Redis入门指南:常见用法与应用场景解析
发表时间: 2021-04-16 11:29
Redis是一个键值对存储的存储系统;一般用做缓存比较多,也可以将其作为数据库及消息中间件使用。
传统应用中,数据存储在关系型数据库中,前端请求到来时通过SQL语句查询关系型数据库中的数据并返回给前端;然而关系型数据库中的数据都是存储在文件系统中,读取数据涉及到多次对文件系统的调用,效率受到限制。一般情况下我们可以使用基于内存的缓存来对查询活动进行提速;而基于内存的的缓存又分成两种:
比如,我们自己在应用里实现一个本地缓存,使用一个Map存储数据,当来请求时先从Map里面根据某个关键字查找,有就直接返回前台,没有再查数据库,然后将查询到的结果存储到Map后再返回给前台。
但这种缓存有一个限制,就是这个缓存只是单点的,如果想要让缓存失效需要通过一些其它补偿机制进行处理;当然单点不存在任何问题;多点部署的情况下,比如我们通过其中一个节点修改了数据库中的数据,这个节点也刷新了他的本地缓存,但另外一个节点并不知道这个数据被修改了,他的缓存不会被刷新,从而造成数据不一致。这在分布式系统中是绝对不允许的。
这个时候我们就将这个缓存的功能抽取出来,单独做成一个系统,所有应用操作缓存的时候都调用这个单独系统的接口。因为缓存都在单系统里面,缓存的失效、刷新等就不会存在不一致的问题了。这种方式就是分布式缓存,你可以自己实现,也可以使用Redis或者其它的内存数据库。当然要自己实现考虑的东西太多了,一般应该很少有人会去这么做。
Redis具有以下特性:
Redis的应用场景包括:
前面说过,Redis以键值对存储,Key一般为String(实际上任何二进制序列都可以做Key,一般都会转成字节流)。
而Value则支持多种,通过不同Value类型,Redis为各种应用场景提供了支持:
对于单值对象的操作包含有以下几种命令:
127.0.0.1:6379> set a bOK127.0.0.1:6379> get a"b"127.0.0.1:6379> del a(integer) 1127.0.0.1:6379> get a(nil)127.0.0.1:6379> set a aOK127.0.0.1:6379> set a a nx(nil)可以使用setnx来做分布式锁;
127.0.0.1:6379> set b b xx(nil)127.0.0.1:6379> set b bOK127.0.0.1:6379> set b c xxOK127.0.0.1:6379> get b"c"127.0.0.1:6379> get a"a"127.0.0.1:6379> incr a(error) ERR value is not an integer or out of range127.0.0.1:6379> set a 1OK127.0.0.1:6379> incr a(integer) 2当key对应的值不存在时,执行incr后其值会变成1,如下所示:
127.0.0.1:6379> del a(integer) 1127.0.0.1:6379> incr a(integer) 1一般使用incr来做计数;
127.0.0.1:6379> set a 1OK127.0.0.1:6379> incrby a 3(integer) 4过期时间设置在做缓存的时候非常有用,一定用做缓存时除非特殊情况最好是设定数据的过期时间,以避免Redis中存储过多数据导致性能下降。
127.0.0.1:6379> set a 1OK127.0.0.1:6379> get a"1"127.0.0.1:6379> expire a 2(integer) 1127.0.0.1:6379> get a(nil)127.0.0.1:6379> set a 2 EX 3OK127.0.0.1:6379> get a"2"127.0.0.1:6379> get a(nil)127.0.0.1:6379> getset a 2(nil)127.0.0.1:6379> getset a 3"2"127.0.0.1:6379> mset a 1 b 2OK127.0.0.1:6379> mget a b1) "1"2) "2"Redis中的列表基于Linked List实现,因此添加新元素的效率很高,但相应的,使用下标访问元素的性能相对较低。如果顺序访问的场景过多,使用列表不是很合适,可以使用下方将会提到的有序集合。列表是按插入顺序排序的,作用上类似于常规的队列。
列表常用操作包含以下几个:
列表可用于实现聊天系统,也可以作为不同进程间传递消息的队列; 或者存储需要按顺序访问的其它数据,如一篇文章的评论列表等;
Set是无序且不重复的集合;主要包含以下几种操作:
无序集合最典型的应用场景就是实现对象标签;如给id为1000的文章打上1、4、5、6这四个标签,可以这样:
sadd article:1000:tags 1 4 5 6 有时候可能会要相反的结果,如打上1标签的文章列表:
sadd tag:1:article 1000sadd tag:1:article 1001 然后我们要根据多个标签查询文章列表就会很简单,将这几个标签中存储的集合做交集:
sinter tag:1:article tag:2:article ...还有一种应用场景就是粉丝,每个账号的粉丝存储一个列表,每个人粉的用户存一个列表,这样就可以利用这两类列表快速完成很多种查询,如找两个人共同粉的明星、找两个明星共同的粉丝等;
有序集合是在集合的基础上保持元素有序性。每个元素在添加时可以指定一个分值(Score),Redis依据这个分值来保持集合中的元素的顺序。
常用操作:
127.0.0.1:6379> zadd test 2 a(integer) 1意思是将元素a添加到集合test中,并且指定其分值为2; 也可以通过incr的方式增加其分值,如:
127.0.0.1:6379> zadd test incr 2 a"4"127.0.0.1:6379> zadd test 2 a(integer) 1127.0.0.1:6379> zadd test 3 b(integer) 1127.0.0.1:6379> zadd test 1 c(integer) 1127.0.0.1:6379> zadd test 4 d(integer) 1127.0.0.1:6379> zrange test 0 -11) "c"2) "a"3) "b"4) "d"可以看出再来的列表是排好序的;(c=1/a=2/b=3/d=4)其中-1表示的是到最后一个元素;
如果我们要获取Top2的元素,那么可以:
127.0.0.1:6379> zrange test 0 11) "c"2) "a"127.0.0.1:6379> zrevrange test 0 11) "d"2) "b"127.0.0.1:6379> zrevrange test 0 1 withscores1) "d"2) "4"3) "b"4) "3"127.0.0.1:6379> zrangebyscore test -inf 21) "c"2) "a"127.0.0.1:6379> zrangebyscore test -inf 31) "c"2) "a"3) "b"127.0.0.1:6379> zrangebyscore test 1 21) "c"2) "a"127.0.0.1:6379> zrank test a(integer) 1127.0.0.1:6379> zrank test b(integer) 2127.0.0.1:6379> zrank test c(integer) 0有序集合最大的特点就是为集合中的每个元素指定一个分值,因此在需要获取Top N的场景下非常有用。
哈希使用键值对的方式来存储元素,如:
127.0.0.1:6379> del test(integer) 1127.0.0.1:6379> hset test a b(integer) 1127.0.0.1:6379> hget test a"b"主要有以下几个方法:
127.0.0.1:6379> hset test c 1(integer) 1127.0.0.1:6379> hincrby test c 20(integer) 21哈希可以用于存储对象属性,能够非常快速地通过属性的名称查询到其值。
位图其实就是一长串的0/1串;
它主要包含以下几种操作:
127.0.0.1:6379> setbit test 0 1(integer) 0127.0.0.1:6379> setbit test 3 1(integer) 0127.0.0.1:6379> getbit test 3(integer) 1127.0.0.1:6379> bitcount test(integer) 2127.0.0.1:6379> bitpos test 0(integer) 1127.0.0.1:6379> bitpos test 1(integer) 0127.0.0.1:6379> bitop and result test test1(integer) 1意思是对test/test1两个集合求交集,将其存储到result中。
位图的常见使用场景,如我们给将每个用户每天的登录情况存储成一个位图,如果某一天有登录,那么将这一天对应位置设置成1;无登录则不需要设置(默认为0);
存储后我们可以方便地对多个用户的集合进行各种与、或等操作,多个用户共同登录的天数:
127.0.0.1:6379> setbit a 0 1(integer) 0127.0.0.1:6379> setbit a 3 1(integer) 1127.0.0.1:6379> setbit b 2 1(integer) 1127.0.0.1:6379> setbit b 3 1(integer) 1127.0.0.1:6379> setbit c 0 1(integer) 0127.0.0.1:6379> setbit c 3 1(integer) 0127.0.0.1:6379> setbit c 1 1(integer) 0127.0.0.1:6379> bitop and result a b c(integer) 1使用位图最大的好处是使用尽量少的存储空间获得尽量高的计算效率。
主要用做计算不同元素的数量,有点像set,但他并不实际的存储元素,只是根据添加的元素,使用一定的算法估算出不同元素数量,因此不需要消耗很大的存储空间。一定要注意他只是估算,不能保证100%精确,因此并不适用于对精确度要求很高的场景;
它主要包括以下操作:
如:
127.0.0.1:6379> del test(integer) 1127.0.0.1:6379> pfadd test a b c d a b(integer) 1127.0.0.1:6379> pfcount test(integer) 4127.0.0.1:6379> pfadd test e(integer) 1127.0.0.1:6379> pfcount test(integer) 5具体算法比较复杂,感兴趣的可以自己去找一下。
Redis可以通过主从配置、集群部署、哨兵等方式来实现高可用。
我们可以通过redis-trib工具将多个单独运行的Redis Server组合成集群,同时可以指定每个主节点对应的从节点数量;最终创建好的集群中包含有多个主节点,每个主节点有其对应的从节点。
当我们要存储数据时,Redis会根据基于哈希槽的数据分片算法(一致性哈希),将数据分配到某个主节点上进行存储,主节点的数据会同步到其对应的从节点上,以此来保证数据安全性(但由于同步延迟,并不能保证强一致性,如果某个主节点挂掉可能会有数据丢失的风险)。
那么在主节点挂掉时如何保证从节点能够顺利切换成主节点呢?
Redis通过哨兵(Sentinel)来实现;由一个或多个Sentinel实际缓存的Sentinel系统可以监视任意多个主服务器,以下这些主服务器下的所有从服务器,并在被监视的主服务器进入下线状态时,自动选择从服务器将其升级成主服务器;
Sentinel执行以下三个任务:
Redis sentinel只是一个运行在特殊模式下的Redis服务器,可以在启动一个普通Redis服务器时通过指定-sentinel选项来启动Redis Sentinel
启动完Sentinel后,如Spring Boot等客户端就可以连接到Sentinel服务器,从其中获取实际Redis服务器地址并进行操作;同时它会启动监听来监听哨兵的主从服务器变更消息,从而在主从发生切换时能够及时响应其变化。
Sentinel也可以做集群部署,一般最少部署三个来做到高可用,因为涉及到Sentinel对于主节点下线的一个投票处理,两个的时候无法正常运行。
以三个哨兵、两个主从集群配置的高可用下Redis的部署图如下所示:
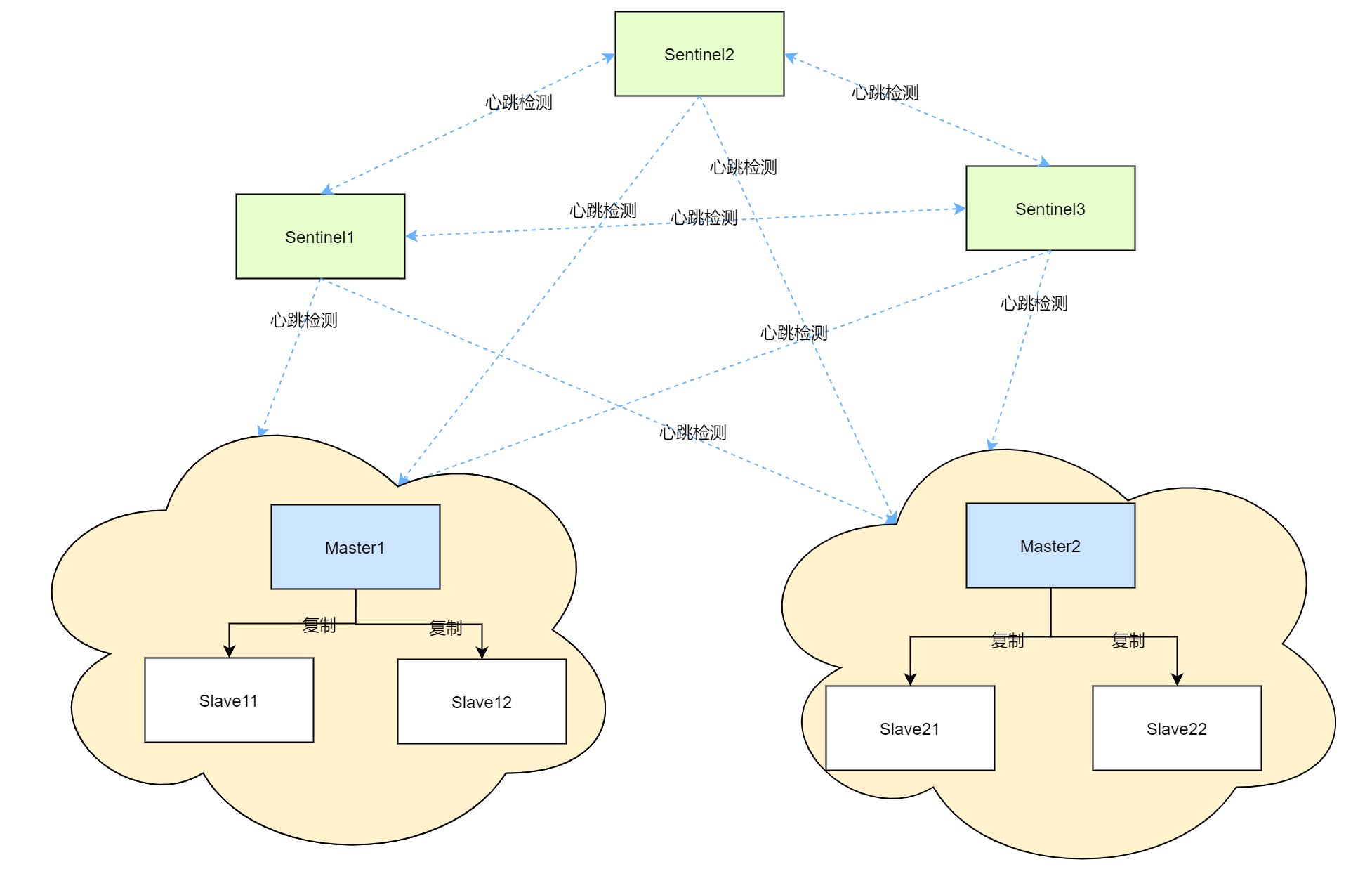
Redis集群部署图
其中哨兵与哨兵之间、哨兵与任意的主节点、任意的从节点都会进行心跳检测,以便在某个节点出现异常时能够尽快对其响应。
常规方式下,每一次Redis的操作都需要等待操作返回再执行下一次操作,如果我们有一批操作需要同时执行,这种效率是很低的。
而使用管道后,在管道中执行命令中不需要等待命令返回就可以继续执行下一条命令,效率会得到较大的提升。
Spring Boot中可以通过RedisTemplate的executePipelined的方式来执行管道命令。如:
public void executePipelined(Map<String, String> map, long seconds) { RedisSerializer<String> serializer = redisTemplate.getStringSerializer(); redisTemplate.executePipelined(new RedisCallback<String>() { @Override public String doInRedis(RedisConnection connection) throws DataAccessException { map.forEach((key, value) -> { connection.set(serializer.serialize(key), serializer.serialize(value),Expiration.seconds(seconds), RedisStringCommands.SetOption.UPSERT); }); return null; } },serializer); }与管道相类似的有一个执行脚本的功能。上面说到在管道中执行下一条命令时不需要等待上一条命令执行完毕,因此,如果我们批量执行的命令需要保持顺序,就不能使用管道了。这个时候就可以使用脚本来执行。 脚本类似数据库中的存储过程,可以将一系列操作封装成一个原子操作,客户端在调用的时候传入脚本内容及参数给Redis,Redis服务器将会顺序执行脚本中的内容,同时保证整个脚本执行的原子性。由于脚本的执行是在服务器上,后面的脚本即使依赖于前面脚本的执行结果,也与客户端之间不存在数据的交互,因此其效率比不使用脚本的方式要高。
类似常规的MQ,Redis也支持发布订阅的模式。通过subscribe/publish等命令来进行订阅与发布。
Redis通过multi/exec/discard等命令支持事务,从而使得客户端的一系列操作能够作为一个原子性操作被执行;
如:
SessionCallback<Object> callback = new SessionCallback<>() { @Override public Object execute(RedisOperations operations) throws DataAccessException { operations.multi(); operations.opsForValue().set("name", "1"); operations.opsForValue().set("gender", "男"); operations.opsForValue().set("age", "30"); return operations.exec(); } }; stringRedisTemplate.execute(callback)需要注意的是,Redis事务并不支持回滚,即使事务中的某条命令执行失败了,Redis仍旧会执行余下的任务。但在执行exec之前,我们可以通过discard来手动放弃事务。
我们也可以通过watch命令在事务处理过程中做监控,它能够在发现某个被监听的对象被其它连接修改后,将当前的事务置成失败。我们可以在应用程序中,检测到这类失败时就再重新尝试,或者直接中止执行。
从定义上来说,Redis中的脚本本身就是一种事务,所有可以在事务中处理的事情,都可以通过脚本来完成。而且脚本一般来说执行速度要更快一些;那为什么会有两种?主要是因为脚本是后引入的,而事务是比较早就已经支持的特性。
因此应用程序中完全可以使用脚本来替代需要使用事务的地方。
当Redis被当做缓存使用时,我们新增数据,它能够自动地回收旧数据,这对于应用程序来说会非常有用,否则可能会造成缓存数据量越来越多,Redis性能下降越来越厉害。
Redis通过近似的LRU算法来实现内存回收。
可以通过maxmemory-policy来配置内存达到限制时的策略:
如果没有键满足回收的前提条件,volatile-lru/volatile-random/volatile-ttl与noevication结果是一样的;
主要是通过setnx命令,即设置某个对象值,如果失败则说明其它连接给他赋值了,表示锁被占用,这个时候可以循环执行等待,也可以使用发布、订阅方式的等通知;
需要注意的是锁超时、锁释放、锁续约等处理;
一个简单的实现如下:
/** * 通过分布式锁执行任务 * 最多支持60秒内的任务,如果超过60秒未执行完成,锁会超期 * * @param lockKey 分布式锁存储在Redis中的Key值 * @param task 需要执行的任务 */ public void callWithLock(String lockKey, Runnable task) { String finalKey = KEY_PREFIX + "lock:" + lockKey; String value = UUID.randomUUID().toString(); int tryLockCount = 0; Boolean result = null; while (tryLockCount < 10) { result = redisTemplate.execute((RedisCallback<Boolean>) connection -> connection.set(finalKey.getBytes(), value.getBytes(), Expiration.from(60, TimeUnit.SECONDS), RedisStringCommands.SetOption.SET_IF_ABSENT)); if (null != result && result) { break; } tryLockCount++; try { Thread.sleep(100); } catch (InterruptedException ignored) { } } if (null != result && result) { try { task.run(); } finally { // 释放锁,需要判断value值与当前线程的Value值是否一致,不一致则表明已经切换了线程,不能释放 String cacheValue = redisTemplate.opsForValue().get(finalKey); if (!StringUtils.isBlank(cacheValue) && cacheValue.equals(value)) { redisTemplate.delete(finalKey); } } } else { throw BusinessException.create("加锁超时"); } }基于Redis实现的分布式锁比较出名的是RedLock,感兴趣的可以了解下。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号