顶级Python项目学习指南(附代码)
发表时间: 2019-04-05 22:00

作者:Anirudh Rao
翻译:张睿毅
校对:王婷
本文约4600字,建议阅读20分钟。
本文介绍了三种不同的阶段去开发Python项目,旨在提供适合各种难度层次Python项目。
Python项目–Python的初级、中级和高级
在这个“Python 项目”博客中,让我们来看3个级别的Python项目,通过这三个项目您将会学习掌握Python,以及从整体上测试项目的分析、开发和处理问题的技能。
如果我说Python的学习真的很有趣,很多人都会同意的。
我们先浏览下面的主题列表,之后开始阅读这篇Python项目博客:
我应当先向您简单介绍一下Python。
Python简介
Python是一种高级的、面向对象的、解释性的编程语言。它在世界上享有广泛关注。Stack Overflow发现38.8%的用户主要使用Python来完成项目。
Python是由一个名为Guido Van Rossum的开发人员创建的。
Python是而且一直是很容易学习和掌握的。它对初学者非常友好,语法非常简单,易于阅读和理解。这特别让我们高兴,而令人更高兴的是Python在全球拥有数百万快乐的学习者!
根据该网站的调查,在2018年,Python的人气超过了c#,就像它在2017年超过了php一样。在GitHub平台上,Python超越了Java成为第二个最常用的编程语言,在2017中比2016多获得了40%的申请。
这使得Python认证成为最受欢迎的编程认证之一。
如何学习Python项目?
答案相当简单直接:从学习Python的初级知识和所有基本知识开始。这是一个用于了解您使用Python舒适程度的评价指标。
下一个主要步骤是看一看基本、简单的代码,以熟悉代码中的语法和逻辑流。这是一个非常重要的步骤,有助于为以后的工作打下坚实的基础。
在这之后,您还要看看在现实生活中Python如何使用。这将成为您在开始就要学习Python的主要原因。
如果您不是刚入门Python,那么您将会学习Python项目,并对自己的项目实施一些策略。接下来一定要看看您可以利用当前关于Python的知识进行处理哪些项目。深入研究Python会帮助您在各个阶段评估自己。
项目基本上是用来解决眼下问题的。如果为各种简单或复杂的问题提供解决方案是您的特长,那么您一定要考虑学习Python的项目。
每当着手搞定几个项目之后,您距离掌握Python将更近一步。这一点很重要,因为这样您就能够自然地将所学的知识应用到项目中,从简单的程序如计算器,到辅助实现人工智能的学习。
让我们从第一级的Python项目开始学习。
https://www.edureka.co/Python-programming-certification-training
初级Python项目:用Python实现《Hangman》游戏
我们能想到的最好的入门项目是《Hangman》游戏。我敢肯定读过这篇Python项目博客的大多数人都曾在生活中某个时刻玩过《Hangman》。用一句话来解释,它的主要目标是创建一个“猜词”游戏。尽管听起来很简单,但有一些关键的东西需要注意。
这意味着你需要一种方法来获取一个用于猜测的单词。让我们用简单思维,使用文本文件输入。文本文件包含了我们必须猜测的单词。
您还需要一些函数去检查用户是否实际输入了单个字母,检查输入的字母是否出现在单词中(如果是,则检查出现多少次),以及打印字母;还有一个计数器变量限制猜测的次数。
这个Python项目中有一些关键的概念需要牢记:
代码:
1. Hangman.py
from string import ascii_lowercasefrom words import get_random_worddef get_num_attempts(): """Get user-inputted number of incorrect attempts for the game.""" while True: num_attempts = input( 'How many incorrect attempts do you want? [1-25] ') try: num_attempts = int(num_attempts) if 1 <= num_attempts <= 25: return num_attempts else: print('{0} is not between 1 and 25'.format(num_attempts)) except ValueError: print('{0} is not an integer between 1 and 25'.format( num_attempts))def get_min_word_length(): """Get user-inputted minimum word length for the game.""" while True: min_word_length = input( 'What minimum word length do you want? [4-16] ') try: min_word_length = int(min_word_length) if 4 <= min_word_length <= 16: return min_word_length else: print('{0} is not between 4 and 16'.format(min_word_length)) except ValueError: print('{0} is not an integer between 4 and 16'.format( min_word_length)) def get_display_word(word, idxs): """Get the word suitable for display.""" if len(word) != len(idxs): raise ValueError('Word length and indices length are not the same') displayed_word = ''.join( [letter if idxs[i] else '*' for i, letter in enumerate(word)]) return displayed_word.strip() def get_next_letter(remaining_letters): """Get the user-inputted next letter.""" if len(remaining_letters) == 0: raise ValueError('There are no remaining letters') while True: next_letter = input('Choose the next letter: ').lower() if len(next_letter) != 1: print('{0} is not a single character'.format(next_letter)) elif next_letter not in ascii_lowercase: print('{0} is not a letter'.format(next_letter)) elif next_letter not in remaining_letters: print('{0} has been guessed before'.format(next_letter)) else: remaining_letters.remove(next_letter) return next_letter def play_hangman(): """Play a game of hangman. At the end of the game, returns if the player wants to retry. """ # Let player specify difficulty print('Starting a game of Hangman...') attempts_remaining = get_num_attempts() min_word_length = get_min_word_length() # Randomly select a word print('Selecting a word...') word = get_random_word(min_word_length) print() # Initialize game state variables idxs = [letter not in ascii_lowercase for letter in word] remaining_letters = set(ascii_lowercase) wrong_letters = [] word_solved = False # Main game loop while attempts_remaining > 0 and not word_solved: # Print current game state print('Word: {0}'.format(get_display_word(word, idxs))) print('Attempts Remaining: {0}'.format(attempts_remaining)) print('Previous Guesses: {0}'.format(' '.join(wrong_letters)))# Get player's next letter guess next_letter = get_next_letter(remaining_letters)# Check if letter guess is in word if next_letter in word: # Guessed correctly print('{0} is in the word!'.format(next_letter))# Reveal matching letters for i in range(len(word)): if word[i] == next_letter: idxs[i] = True else: # Guessed incorrectly print('{0} is NOT in the word!'.format(next_letter))# Decrement num of attempts left and append guess to wrong guesses attempts_remaining -= 1 wrong_letters.append(next_letter)# Check if word is completely solved if False not in idxs: word_solved = True print() # The game is over: reveal the word print('The word is {0}'.format(word))# Notify player of victory or defeat if word_solved: print('Congratulations! You won!') else: print('Try again next time!') # Ask player if he/she wants to try again try_again = input('Would you like to try again? [y/Y] ') return try_again.lower() == 'y'if __name__ == '__main__': while play_hangman(): print()
2.Words.py
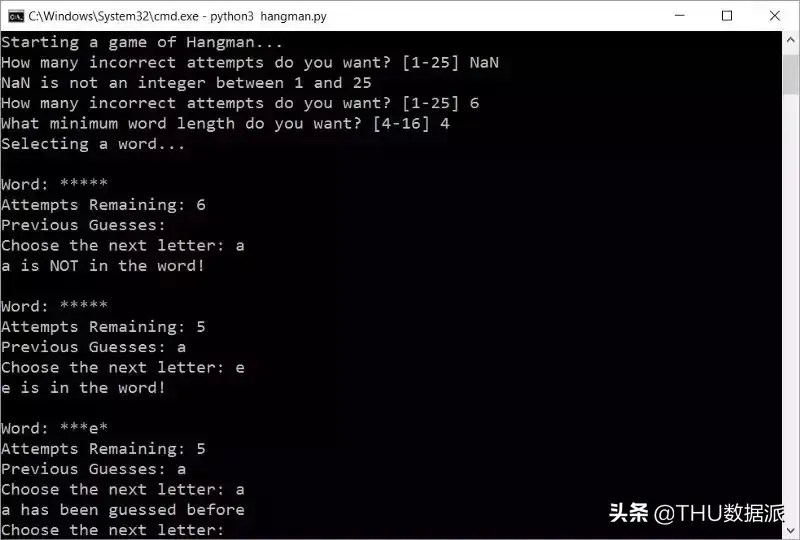
"""Function to fetch words."""import randomWORDLIST = 'wordlist.txt'def get_random_word(min_word_length): """Get a random word from the wordlist using no extra memory.""" num_words_processed = 0 curr_word = None with open(WORDLIST, 'r') as f: for word in f: if '(' in word or ')' in word: continue word = word.strip().lower() if len(word) < min_word_length: continue num_words_processed += 1 if random.randint(1, num_words_processed) == 1: curr_word = word return curr_word结果如图
现在我们已经了解了如何处理像《hangman》这样的初级项目,那么让我们稍微升级一下,尝试一个中级的Python项目。
中级Python项目:在Python中使用图形
开始学习Python编程的中间阶段的最好方法绝对是开始使用Python支持的库。
在用Python进行编码时,可以使用真正意义上的“n”个库。有些库是非常容易直接的,而有些可能需要一些时间来理解和掌握。
下面是一些您可以考虑入门学习的顶级库:
NumPy总的来说是用于科学计算的。
SciPy使用数组,例如用于线性代数、微积分和其他类似概念的基本数据结构。
Pandas用于数据帧,而Matplotlib则以图形和符号的形式显示数据。
实现数据可视化可能是Python最好的应用之一。尽管数字化的数据输出很有用,但对数据的可视化表示也有许多要求。
它通过可视化展现,只是一种抽象概括。从创建前端或图形用户界面(GUI)到将数字化数据绘制为图上的点。
Matplotlib用于在图形上绘制数据点。Matplotlib是一个绘图库,可以用于Python编程语言及其数字化数学扩展库NumPy。它提供了一个面向对象的API,通过使用通用的GUI工具包(如Tkinter、wxPython、Qy或GTK+),将绘图嵌入到应用中。
在Python中有许多用于三维绘图的选项,但这里有一些使用Matplotlib的常见简单方法。
一般来说,第一步是创建一个三维坐标轴,然后绘制出最能说明特定需求的数据的三维图形。为了使用Matplotlib,必须导入Matplotlib安装中包含的mplot3d工具包:
from mpl_toolkits import mplot3d
然后,要创建三维轴,可以执行以下代码:
<pre id="3346" class="graf graf--pre graf-after--p">%matplotlib inlineimport numpy as npimport matplotlib.pyplot as pltfig = plt.figure()ax = plt.axes(projection=’3d’)</pre>

在这个三维坐标轴中,可以绘制一个图,重要的是要知道哪种类型的图(或图的组合)可以更好地描述数据。
此时,您需要注意的是,这一操作是我们进一步绘图的基础。
https://www.edureka.co/Python-programming-certification-training
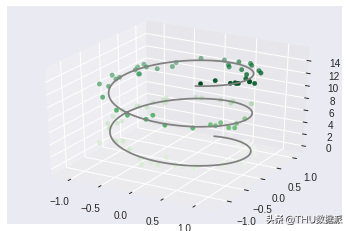
点和线:
下图结合了两个绘图,一个图带有一条线,该线穿过数据的每个点,另一个图在本例中的每个特定1000个值上绘制一个点。
这个代码分析时实际上非常简单。我们利用标准三角函数绘制了一组随机值,并利用这些数据生成三维投影。
代码:
ax = plt.axes(projection=’3d’)# Data for a three-dimensional linezline = np.linspace(0, 15, 1000)xline = np.sin(zline)yline = np.cos(zline)ax.plot3D(xline, yline, zline, ‘gray’)# Data for three-dimensional scattered pointszdata = 15 * np.random.random(100)xdata = np.sin(zdata) + 0.1 * np.random.randn(100)ydata = np.cos(zdata) + 0.1 * np.random.randn(100)ax.scatter3D(xdata, ydata, zdata, c=zdata, cmap=’Greens’);
三维等高线图
由于需要二维网格上的数据,因此轮廓图的输入与上一个绘图稍有不同。
请注意,在下面的示例中,在为x和y赋值之后,通过执行“np.meshgrid(x,y)”将它们组合到网格上,然后通过执行函数f(x,y)和网格值(z=f(x,y))创建z值。
再一次,基本的简化三维图为以下代码:
def f(x, y): return np.sin(np.sqrt(x ** 2 + y ** 2))x = np.linspace(-6, 6, 30)y = np.linspace(-6, 6, 30)X, Y = np.meshgrid(x, y)Z = f(X, Y)fig = plt.figure()ax = plt.axes(projection='3d')ax.contour3D(X, Y, Z, 50, cmap='binary')ax.set_xlabel('x')ax.set_ylabel('y')ax.set_zlabel('z');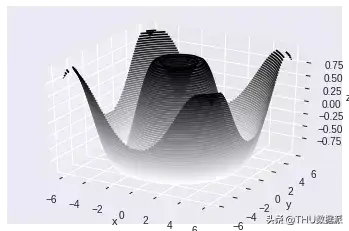
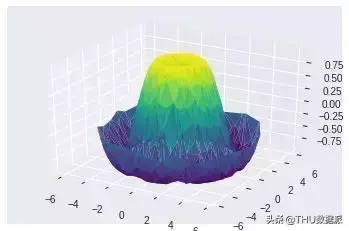
在以前的图形中,数据是按顺序生成的,但在现实生活中,有时数据是不按顺序生成的,对于这些情况,三角网格曲面测量非常有用,因为它通过查找相邻点之间形成的三角形集来创建曲面。
表面三角测量:
theta = 2 * np.pi * np.random.random(1000)r = 6 * np.random.random(1000)x = np.ravel(r * np.sin(theta))y = np.ravel(r * np.cos(theta))z = f(x, y)ax = plt.axes(projection=’3d’)ax.plot_trisurf(x, y, z,cmap=’viridis’, edgecolor=’none’);
现在我们已经熟悉了如何通过查看外部库来扩展我们对Python的学习,那么我们就可以研究下一个高级级别的Python项目。
Python 高级项目
Python有着广泛的应用——从“Hello World”一路走到实现人工智能。
实际上,您可以使用Python进行无限多的项目,但如果您想深入了解Python的核心,可以考虑以下几个主要的项目。
在这些里面,我最喜欢的就是机器学习和深度学习。让我们看一个非常好的用例以便深入学习Python。
在Python中使用TensorFlow实现CIFAR10
让我们训练一个网络,对CIFAR10数据集中的图像进行分类。可以使用TensorFlow内置的卷积神经网络。

为理解用例的工作原理,我们考虑以下流程图:
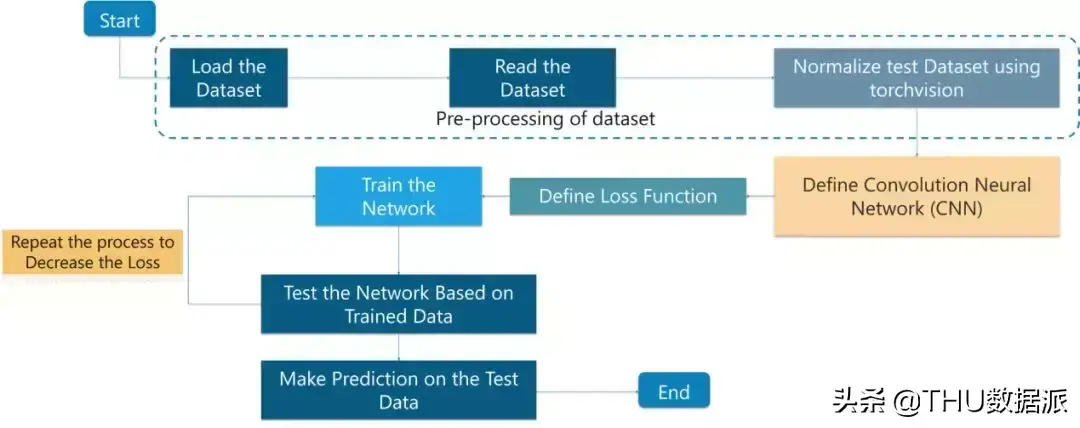
我们把这个流程图分解成简单的组分:
这个用例分为两个程序。一个是训练网络,另一个是测试网络。
我们先训练一下这个网络。
训练网络
import numpy as npimport tensorflow as tffrom time import timeimport mathfrom include.data import get_data_setfrom include.model import model, lrtrain_x, train_y = get_data_set("train")test_x, test_y = get_data_set("test")tf.set_random_seed(21)x, y, output, y_pred_cls, global_step, learning_rate = model()global_accuracy = 0epoch_start = 0# PARAMS_BATCH_SIZE = 128_EPOCH = 60_SAVE_PATH = "./tensorboard/cifar-10-v1.0.0/"# LOSS AND OPTIMIZERloss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=output, labels=y))optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-08).minimize(loss, global_step=global_step)# PREDICTION AND ACCURACY CALCULATIONcorrect_prediction = tf.equal(y_pred_cls, tf.argmax(y, axis=1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))# SAVERmerged = tf.summary.merge_all()saver = tf.train.Saver() sess = tf.Session() train_writer = tf.summary.FileWriter(_SAVE_PATH, sess.graph)try: print("\nTrying to restore last checkpoint ...") last_chk_path = tf.train.latest_checkpoint(checkpoint_dir=_SAVE_PATH) saver.restore(sess, save_path=last_chk_path) print("Restored checkpoint from:", last_chk_path)except ValueError: print("\nFailed to restore checkpoint. Initializing variables instead.") sess.run(tf.global_variables_initializer())def train(epoch): global epoch_start epoch_start = time() batch_size = int(math.ceil(len(train_x) / _BATCH_SIZE)) i_global = 0 for s in range(batch_size): batch_xs = train_x[s*_BATCH_SIZE: (s+1)*_BATCH_SIZE] batch_ys = train_y[s*_BATCH_SIZE: (s+1)*_BATCH_SIZE] start_time = time() i_global, _, batch_loss, batch_acc = sess.run( [global_step, optimizer, loss, accuracy], feed_dict={x: batch_xs, y: batch_ys, learning_rate: lr(epoch)}) duration = time() - start_time if s % 10 == 0: percentage = int(round((s/batch_size)*100))bar_len = 29 filled_len = int((bar_len*int(percentage))/100) bar = '=' * filled_len + '>' + '-' * (bar_len - filled_len)msg = "Global step: {:>5} - [{}] {:>3}% - acc: {:.4f} - loss: {:.4f} - {:.1f} sample/sec" print(msg.format(i_global, bar, percentage, batch_acc, batch_loss, _BATCH_SIZE / duration)) test_and_save(i_global, epoch)def test_and_save(_global_step, epoch): global global_accuracy global epoch_start i = 0 predicted_class = np.zeros(shape=len(test_x), dtype=np.int) while i < len(test_x): j = min(i + _BATCH_SIZE, len(test_x)) batch_xs = test_x[i:j, :] batch_ys = test_y[i:j, :] predicted_class[i:j] = sess.run( y_pred_cls, feed_dict={x: batch_xs, y: batch_ys, learning_rate: lr(epoch)} ) i = j correct = (np.argmax(test_y, axis=1) == predicted_class) acc = correct.mean()*100 correct_numbers = correct.sum() hours, rem = divmod(time() - epoch_start, 3600) minutes, seconds = divmod(rem, 60) mes = "\nEpoch {} - accuracy: {:.2f}% ({}/{}) - time: {:0>2}:{:0>2}:{:05.2f}" print(mes.format((epoch+1), acc, correct_numbers, len(test_x), int(hours), int(minutes), seconds)) if global_accuracy != 0 and global_accuracy < acc: summary = tf.Summary(value=[ tf.Summary.Value(tag="Accuracy/test", simple_value=acc), ]) train_writer.add_summary(summary, _global_step) saver.save(sess, save_path=_SAVE_PATH, global_step=_global_step) mes = "This epoch receive better accuracy: {:.2f} > {:.2f}. Saving session..." print(mes.format(acc, global_accuracy)) global_accuracy = acc elif global_accuracy == 0: global_accuracy = acc print("###########################################################################################################")def main(): train_start = time() for i in range(_EPOCH): print("\nEpoch: {}/{}\n".format((i+1), _EPOCH)) train(i) hours, rem = divmod(time() - train_start, 3600) minutes, seconds = divmod(rem, 60) mes = "Best accuracy pre session: {:.2f}, time: {:0>2}:{:0>2}:{:05.2f}" print(mes.format(global_accuracy, int(hours), int(minutes), seconds))if __name__ == "__main__": main()sess.close()输出: Epoch: 60/60 Global step: 23070 - [>-----------------------------] 0% - acc: 0.9531 - loss: 1.5081 - 7045.4 sample/secGlobal step: 23080 - [>-----------------------------] 3% - acc: 0.9453 - loss: 1.5159 - 7147.6 sample/secGlobal step: 23090 - [=>----------------------------] 5% - acc: 0.9844 - loss: 1.4764 - 7154.6 sample/secGlobal step: 23100 - [==>---------------------------] 8% - acc: 0.9297 - loss: 1.5307 - 7104.4 sample/secGlobal step: 23110 - [==>---------------------------] 10% - acc: 0.9141 - loss: 1.5462 - 7091.4 sample/secGlobal step: 23120 - [===>--------------------------] 13% - acc: 0.9297 - loss: 1.5314 - 7162.9 sample/secGlobal step: 23130 - [====>-------------------------] 15% - acc: 0.9297 - loss: 1.5307 - 7174.8 sample/secGlobal step: 23140 - [=====>------------------------] 18% - acc: 0.9375 - loss: 1.5231 - 7140.0 sample/secGlobal step: 23150 - [=====>------------------------] 20% - acc: 0.9297 - loss: 1.5301 - 7152.8 sample/secGlobal step: 23160 - [======>-----------------------] 23% - acc: 0.9531 - loss: 1.5080 - 7112.3 sample/secGlobal step: 23170 - [=======>----------------------] 26% - acc: 0.9609 - loss: 1.5000 - 7154.0 sample/secGlobal step: 23180 - [========>---------------------] 28% - acc: 0.9531 - loss: 1.5074 - 6862.2 sample/secGlobal step: 23190 - [========>---------------------] 31% - acc: 0.9609 - loss: 1.4993 - 7134.5 sample/secGlobal step: 23200 - [=========>--------------------] 33% - acc: 0.9609 - loss: 1.4995 - 7166.0 sample/secGlobal step: 23210 - [==========>-------------------] 36% - acc: 0.9375 - loss: 1.5231 - 7116.7 sample/secGlobal step: 23220 - [===========>------------------] 38% - acc: 0.9453 - loss: 1.5153 - 7134.1 sample/secGlobal step: 23230 - [===========>------------------] 41% - acc: 0.9375 - loss: 1.5233 - 7074.5 sample/secGlobal step: 23240 - [============>-----------------] 43% - acc: 0.9219 - loss: 1.5387 - 7176.9 sample/secGlobal step: 23250 - [=============>----------------] 46% - acc: 0.8828 - loss: 1.5769 - 7144.1 sample/secGlobal step: 23260 - [==============>---------------] 49% - acc: 0.9219 - loss: 1.5383 - 7059.7 sample/secGlobal step: 23270 - [==============>---------------] 51% - acc: 0.8984 - loss: 1.5618 - 6638.6 sample/secGlobal step: 23280 - [===============>--------------] 54% - acc: 0.9453 - loss: 1.5151 - 7035.7 sample/secGlobal step: 23290 - [================>-------------] 56% -acc: 0.9609 - loss: 1.4996 - 7129.0 sample/secGlobal step: 23300 - [=================>------------] 59% - acc: 0.9609 - loss: 1.4997 - 7075.4 sample/secGlobal step: 23310 - [=================>------------] 61% - acc: 0.8750 - loss: 1.5842 - 7117.8 sample/secGlobal step: 23320 - [==================>-----------] 64% - acc: 0.9141 - loss: 1.5463 - 7157.2 sample/secGlobal step: 23330 - [===================>----------] 66% - acc:0.9062 - loss: 1.5549 - 7169.3 sample/secGlobal step: 23340 - [====================>---------] 69% - acc: 0.9219 - loss: 1.5389 - 7164.4 sample/secGlobal step: 23350 - [====================>---------] 72% - acc: 0.9609 - loss: 1.5002 - 7135.4 sample/secGlobal step: 23360 - [=====================>--------] 74% - acc: 0.9766 - loss: 1.4842 - 7124.2 sample/secGlobal step: 23370 - [======================>-------] 77% - acc: 0.9375 - loss: 1.5231 - 7168.5 sample/secGlobal step: 23380 - [======================>-------] 79% - acc: 0.8906 - loss: 1.5695 - 7175.2 sample/secGlobal step: 23390 - [=======================>------] 82% - acc: 0.9375 - loss: 1.5225 - 7132.1 sample/secGlobal step: 23400 - [========================>-----] 84% - acc: 0.9844 - loss: 1.4768 - 7100.1 sample/secGlobal step: 23410 - [=========================>----] 87% - acc: 0.9766 - loss: 1.4840 - 7172.0 sample/secGlobal step: 23420 - [==========================>---] 90% - acc: 0.9062 - loss: 1.5542 - 7122.1 sample/secGlobal step: 23430 - [==========================>---] 92% - acc:0.9297 - loss: 1.5313 - 7145.3 sample/secGlobal step: 23440 - [===========================>--] 95% - acc: 0.9297 - loss: 1.5301 - 7133.3 sample/secGlobal step: 23450 - [============================>-] 97% - acc: 0.9375 - loss: 1.5231 - 7135.7 sample/secGlobal step: 23460 - [=============================>] 100% - acc: 0.9250 - loss: 1.5362 - 10297.5 sample/sec Epoch 60 - accuracy: 78.81% (7881/10000)This epoch receive better accuracy: 78.81 > 78.78. Saving session...在测试数据集上运行网络
import numpy as npimport tensorflow as tffrom include.data import get_data_setfrom include.model import modeltest_x, test_y = get_data_set("test")x, y, output, y_pred_cls, global_step, learning_rate = model()_BATCH_SIZE = 128_CLASS_SIZE = 10_SAVE_PATH = "./tensorboard/cifar-10-v1.0.0/"saver = tf.train.Saver()sess = tf.Session()try: print("\nTrying to restore last checkpoint ...") last_chk_path = tf.train.latest_checkpoint(checkpoint_dir=_SAVE_PATH) saver.restore(sess, save_path=last_chk_path) print("Restored checkpoint from:", last_chk_path)except ValueError: print("\nFailed to restore checkpoint. Initializing variables instead.") sess.run(tf.global_variables_initializer())def main(): i = 0 predicted_class = np.zeros(shape=len(test_x), dtype=np.int) while i < len(test_x): j = min(i + _BATCH_SIZE, len(test_x)) batch_xs = test_x[i:j, :] batch_ys = test_y[i:j, :] predicted_class[i:j] = sess.run(y_pred_cls, feed_dict={x: batch_xs, y: batch_ys}) i = j correct = (np.argmax(test_y, axis=1) == predicted_class) acc = correct.mean() * 100 correct_numbers = correct.sum() print() print("Accuracy on Test-Set: {0:.2f}% (开发人员 / 自然语言处理)".format(acc, correct_numbers, len(test_x)))if __name__ == "__main__": main()sess.close()简单输出:
Trying to restore last checkpoint ...Restored checkpoint from: ./tensorboard/cifar-10-v1.0.0/-23460Accuracy on Test-Set: 78.81% (7881 / 10000)
这难道不是一个非常有趣的用例吗?至此,我们了解了机器学习是如何工作的,开发了一个基本程序,并使用Python中的TensorFlow来实现了它。
原文标题:
Top Python Projects You Should Consider Learning
原文链接:
https://www.edureka.co/blog/python-projects/
编辑:王菁
校对:龚力
译者简介

张睿毅,北京邮电大学大二物联网在读。我是一个爱自由的人。在邮电大学读第一年书我就四处跑去蹭课,折腾整一年惊觉,与其在当下焦虑,不如在前辈中沉淀。于是在大二以来,坚持读书,不敢稍歇。资本主义国家的科学观不断刷新我的认知框架,同时因为出国考试很早出分,也更早地感受到自己才是那个一直被束缚着的人。太多真英雄在社会上各自闪耀着光芒。这才开始,立志终身向遇到的每一个人学习。做一个纯粹的计算机科学里面的小学生。喜欢算法,数据挖掘,图像识别,自然语言处理,神经网络,人工智能等方向。
— 完 —
关注清华-青岛数据科学研究院官方微信公众平台“THU数据派”及姊妹号“数据派THU”获取更多讲座福利及优质内容。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号