JS逆向技术大解析:为何它比Selenium更受欢迎?
发表时间: 2021-10-15 11:04
正所谓条条道路通罗马,上次我们使用了Selenium自动化工具来爬取网易云的音乐评论,Selenium自动化工具可以驱动浏览器执行特定的动作,获得浏览器当前呈现的页面的源代码,做到可见即可爬,但需要等网页完全加载完,也就是JavaScript完全渲染出来才可以获取到当前的网页源代码,这样的爬取效率太低了、爬取速度太慢了。
追求完美、追求高效率的我们,怎么会容忍效率低下呢?所以我们今天利用Scrapy框架加js逆向来爬取网易云评论并做词云图,做效率最高的人!!!
在爬取前,我们首先要了解一下什么是js逆向。
首先Javascript简称js,js是一种脚本语言,是不需要进行编译的,也是浏览器中的一部分,经常用在web客户端脚本语言,主要是用来给html增加动态功能,也可以进行数据加密。
加密在前端开发和爬虫中是很常见的,当我们掌握了加密算法且可以将加密的密文进行解密破解时,就可以从编程小白摇身变为编程大神,熟练掌握加密算法可以帮助我们实现高效的js逆向。由于加密算法的内容有很多,今天我们主要是简单了解一下加密算法有哪些,之前有写过加密算法,感兴趣可以看看往期文章!!!
js中常见的加密算法有以下几种:
我们发送网络请求的时候,往往需要携带请求参数,如下图所示:
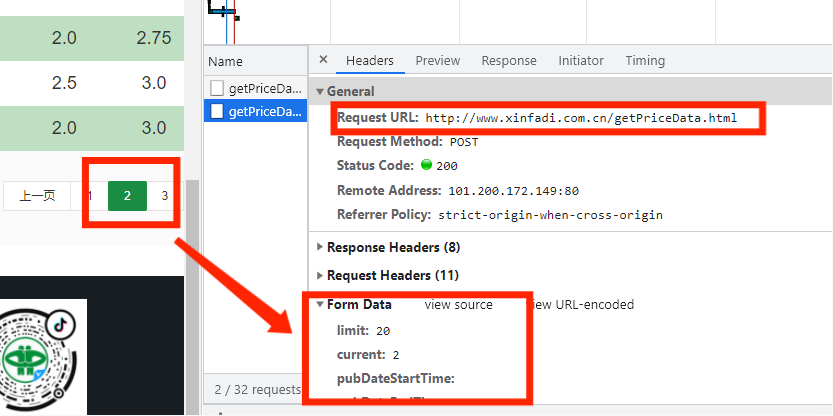
有爬虫基础的人都知道,上图发送的是POST网络请求,在发送请求时,我们还要携带一些参数,例如上图中的limit和current,其中limit是每次获取的数据个数,current是页码数。要想获取上面的URL链接所呈现中的数据时,必须要在发送网络请求时携带limit和current这两个参数。
有时候我们需要携带的请求参数是加密过的参数,如下图所示:
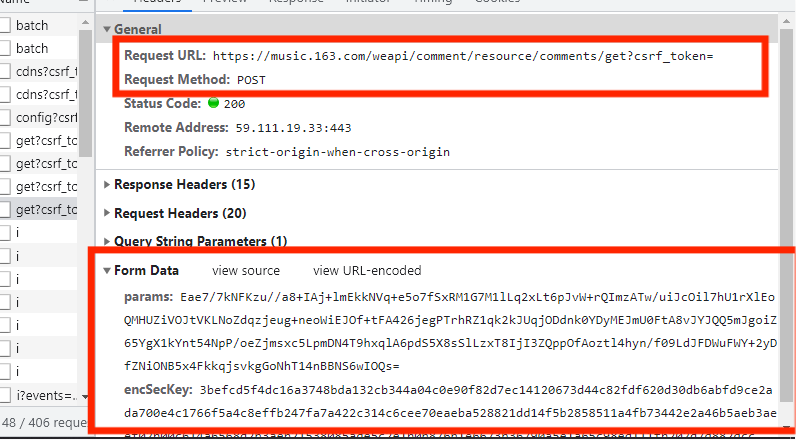
同样是发送POST网络请求,很明显这次的参数是已经加密过的参数,该参数是一大串不知道表达什么意思的字符串,这时就需要采用js逆向来破解该参数。有人可能说,直接复制粘贴那参数,也获取到数据呀。可是这样只能获取到一小部分数据或者一页的数据,不能获取到多页。
通过上面的例子,我们可以知道,js逆向可以帮助我们破解加密过的参数。
当然除了帮我们破解加密过的参数,还可以帮我们处理以下事情:
那么如何实现js逆向或者破解加密过的参数呢。
要破解加密过的参数,大致可以分为四步:
下面我们以待会要爬取的网易云音乐评论为例,所创建的js文件名为wangyi.js,来演示一下如何实现js逆向。
首先打开开发者模式,找到你要获取的数据的URL请求条目,再把加密参数的变量复制下来,点击右上角三个小点,选择Search。
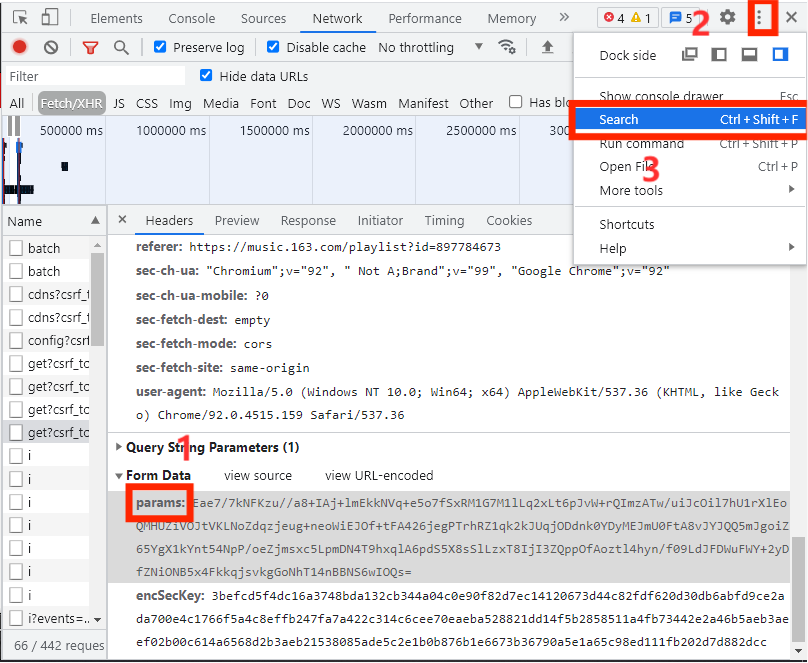
在通过Search搜索把加密参数函数的存放位置找出来,如下图所示:
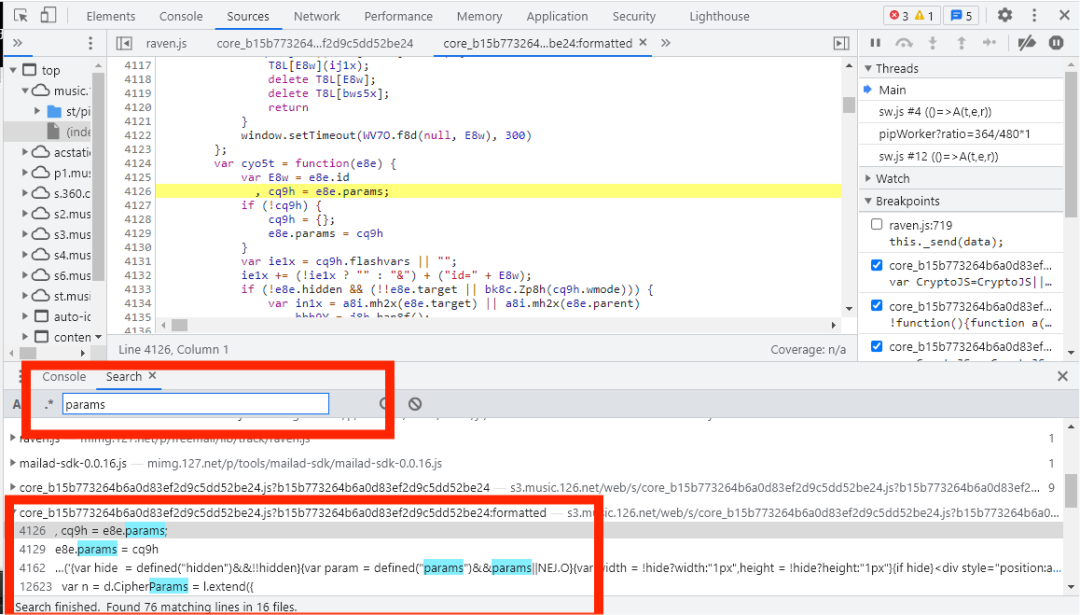
经过选择我们发现加密函数放在core_b15...中,点击4126这一行就会打开core_b15...,我们再在core_b15...中搜索有没有其他params,键盘同时按下Ctrl F,如下图所示:
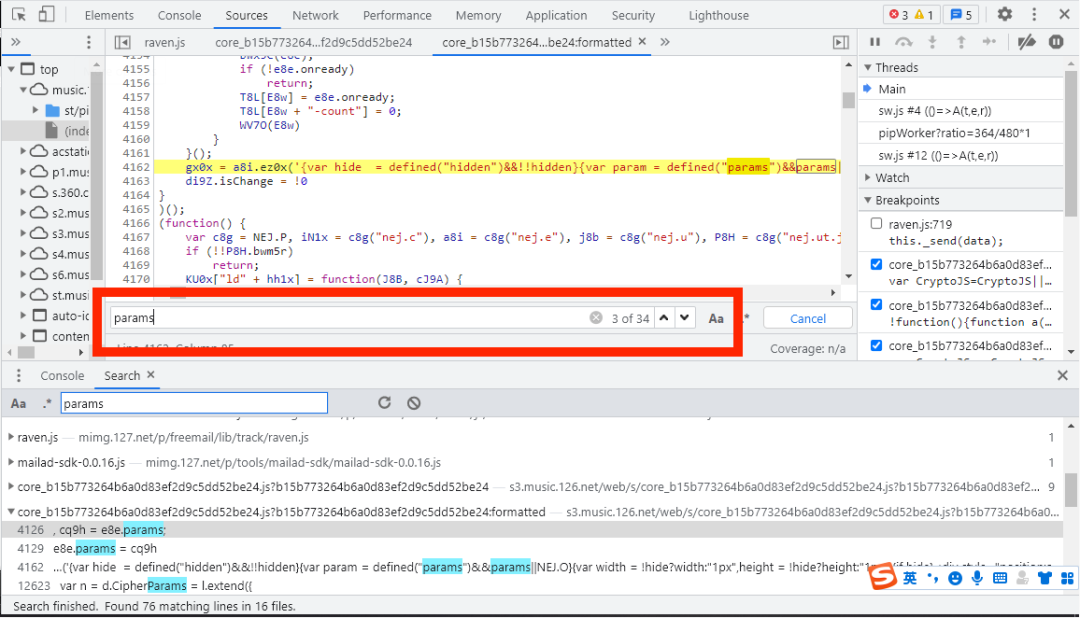
由上图可知,core_b15...中有34个params,这34个params中都有可能是加密参数,这里我们来告诉大家一个小技巧,一般情况下,加密参数都是以下形式输出的,
参数:
参数 =
所以我们可以在搜索框中稍稍加点东西,例如把搜索框中的params改为params:,结果如下图所示:
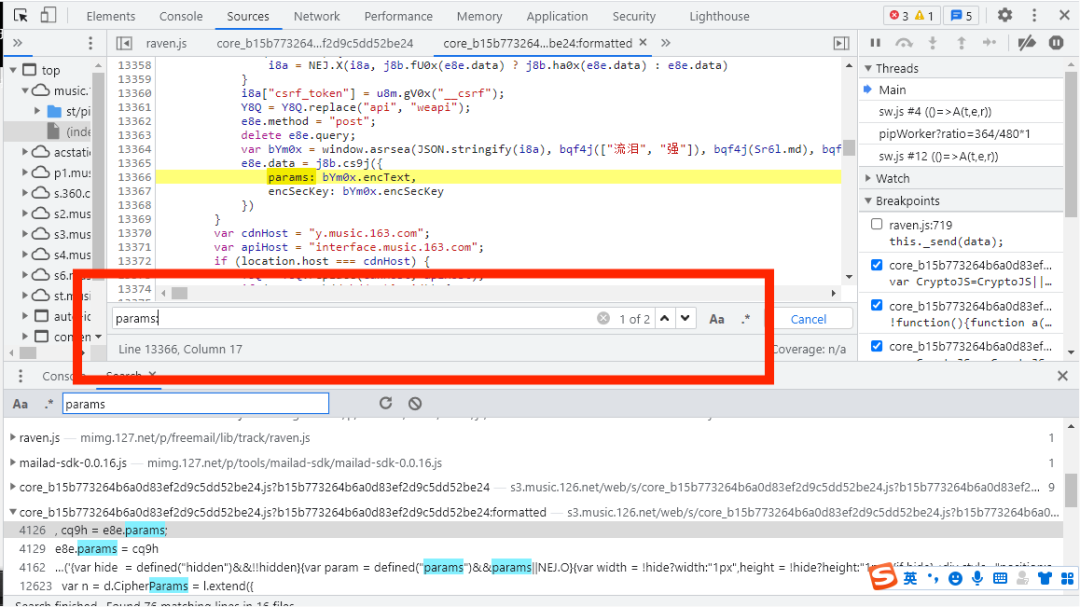
这样params就被我们精确到只有两个,接下来我们开始设置断点。
在上一步中,我们把params的范围缩短到只有两处,如下图所示:
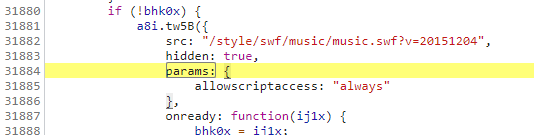

第一种图的params只是一个类似字典的变量,而第二张图的params:bYm0x.encText,表示在bYm0x中选取encText的值赋给params,而在13367行代码中,表示encSecKey为bYm0x中encSecKey的值,所以我们可以通过变量bYm0x来获取,而在params:bYm0x.encText上两行代码中,bYm0x变量中window调用了asrsea()方法,13364行代码是我们加密参数的函数。我们把鼠标放在window.asrsea中间,如下图所示:
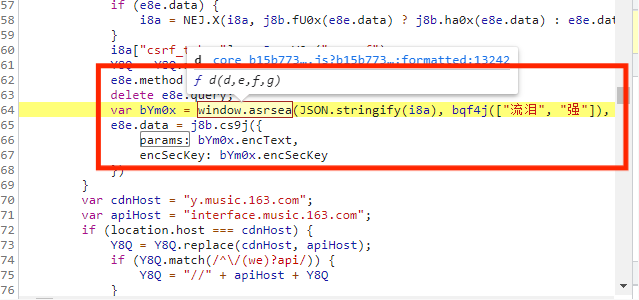
由上图可知,window.asrsea通过function d函数中调用的,其传入参数为d,e,f,g,点击f d(d,e,f,g),如下图所示:
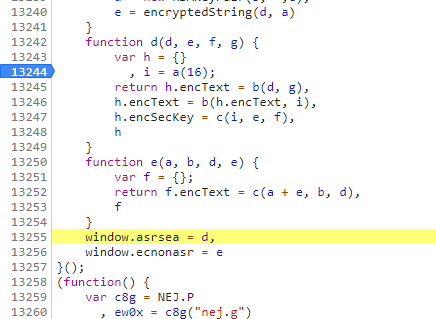
当我们不知道从哪里设置断点时,我们可以尝试在它调用函数的一行设置断点或者你认为哪行代码可疑就在哪行代码设置断点,刷新页面,如下图所示:
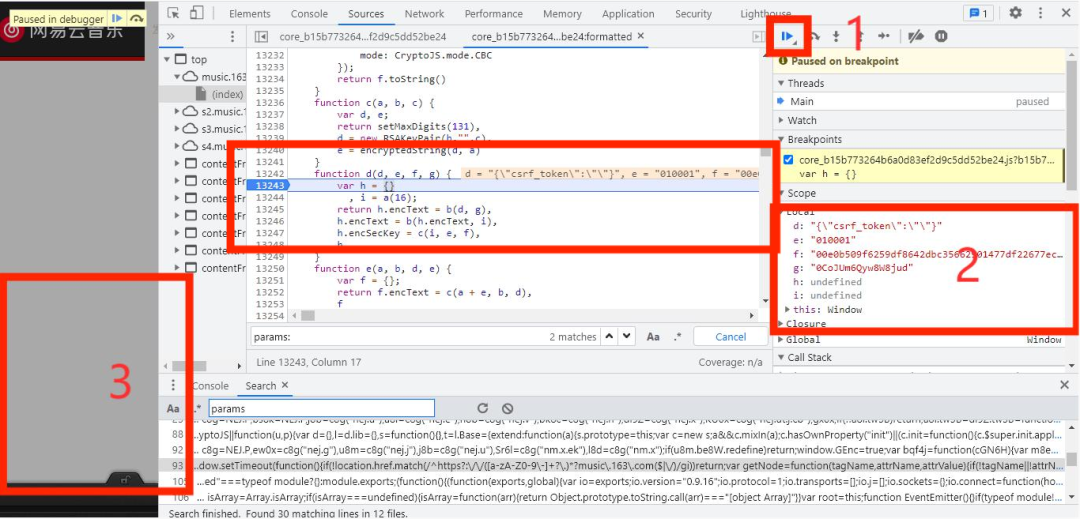
点击上图的1,一步步放开断点,注意观察上图中的2,3处的变化,如下图如下图所示:
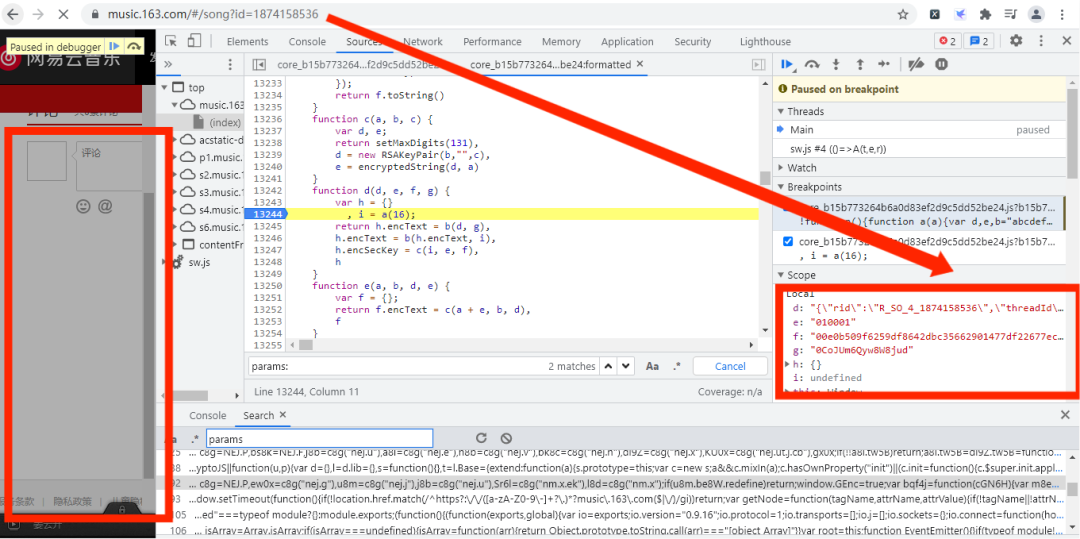
当左边出现了评论区,但没出现评论内容时,这时右边的方框刚好出现了d,e,f,g这三个数据,而且d中的数字刚好是歌曲的id。我们这四个参数复制下来,并去除\,观察一下:
d: "{"rid":"R_SO_4_1874158536","threadId":"R_SO_4_1874158536","pageNo":"1","pageSize":"20","cursor":"-1","offset":"0","orderType":"1","csrf_token":""}"
e: "010001"
f: "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
g: "0CoJUm6Qyw8W8jud"
通过上面的代码,我们推测rid和threadId是单曲id,pageNo是评论区的页数,pageSize是评论数据的行数,其他的不认识!!!
为了证实推测,我们换个歌单来测试获取d,e,f,g这四个参数:
d: "{"rid":"A_PL_0_6892176976","threadId":"A_PL_0_6892176976",\"pageNo":"1","pageSize":"20","cursor":"-1","offset":"0","orderType":"1","csrf_token":""}"
e: "010001"
f: "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
g: "0CoJUm6Qyw8W8jud"
通过观察可以发现,我们的推测是正确的,而且e,f,g是固定不变的,那么我们可以确定参数d中的参数就是未加密的参数,既然找到了未加密的参数,那么我们先把未加密的参数写入js文件中。
注意:rid中的A_PL_0代表的是歌单,而R_SO_4代表的是单曲。
未加密的参数我们在上一步已经获取到了,也就知道了加密参数的函数为接下来开始把加密参数的方法并写入js文件中。
该加密参数方法如下图所示:
加密参数方法为window.asrsea(),所以我们直接复制粘贴第13364行代码作为我们的加密参数方法,并写在入口函数中,并返回变量bYm0x,具体代码如下所示:
function start(){
var bYm0x = window.asrsea(JSON.stringify(i8a), bqf4j(["流泪", "强"]), bqf4j(Sr6l.md), bqf4j(["爱心", "女孩", "惊恐", "大笑"]));
return bYm0x
}
将鼠标放在window.asrsea中间,如下图所示:
在图中我们可以知道window.asrsea()调用了function d函数,而传入的参数对应着未加密的参数d、e、f、g,而d属于字典,e、f、g属于常量,所以我们可以把上面的代码改写为:
function start(){
var bYm0x=window.asrsea(JSON.stringify(d),e,f,g);
return bYm0x
}
写了入口函数后,我们开始观察function d函数,如下图所示:
通过function d()函数,我们发现function d()函数调用了a()函数、b()函数、c()函数,所以我们要把这些函数都复制在刚才的js文件中。当我们不知道要复制哪些代码时,就直接复制function d函数的外面一层花括号的所有代码,也就是第13217行代码为复制的开始点,第13257行代码为复制的结束点。
为了我们的js文件可以在控制台看到调试的结果,我们需要添加以下代码:
console.log(start())
好了,我们已经把代码复制在js文件中了,在调试js文件前,我们先安装node.js和node.js插件。
node.js安装方式很简单,进入node.js官网,如下图所示:
大家选择对应的系统来下载安装,由于安装实在太简单了,都是无脑下一步就可以了,当然最好参照网上的教程来安装,这里我们就不讲解如何安装node.js。
注意:一定要安装node.js,否则会在调试js文件中报以下错误:
execjs._exceptions.ProgramError: TypeError: ‘JSON‘ 未定义
我们写好js文件后,需要进行调试,而在pycharm中调试js文件需要安装node.js插件。
首先进入pycharm中的setting配置,如下图所示:
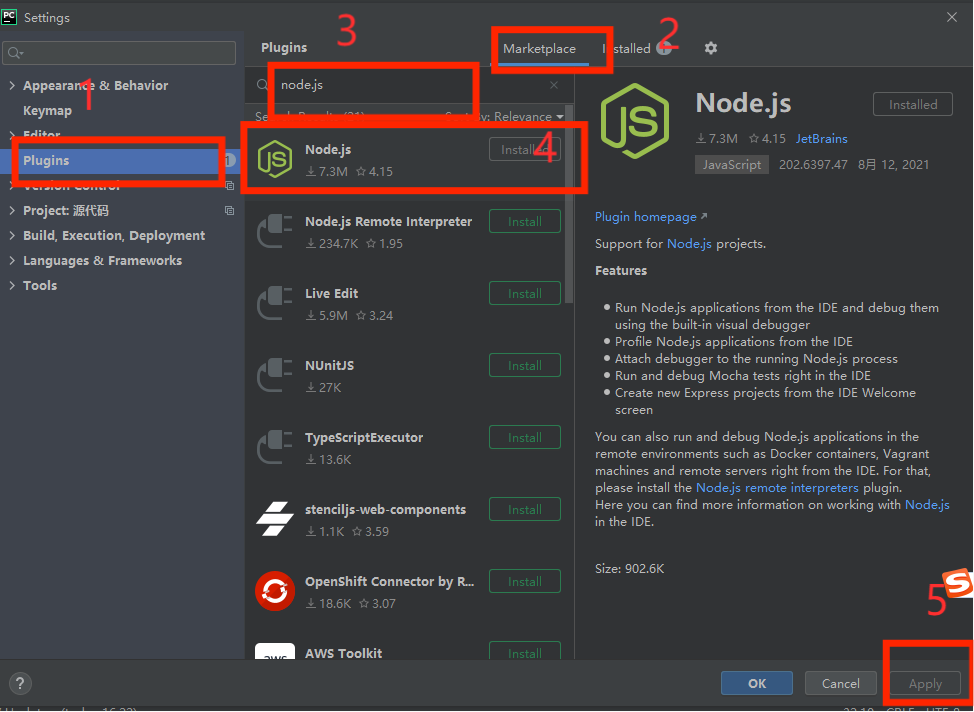
按照上图中的步骤,即可安装好插件。
好了,准备工作已经做好了,现在开始调试js文件,运行刚才的js文件,会发现报了以下错误:
window.asrsea = d,
^
ReferenceError: window is not defined
该错误是说window没定义,这时我们只需要在最前面添加以下代码即可:
window={}
进行运行我们的js文件,发现又报错了,错误如下所示:
var c = CryptoJS.enc.Utf8.parse(b)
^
ReferenceError: CryptoJS is not defined
错误提示又是参数没定义,但CryptoJS就不能简单的设置一个空字典,这需要我们继续在刚才的core_b15...中寻找CryptoJS了,如下图所示:
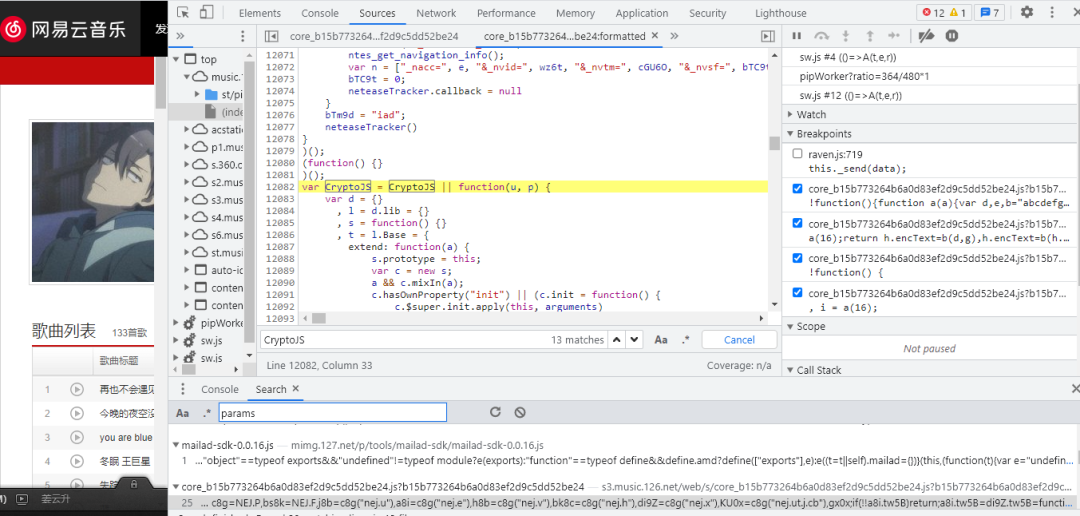
由图中可知,CryptoJS一共要13处那么多,那么我们该从何开始复制呢,又从何处结束复制呢,当我们不知道在哪里开始复制时,直接把所有的CrpytoJS都复制下来,请记住一个原则,宁愿复制多了也不复制少了,多了不会报错,少了会报错,而且还要找错,重新复制。
好了,我们复制完后,继续运行js文件。
运行结果如下:

好了,js文件已经运行准确无误了。接下来开始爬取数据
我们是通过Scrapy框架来爬取数据,所以我们首先来创建Scrapy项目和spider爬虫。
创建Scrapy项目和Spider爬虫很简单,依次执行以下代码即可:
scrapy startproject <Scrapy项目名>
cd <Scrapy项目名>
scrapy genspider <爬虫名字> <允许爬取的域名>
其中,我们的Scrapy项目名为NeteaseCould,爬虫名字为:NC,允许爬取的域名为:music.163.com。
好了创建Scrapy项目后,接下来我们创建一个名为JS的文件夹来存放刚才编写的js文件,项目目录如下所示:
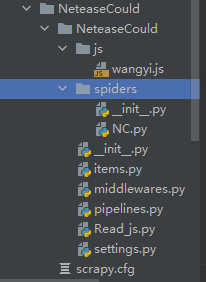
这里我们还创建了一个名为Read_js.py文件,该文件用来读取js文件。
我们编写好js文件后,当然要把它读取出来,具体代码如下所示:
def get_js():
path = dirname(realpath(__file__)) + '/js/' + 'wangyi' + '.js'
with open(path,'r',encoding='utf-8')as f:
r_js=f.read()
c_js=execjs.compile(r_js)
u_js=c_js.call('start')
data={
"params":u_js['encText'],
"encSecKey":u_js['encSecKey']
}
return data
我们把读取到的js文件内容存放在r_js变量中,然后通过execjs.compile()方法获取代码编译完成后的对象,再通过call()方法来调用js文件中的入口函数,也就是start()函数。然后将获取到的数据存放在字典data中,最后返回字典data。
对了,为了使我们的代码更灵活,我们可以把参数d放在Read_js.py文件中,具体代码如下所示:
url = 'https://music.163.com/#/song?id=17177324'
id = url.split('=')[-1]
d = {
"rid": f"R_SO_4_{id}",
"threadId": f"R_SO_4_{id}",
"pageNo": "1",
"pageSize": "5",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"csrf_token": ""
}
u_js=c_js.call('start',d)
首先利用split()方法把歌曲的id获取下来,然后放在参数d中,当我们需要获取另一首歌的评论信息的时候,只需要修改上面的url即可。注意:参数d中R_SO_4代表的单曲,当我们要获取其他的评论信息时,则需要更改R_SO_4,例如获取歌单的时候则需要更改为A_PL_0。
在获取数据前,我们先在items.py文件中,定义爬取数据的字典,具体代码如下所示:
import scrapy
class NeteasecouldItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
content = scrapy.Field()
在定义字段后,先看看评论数据的位置,如下图所示:
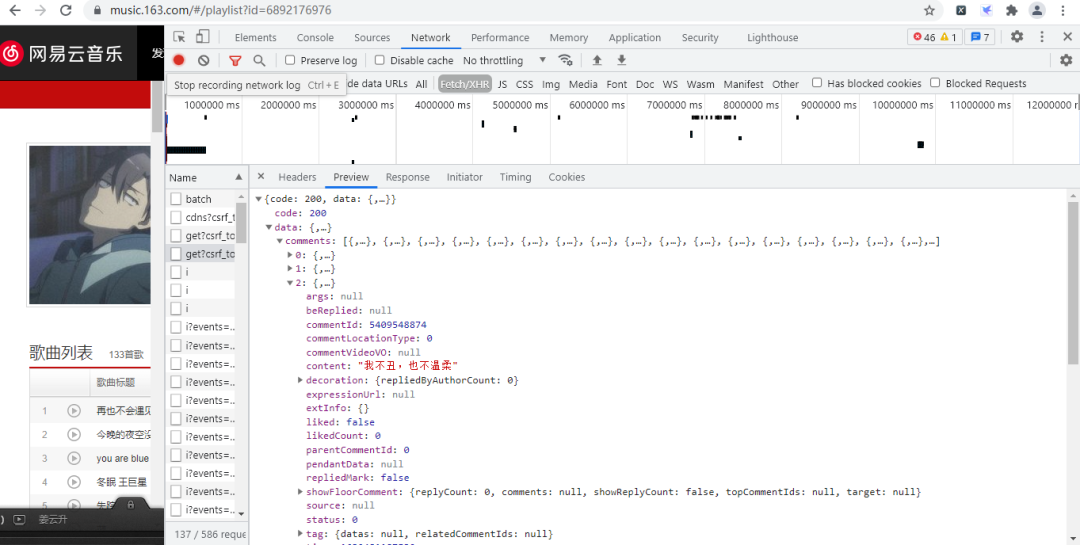
现在我们开始获取网易云音乐评论的数据,具体代码如下所示:
import scrapy
from NeteaseCould.Read_js import get_js
from NeteaseCould.items import NeteasecouldItem
class NcSpider(scrapy.Spider):
name = 'NC'
allowed_domains = ['music.163.com']
start_urls = ['https://music.163.com/weapi/comment/resource/comments/get?csrf_token=']
def start_requests(self):
js=get_js()
yield scrapy.FormRequest('https://music.163.com/weapi/comment/resource/comments/get?csrf_token=',formdata=js,callback=self.parse)
def parse(self, response):
json=response.json()
p=json.get('data').get('comments')
for i in p:
item = NeteasecouldItem()
item['content']=i.get('content')
yield item
首先我们导入get_js和NeteasecouldItem,再将start_urls中的链接修改为https://music.163.com/weapi/comment/resource/comments/get?csrf_token=。
由于我们发送的是POST请求,所以我们需要重写start_requests()方法,在start_requests()方法中,我们先调用了get_js()方法,然后在通过ForMReuqest()方法发送网络请求。
其中,formdata=相当于我们普通爬虫的data=callback=self.parse()表示将响应返回给parse()方法。
最后通过parse()方法进行数据的获取并通过yield生成器返回给引擎。
当我们需要把数据放在数据库或者存放在.txt文件中数,则需要在pipelines.py文件编写代码,这里我们把数据存放在txt文件中,具体代码如下所示:
from itemadapter import ItemAdapter
class NeteasecouldPipeline:
def process_item(self, item, spider):
with open('评论.txt','a',encoding='utf-8')as f:
f.write(item['content'])
f.write('\n')
对了,如何获取多条评论呢,通常情况下,我们需要进行翻页来获取多条评论,但是这次不同,我们可以修改参数d中的数据就可以获取多条评论,参数d如下所示:
d = {
"rid": f"R_SO_4_{id}",
"threadId": f"R_SO_4_{id}",
"pageNo": "1",
"pageSize": "5",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"csrf_token": ""
}
我们可以修改pageSize的数据,例如我现在的pageSize对应的是5,所以只获取五条评论。
最后,我们需要在settings.py文件中做一些配置,具体代码如下:
#屏蔽日志的输出
LOG_LEVEL="WARNING"
#开启引擎
ITEM_PIPELINES = {
'NeteaseCould.pipelines.NeteasecouldPipeline': 300,
}
所有的代码已经编写完毕了,现在我们开始运行爬虫,执行如下代码:
scrapy crawl NC
运行结果如下:
制作词云我们需要jieba库,wordcloud库、imageio库,其安装方式如下:
pip install jieba
pip install wordcloud
pip install imageio
在前面的步骤中,我们已经成功获取到评论并把评论数据保存在txt文本中,接下来我们将开始制作词云,具体代码如下:
import jieba
import wordcloud
import imageio
img_read=imageio.imread('小熊.jpg')
file_open=open('评论.txt', 'r', encoding='utf-8')
txt=file_open.read()
Cloud=wordcloud.WordCloud(width=1000,height=1000,background_color='white',mask=img_read,scale=8,font_path='C:\Windows\Fonts\msyhbd.ttc',stopwords={'的','了','是'})
txtlist=jieba.lcut(txt)
string=' '.join(txtlist)
Cloud.generate(string)
Cloud.to_file('小熊.png')
首先我们导入jieba、wordcloud、imageio库,再调用imageio.imread()方法来读取词云的背景图,然后再调用wordcloud.WordCloud()方法,把词云图设置宽高为1000,背景色为白色,词云图背景为刚才读取的图片。
注意:当我们做的词云有中文时,我们要把系统文字路径传入到wordcloud.WordCloud()方法中,这里我们还把“的,了,是”在词云中屏蔽掉。
然后我们调用jieba.lcut()方法把text.txt文本中的文字进行切割,由于我们分割出来的文字是以列表的形式保存的,所以调用join()方法把列表转换为字符
最后调用generate()方法生成词云,调用to_file()方法保存词云图。

好了,js逆向爬取网易云音乐评论并做词云就讲到这里了,感谢观看!!!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号