提升代码质量:Swift的妙用
发表时间: 2023-05-10 09:56
作者:京东零售 何骁
京喜APP最早在2019年引入了Swift,使用Swift完成了第一个订单模块的开发。之后一年多我们持续在团队/公司内部推广和普及Swift,目前Swift已经支撑了70%+以上的业务。通过使用Swift提高了团队内同学的开发效率,同时也带来了质量的提升,目前来自Swift的Crash的占比不到1%。在这过程中不断的学习/实践,团队内的Code Review,也对如何使用Swift来提高代码质量有更深的理解。
在讨论如何使用Swift提高代码质量之前,我们先来看看Swift本身相比ObjC或其他编程语言有什么优势。Swift有三个重要的特性分别是富有表现力/安全性/快速,接下来我们分别从这三个特性简单介绍一下:
Swift提供更多的编程范式和特性支持,可以编写更少的代码,而且易于阅读和维护。
提示:类型推断同时也会增加一定的编译耗时,不过Swift团队也在不断的改善编译速度。
提示:编写ObjC代码时,我们通常会在编码时添加类型检查避免运行时崩溃导致Crash。
提示:ObjC消息派发会导致编译器无法进行移除无用方法/类的优化,编译器并不知道是否可能被用到。
提示: 相比ObjC,Swift内部不需要使用autorelease进行管理。
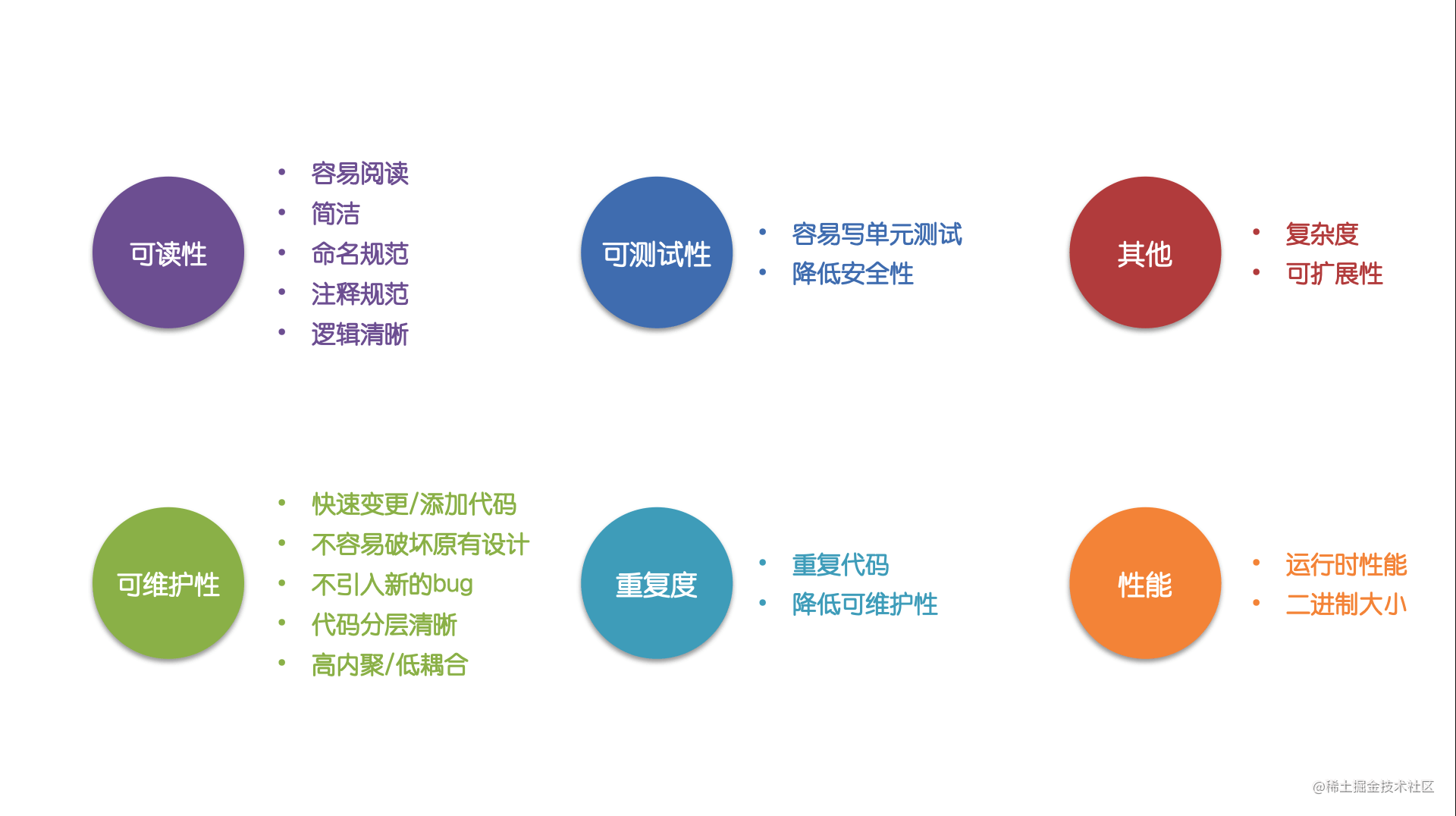
以上是一些常见的代码质量指标。我们的目标是如何更好的使用Swift编写出符合代码质量指标要求的代码。
提示:本文不涉及设计模式/架构,更多关注如何通过合理使用Swift特性做局部代码段的重构。
因为Any/AnyObject缺少明确的类型信息,编译器无法进行类型检查,会带来一些问题:
当使用Any/AnyObject时会频繁使用as?进行类型转换。这好像没什么问题因为使用as?并不会导致程序Crash。不过代码错误至少应该分为两类,一类是程序本身的错误通常会引发Crash,另外一种是业务逻辑错误。使用as?只是避免了程序错误Crash,但是并不能防止业务逻辑错误。
func do(data: Any?) { guard let string = data as? String else { return } // }do(1)do("")以上面的例子为例,我们进行了as?转换,当data为String时才会进行处理。但是当do方法内String类型发生了改变函数,使用方并不知道已变更没有做相应的适配,这时候就会造成业务逻辑的错误。
提示:这类错误通常更难发现,这也是我们在一次真实bug场景遇到的。
代码中大量Dictionary数据结构会降低代码可维护性,同时带来潜在的bug:
提示:自定义类型还有个好处,例如JSON转自定义类型时会进行类型/nil/属性名检查,可以避免将错误数据丢到下一层。
let dic: [String: Any]let num = dic["value"] as? Intdic["name"] = "name"struct Data { let num: Int var name: String?}let num = data.numdata.name = "name"例如使用枚举改造NSAttributedStringAPI,原有APIvalue为Any类型无法限制特定的类型。
let string = NSMutableAttributedString()string.addAttribute(.foregroundColor, value: UIColor.red, range: range)enum NSAttributedStringKey { case foregroundColor(UIColor)}let string = NSMutableAttributedString()string.addAttribute(.foregroundColor(UIColor.red), range: range) // 不传递Color会报错使用泛型或协议关联类型代替Any,通过泛型类型约束来使编译器进行更多的类型检查。
代码中存在重复的硬编码字符串/数字,在修改时可能会因为不同步引发bug。尽可能减少硬编码字符串/数字,使用枚举或常量代替。
KeyPath包含属性名和类型信息,可以避免硬编码字符串,同时当属性名或类型改变时编译器会进行检查。
class SomeClass: NSObject { @objc dynamic var someProperty: Int init(someProperty: Int) { self.someProperty = someProperty }}let object = SomeClass(someProperty: 10)object.observeValue(forKeyPath: "", of: nil, change: nil, context: nil)let object = SomeClass(someProperty: 10)object.observe(\.someProperty) { object, change in}!属性会在读取时隐式强解包,当值不存在时产生运行时异常导致Crash。
class ViewController: UIViewController { @IBOutlet private var label: UILabel! // @IBOutlet需要使用!}使用!强解包会在值不存在时产生运行时异常导致Crash。
var num: Int?let num2 = num! // 错误提示:建议只在小范围的局部代码段使用!强解包。
使用try!会在方法抛出异常时产生运行时异常导致Crash。
try! method()resource.request().onComplete { [weak self] response in guard let self = self else { return } let model = self.updateModel(response) self.updateUI(model)}resource.request().onComplete { [unowned self] response in let model = self.updateModel(response) self.updateUI(model)}unowned在值不存在时会产生运行时异常导致Crash,只有在确定self一定会存在时才使用unowned。
class Class { @objc unowned var object: Object @objc weak var object: Object?}unowned/weak区别:
可选值的价值在于通过明确标识值可能会为nil并且编译器强制对值进行nil判断。但是不应该随意的定义可选值,可选值不能用let定义,并且使用时必须进行解包操作相对比较繁琐。在代码设计时应考虑这个值是否有可能为nil,只在合适的场景使用可选值。
class Object { var num: Int?}let object = Object()object.num = 1class Object { let num: Int init(num: Int) { self.num = num }}let object = Object(num: 1)在使用可选值时,通常我们需要在可选值为nil时进行异常处理。有时候我们会通过给予可选值默认值的方式来处理。但是这里应考虑在什么场景下可以给予默认值。在不能给予默认值的场景应当及时使用return或抛出异常,避免错误的值被传递到更多的业务流程。
func confirmOrder(id: String) {}// 给予错误的值会导致错误的值被传递到更多的业务流程confirmOrder(id: orderId ?? "")func confirmOrder(id: String) {}guard let orderId = orderId else { // 异常处理 return}confirmOrder(id: orderId)提示:通常强业务相关的值不能给予默认值:例如商品/订单id或是价格。在可以使用兜底逻辑的场景使用默认值,例如默认文字/文字颜色。
Object结构同时只会有一个值存在:
class Object { var name: Int? var num: Int?}enum CustomType { case name(String) case num(Int)}使用计算属性可以减少多个变量同步带来的潜在bug。
class model { var data: Object? var loaded: Bool}model.data = Object()loaded = falseclass model { var data: Object? var loaded: Bool { return data != nil }}model.data = Object()提示:计算属性因为每次都会重复计算,所以计算过程需要轻量避免带来性能问题。
使用filter/reduce/map可以带来很多好处,包括更少的局部变量,减少模板代码,代码更加清晰,可读性更高。
let nums = [1, 2, 3]var result = []for num in nums { if num < 3 { result.append(String(num)) }}// result = ["1", "2"]let nums = [1, 2, 3]let result = nums.filter { $0 < 3 }.map { String($0) }// result = ["1", "2"]guard !a else { return}guard !b else { return}// doif a { if b { // do }}let b = truelet a = b ? 1 : 2let c: Int?let b = c ?? 1var a: Int?if b { a = 1} else { a = 2}for循环添加where语句,只有当where条件满足时才会进入循环
for item in collection { if item.hasProperty { // ... }}for item in collection where item.hasProperty { // item.hasProperty == true,才会进入循环}defer可以保证在函数退出前一定会执行。可以使用defer中实现退出时一定会执行的操作例如资源释放等避免遗漏。
func method() { lock.lock() defer { lock.unlock() // 会在method作用域结束的时候调用 } // do}在定义复杂字符串时,使用多行字符串字面量可以保持原有字符串的换行符号/引号等特殊字符,不需要使用\进行转义。
let quotation = """The White Rabbit put on his spectacles. "Where shall I begin,please your Majesty?" he asked."Begin at the beginning," the King said gravely, "and go ontill you come to the end; then stop.""""提示:上面字符串中的""和换行可以自动保留。
使用字符串插值可以提高代码可读性。
let multiplier = 3let message = String(multiplier) + "times 2.5 is" + String((Double(multiplier) * 2.5))let multiplier = 3let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"var nums = []nums.count == 0nums[0]var nums = []nums.isEmptynums.firstSwift中默认访问控制级别为internal。编码中应当尽可能减小属性/方法/类型的访问控制级别隐藏内部实现。
提示:同时也有利于编译器进行优化。
private let num = 1class MyClass { private var num: Int}class MyClass { private(set) var num = 1}let num = MyClass().numMyClass().num = 2 // 会编译报错使用参数默认值,可以使调用方传递更少的参数。
func test(a: Int, b: String?, c: Int?) {}test(1, nil, nil)func test(a: Int, b: String? = nil, c: Int? = nil) {}test(1)提示:相比ObjC,参数默认值也可以让我们定义更少的方法。
当方法参数过多时考虑使用自定义类型代替。
func f(a: Int, b: Int, c: Int, d: Int, e: Int, f: Int) {}struct Params { let a, b, c, d, e, f: Int}func f(params: Params) {}某些方法使用方并不一定会处理返回值,可以考虑添加@discardableResult标识提示Xcode允许不处理返回值不进行warning提示。
// 上报方法使用方不关心是否成功func report(id: String) -> Bool {} @discardableResult func report2(id: String) -> Bool {}report("1") // 编译器会警告report2("1") // 不处理返回值编译器不会警告元组虽然具有类型信息,但是并不包含变量名信息,使用方并不清晰知道变量的含义。所以当元组数量过多时考虑使用自定义类型代替。
func test() -> (Int, Int, Int) {}let (a, b, c) = test()// a,b,c类型一致,没有命名信息不清楚每个变量的含义block API的优势:
class Object: NSObject { init() { super.init() addObserver(self, forKeyPath: "value", options: .new, context: nil) NotificationCenter.default.addObserver(self, selector: #selector(test), name: NSNotification.Name(rawValue: ""), object: nil) } override class func observeValue(forKeyPath keyPath: String?, of object: Any?, change: [NSKeyValueChangeKey : Any]?, context: UnsafeMutableRawPointer?) { } @objc private func test() { } deinit { removeObserver(self, forKeyPath: "value") NotificationCenter.default.removeObserver(self) }}class Object: NSObject { private var observer: AnyObserver? private var kvoObserver: NSKeyValueObservation? init() { super.init() observer = NotificationCenter.default.addObserver(forName: NSNotification.Name(rawValue: ""), object: nil, queue: nil) { (_) in } kvoObserver = foo.observe(\.value, options: [.new]) { (foo, change) in } }}Swift中针对protocol提供了很多新特性,例如默认实现,关联类型,支持值类型。在代码设计时可以优先考虑使用protocol来避免臃肿的父类同时更多使用值类型。
提示:一些无法用protocol替代继承的场景:1.需要继承NSObject子类。2.需要调用super方法。3.实现抽象类的能力。
使用extension将私有方法/父类方法/协议方法等不同功能代码进行分离更加清晰/易维护。
class MyViewController: UIViewController { // class stuff here}// MARK: - Privateextension: MyViewController { private func method() {}}// MARK: - UITableViewDataSourceextension MyViewController: UITableViewDataSource { // table view data source methods}// MARK: - UIScrollViewDelegateextension MyViewController: UIScrollViewDelegate { // scroll view delegate methods}良好的代码风格可以提高代码的可读性,统一的代码风格可以降低团队内相互理解成本。对于Swift的代码格式化建议使用自动格式化工具实现,将自动格式化添加到代码提交流程,通过定义Lint规则统一团队内代码风格。考虑使用SwiftFormat和SwiftLint。
提示:SwiftFormat主要关注代码样式的格式化,SwiftLint可以使用autocorrect自动修复部分不规范的代码。
性能优化上主要关注提高运行时性能和降低二进制体积。需要考虑如何更好的使用Swift特性,同时提供更多信息给编译器进行优化。
当Xcode开启WMO优化时,编译器可以将整个程序编译为一个文件进行更多的优化。例如通过推断final/函数内联/泛型特化更多使用静态派发,并且可以移除部分未使用的代码。
当我们使用组件化时,为了提高编译速度和打包效率,通常单个组件独立编译生成静态库,最后多个组件直接使用静态库进行打包。这种场景下WMO仅针对internal以内作用域生效,对于public/open缺少外部使用信息所以无法进行优化。所以对于大量使用Swift的项目,使用全量代码打包更有利于编译器做更多优化。
在使用Array/String时,可以使用Slice切片获取一部分数据。Slice保存对原始Array/String的引用共享内存数据,不需要重新分配空间进行存储。
let midpoint = absences.count / 2let firstHalf = absences[..提示:应避免一直持有Slice,Slice会延长原始Array/String的生命周期导致无法被释放造成内存泄漏。
protocol AnyProtocol {}protocol ObjectProtocol: AnyObject {}当protocol仅限制为class使用时,继承AnyObject协议可以使编译器不需要考虑值类型实现,提高运行时性能。
// 原始代码let label = UILabel().then { $0.textAlignment = .center $0.textColor = UIColor.black $0.text = "Hello, World!"}以then库为例,他使用闭包进行对象初始化以后的相关设置。但是 then 方法以及闭包也会带来额外的性能消耗。
@inlinablepublic func then(_ block: (Self) throws -> Void) rethrows -> Self { try block(self) return self}// 编译器内联优化后let label = UILabel() label.textAlignment = .centerlabel.textColor = UIColor.blacklabel.text = "Hello, World!"class View { var lazy label: UILabel = { let label = UILabel() self.addSubView(label) return label }()}lazy属性初始化会延迟到第一次使用时,常见的使用场景:
提示:lazy属性不能保证线程安全
private let属性会增加每个class对象的内存大小。同时会增加包大小,因为需要为属性生成相关的信息。可以考虑使用文件级private let申明或static常量代替。
class Object { private let title = "12345"}private let title = "12345"class Object { static let title = ""}提示:这里并不包括通过init初始化注入的属性。
某些场景需要使用didSet/willSet属性检查器监控属性变化,做一些额外的计算。但是由于didSet/willSet并不会检查新/旧值是否相同,可以考虑添加新/旧值判断,只有当值真的改变时才进行运算提高性能。
class Object { var orderId: String? { didSet { // 拉取接口等操作 } }}例如上面的例子,当每一次orderId变更时需要重新拉取当前订单的数据,但是当orderId值一样时,拉取订单数据是无效执行。
class Object { var orderId: String? { didSet { // 判断新旧值是否相等 guard oldValue != orderId else { return } // 拉取接口等操作 } }}var nums = [1, 2, 3]var result = nums.lazy.map { String($0) }result[0] // 对1进行map操作result[1] // 对2进行map操作在集合操作时使用lazy,可以将数组运算操作推迟到第一次使用时,避免一次性全部计算。
提示:例如长列表,我们需要创建每个cell对应的视图模型,一次性创建太耗费时间。
var items = [1, 2, 3]items.filter({ $0 > 1 }).first // 查找出所有大于1的元素,之后找出第一个var items = [1, 2, 3]items.first(where: { $0 > 1 }) // 查找出第一个大于1的元素直接返回Swift中的值类型主要是结构体/枚举/元组。
提示:class即使没有继承NSObject也会生成ro_data_t,里面包含了ivars属性信息。如果属性/方法申明为@objc还会生成对应的方法列表。
提示:struct无法代替class的一些场景:1.需要使用继承调用super。2.需要使用引用类型。3.需要使用deinit。4.需要在运行时动态转换一个实例的类型。
提示:不是所有struct都会保存在栈上,部分数据大的struct也会保存在堆上。
集合元素使用值类型。因为NSArray并不支持值类型,编译器不需要处理可能需要桥接到NSArray的场景,可以移除部分消耗。
当class只包含静态方法/属性时,考虑使用enum代替class,因为class会生成更多的二进制代码。
class Object { static var num: Int static func test() {}}enum Object { static var num: Int static func test() {}}提示:为什么用enum而不是struct,因为struct会额外生成init方法。
值类型为了维持值语义,会在每次赋值/参数传递/修改时进行复制。虽然编译器本身会做一些优化,例如写时复制优化,在修改时减少复制频率,但是这仅针对于标准库提供的集合和String结构有效,对于自定义结构需要自己实现。对于参数传递编译器在一些场景会优化为直接传递引用的方式避免复制行为。
但是对于一些数据特别大的结构,同时需要频繁变更修改时也可以考虑使用引用类型实现。
虽然编译器本身会进行写时复制的优化,但是部分场景编译器无法处理。
func append_one(_ a: [Int]) -> [Int] { var a = a a.append(1) // 无法被编译器优化,因为这时候有2个引用持有数组 return a}var a = [1, 2, 3]a = append_one(a)直接使用inout传递参数
func append_one_in_place(a: inout [Int]) { a.append(1)}var a = [1, 2, 3]append_one_in_place(&a)默认情况下结构体中包含引用类型,在修改时只会重新拷贝引用。但是我们希望CustomData具备值类型的特性,所以当修改时需要重新复制NSMutableData避免复用。但是复制操作本身是耗时操作,我们希望可以减少一些不必要的复制。
struct CustomData { fileprivate var _data: NSMutableData var _dataForWriting: NSMutableData { mutating get { _data = _data.mutableCopy() as! NSMutableData return _data } } init(_ data: NSData) { self._data = data.mutableCopy() as! NSMutableData } mutating func append(_ other: MyData) { _dataForWriting.append(other._data as Data) }}var buffer = CustomData(NSData())for _ in 0..<5 { buffer.append(x) // 每一次调用都会复制}使用isKnownUniquelyReferenced检查如果是唯一引用不进行复制。
final class Box { var unbox: A init(_ value: A) { self.unbox = value }}struct CustomData { fileprivate var _data: Box var _dataForWriting: NSMutableData { mutating get { // 检查引用是否唯一 if !isKnownUniquelyReferenced(&_data) { _data = Box(_data.unbox.mutableCopy() as! NSMutableData) } return _data.unbox } } init(_ data: NSData) { self._data = Box(data.mutableCopy() as! NSMutableData) }}var buffer = CustomData(NSData())for _ in 0..<5 { buffer.append(x) // 只会在第一次调用时进行复制}提示:对于ObjC类型isKnownUniquelyReferenced会直接返回false。
尽可能避免在Swift中使用NSString/NSArray/NSDictionary等ObjC基础类型。以Dictionary为例,虽然Swift Runtime可以在NSArray和Array之间进行隐式桥接需要O(1)的时间。但是字典当Key和Value既不是类也不是@objc协议时,需要对每个值进行桥接,可能会导致消耗O(n)时间。
@objc标识虽然不会强制使用消息转发的方式来调用方法/属性,但是他会默认ObjC是可见的会生成和ObjC一样的ro_data_t结构。
使用@objcMembers修饰的类,默认会为类/属性/方法/扩展都加上@objc标识。
@objcMembers class Object: NSObject {}提示:你也可以使用@nonobjc取消支持ObjC。
你只需要在需要使用NSObject特性时才需要继承,例如需要实现UITableViewDataSource相关协议。
集合不需要修改时,使用let修饰,编译器会优化创建集合的性能。例如针对let集合,编译器在创建时可以分配更小的内存大小。
在Swift中,当捕获var变量时编译器需要生成一个在堆上的Box保存变量用于之后对于变量的读/写,同时需要额外的内存管理操作。如果是let变量,编译器可以保存值复制或引用,避免使用Box。
大型struct通常是指属性特别多并且嵌套类型很多。目前swift编译器针对struct等值类型编译优化处理的并不好,会生成大量的assignWithCopy、assignWithCopy等copy相关方法,生成大量的二进制代码。使用class类型可以避免生成相关的copy方法。
提示:不要小看这部分二进制的影响,个人在日常项目中遇到过复杂的大型struct能生成几百KB的二进制代码。但是目前并没有好的方法去发现这类struct去做优化,只能通过相关工具去查看生成的二进制详细信息。希望官方可以早点优化。
因为实现Encodable和Decodable协议的结构,编译器在编译时会自动生成对应的init(from decoder: Decoder)和encode(to: Encoder)方法。Codable同时实现了Encodable和Decodable协议,但是大部分场景下我们只需要encode或decode能力,所以明确指定实现Encodable或Decodable协议可以减少生成对应的方法减少包体积。
提示:对于属性比较多的类型结构会产生很大的二进制代码,有兴趣可以用相关的工具看看生成的二进制文件。
因为实现Equatable协议的结构,编译器在编译时会自动生成对应的equal方法。默认实现是针对所有字段进行比较会生成大量的代码。所以当我们不需要实现==比较能力时不要实现Equatable或者对于属性特别多的类型也可以考虑重写Equatable协议,只针对部分属性进行比较,这样可以生成更少的代码减少包体积。
提示:对于属性特别多的类型也可以考虑重写Equatable协议,只针对部分属性进行比较,同时也可以提升性能。
个人从Swift3.0开始将Swift作为第一语言使用。编写Swift代码并不只是简单对于ObjC代码的翻译/重写,需要对于Swift特性更多的理解才能更好的利用这些特性带来更多的收益。同时我们需要关注每个版本Swift的优化/改进和新特性。在这过程中也会提高我们的编码能力,加深对于一些通用编程概念/思想的理解,包括空安全、值类型、协程、不共享数据的Actor并发模型、函数式编程、面向协议编程、内存所有权等。对于新的现代编程语言例如Swift/Dart/TS/Kotlin/Rust等,很多特性/思想都是相互借鉴,当我们理解这些概念/思想以后对于理解其他语言也会更容易。
这里推荐有兴趣可以关注Swift Evolution,每个特性加入都会有一个提案,里面会详细介绍动机/使用场景/实现方式/未来方向。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号