轻松掌握数据结构与算法系列:Radix树图解
发表时间: 2018-11-05 15:10
前言
推出一个新系列,《看图轻松理解数据结构和算法》,主要使用图片来描述常见的数据结构和算法,轻松阅读并理解掌握。本系列包括各种堆、各种队列、各种列表、各种树、各种图、各种排序等等几十篇的样子。
Radix树
Radix树,即基数树,也称压缩前缀树,是一种提供key-value存储查找的数据结构。与Trie不同的是,它对Trie树进行了空间优化,只有一个子节点的中间节点将被压缩。同样的,Radix树的插入、查询、删除操作的时间复杂度都为O(k)。
Radix树特点
插入操作
对romane、romanus、romulus、rubens、ruber、rubicon、rubicundus七个字符串进行插入,开始插入romane,此时树为空,直接创建一个“romane”节点,并将该节点结束标记设为true,随即完成romane的插入。

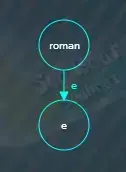
接着插入romanus,此时根节点已经不为空,于是从根节点开始逐个字符进行比较,发现两者前缀“roman”相同,需要分割原来的“romane”节点,先创建一个新的公共前缀“roman”节点,

然后将原来的“romane”节点设为“e”,“e”是“romane”除去公共前缀“roman”后剩下的字符,并将新的公共前缀节点指向“e”子节点,子节点索引为“e”。
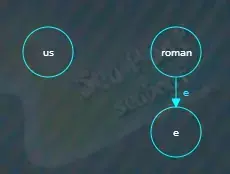
接着继续创建一个新的“us”节点,“us”是“romanus”除去公共前缀“roman”后剩下的字符,
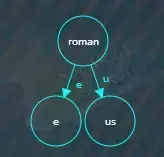
最后将公共前缀“roman”节点指向“us”子节点,索引为“u”,并将“us”节点结束标记设为true。
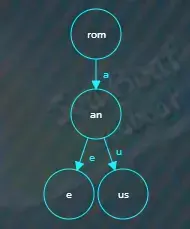
往下插入romulus,从根节点开始逐个字符进行比较,发现两者前缀“rom”相同,需要分割原来的“roman”节点,先创建一个新的公共前缀“rom”节点,
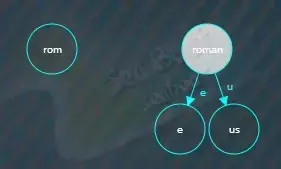
然后将原来的“roman”节点设为“an”,“an”是“roman”除去公共前缀“rom”后剩下的字符,并将新的公共前缀节点指向“an”子节点,子节点索引为“a”。
接着继续创建一个新的“ulus”节点,“ulus”是“romulus”除去公共前缀“rom”后剩下的字符,
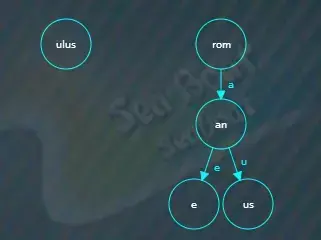
最后将公共前缀“rom”节点指向“ulus”子节点,索引为“u”,并将“ulus”节点结束标记设为true。
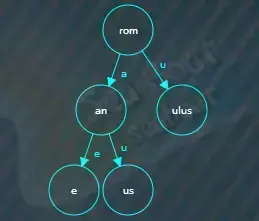
继续插入rubens,从根节点开始逐个字符进行比较,发现两者前缀“r”相同,需要分割原来的“rom”节点,先创建一个新的公共前缀“r”节点,
然后将原来的“rom”节点设为“om”,“om”是“rom”除去公共前缀“r”后剩下的字符,并将新的公共前缀节点指向“om”子节点,子节点索引为“o”。
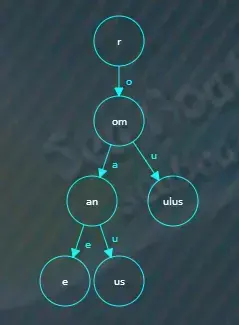
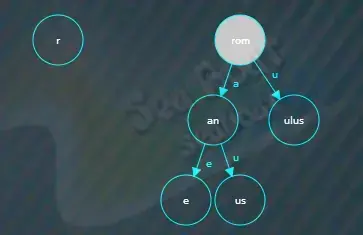
接着继续创建一个新的“ubens”节点,“ubens”是“rubens”除去公共前缀“r”后剩下的字符,
最后将公共前缀“r”节点指向“ubens”子节点,索引为“u”,并将“ubens”节点结束标记设为true。
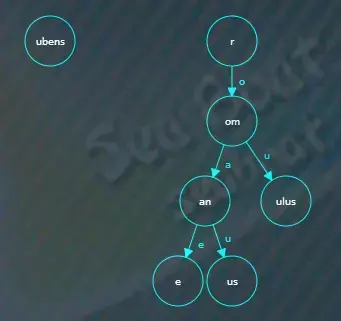
继续插入ruber,从根节点开始逐个字符进行比较,发现比较完“r”后根节点已经没有值可以比较了,于是开始找“r”节点的子节点,
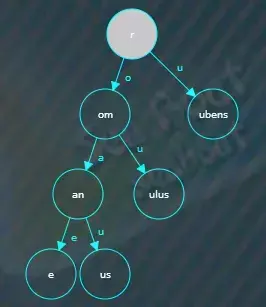
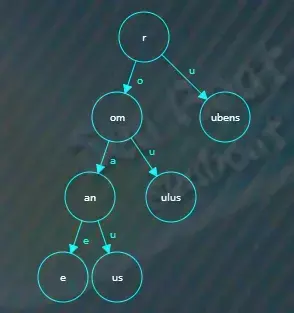
根据第二个字符“u”找到对应的子节点,即“ubens”节点,
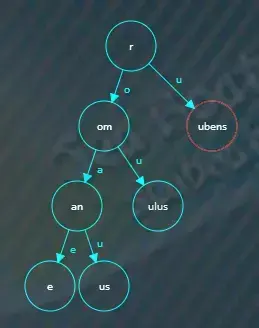
剩余的“uber”字符串继续与该节点进行逐一比较,发现两者前缀“ube”相同,需要分割原来的“ubens”节点,先创建一个新的公共前缀“ube”节点,
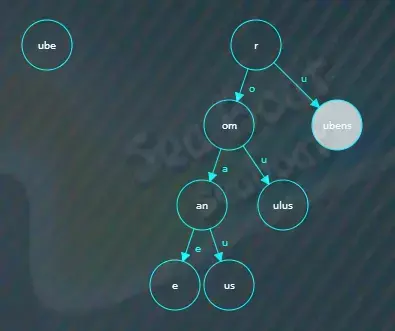
然后将原来的“ubens”节点设为“ns”,“ns”是“ubens”除去公共前缀“ube”后剩下的字符,并将新的公共前缀节点指向“ns”子节点,索引为“n”,此外,原来指向“ubens”节点的“u”索引指向“ube”节点。

接着继续创建一个新的“r”节点,“r”是“ruber”除去公共前缀“r”和“ube”后剩下的字符,
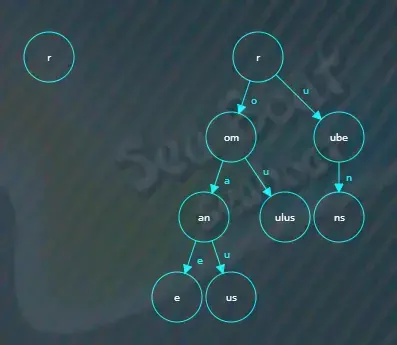
最后将公共前缀“ube”节点指向“r”子节点,索引为“r”,并将“r”节点结束标记设为true。
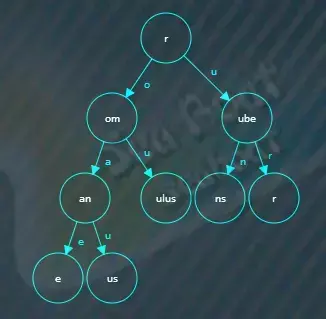
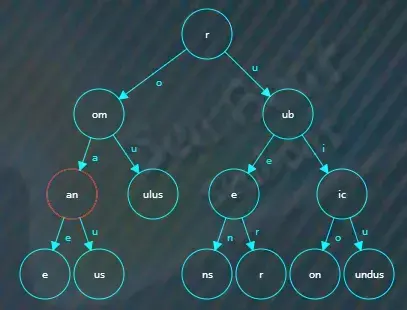
类似地,将rubicon插入树中,结果如下。
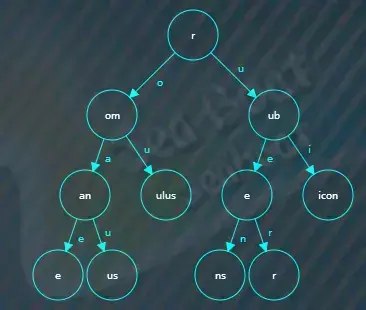
继续插入rubicundus,结果如下。
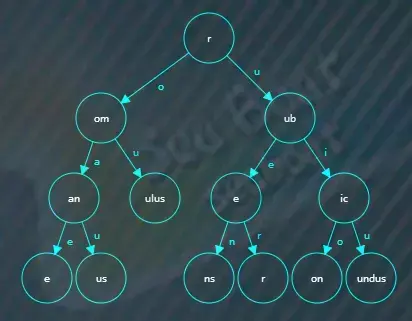
查询操作
假如查找ruok,从根节点开始比较,“r”相等且根节点已经没有值可以继续比较,
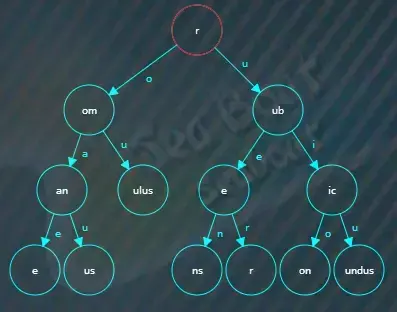
于是根据“u”索引找下一个子节点,在“ub”子节点中继续逐一字符比较,
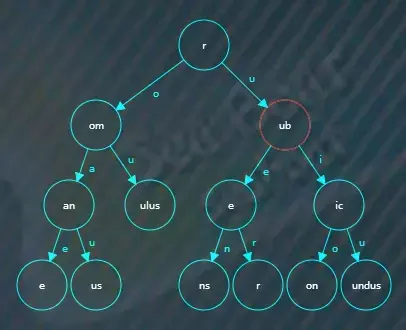
发现没法匹配上“uok”,不存在“ruok”,于是查找结束。
假如查找rubicon,从根节点开始比较,“r”相等且根节点已经没有值可以继续比较,
于是根据“u”索引找下一个子节点,在“ub”子节点中继续逐一字符比较,
比较完该节点后继续根据“i”索引找子节点,在“ic”节点中继续逐一字符比较,
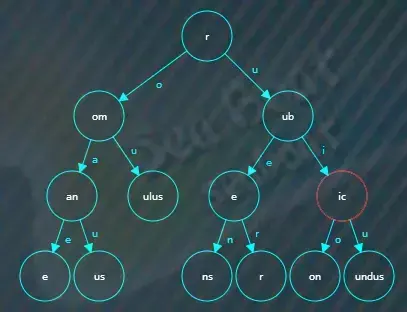
比较完该节点后继续根据“o”索引找子节点,在“on”节点中继续逐一字符比较,此时“rubicon”已经完成所有字符的比较,而且“on”节点的结束标记为true,也就是说存在“rubicon”字符串,查找结束。
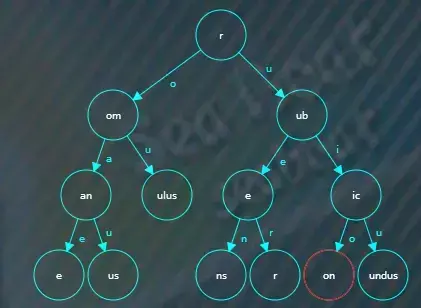
假如查找roman,从根节点开始比较,“r”相等且根节点已经没有值可以继续比较,
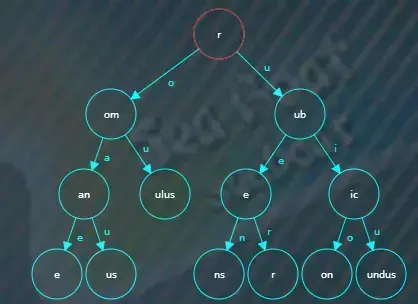
于是根据“o”索引找下一个子节点,在“om”子节点中继续逐一字符比较,
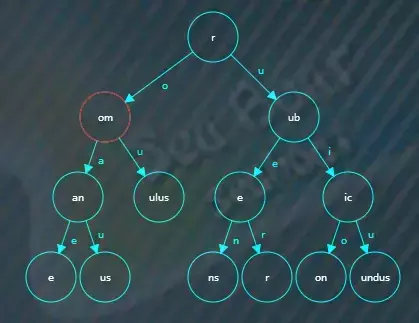
比较完该节点后继续根据“a”索引找子节点,在“an”节点中继续逐一字符比较,此时“roman”已经完成所有字符的比较,但“an”节点的结束标记为false,所以“roman”字符串不存在,查找结束。
需要了解获取最新Python、人工智能、自动化运维方面的技术可以关注我然后私信回复我“Python”获取每日的咨询更新,另外最近在整理一套Python基础的系统教学视频,免费分享给你们,大家可以关注我微头条的更新。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号