数据库一致性:每位开发者必知的知识
发表时间: 2020-08-21 10:58

作者 | Roberto Vitillo
译者 | 弯月,责编 | 屠敏
头图 | CSDN 下载自视觉中国
出品 | CSDN(ID:CSDNnews)
以下为译文:
想象一下,给变量赋值,然后立即读取,却发现刚刚的写入根本不起作用,是不是很抓狂?
x = 42assert(x == 42) # 抛出异常在使用一致性保证较弱的分布式数据存储时,就有可能遇到这种情况。你可能会问:“等等,难道数据库不是应该为我解决一致性的问题吗?”执行更新操作后,实际的数据会立即被更新还是需要等待一段时间,取决于数据库是否提供这种保证。
有些数据库提供的一致性保证有点违反直觉,但其目的是提供高可用性和高性能。还有一些数据库可以让你选择想要更好的性能还是更强的保证,例如Azure的Cosmos DB和Cassandra。因此,你需要了解其中的利弊。

下面我们来看看,当你将请求发送到数据库后,接下来会发生什么。在理想的情况下,你的请求会被立即执行:
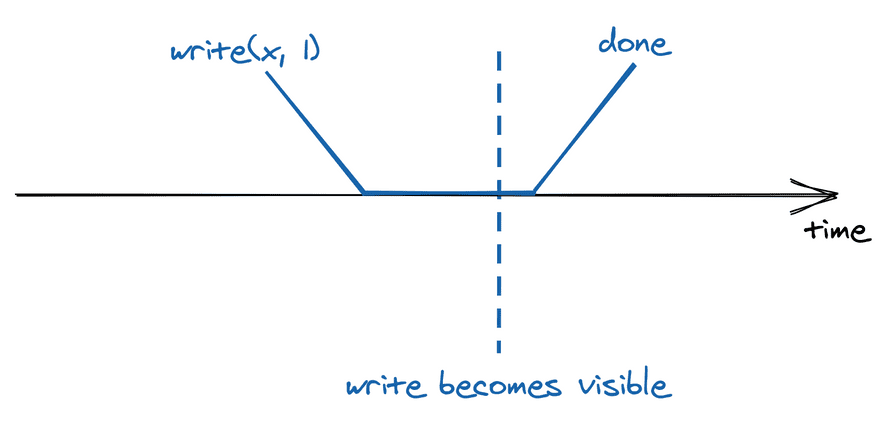
但是,我们并非生活在理想世界中,你的请求需要送到数据存储,然后经过处理,最后再将响应发送给你。所有这些操作都需要一定的时间,无法在瞬间完成:
数据库可以提供的最佳保证是,在调用和完成之间的某个时间点上执行请求。你可能会认为这也没什么大不了,毕竟你在编写单线程应用程序时就习惯了这一点,例如将1赋给x,然后读取x的值,那么必然会得到1,当然前提是没有其他线程写入同一变量。然而,当你使用的数据存储为了实现高可用性和可伸缩性,将数据状态复制到多台计算机上,那么一切都变成了未知数。为了理解为什么会出现这种情况,我们来探讨一下在分布式数据库的简化模型中,系统设计师在实现读取的时候必须权衡的利弊。
假设我们有一个分布式键值存储,它由一组副本组成。副本之间会选出一个领导者,这是唯一可以接受写入的节点。在领导者收到写请求后,它会通过异步将数据写入到其他副本。尽管所有副本都以相同的顺序收到相同的更新,但是它们接收到的时间点不同。
你的任务是想出一种策略来处理读取请求,你该怎么办?你可以从领导者或其他副本中读取数据。如果所有读取都经由领导者,那么吞吐量就会成为瓶颈,无法超过单个节点可以处理的数据量。如果任何副本都可以服务请求读取,那么吞吐量就可以得到极大地提升,但这种情况下两个客户端(观察者)获取的系统状态就有可能不一致,因为领导者和副本之间以及各个副本之间可能出现延迟。
简单来说,我们需要在观察者看到的系统的一致性与系统的性能和高可用性之间进行权衡利弊。为了理解这种关系,我们需要准确地定义一致性。我们可以参考一致性模型(
https://jepsen.io/consistency),该模型定义了系统状态观察者可能体验到的系统状态视图。

如果客户端的写和读操作只能发送给领导者,则似乎每个请求都在特定的时间点以原子的方式进行,就好像只有一个数据副本。无论有多少个副本,也无论每个副本延迟多少,只要客户端直接查询领导者,那么从他们的角度来看,只有一个数据副本。
由于请求不会立即被服务,而且只有一个节点提供服务,所以请求必然在调用和完成期间内执行。另一种思考方式是,在请求完成后,所有观察者都可以看到它的副作用:
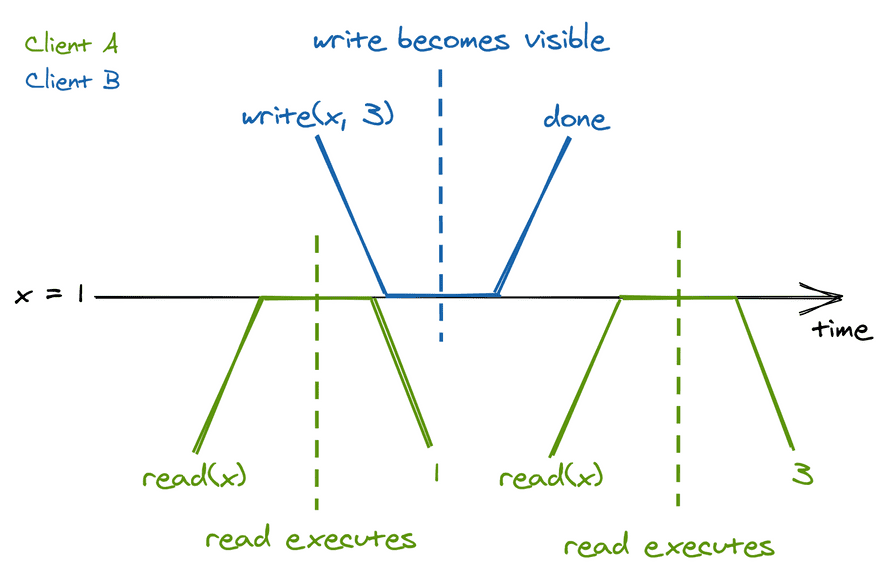
由于在请求调用和完成之间,其他参与者都可以看到这个请求,因此实时性必须得到保证。这种保证有一个理论上的一致性模型,名叫线性一致性,又称强一致性。线性一致性是系统可以为单个对象请求提供的最强一致性。
如果客户端向领导者发送了读取请求,但在请求到达时,这个领导者已被废除,但收到请求的服务器认为它仍然是领导者,该怎么办?如果由前一个领导者处理请求,则无法保证系统的强一致性。为了防止出现这种情况,这个假定的领导者首先需要联系大多数副本,确认自己是否仍然是领导者。只有自己仍是领导者的时候,它才能执行请求并将响应发送回客户端。这个过程会大幅增加读取所需的时间。

到此为止,我们讨论了由领导者按照顺序处理读取的做法。但是这种做法会产生一个瓶颈,从而限制系统的吞吐量。最重要的是,领导者还需要联系大多数副本才能处理读取。为了提高读取性能,我们应该允许副本处理请求。
尽管副本会落后于领导者,但它接收到更新的顺序与领导者相同。如果客户端A仅查询副本1,而客户端B仅查询副本2,则由于副本不完全同步,这两个客户端在不同时间点看到的状态也有所不同:
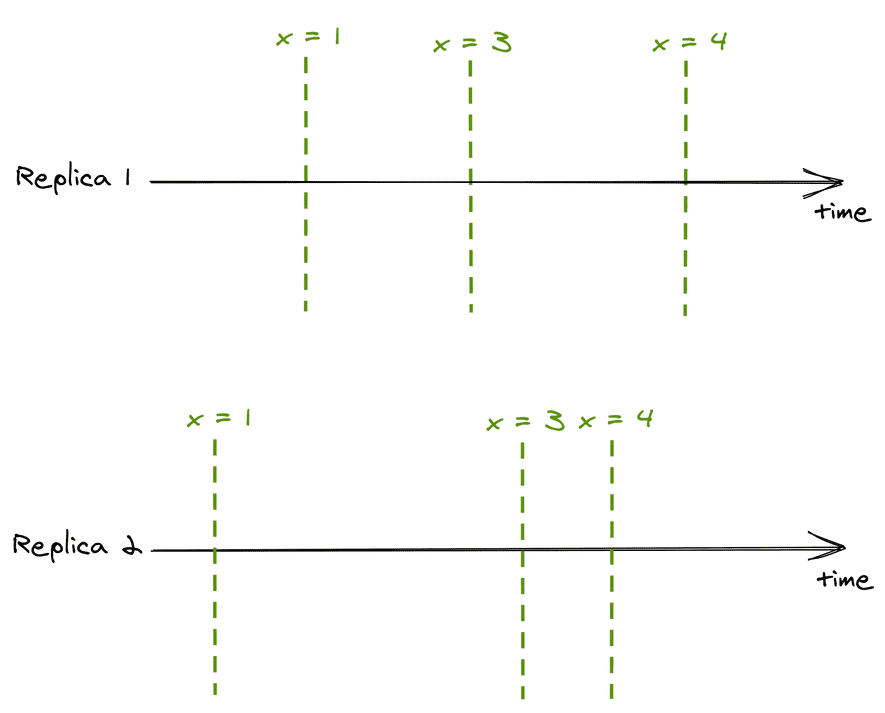
在这个一致性模型中,对于所有观察者来说,操作发生的顺序相同,但操作的副作用何时会被观察者看到,该模型不能提供任何实时性的保证。该模型称为顺序一致性。顺序一致性与线性一致性之间的差异就在于前者缺乏实时性保证。
这种模型的一个简单应用是与队列同步的生产者/消费者系统:生产者节点负责写入队列,而消费者则负责读取。生产者和消费者看到队列各项的顺序相同,但消费者落后于生产者。

尽管我们设法提高了读取吞吐量,但我们不得不将客户端固定到某个副本上,此时如果副本出现故障该怎么办?为了提高存储的可用性,我们可以通过允许客户端查询任意副本。但是,就一致性而言,这一步需要付出高昂的代价。假设有两个副本1和2,其中副本2落后于副本1。如果客户端在查询了副本2之后,紧接着又查询副本1,那么它将看到过去的状态,这可能会令人非常困惑。客户端拥有的唯一保证是,如果系统的写入停止,则所有副本最终都将收敛到最终状态。这种一致性模型称为最终一致性。
在最终一致性的数据存储之上构建应用程序非常困难,因为其行为与你所习惯的编写单线程应用程序的行为不同。任何一个细小的错误都可能逐步蔓延,而且很难调试和重现。然而,并非所有应用程序都需要线性一致性,所以最终一致性也有一定的用武之地。你需要做出明智的选择,仔细考虑你的数据存储提供的保证是否能够满足应用程序的需要。如果你想记录网站的访问量,那么最终一致性将是你的首选,因为读取返回的数字是否有些过时并不重要。但对于支付系统来说,强一致性绝对不可或缺。

除了本文介绍的模型之外,还有很多有关一致性的模型。但其背后的基本思想万变不离其宗:一致性保证越强,单个操作的等待时间就越长,而且发生故障时存储的可用性越低。这种关系又称之为PACELC定理:在分布式计算机系统中进行网络分区(Partitioning,即P)的时候,我们必须在可用性(Availability ,即A)和一致性(Consistency ,即C)之间进行选择,否则(Else,即E)即便系统没有任何分区,我们也必须在延迟(Latency ,即L)和一致性(Consistency,即C)之间进行选择。
原文:
https://robertovitillo.com/what-every-developer-should-know-about-database-consistency/
本文为 CSDN 翻译,转载请注明来源出处。


声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号