解析人工智能的工作原理
发表时间: 2024-05-19 15:08
本文全面介绍了人工智能(AI)的工作原理,包括其定义、组成部分以及如何逐步构建和运用AI系统。文章从数据收集、预处理、模型选择、训练、测试评估、优化、部署到持续学习等各个环节,详细阐述了AI的工作流程,旨在帮助读者更好地理解AI技术及其应用,希望对你有所帮助。

人工智能 (AI) 是一项不断发展的技术,旨在模仿人类智能。它帮助计算机学习如何像人脑一样推理、学习和解决问题。
从医疗保健到金融等行业正在实施人工智能技术,对我们的生活产生有意义的积极影响。人工智能在自动驾驶汽车和个人助理等领域具有进步的潜力,可能会推动科学突破,增强医疗扫描能力,并实现准确的面部识别。
随着人工智能研究的加速以及人工智能的应用在商业和个人生活中发挥越来越大的作用,了解人工智能的工作原理以及如何使用它比以往任何时候都更加重要。
本文全面概述了人工智能,包括其组件以及其工作原理的逐步介绍!
人工智能是计算机科学的一个领域,试图模拟人类的思维方式。您将数据源中的信息提供给人工智能系统,让人工智能处理它,并创建使用输入数据作为参考的经过训练的模型。
拥有的数据越多,人工智能系统就能学得越好。
然而,并非所有人工智能系统都需要大数据源。您可以使用不同的技术训练一些具有较小数据集的模型,例如强化学习(一种机器学习技术,我们接下来讨论)。
完成后,您可以向 AI 提出问题,让它根据学到的知识进行估计并采取行动。但人工智能响应的程度和准确性主要取决于训练数据的质量和算法。
您可以通过多种方式使用 AI 解决方案,包括:
机器学习(ML) 是人工智能系统学习的基础。您提供给机器学习工具的数据可帮助人工智能创建数据集,以学习如何做出决策和预测,而无需进行编程来执行特定任务。
然而,虽然机器学习允许人工智能系统从数据中学习,但它们仍然需要编程和算法来处理数据并生成有意义的见解。
机器学习的工作原理是为工具提供大量数据。然后,您可以处理该数据以创建可用于处理人工智能任务的数学模型。从本质上讲,它允许人工智能应用程序像人类一样执行任务。
图像分类就是一个很好的例子。假设您想训练人工智能识别猫。
您可以向机器学习系统提供猫图像并将它们标记为猫。然后,系统会从您提供的内容中学习,并在训练完成后识别您提供的任何猫图片。
神经网络是一种机器学习算法,它提供了处理基于人工智能模型创建的信息的工具。它们由相互连接的节点(或人工神经元)组成。
这些节点根据进入神经网络的信息进行调整。这使得神经网络能够发现数据中的关系和模式。
节点分为几层,每层都有自己的功能:
深度学习是一种具有多个隐藏层的神经网络,因此它可以学习数据中更复杂的关系。然后,数据科学家可以使用不同的格式(文本、音频、视频和图像)优化这些层,以提高准确性,但他们还需要更多的培训才能工作。数据:人工智能的燃料
数据是人工智能系统的“燃料”。如果没有大量数据集来训练人工智能模型,人工智能就不会具有任何功能。
好的人工智能训练数据具有几个特征,包括:
您使用多种类型的数据来训练人工智能系统,分为三类:结构化、非结构化和半结构化。
结构化数据具有预定义的格式。想想日期、地址、信用卡号码、数字系列和其他标准输入方法。输入人工智能系统的每条数据都会有一个标准格式。
非结构化数据缺乏任何特定信息。输入非结构化文本、图像、视频和图像,让 AI 找到数据中的模式。人工智能可以使用自然语言处理(NLP)、计算机视觉和其他方法来处理信息。
如果没有预定义的模型,您可以使用半结构化数据。此数据使用 JSON、XML 和 CSV 等文件格式。走这条路将为您带来非结构化数据源的好处以及轻松存储训练数据的能力。
算法是人工智能的支柱。它们是告诉人工智能如何学习、改进决策和解决问题的数学程序。算法将原始数据转化为您每天可以使用的见解。
人工智能程序中使用的流行算法包括:
这些算法的工作原理是获取您输入的数据并将其输入到算法中。您提供的高质量数据越多,算法就越容易找到模式并将其转化为可行的见解!
既然您了解了人工智能是什么,您可能想知道如何在实践中使用它。本节将引导您逐步完成构建人工智能系统的过程。
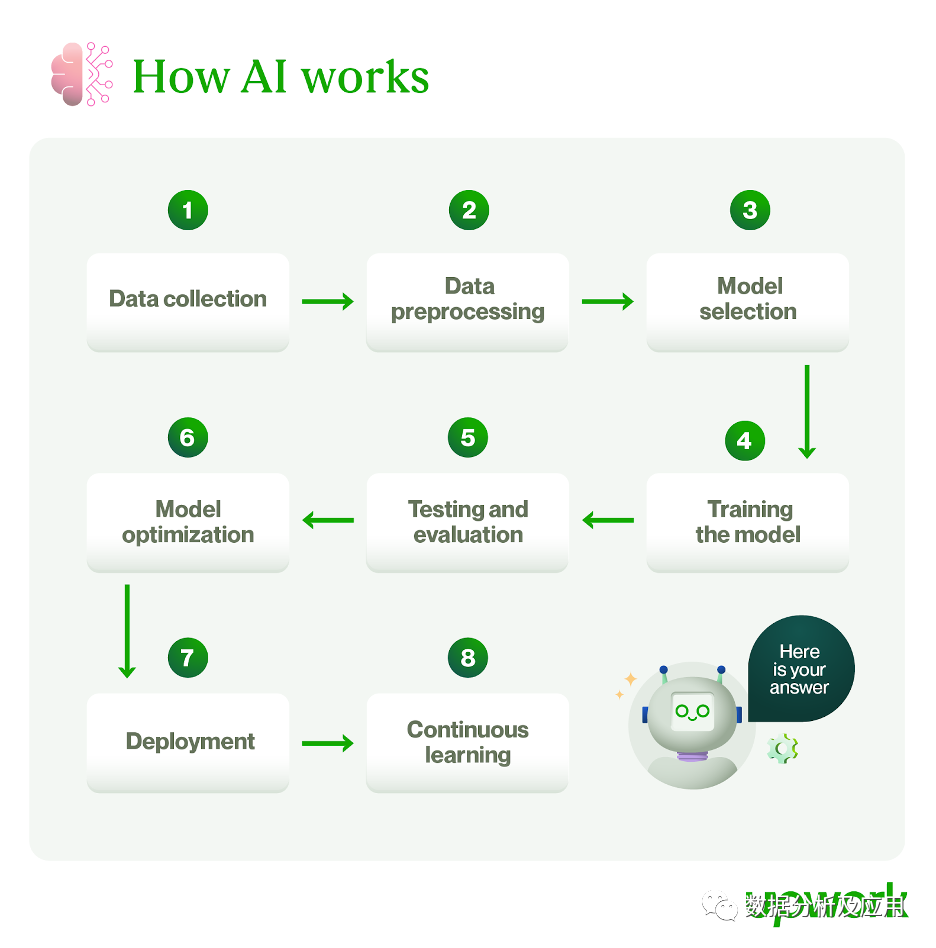
数据收集是开发人工智能系统最关键的部分之一。这是收集大量数据来训练人工智能系统的过程。
您的训练数据可以是任何格式:文本、数字、图像、视频或音频。数据的格式取决于您使用的是结构化数据集还是非结构化数据集。
让我们以查看社交媒体帖子对品牌的情绪为例。从社交媒体收集大量数据集并对这些帖子的情绪进行分类。它们是积极的、消极的还是中性的?
将这些结果放入 CSV 文件中以进行训练。完成后,您可以确定您的品牌在网上的情感。
您不应该只输入找到的数据。人工智能系统需要准确、最新且相关的信息才能获得最佳结果。如果不预处理数据,就无法保证这种情况会发生,尤其是当您拥有大量数据时。
噪声去除(也称为数据平滑)是一项重要过程。这意味着查找并删除任何损害学习过程的数据并修复任何结构化数据的格式。
以正在接受财务分析训练的人工智能模型为例。查看您的训练数据(例如股票价格和利率),以查找任何格式不正确的值。包含或删除美元符号,确保小数位于正确的位置,并删除任何其他异常情况。
模型选择是人工智能开发过程中的一个步骤,您可以在其中选择最适合当前问题的人工智能模型。许多人工智能模型都可用,包括机器学习算法、深度神经网络或使用各种技术的混合模型。
除了不同类型的人工智能算法之外,还可以使用多种类型的机器学习:
监督学习。依靠人工标记的数据来学习和获取知识。
无监督学习。依靠未标记的数据和学习模式来获取知识。
强化学习。依靠人工智能与环境的交互来从错误中学习并获取知识。
深度学习模型可以通过多层转换数据。它适合更复杂的任务。
您选择的模型将取决于几个因素,包括:
当您预处理数据并选择模型时,就进入了训练阶段。
在此阶段中,您将把数据分为两组:训练集和验证集。训练集是您用来训练模型的数据集,验证(测试)集可帮助您了解模型的训练情况。
您选择的模型将开始读取您的数据集,使用数学和计算模型来查看数据模式并创建输出模型以帮助其做出未来预测。
这所需的时间取决于您拥有的训练数据量以及您计划训练的模型有多大。层数越多,花费的时间就越长,使用的资源也就越多。
您不应该仅仅指望 AI 模型在完成训练后就处于生产状态。根据数据集的质量以及您在预处理方面的工作表现,最终模型可能不会给出很好的结果。
这就是您创建的单独验证数据集可以发挥作用的地方。您的验证数据集包含输入和放入 AI 应用程序后的预期输出。
验证 AI 模型时,您需要进行多次测量。准确度(正确预测的百分比)、精确度(实际为正的预测的百分比)和召回率(正确识别的案例的百分比)是最常见的。
以下几种情况可能会出现问题:
数据不佳。不准确的数据意味着您的模型无法产生良好的结果。
欠拟合。AI模型过于简单,无法捕捉数据模式。
偏见。这些数据倾向于一个方向,并且趋势与人类的偏见相同。
模型优化是提高 AI 模型性能的过程。这可能意味着微调或修改模型参数并使用正则化技术。
微调意味着优化模型的参数。您可以更改神经网络的权重或用于调整模型的 AI 算法。
调整模型的架构意味着在神经网络中添加和删除层,以改变层之间的连接并更好地捕获数据的复杂性。
正则化技术有助于防止过度拟合,当模型在经过训练的数据(而不是未见的数据)上表现良好时,这非常有用。正则化使人工智能更容易泛化并提供更准确的结果。
部署是完成 AI 模型训练和优化后模型开发生命周期的最后阶段。这是将模型集成到现有系统或构建新计算机程序来使用模型的过程。
例如,假设您有一个新的人工智能模型想要用于财务预测。您拥有一家产品业务,并希望了解未来的销售额。
您将把模型与当前的计算机系统联系起来,以获取销售数据、财务和其他相关信息。作为回报,该模型会生成报告,估算您未来可以预期的销售额和收入。
人工智能模型不是一次性训练的东西。您必须定期根据新信息训练模型,以继续看到准确的输出。
您可以通过几种方式来做到这一点。首先是微调您的基础模型。您可以根据初始训练数据生成基础模型,并根据新数据微调该模型。这为您的人工智能模型提供了更新的数据,以做出更准确的预测。
更新人工智能模型的另一种方法是通过强化学习人类反馈(RLHF)。通过此过程,您将监控人工智能系统的反馈并对其进行评分。然后,系统会了解自己做错了什么,并利用该反馈在未来提供更好的结果。概括
如您所见,训练人工智能系统需要几个步骤。
持续学习。不断根据新信息更新您的人工智能模型,以保持其相关性并产生良好的结果。
然而,这只是一个示例过程。并非所有人工智能系统都是相同的,因此您可能需要更改此流程以满足您的独特需求。
本文由人人都是产品经理作者【成于念】,微信公众号:【老司机聊数据】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号