26分钟见证历史:OpenAI发布免费GPT-4,视频语音交互宛如未来科技!
发表时间: 2024-05-14 04:55
今天凌晨,一场 26 分钟的发布会,将又一次大大改变 AI 行业和我们未来的生活,也会让无数 AI 初创公司焦头烂额。
这真不是标题党,因为这是 OpenAI 的发布会。
刚刚,OpenAI 正式发布了 GPT-4o,其中的「o」代表「omni」(即全面、全能的意思),这个模型同时具备文本、图片、视频和语音方面的能力,这甚至就是 GPT-5 的一个未完成版。
更重要的是,这个 GPT-4 级别的模型,将向所有用户免费提供,并将在未来几周内向 ChatGPT Plus 推出。
我们先给大家一次性总结这场发布会的亮点,更多功能解析请接着往下看。

发布会要点
这些功能早在预热阶段就被 Altman 形容为「感觉像魔法」。既然全世界 AI 模型都在「赶超 GPT-4」,那 OpenAI 也要从武器库掏出点真家伙。
其实在发布会前一天,我们发现 OpenAI 已经悄悄将 GPT-4 的描述从「最先进的模型」,修改为「先进的」。
这就是为了迎接 GPT-4o 的到来。GPT-4o 的强大在于,可以接受任何文本、音频和图像的组合作为输入,并直接生成上述这几种媒介输出。
这意味着人机交互将更接近人与人的自然交流。
GPT-4o 可以在 232 毫秒内回应音频输入,平均为 320 毫秒,这接近于人类对话的反应时间。此前使用语音模式与 ChatGPT 进行交流,平均延迟为 2.8 秒(GPT-3.5)和 5.4 秒(GPT-4)。
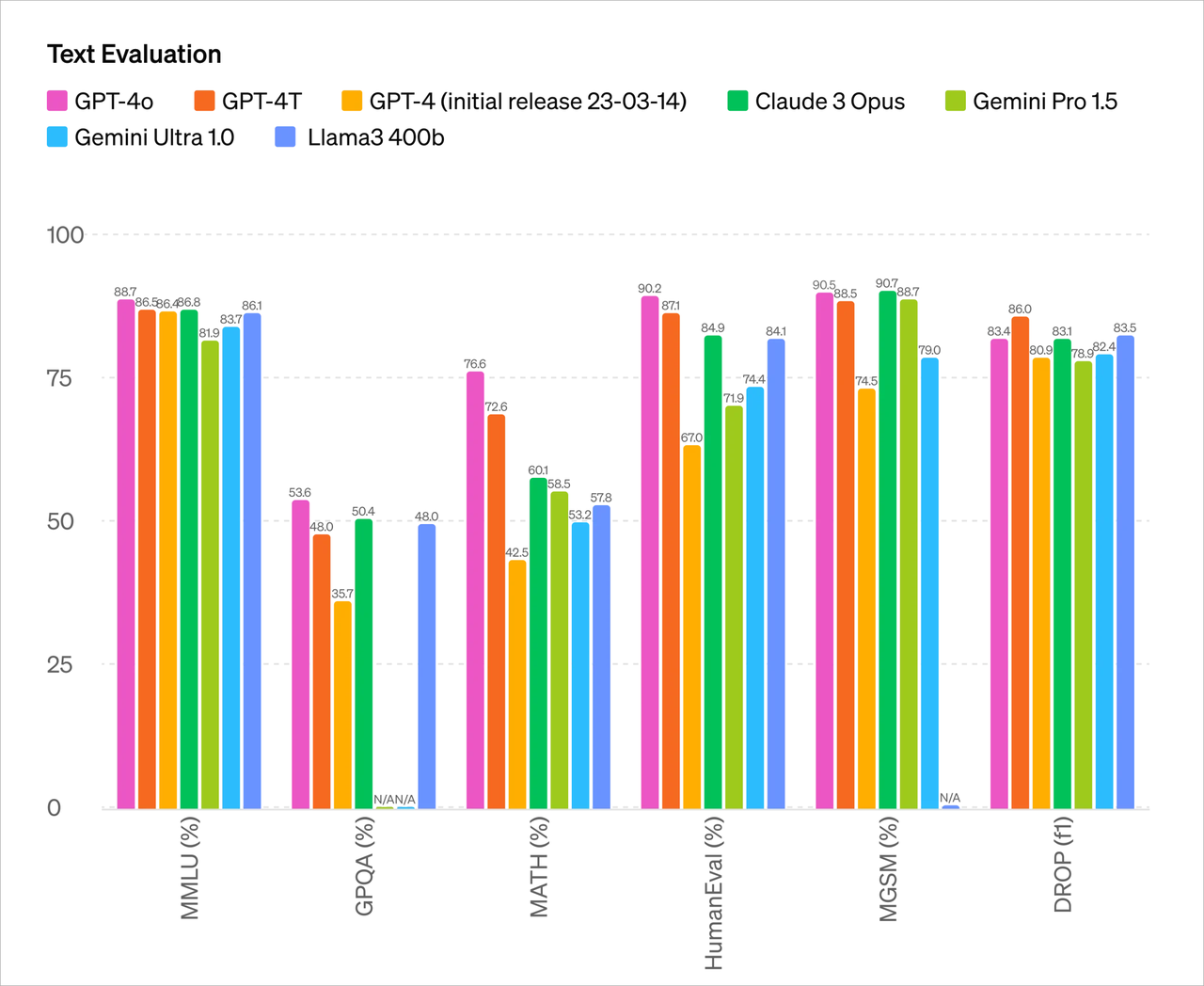
它在英文和代码文本上与 GPT-4 Turbo 的性能相匹敌,在非英语语言文本上有显著改进,同时在 API 上更快速且价格便宜 50%。

而与现有模型相比,GPT-4o 在视觉和音频理解方面表现尤为出色。
从测试参数来看,GPT-4o 主要能力上基本和目前最强 OpenAI 的 GPT-4 Turbo 处于一个水平。
过去我们和 Siri 或其他语音助手的使用体验都不够理想,本质上是因为语音助手对话要经历三个阶段:
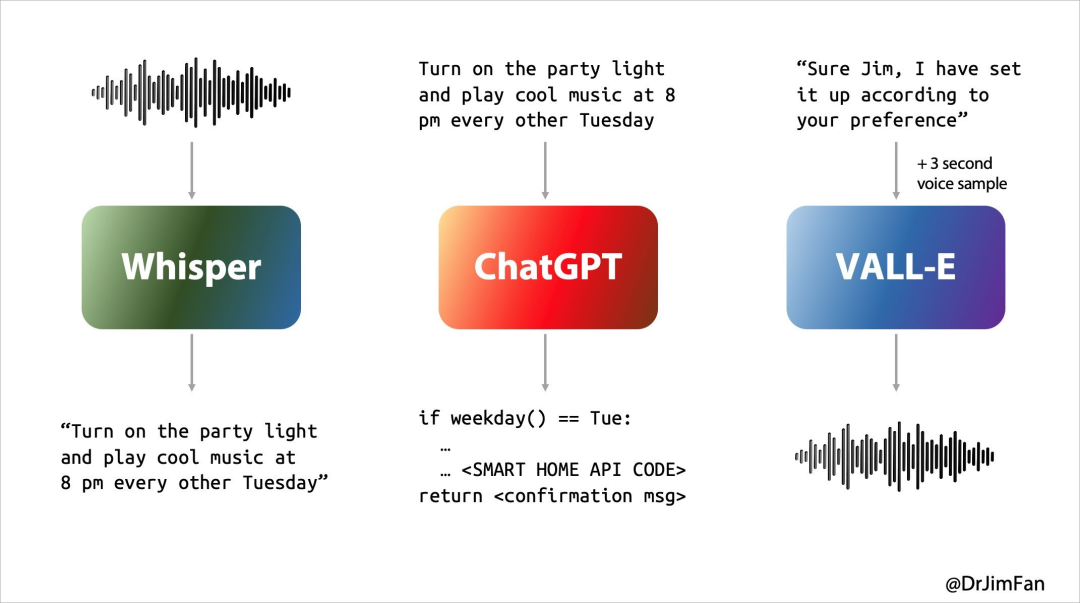
然而我们日常的自然对话基本上却是这样的
此前的 AI 语言助手无法很好处理这些问题,在对话的三个阶段每一步都有较大延迟,因此体验不佳。同时会在过程中丢失很多信息,比如无法直接观察语调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。

当音频能直接生成音频、图像、文字、视频,整个体验将是跨越式的。
GPT-4o 就是 OpenAI 为此而训练的一个全新的模型,而要时间跨越文本、视频和音频的直接转换,这要求所有的输入和输出都由同一个神经网络处理。
而更令人惊喜的是,ChatGPT 免费用户就能使用 GPT-4o 可以体验以下功能:
而当你看完 GPT-4o 下面这些演示,你的感受或许将更加复杂。
ChatGPT 不光能说,能听,还能看,这已经不是什么新鲜事了,但「船新版本」的 ChatGPT 还是惊艳到我了。
睡觉搭子
以一个具体的生活场景为例,让 ChatGPT 讲一个关于机器人和爱的睡前故事,它几乎不用太多思考,张口就能说出一个带有情感和戏剧性的睡前故事。
甚至它还能以唱歌的形式来讲述故事,简直可以充当用户的睡眠搭子。
做题高手

又或者,在发布会现场,让其演示如何给线性方程 3X+1=4 的求解提供帮助,它能够一步步贴心地引导并给出正确答案。
当然,上述还是一些「小儿戏」,现场的编码难题才是真正的考验。不过,三下五除二的功夫,它都能轻松解决。
借助 ChatGPT 的「视觉」,它能够查看电脑屏幕上的一切,譬如与代码库交互并查看代码生成的图表,咦,不对劲?那我们以后的隐私岂不是也要被看得一清二楚了?
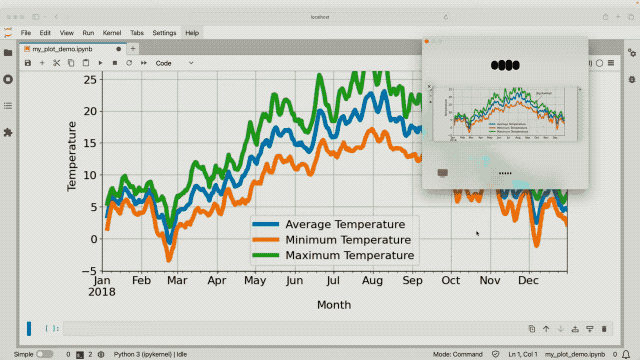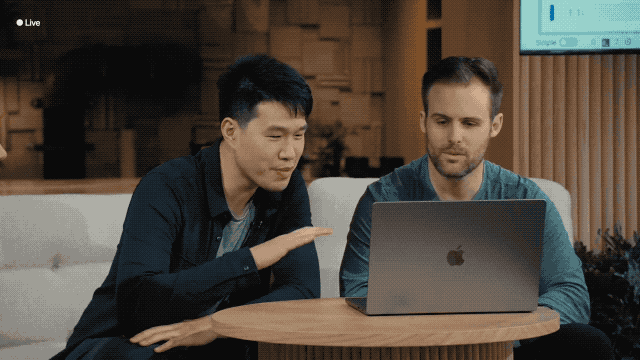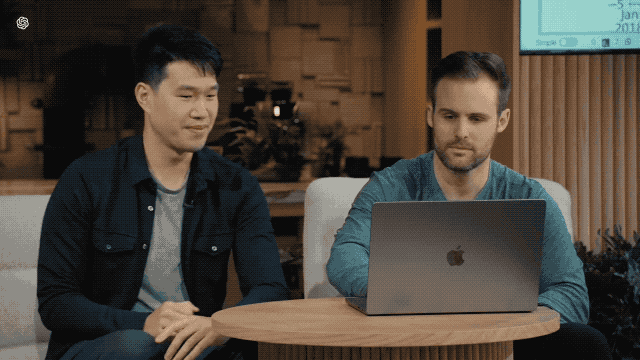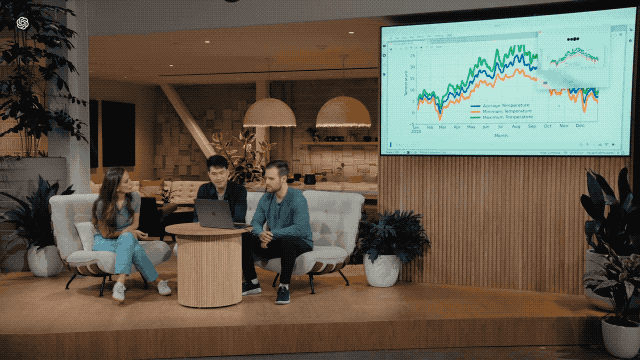
实时翻译
现场的观众也给 ChatGPT 提出了一些刁钻的问题。
从英语翻译到意大利语,从意大利语翻译到英语,无论怎么折腾该 AI 语音助手,它都游刃有余,看来没必要花大价钱去买翻译机了,在未来,指不定 ChatGPT 可能比你的实时翻译机还靠谱。
暂时无法在飞书文档外展示此内容
实时翻译(官网案例)
感知语言的情绪还只是第一步,ChatGPT 还能解读人类的的面部情绪。

在发布会现场,面对摄像头拍摄的人脸,ChatGPT 直接将其「误认为」桌子,正当大家伙以为要翻车时,原来是因为最先打开的前置摄像头瞄准了桌子。
不过,最后它还是准确描述出自拍面部的情绪,并且准确识别出脸上的「灿烂」的笑脸。
有趣的是,在发布会的尾声,发言人也不忘 Cue 了英伟达和其创始人老黄的「鼎力支持」,属实是懂人情世故的。
对话语言界面的想法具有令人难以置信的预见性。
Altman 在此前的采访中表示希望最终开发出一种类似于 AI 电影《Her》中的 AI 助理,而今天 OpenAI 发布的语音助手切实是有走进现实那味了。

OpenAI 的首席运营官 Brad Lightcap 前不久曾预测,未来我们会像人类交谈一样与 AI 聊天机器人对话,将其视为团队中的一员。
现在看来,这不仅为今天的发布会埋下了伏笔,同时也是我们未来十年生活的生动注脚。
苹果在 AI 语音助手「兜兜转转」了十三年的时间都没能走出迷宫,而 OpenAI 一夜之间就找到出口。可预见的是,在不久的将来,钢铁侠的「贾维斯」将不再是幻想。
虽然 Sam Altman 没在发布会上出现,但他在发布会后就发布了一篇博客,并且在 X 上发了一个词: her。
这显然在暗指那部同名的经典科幻电影《她》,这样是我观看这场发布会的演示时,脑子里最先联想的画面。
电影《她》里的萨曼莎,不只是产品,甚至比人类更懂人类,也更像人类自己 ,你真的能在和她的交流中逐渐忘记,她原来是一个 AI 。

这意味着人机交互模式可能迎来图像界面后真正的革命性更新,如同 Sam Altman 在博客中表示:
新的语音(和视频)模式是我使用过的最好的计算机界面。它感觉像电影中的人工智能;而且我仍然有点惊讶它是真实的。达到人类级别的响应时间和表现力原来是一个很大的改变。
之前的 ChatGPT 让我们看到自然用户界面初露端倪:简单性高于一切:复杂性是自然用户界面的敌人。每个交互都应该是不言自明的,不需要说明手册。
但今天发布的 GPT-4o 则完全不同,它的几乎无延迟的相应、聪明、有趣、且实用,我们和计算机的交互从未真正体验过这样的自然顺畅。
这里面还藏着巨大可能性,当支持更多的个性化功能和与不同终端设备的协同后,意味着我们能够利用手机、电脑、智能眼镜等计算终端做到很多以往无法实现的事情。
AI 硬件不会再试积累,当下更令人期待的,就是如果下个月苹果 WWDC 真的官宣与 OpenAI 达成合作,那么 iPhone 的体验提升或许将比近几年任何一次发布会都大。
英伟达高级可科学家 Jim Fan 认为,号称史上最大更新 iOS 18 ,和 OpenAI 的合作可能会有三个层面:
说到这里,也不得不心疼明天要举办发布会的 Google 一秒。
作者:李超凡 莫崇宇
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿|原文链接· ·新浪微博
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号