开源与闭源:大模型发展的两条道路探讨
发表时间: 2024-09-20 09:44
北京时间9月19日凌晨
阿里巴巴
史上最大规模的开源发布
包含基础模型Qwen2.5
用于编码的Qwen2.5-Coder
和用于数学的Qwen2.5-Math
刷新业界纪录
引发关注

图源:Qwen X平台截图
Qwen2.5有何不同
Qwen2.5虽然只有720亿参数
但在多个基准测试中
击败了Meta
拥有4050亿参数的Llama-3.1
超过了Mistral
最新开源的Large-V2
成为目前最强大参数的开源模型之一
本次开源的三类模型
共有10多个版本
适用于个人、企业
以及移动端、PC等
不同人群、不同业务场景
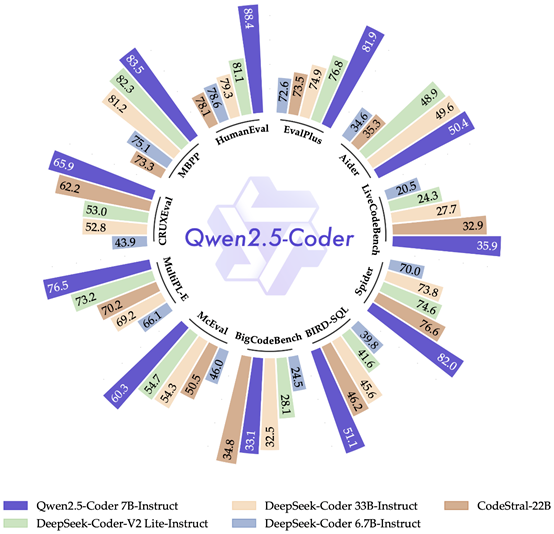
Qwen2.5-Coder-7B指令微调版本在众多测试基准中获得较好成绩。
图源:Qwen
Qwen2.5系列支持
超过29种主流语言
语言模型支持128K tokens
并能生成最多8K tokens的内容
Qwen2.5系列的预训练数据
大幅度增长
达到了18万亿tokens
超过了Llama-3.1的15万亿
成为目前训练数据最多的开源模型
此外
Qwen2.5在
指令跟踪
生成长文本
(从1k增加到超过8K标记)
理解结构化数据
(例如表格)
以及生成结构化输出
(尤其是JSON)
等方面实现了显著改进
同时对系统提示的多样性
更具弹性
增强了聊天机器人的
角色扮演实施和条件设置能力
开源模型VS闭源模型
谁更胜一筹?
在大语言模型领域
选择开源还是闭源
一直都是颇具争议的话题
众多企业做出了不同选择
其中
Meta、阿里云选择了开源
OpenAI、百度选择了极致闭源
而更多大模型公司选择了中间路线
即模型“低配版”开源
更高参数量的模型闭源
比如
谷歌Gemini多模态模型闭源
但单模态Gemma语言模型开源
法国的Mistral AI
最初一直是开源模型的拥趸
但获得微软投资后
其新发布的旗舰级大模型
Mistral Large选择了闭源
百川智能的前两代大模型均开源
但Baichuan 3则完全闭源
智谱AI在今年1月发布GLM-4时
同样选择了闭源模式

图源:观察者网
阿里云的负责人表示
大模型的训练和迭代成本极高
绝大部分的AI开发者
和中小企业都无法负担
Meta、阿里云等推动的大模型开源风潮
让开发者不必从头训练模型
还把模型选择的主动权交给了开发者
大大加速了大模型的应用落地进程
而百度创始人、董事长兼首席执行官李彦宏认为
模型开源与代码开源不同
无法做到众人拾柴火焰高
激烈竞争环境中
商业化闭源模型“最能打”
让大模型为人类服务
有专家指出
未来
开源和闭源的大模型会并存和互补
正如百川智能CEO王小川所说
开源和闭源并不只能二选一
从toB角度来看
开源闭源都需要
他预计
未来80%的企业会用到开源大模型
闭源可以给剩下的20%提供服务
二者不是竞争关系
而是在不同产品中互补的关系

关于大模型开源的安全风险
“AI教父”杰弗里·辛顿呼吁
政府和大公司应投入更多资源
进行安全研究
以确保AI技术发展尽量避免失控
此外
李彦宏也表示
AI永远只是工具
不是人类的竞争对手
我们构建和应用人工智能技术
是为了满足人的需求
增强人的能力
让人类的生活更美好
撰文:曾震宇、孙新武编辑/排版:李汶键统筹:李政葳
参考|新华网、中国青年网、南方都市报、观察者网、搜狐科技
光明网出品
来源: 世界互联网大会
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号