送了,只有master节点的数据是最新数据,怎么把对master节点的写操作也同步到各个slave节点上呢?
binlog是实现MySQL主从复制功能的核心组件。master节点会将所有的写操作记录到binlog中,slave节点会有专门的I/O线程读取master节点的binlog,将写操作同步到当前所在的slave节点。

主从复制
这种集群的架构对减轻主数据库服务器的压力有非常好的效果,但是随着业务数据越来越多,如果某张表的数据量急剧增加,单表的查询性能就会大幅下降,而这个问题是读写分离也无法解决的,毕竟所有节点存放的是一模一样的数据啊,单表查询性能差,说的自然也是所有节点性能都差。
这时我们可以把单个节点的数据分散到多个节点上进行存储,这就是分库分表。
分库分表中的节点的含义比较宽泛,要是把数据库作为节点,那就是分库;如果把单张表作为节点,那就是分表。
大家都知道分库分表分成垂直分库、垂直分表、水平分库和水平分表,但是每次都记不住这些概念,我就给大家详细说一说,帮助大家理解。
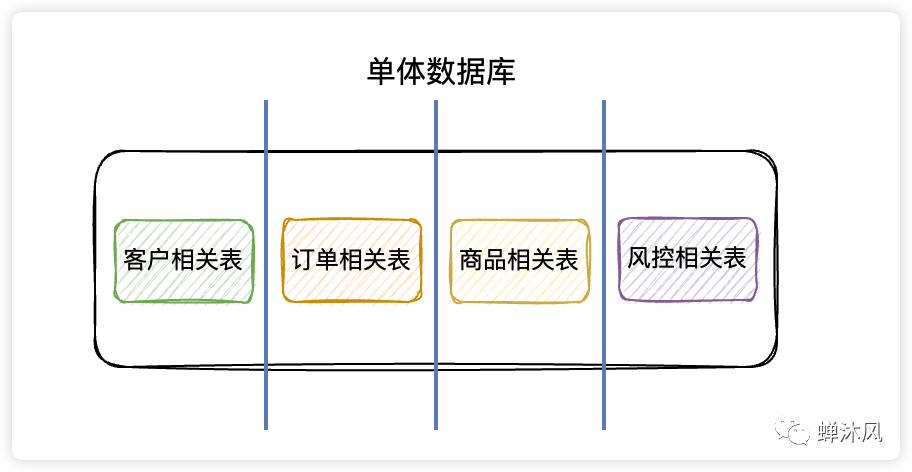
垂直分库
在单体数据库的基础上垂直切几刀,按照业务逻辑拆分成不同的数据库,这就是垂直分库啦。
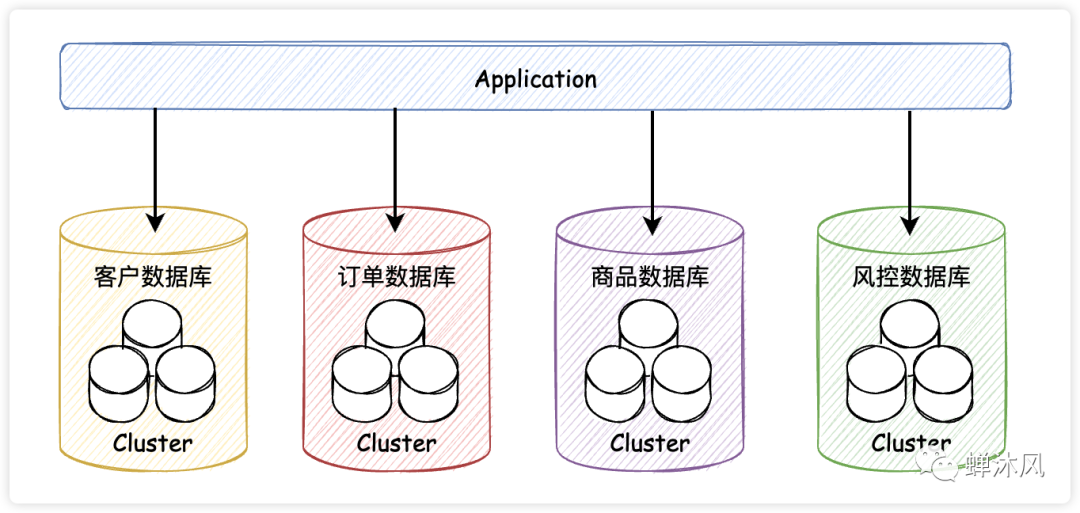
垂直分库
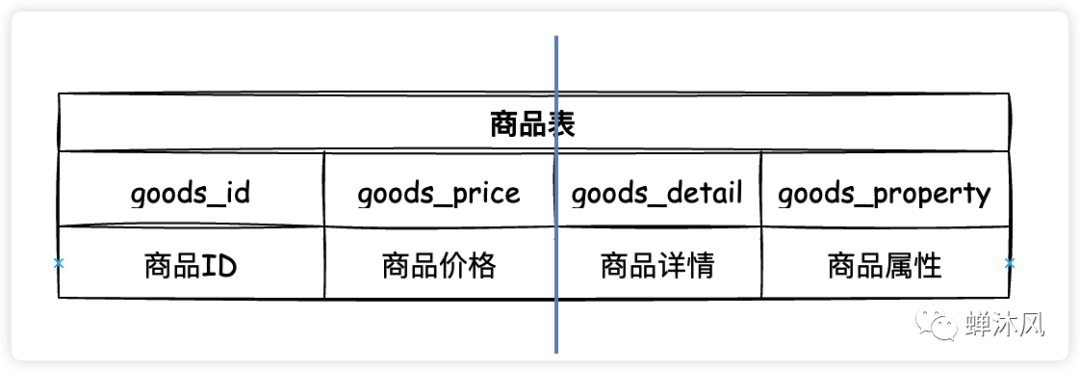
垂直分表
垂直分表就是在单表的基础上垂直切一刀(或几刀),将一个表的多个字短拆成若干个小表,这种操作需要根据具体业务来进行判断,通常会把经常使用的字段(热字段)分成一个表,不经常使用或者不立即使用的字段(冷字段)分成一个表,提升查询速度。
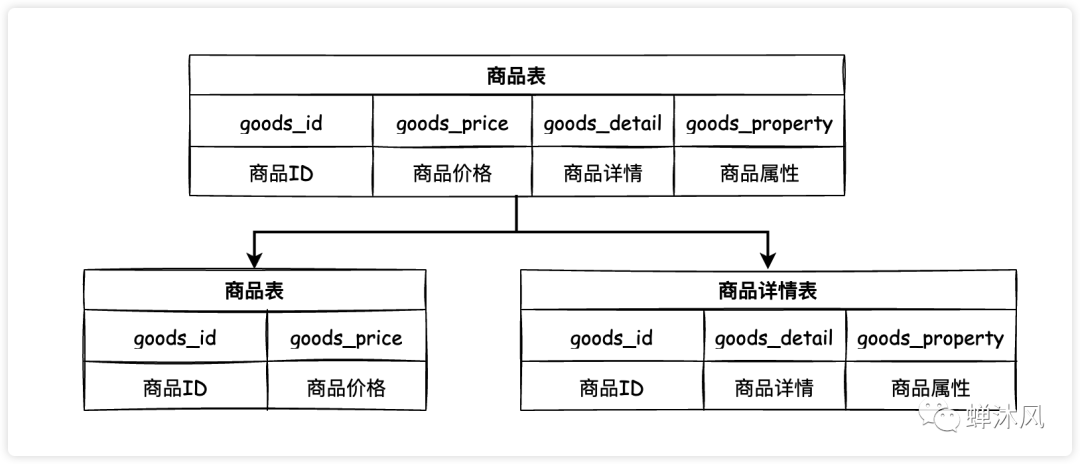
垂直分表
拿上图举例:通常情况下商品的详情信息都比较长,而且查看商品列表时往往不需要立即展示商品详情(一般都是点击详情按钮才会进行显示),而是会将商品更重要的信息(价格等)展示出来,按照这个业务逻辑,我们将原来的商品表做了垂直分表。
把单张表的数据按照一定的规则(行话叫分片规则)保存到多个数据表上,横着给数据表来一刀(或几刀),就是水平分表了。
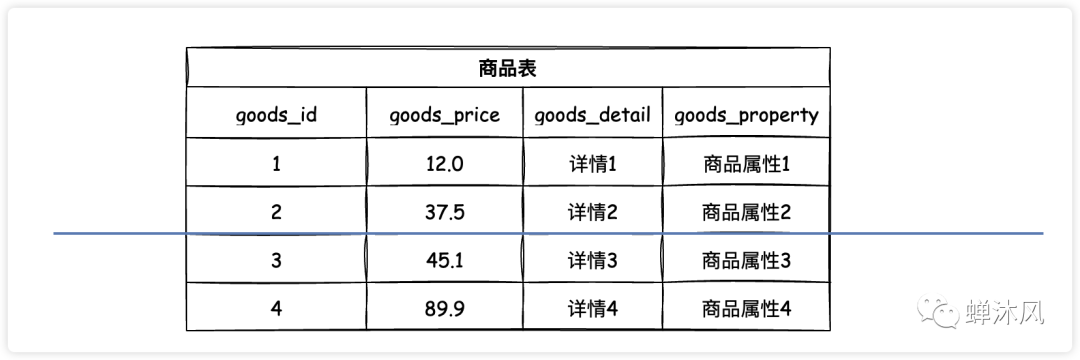
水平分表

水平分表
水平分库就是对单个数据库水平切一刀,往往伴随着水平分表。
水平分库
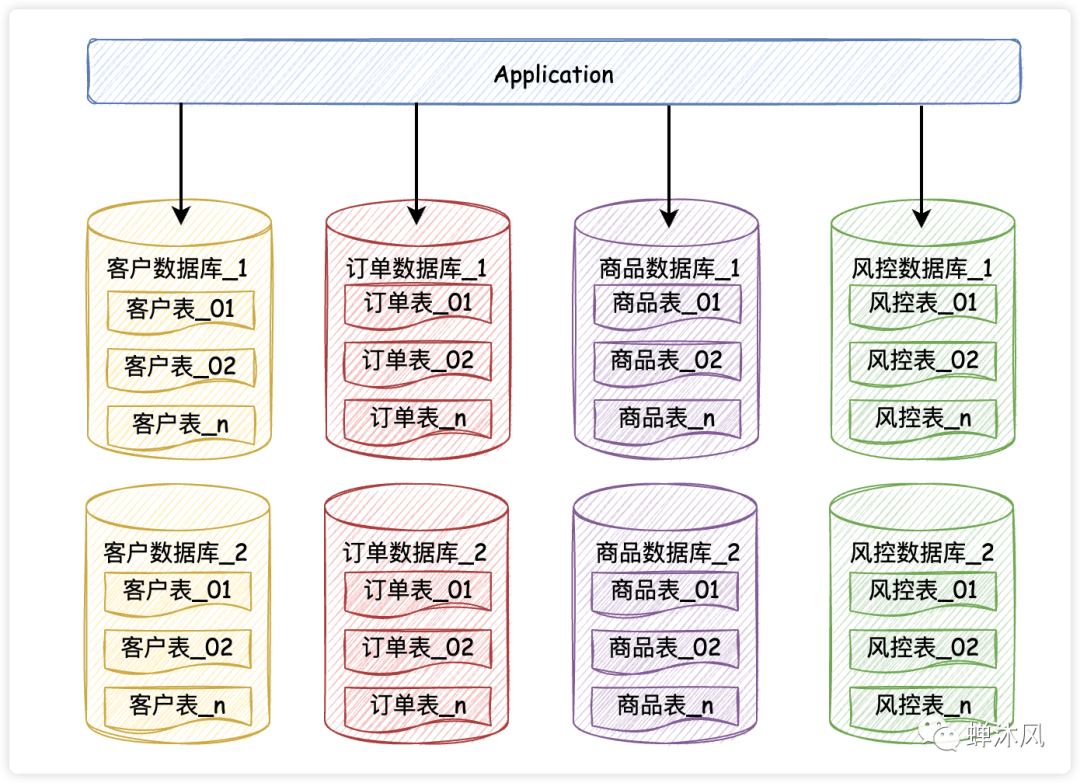
水平分库
水平分,主要是为了解决存储的瓶颈;垂直分,主要是为了减轻并发压力。
通常情况下,用户的请求会直接访问数据库,如果同一时刻在线用户数量非常庞大,极有可能压垮数据库(参考明星出轨或公布恋情时微博的状态)。
这种情况下可以通过使用消息队列降低数据库的压力,不管同时有多少个用户请求,先存入消息队列,然后系统有条不紊地从消息队列中消费请求。
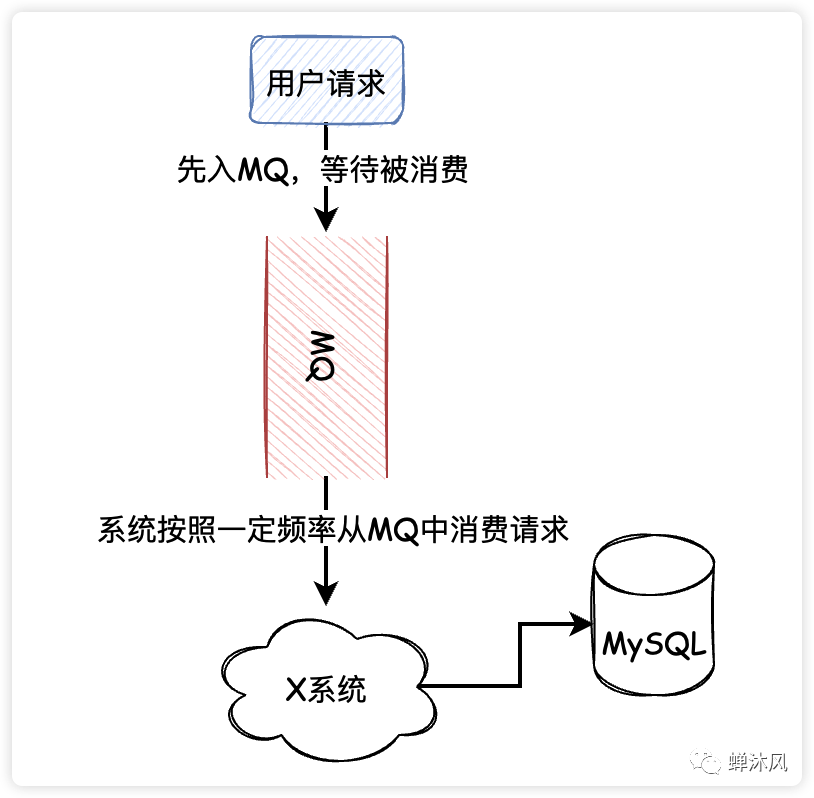
队列削峰
处理完连接、优化完缓存等架构的事情,SQL查询语句来到了解析器和优化器的地盘了。在这一步如果出了任何问题,那就只能是SQL语句的问题了。
只要你的语法不出问题,解析器就不会有问题。此外,为了防止你写的SQL运行效率低,优化器会自动做一些优化,但如果实在是太烂,优化器也救不了你了,只能眼睁睁地看着你的SQL查询沦为慢查询。
慢查询就是执行地很慢的查询(这句话说得跟废话似的。。。),只有知道MySQL中有哪些慢查询我们才能针对性地进行优化。
因为开启慢查询日志是有性能代价的,因此MySQL默认是关闭慢查询日志功能,使用以下命令查看当前慢查询状态
mysql> show variables like 'slow_query%';+---------------------+--------------------------------------+| Variable_name | Value |+---------------------+--------------------------------------+| slow_query_log | OFF || slow_query_log_file | /var/lib/mysql/9e74f9251f6c-slow.log |+---------------------+--------------------------------------+2 rows in set (0.00 sec)slow_query_log表示当前慢查询日志是否开启,slow_query_log_file表示慢查询日志的保存位置。
除了上面两个变量,我们还需要确定“慢”的指标是什么,即执行超过多长时间才算是慢查询,默认是10S,如果改成0的话就是记录所有的SQL。
mysql> show variables like '%long_query%';+-----------------+-----------+| Variable_name | Value |+-----------------+-----------+| long_query_time | 10.000000 |+-----------------+-----------+1 row in set (0.00 sec)有两种打开慢日志的方式
此种修改方式系统重启后依然有效
# 是否开启慢查询日志slow_query_log=ON# long_query_time=2slow_query_log_file=/var/lib/mysql/slow.logmysql> set @@global.slow_query_log=1;Query OK, 0 rows affected (0.06 sec)mysql> set @@global.long_query_time=2;Query OK, 0 rows affected (0.00 sec)MySQL不仅为我们保存了慢日志文件,还为我们提供了慢日志查询的工具mysqldumpslow,为了演示这个工具,我们先构造一条慢查询:
mysql> SELECT sleep(5);然后我们查询用时最多的1条慢查询:
[root@iZ2zejfuakcnnq2pgqyzowZ ~]# mysqldumpslow -s t -t 1 -g 'select' /var/lib/mysql/9e74f9251f6c-slow.logReading mysql slow query log from /var/lib/mysql/9e74f9251f6c-slow.logCount: 1 Time=10.00s (10s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@localhost SELECT sleep(N)其中,
更多关于mysqldumpslow的使用方式,可以查阅官方文档,或者执行mysqldumpslow --help寻求帮助。
我们可以运行show full processlist查看MySQL中运行的所有线程,查看其状态和运行时间,找到不顺眼的,直接kill。

image-20220405182328247
其中,
使用SHOW STATUS查看MySQL服务器的运行状态,有session和global两种作用域,一般使用like+通配符进行过滤。
-- 查看select的次数mysql> SHOW GLOBAL STATUS LIKE 'com_select';+---------------+--------+| Variable_name | Value |+---------------+--------+| Com_select | 168241 |+---------------+--------+1 row in set (0.05 sec)SHOW ENGINE用来展示存储引擎的当前运行信息,包括事务持有的表锁、行锁信息;事务的锁等待情况;线程信号量等待;文件IO请求;Buffer pool统计信息等等数据。
例如:
SHOW ENGINE INNODB STATUS;上面这条语句可以展示innodb存储引擎的当前运行的各种信息,大家可以据此找到MySQL当前的问题,限于篇幅不在此意义说明其中信息的含义,大家只要知道MySQL提供了这样一个监控工具就行了,等到需要的时候再来用就好。
通过慢查询日志我们可以知道哪些SQL语句执行慢了,可是为什么慢?慢在哪里呢?
MySQL提供了一个执行计划的查询命令EXPLAIN,通过此命令我们可以查看SQL执行的计划,所谓执行计划就是:优化器会不会优化我们自己书写的SQL语句(比如外连接改内连接查询,子查询优化为连接查询...)、优化器针对此条SQL的执行对哪些索引进行了成本估算,并最终决定采用哪个索引(或者最终选择不用索引,而是全表扫描)、优化器对单表执行的策略是什么,等等等等。
EXPLAIN在MySQL5.6.3之后也可以针对UPDATE、DELETE和INSERT语句进行分析,但是通常情况下我们还是用在SELECT查询上。
这篇文章主要是从宏观上多个角度介绍MySQL的优化策略,因此这里不详细说明EXPLAIN的细节,之后单独成篇。
SQL优化指的是SQL本身语法没有问题,但是有实现相同目的的更好的写法。比如:
针对最后一条举个简单的例子,下面两条语句能实现同样的目的,但是第二条的执行效率比第一条执行效率要高得多(存储引擎使用的是InnoDB),大家感受一下:
-- 1. 大偏移量的查询mysql> SELECT * FROM user_innodb LIMIT 9000000,10;Empty set (8.18 sec)-- 2.先过滤ID(因为ID使用的是索引),再limitmysql> SELECT * FROM user_innodb WHERE id > 9000000 LIMIT 10;Empty set (0.02 sec)为慢查询创建适当的索引是个非常常见并且非常有效的方法,但是索引是否会被高效使用又是另一门学问了。
一般情况下,我们会选择MySQL默认的存储引擎存储引擎InnoDB,但是当对数据库性能要求精益求精的时候,存储引擎的选择也成为一个关键的影响因素。
建议根据不同的业务选择不同的存储引擎,例如:
字段优化的最终原则是:使用可以正确存储数据的最小的数据类型。
MySQL提供了6种整数类型,分别是
不同的存储类型的最大存储范围不同,占用的存储的空间自然也不同。
例如,是否被删除的标识,建议选用tinyint,而不是bigint。
你是不是直接把所有字符串的字段都设置为varchar格式了?甚至怕不够,还会直接设置成varchar(1024)的长度?
如果不确定字段的长度,肯定是要选择varchar,但是varchar需要额外的空间来记录该字段目前占用的长度;因此如果字段的长度是固定的,尽量选用char,这会给你节约不少的内存空间。
非空字段尽量设置成NOT NULL,并提供默认值,或者使用特殊值代替NULL。
因为NULL类型的存储和优化都会存在性能不佳的问题,具体原因在这里就不展开了。
这也是「阿里巴巴开发手册」中提到的原则。原因有三个:
不要直接存储大文件,而是要存储大文件的访问地址。
大字段拆分其实就是前面说过的垂直分表,把不常用的字段或者数据量较大的字段拆分出去,避免列数过多和数据量过大,尤其是习惯编写SELECT *的情况下,列数多和数据量大导致的问题会被严重放大!
字段冗余原则上不符合数据库设计范式,但是却非常有利于快速检索。比如,合同表中存储客户id的同时可以冗余存储客户姓名,这样查询时就不需要再根据客户id获取用户姓名了。因此针对业务逻辑适当做一定程度的冗余也是一种比较好的优化技巧。
严格来说,业务方面的优化已经不算是MySQL调优的手段了,但是业务的优化却能非常有效地减轻数据库访问压力,这方面一个典型例子就是淘宝,下面举几个简单例子给大家提供一下思路:
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号