探索无服务器数据库:数据库技术的新领域
发表时间: 2022-04-07 12:03

数据库的发展已走过近四十年,作为基础软件之一,数据库称得上是一个“古老”的领域。而随着新技术的涌现,这个传统的领域也正不断焕发出新的生机。如果说云时代的到来推动了数据库的变革,那么,与 Serverless 的结合,则再次为数据库的发展添了把火。Serverless 数据库会成为未来的趋势吗?又该如何让 Serverless 数据库从概念走向落地?亚马逊云科技 Tech Talk 特别邀请资深数据库专家马丽丽带来分享《 Serverless 数据库为应用开发带来的变革》。
从自建数据库到迁移上云,云数据库帮助企业和开发者省掉了很大一部分精力。开发者不再需要进行数据库的安装或备份工作,然而,数据库的选型难题却并未得到很好的解决。尽管云上数据库能够提供一些监控信息,但在多数场景下,工作负载是不均衡的,波峰和波谷往往差异极大,那么在这样的情况下该如何进行数据库选型呢?一般来说,有以下几个方式:
第一,为了避免数据库成为瓶颈,开发者可以按照波峰的方式进行部署。但工作负载不是始终都处于波峰,如果统一按照波峰位置部署数据库,就会带来资源浪费,提升成本。
第二,开发者可考虑按照波峰波谷的工作负载,配置一个平均值。这样成本的确有所节约,但问题是,一旦工作负载达到波峰,数据库将成为瓶颈,严重影响终端用户的体验。
第三,也是开发者现阶段最为常用的方式,即对不同指标进行监控,设置预警,比如设置当监测到 CPU 利用率到达 80% 的时候,系统发送告警信息,然后由开发或运维人员手动对数据库容量进行调整。尽管这样的方式的确可行,但却会耗费大量的时间成本。
从以上 3 种方式可以看出,在预算有限的情况下,依赖持续的监控和手动对数据库容量进行调整是非常困难的。是否有一种方式能够解决数据库这方面的痛点?Serverless 数据库正是这样一种切实有效的解决方案。
Serverless 数据库可按需求自动缩放配置,根据应用程序的需求自动扩展容量,并内置高可用和容错能力,采用 Serverless 数据库开发者将无需考虑选型问题,只需要关注如何设计数据库模式,怎样查询数据,及如何进行相应的优化即可。
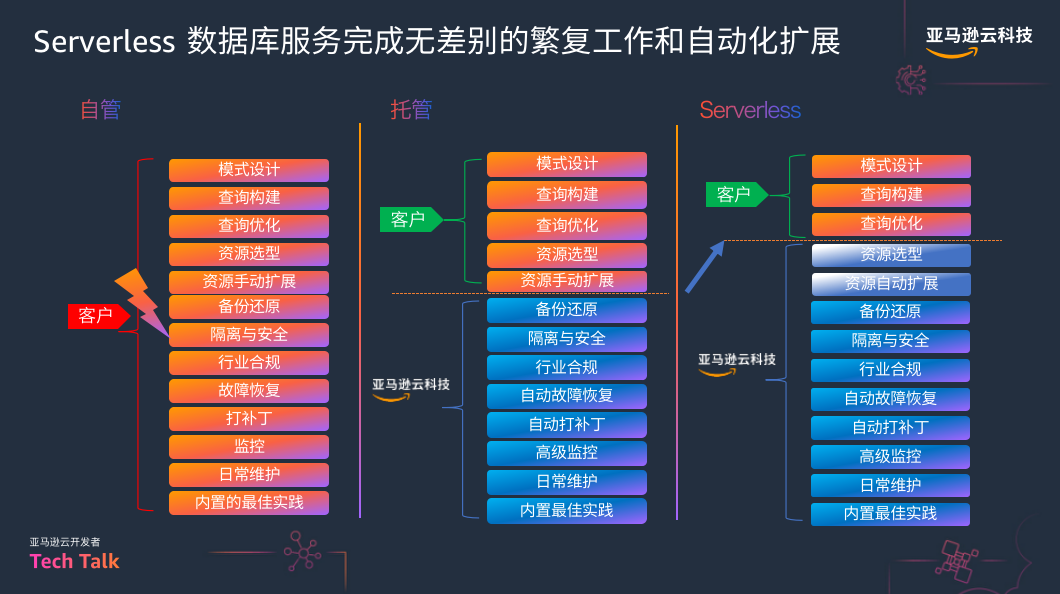
自动扩展容量,解决了开发者面临的数据库选型难的问题。那么,Serverless 数据库的出现,为应用开发又带来了哪些改变呢?马丽丽将 Serverless 数据库数据库的应用场景概括为以下四种。
最初在 SaaS 应用的数据库实现上,对于多租户的数据管理来说,每个租户的数据都是单独放在一个数据库里的,因此每个租户都会占用一个数据库,这样就会产生成千上万个数据库,成本高昂。
针对这一问题,当时的解决办法是将多个用户的数据库部署同一个 Aurora 集群来提高利用率和成本效率,这样一定程度上能够解决多租户 SaaS 应用研发的痛点,但会牺牲单个数据用户数据库操作的粒度。
而采用 Serverless 数据库,可辅助进行多租户的 SaaS 应用开发,把每个租户对应到一个 Serverless 数据库,随着应用的变化,可对每个租户数据库的容量进行自动收缩或扩展。
在企业内部,也常常会出现要运行很多应用程序的情况,少则几百,多则甚至达到几千个应用程序,每个应用程序由一个或多个数据库支持。逐步发展的应用程序要求需要调整数据库容量,在有限预算内的调整各个数据库非常困难。而通过 Serverless 数据库就可以自动根据应用程序对数据库的需求进行调整。
当数据放在单一的关系型数据库中容量受限时,往往需要进行分库分表操作。在进行分库分表时,分几份,如何分呢?需要写入可扩展性的应用程序将其数据库分散到多个节点以提高吞吐量,但预测每个节点的容量既困难又低效。创建的节点过少,必须在停机期间重新分配数据,创建的节点过多,成本较高,因为所有节点的利用率都不同。有了 Serverless 数据库,可以考虑相对灵活的设定容量,因为随着业务的变化,Serverless 数据库 可自动进行扩展和收缩,而不需要额外的运维。
在应用研发的过程中,越来越多的开发者接受了无服务器的理念,并尝试采用无服务器,所谓无服务器就是不需要管理服务器,从而实现自动缩放能力,并且按需付费、内置高可用、容错能力保证。当数据库也采用 Serverless,就可以实现端到端的 Serverless 架构,进一步提升用户体验。
Serverless 数据库在应用程序如何重新开发、维护,如多租户管理、分库分表、无服务器化等方面均起到不可替代的作用。那么该如何让 Serverless 数据库从抽象的概念走向具体的落地实践呢?
事实上,Serverless 数据库并非这两年才有的新概念。早在 2004 年的时候,由于亚马逊的电商网站面临数据库扩展性的挑战,Serverless 数据库的探索之旅便已经启程。
当时,亚马逊内部自研了名为 Dynamo 的分布式键值存储,以解决数据库扩展性方面的挑战。在进行一系列内部实践后,亚马逊于 2012 年正式对外推出可商用的 Amazon DynamoDB,DynamoDB 在发布之初就被定义为 Serverless 架构。而当初发表的论文《Dynamo: Amazon's Highly Available Key-value Store》也凭借着对 NoSQL 的启发与深远影响,在操作系统领域顶级学术会议 SOSP2017 上,获得了 Hall of Fame Award 终身成就奖。如今,DynamoDB 已发展整整十年,并在众多领域都有着非常广泛的应用。与此同时,在 NoSQL 领域,亚马逊云科技也不断在 Serverless 数据库方面进行着探索,形成了完善的 Serverless 数据库服务体系。
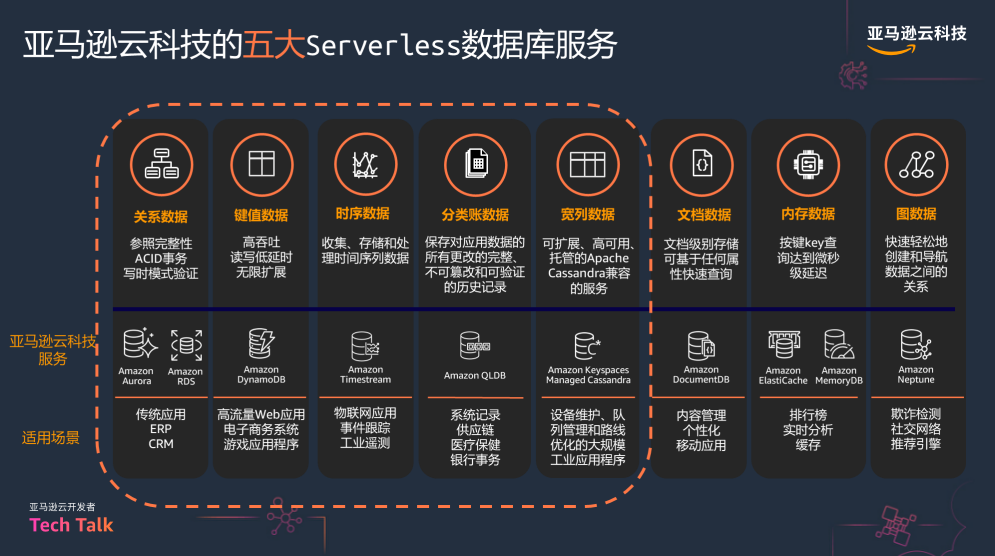
马丽丽着重对专为云平台打造的关系型数据库 Amazon Aurora 展开介绍。
首先,在性能方面,Amazon Aurora 跟开源引擎完全兼容,可获得 5 倍于标准 MySQL 以及 3 倍于标准 PostgreSQL 的吞吐量,并行查询加速联机分析处理 (OLAP);其次,在高可用方面,Amazon Aurora 能实现可用区 (AZ)+1 的高可用,Global Database 可以完成跨区容灾备份;第三,在扩展性方面,Amazon Aurora 支持 15 个只读副本自动扩展,Aurora Serverless,高达 128T 存储;第四,在成本方面,Amazon Aurora 提供商用级数据库性能的同时,成本仅为其 1/10,存储无需预置按用量付费。
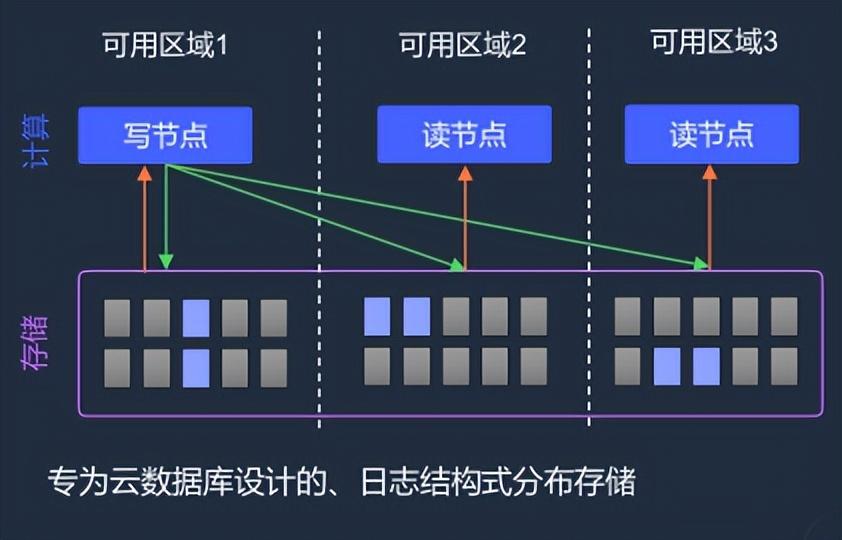
从架构上来看,Amazon Aurora 架构支持 Serverless。它采用计算与存储分离的架构,可以做到存储层的快速扩展,从而提升数据分析方面的能力。Amazon Aurora 还采用了独特的日志即数据库的理念,省去节点跟存储层数据传输的量,以达到性能的提升。
Amazon Aurora Serverless 目前为 V1 版本,马丽丽透露,V2 版本已支持预览版。相比于 V1 版本,V2 最显著的提升在于可立即扩容以支持高要求的应用程序。它能够一秒内实现 CPU 和内存资源的原地扩展,运行中的数十万项事务不会因为扩展受到影响。不仅如此,它还能持续监控和扩展计算节点。在保持状态的同时,对空闲实例后台移动 (例如,缓冲池、连接),缩放 scale down 速度是 V1 的 15 倍。
此外,V2 版本能够在容量调整时做到更细粒度,并能够依据多个维度进行容量调整。更值得一提的是 Amazon Aurora Serverless 支持跨 AZ 的高可用部署和读取扩展,通过持续的监控和尽可能大的利用缓冲池,V2 原地扩展可以做到秒级别。
在全球扩展方面,Aurora Serverless V2 支持全球数据库。全球数据库可以满足用户的两个需求:跨区域的故障恢复和增强应用程序的就近访问。如果在从区域部署 Aurora serverless V2 用来支持跨区域灾难恢复,它在空闲时会占用较低的资源,一旦发生故障恢复从区域提升为主区域时,Serverless 数据库能够快速扩容来支撑应用访问,这样能够带来空闲时数据库成本的节约。如果在从区域部署 Aurora serverless V2 用来支持本区域应用程序的就近访问,它可以根据本地应用程序的访问负载进行独立于主区域的自动扩展,进而提供更多的灵活性。随着国内越来越多企业出海诉求的涌现,Amazon Aurora Serverless V2 将在很大程度上满足业界对于全球数据库的需求。
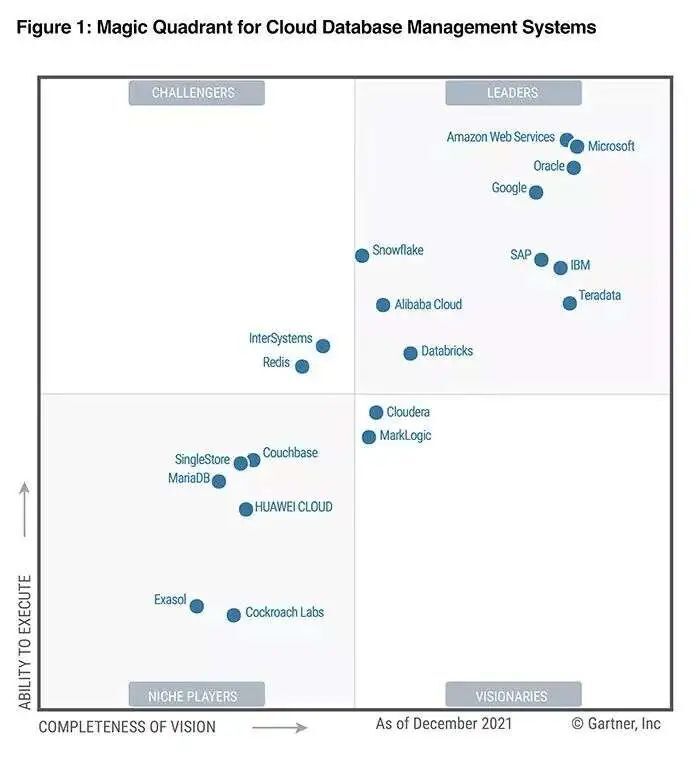
去年 12 月,权威咨询机构 Gartner 发布了报告——2021 Gartner Magic Quadrant for Cloud Database Management System。亚马逊云科技连续七年被评为云数据库领导者,在“执行能力”上获得 20 家参评厂商的最高位置。
就像云技术的引入催生了一代创新一样,亚马逊云科技相信下一波创新浪潮是由数据驱动的。对于数据库,马丽丽在分享的最后谈到:“无服务器化架构是数据库未来发展的必然趋势之一。”
了解更多软件开发与相关领域知识,点击访问 InfoQ 官网:https://www.infoq.cn/,获取更多精彩内容!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号