那些年,我们共同追逐的缓存数据库时光
发表时间: 2019-08-07 19:31

人生不过如此,且行且珍惜。自己永远是自己的主角,不要总在别人的戏剧里充当着配角。
我以林语堂的《人生不过如此》中一句话来开篇。
在互联网高速发展、快速演化的时代,想必在你的系统架构设计中,缓存服务是不是已经成为必不可少的一层,丰富的数据结构、高性能的读写、简单的协议,让缓存数据库很好的承担起关系型数据库的上层。畅途网为了解决节假日或高峰期的车次查询、抢票等大数据量的访问请求,很早以前就引进了 Redis,来作为数据库的上游缓存层,缓解底层数据库的读写压力。
世界上唯一可以不劳而获的就是贫穷,唯一可以无中生有的是梦想。没有哪件事,不动手就可以实现。世界虽然残酷,但只要你愿意走,总会有路;看不到美好,是因为你没有坚持走下去。人生贵在行动,迟疑不决时,不妨先迈出小小一步。前进不必遗憾,若是美好,叫做精彩;若是糟糕,叫做经历。**——林语堂《人生不过如此》
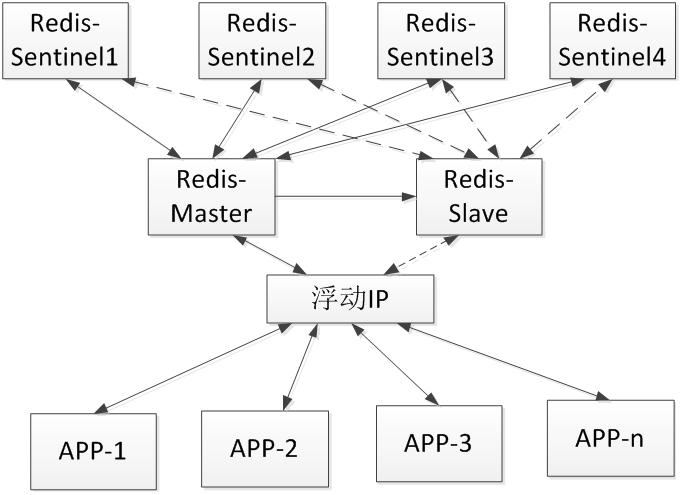
2014 年 10 月,为了避免单点故障,我们尝试在生产环境的 Redis 主从架构中,引入了 Redis Sentinel,实现了 Redis 服务的 failover。当 Redis-Master 主机异常宕机或 Redis-Master 服务异常崩溃时,原有的 Redis-Slave 自动升级为 master 角色,当原有 Redis-Master 恢复后,自动恢复为 slave 角色。
由于 Redis Sentinel 只能做到 Redis 服务级别的切换,无法做到 IP 地址的切换,无法完全满足现网系统架构的需要,我们又尝试在 HA 架构中加入了负载均衡器设备,引用了浮动 IP,所有应用程序访问浮动 IP,IP 地址的切换操作由负载均衡器设备来实现。
Redis Sentinel 配置文件
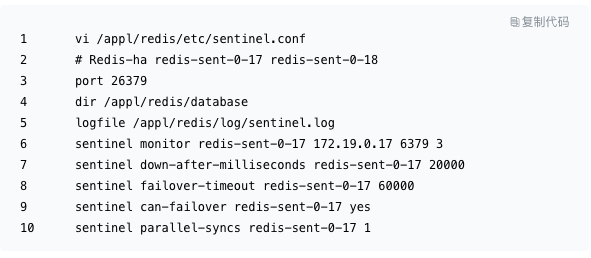
测试小结:
主 Redis 服务器:redis-sent-0-17
从 Redis 服务器:redis-sent-0-18
域名:
redis-sent.cache.changtu.pvt
对应用程序的要求
2015 年新增 2 台 Redis Sentinel 服务器,负责平台所有 Redis 服务器集群管理。并对平台现有 Redis 服务进行改造,逐步升级为 Redis HA 架构。
你可以一辈子不登山,但你心中一定要有座山。它使你总往高处爬,它使你总有个奋斗的方向,它使你任何一刻抬起头,都能看到自己的希望。——林语堂《人生不过如此》
随着畅途网业务量上涨,数据量猛增,单点的 Redis 容量受限于服务器的内存,Redis 主从架构已经力不从心了。在业务系统对性能要求逐渐提高情况下,我们更希望将数据能存在内存中,本地持久化,而不希望写入数据库中。虽然当时用 SSD 将内存换成磁盘,以获取更大的容量,但是我们更想如何将 redis 变成一个可以水平扩展的分布式缓存服务?
在 Codis 发布之前,业界只有 Twemproxy,Twemproxy 本身是一个静态的分布式 Redis 方案,进行扩容、缩容对运维要求非常高,而且很难做到平滑的扩缩容。Codis 的目标就是尽量兼容 Twemproxy,并且加上数据迁移的功能以实现扩容和缩容,最终替换 Twemproxy。本文省略了对 Twemproxy 的介绍。
REDIS-CLUSTER
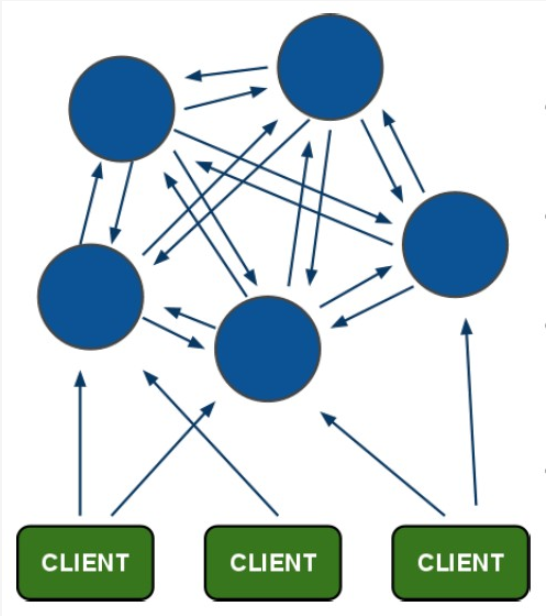
与 Codis 同时期发布的官方 redis-cluster,采用 P2P 的模式,完全去中心化架构, 其实我们花了大精力研究测试过,由于当时对 failover 判断方式提出怀疑,高耦合的模块设计思想、客户端问题、不太友好的维护等方面, 我司目前没有投入生产,没有了实际的生产维护经验,我先不发表看法。抱拳,我知道在缓存数据库里最不应该缺少的就是 Redis-cluster 了,以后有机会单独介绍吧!
容我感叹一下,别指望所有的人都能懂你,因为萝卜白菜,各有所爱。你做了萝卜,自然就做不成青菜。
好了,回归正题,先简单介绍一下 Codis,由豌豆荚于 2014 年 11 月开源,基于 Go 和 C 开发,引用作者的一段原话, Codis 采用一层无状态的 proxy 层,将分布式逻辑写在 proxy 上,底层的存储引擎是 Redis,数据的分布状态存储于 zookeeper(etcd) 中,底层的数据存储变成了可插拔的部件。各个部件是可以动态水平扩展的,尤其无状态的 proxy 对于动态的负载均衡,对业务而言完全是透明的。*
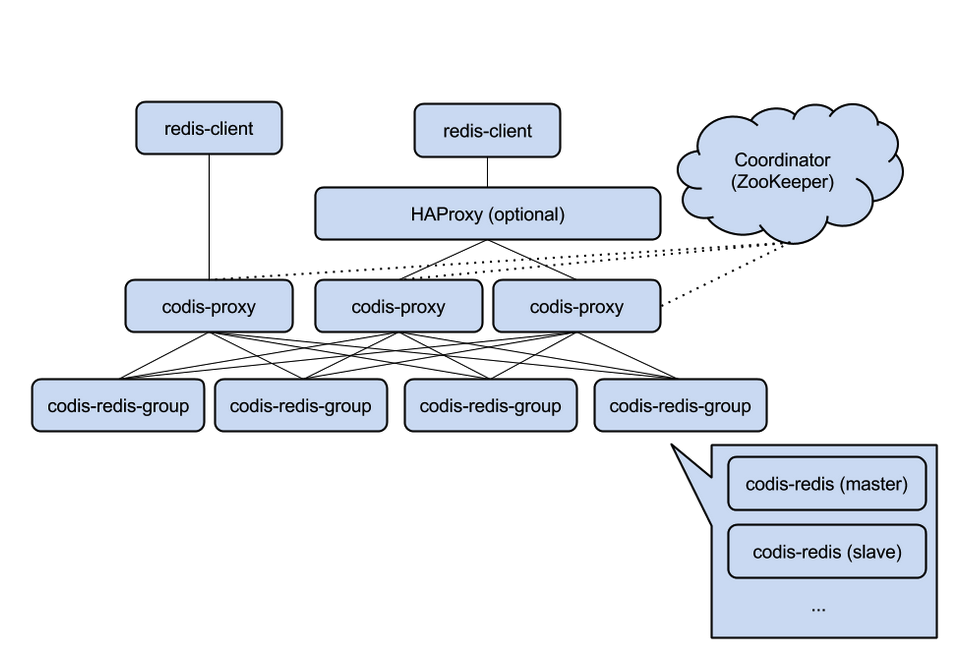
核心组件说明
1. ZooKeeper:
用来存放数据路由表和 Codis-proxy 节点的元信息,Codis-config 发起的命令都会通过 ZooKeeper 同步到各个存活的 Codis-proxy 中。
2. Codis-Proxy :
是客户端连接的 Redis 代理服务,本身是没状态的,Codis-proxy 实现了 Redis 协议,对于一个业务来说,可以部署多个 Codis-proxy, 提供连接集群 Redis 服务的入口。
3. Codis-Config :
是 Codis 的集成管理工具,支持添加 / 删除 Redis 节点、添加 / 删除 Proxy 节点、以及发起数据迁移等操作,Codis-config 还自带了 http server,会启动 dashboard,用户可以在 WEB 上监控 Codis 集群的状态。
4. Codis-Server:
是 Codis 项目维护的一个 Redis 分支,基于 redis-2.8.21 分支开发,增加了额外的数据结构,以支持 slot 有关的操作以及数据迁移指令。
5.Pre-Sharding 技术
Codis 采用 Pre-Sharding 的技术来实现数据的分片, 默认分成 1024 个 slots (0-1023), 对于每个 key 来说, 通过以下公式确定所属的 Slot Id : SlotId = crc32(key) % 1024,每一个 slot 都会有一个特定的 server group id 来表示这个 slot 的数据由哪个 server group 来提供。
在 2016 年 6 月左右,我们引进了 Codis(当时版本是 3.0,并没有 Redis-Sentinel、Codis-fe 等组件,1 年后,才升级到 3.2 的,文章主要以 3.0 版本为背景),首先介绍一下基础环境。

系统架构
在公司硬件资源有限条件下,我们计划用 6 台服务器部署 Codis,简单分了两层,Codis-Proxy 层和 Codis-Server 层。


我们分别通过 jredis 编写测试程序和使用 redis-benchmark 工具模拟压力测试(请求量:1000 万~1 亿,并发数:1000~50000,长度:固定 / 可变):
倔强的青铜
于是组织研发同事进行多次分析讨论,并提出了对缓存服务进行接口改造,经过 2 个多月的辛劳,取得了很大进展,让我们 Codis 项目顺利上线迈开了重要一步,打断一下,容我在此特别感谢一下同事王慧,在他的主导下,完成公司绝大部分缓存服务接口改造工作。
几点改造思路
1. 缓存服务分类。
2. 对缓存服务进行接口改造,新增基础缓存服务层,将生产的 Redis/Codis 相关的服务纳入基础缓存服务进行统一管理。

3.SLOT 的分配
哈希算法
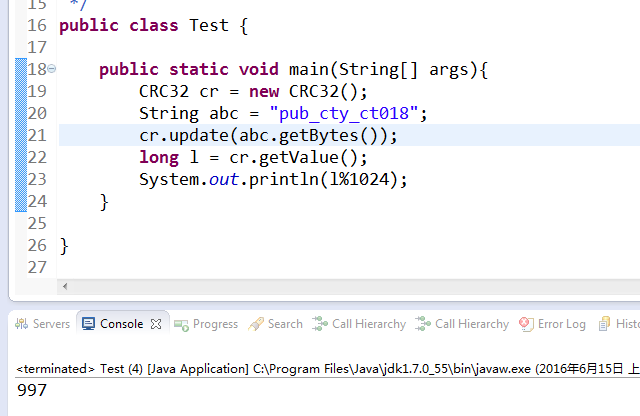
Codis 采用 Pre-sharding 的技术来实现数据的分片, 默认分成 1024 个 slots (0-1023), 对于每个 key 来说, 通过以下公式确定所属的 Slot Id : SlotId = crc32(key) % 1024。例如 pub_cty_ct018 根据算法得出的值是 997。
key 值重定向分配
比如你有一个脚本是操作某个用户的多个信息,如 uid1age,uid1sex,uid1name 形如此类的 key,如果你不用 hashtag 的话,这些 key 可能会分散在不同的机器上,如果使用了 hashtag(用花括号扩住计算 hash 的区域):{uid1}age,{uid1}sex,{uid1}name,这样就保证这些 key 分布在同一个机器上。这个是 twemproxy 引入的一个语法,我们这边也支持了。
以 pub_cty 为例,通过 crc32hash 算法得出,key 存放在 237 slot 中,类似测试了{pub_cty}_ct01,{pub_cty}_ct02…{pub_cty}_ctnn 都存放在 237 slot 中。第一,有了 hashtag 算法支持,我们可以对特定需求的 key 做一些特需的规划,将这些特殊的 key 有序的存放在 codis slot 中,保证 mget/mset, 以及 lua 脚本正常执行。我们目前大概管理 200 多个 redis 键,统一锁定到一个 codis-server(slot)中。第二,在某些极端情况(不希望发生),如某 codis-group 中的 master 异常或崩溃时,我们从程序设计角度,尽可能对出现的无法进行操作 KEY 的行为做一些 " 某种意义上 " 保护。譬如,当某 codis-group 的 maser 宕机时,对 codis 进行写操作,如果对应的 key 落到宕机的主机上,会得到异常或者错误,可以通过捕获异常信息,将异常的 key 通过改变 key 名的规则将其存放到其他 codis-group 上。同理,如果是读取宕机主机上的 key 数据时,将其引导到调整后的 key 上,在一定程度上保障 codis 的完整性(不保障数据不丢失,只保证业务系统操作缓存数据完整性)。
有点意思的整改
在长达几年的迭代演变过程中,维护团队推动多次缓存服务架构的升级与优化,缓存服务逐渐完善和稳定。 记下了一些“有点意思”的整改,提供大家参考。
热点数据
统计缓存热点数据,在基础缓存服务层上假设二级缓存,作为热点数据的快速通道,具备可动态获取,最快访问,少变化的特点 。
根据缓存服务各主、子键关系,使用 index_{主键}的方式来作为管理主子键关系的 SortedSet 集合,统计数据的使用频率,抽取 Top100 的数据,作为热点数据。对这批数据进行分析,结合数据的改动频率,制定这批数据缓存在内存中的时长。
二级缓存设计
缓存数据列表生成与维护
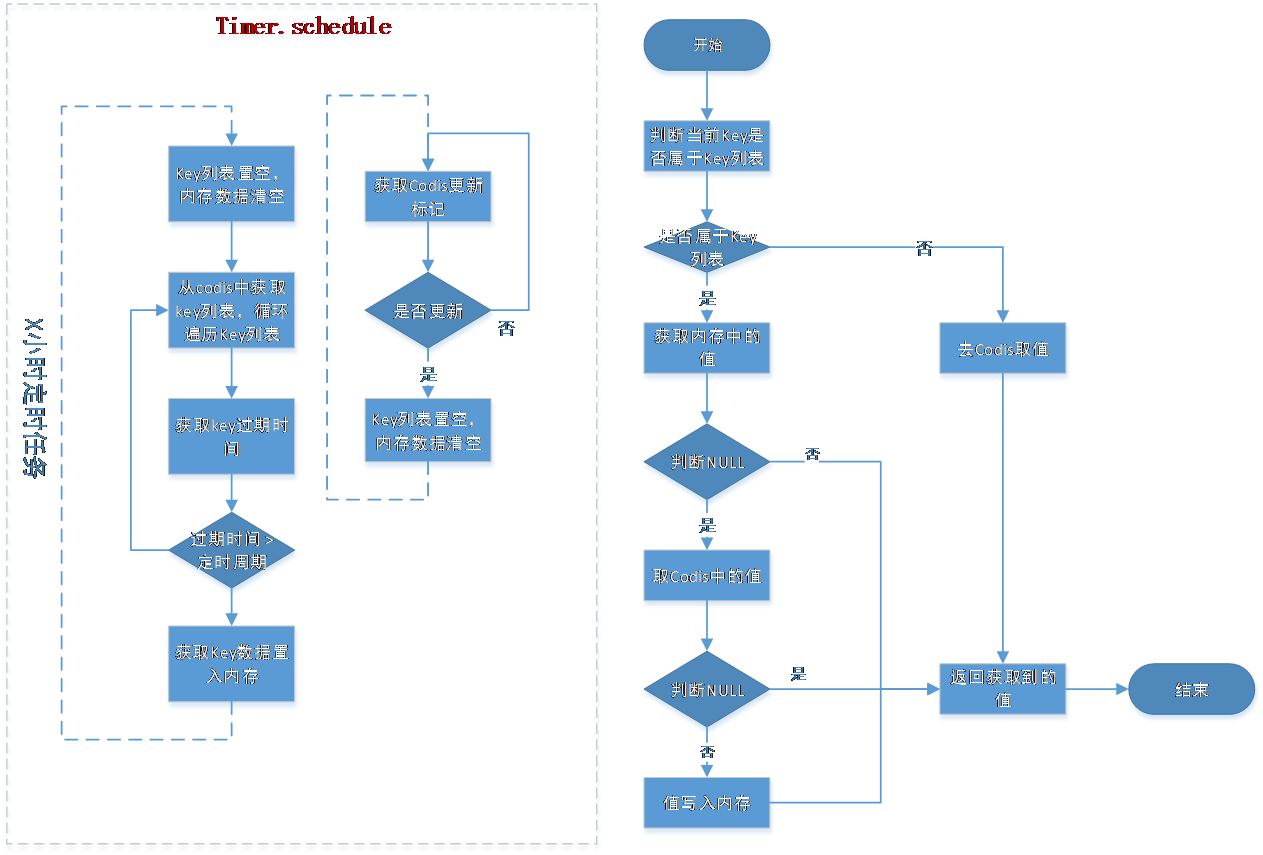
内存缓存数据的 key 列表由缓存服务生成和维护,Key 列表包括后台手动配置(如,10 个)和系统根据使用热度生成(如,20 个)共同组成,其中 cache-manager 的 jar 包只负责对该数据使用,通过定时任务获取 codis 中的前 20 位和后台手动配置的相关数据,期间要保证获取到数据的有效性。
维护本地内存中的数据
自然统计内存缓存: 用 sortedSet 集合,统计各主键下的所有键 Get 的次数,汇总成 score_{主键}方式的集合。利用 ZIncrby 命令统计对应的子键的次数,最终汇总每个主键,统计出 Top100 的 key,利用 zunionstore 命令将信息统计汇总作为内存缓存的基础,此集合内数据均从内存中获取。
管理类内存缓存: 分析和统计项目主流程的关键的基础缓存数据保存到内存中, 保障对应区域的数据获取与缓存时间,在离开数据源后能够最大程度的展现畅途网的功能。
在发生手动更新时,对内存中对应的主键进行更新
在发生更新时,由后台发起,在缓存服务向 codis 中置入标志位,各客户端在定时任务中获取标志位,如果标志位(cache_memory_update_flag)为 Y,则清空内存和 Key 规则表,等到下一个更新周期来临重新获取数据。
多年后,再回想年少时的迷茫和执著,或许原因都记不得了。青春就是让你张扬的笑,也给你莫名的痛。——林语堂《人生不过如此》
经过大半年的时间测试、缓存服务接口改造,在 2016 年 9 月份,赶在国庆前,我们的 Codis3.0 上线了,在车次查询等方面,有了质的飞越,尤其节假日或高峰期期间,平滑的扩缩容、数据迁移、高可用等方面展示出巨大优势。
三个 codis_proxy 节点的均衡情况:
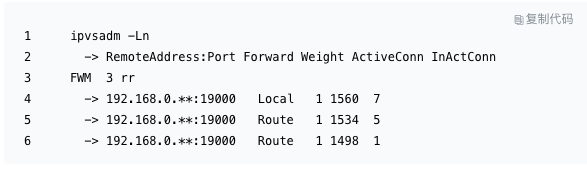
1 年后,2018 年 8~9 月份,我们将 Codis 升级到 3.2 的,由之前 6 台服务器,扩展到 7 台,实际上多一台 Codis-web 节点,独立承担 Codis-fe、Codis-dashboard 等组件。对于 Redis-Sentinel、Codis-fe 等组件的引进,解决了运维人员很多问题,在此不再描述,有兴趣的可以参考。
https://github.com/CodisLabs/codis/blob/3.2.2/doc/tutorial_zh.md
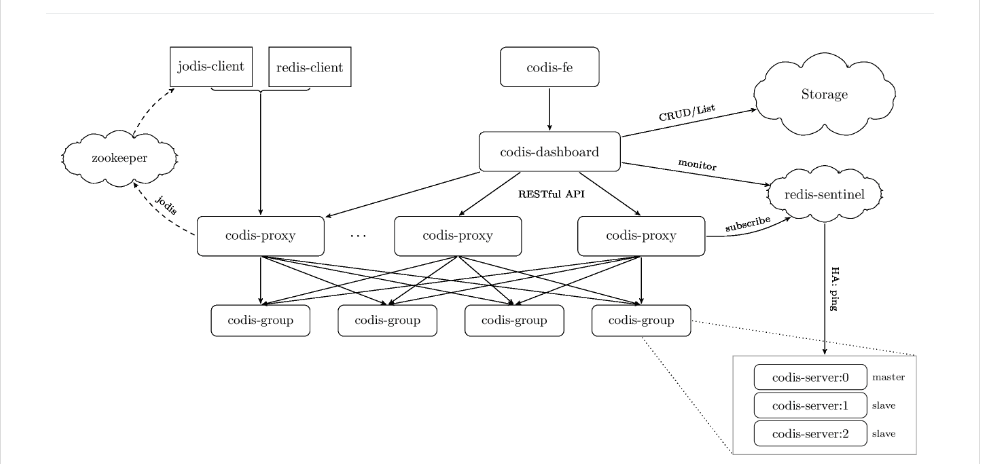
目前 Codis 作为畅途网最为核心的缓存层,一如既往的稳定输出,肩负起它的神圣使命!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号