维基百科:ChatGPT,是与否?
发表时间: 2023-05-15 14:11
维基百科胜在知识结构清晰,ChatGPT 长于具体问题,双方未必不可调和。
22 年前,2001 年初,维基百科 Wikipedia 横空出世,在其后的互联网时代,成为人们获取知识的重要平台。
但在刚开始,人们对维基「人人可编辑」的组织形式产生过质疑。甚至有电视主持人讽刺其为「wikiality」,即如果在维基百科上编造条目,只要有足够多的人同意,它就会成为现实。
后来,随着《自然》(Nature)杂志的调查研究,发现维基百科准确度接近大英百科全书,Google 开始把维基百科放到搜索结果的首项,维基社区和内容贡献者也持续壮大,维基百科用了很多年时间终于取得了公众的信任。
诞生之初遭到质疑,越来越多人参与去完善,而后平反收到大众认可,继而成为日常的工具,这一过程,仅诞生半年的 ChatGPT 正在经历,不仅于此,它还成为了维基百科的挑战者。
不久前,维基媒体基金会召开 2023-2024 年度计划的电话会议,会议中提及了 35 次 AI,讨论的主题也是围绕 ChatGPT 带来的挑战。
但维基百科所担心的挑战,并不是被 ChatGPT 取代。而是更深刻地考验:未来的维基百科,会由 ChatGPT 来撰写吗?
要想知道 ChatGPT 能否撰写维基百科,得先知道维基百科目前内容来源于哪里。
维基百科主要是由来自互联网上的志愿者共同合作编写而成,任何使用网络进入维基百科的用户都可以编写和修改里面的文章。它是互联网上一个极大的自由内容、公开编辑、多语言的网络百科全书协作计划。
截至 2021 年初,所有语种的维基百科条目数量达 5500 万条,如何确保内容上的准确,全靠维基社群志愿者们的筛查。
在 ChatGPT 出现前,维基百科已经长期在用 AI 去减少一些人力成本。应用最多的就是把现有条目直接机器翻译,再由人工编辑校对。
2016 年时,资深科学家 Aaron Halfaker 开发了一套开源机器学习算法,可以自动识别维基百科里那些恶意破坏条目和编辑假消息的行为;2020 年,MIT 的研究人员也为维基百科推出过基于 AI 的修改功能,可以精确定位维基百科句子中的特定信息,并自动替换为类似于人类编辑的语言。
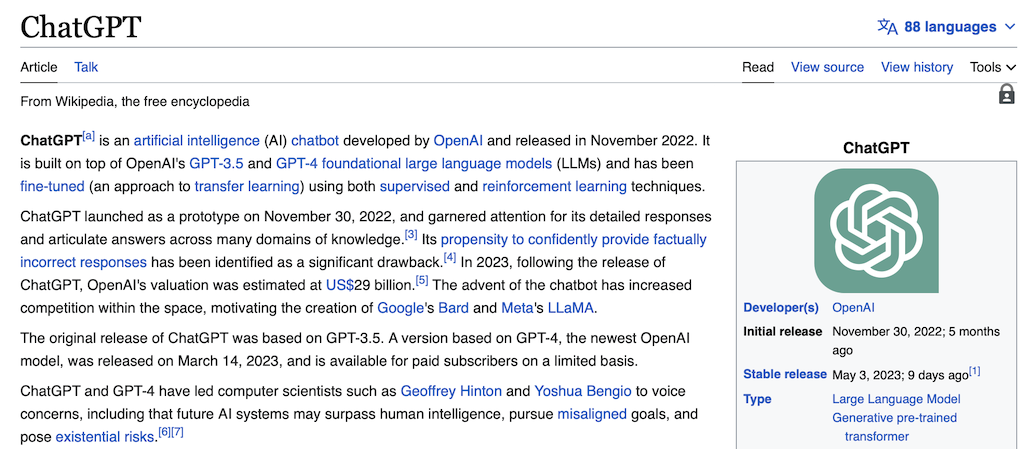
Wikipedia 关于 ChatGPT 的页面|Wikipedia
以及如维基社群所述,人工智能非常擅长总结把一篇很长的技术类条目,总结成儿童都能理解的版本,让 AI 去生成儿童版的维基百科效果很好。
翻译、检查、概括简化已有内容,维基百科一直以来对 AI 的应用仅限于此,直到大型语言模型 ChatGPT 的出现。
目前仍以文字方式交互为主的 ChatGPT,除了回答用户直接的提问以外,还可以用于甚为复杂的语言工作,包括自动生成文本、自动问答、自动摘要等等。
ChatGPT 可以写出相似真人的文章,并在许多知识领域给出详细和清晰的回答。哪怕 ChatGPT 生成内容的事实准确度还需要人工去二次查阅,但这时维基百科面临的问题已经很明显了:志愿者能否用 ChatGPT 来撰写维基百科条目?
纽约市维基媒体分会的老维基人 Richard Knipel 就用 ChatGPT 在维基百科上起草了一个名为「艺术作品标题」的新条目,Knipel 表示,ChatGPT 给出的版本一般但语法正确,定义了艺术作品标题的概念,给出了从古至今的例子。他在草稿基础上只做了轻微修改。
但另一位编辑在条目上标注,将会进行大量修改并完善。如今,我们再点进这一条目,会发现它增加了大量内容和理论索引,还梳理出了目录,给出了图片案例。像 Knipel 这样的维基人认为,ChatGPT 可以作为生成维基百科条目草稿、骨架的工具,在此基础上,人工再验证内容,编辑和充实条目。
但另一派维基人则认为,在维基百科条目的创作里 ChatGPT 应该完全被禁用。一位维基百科编辑就表示「我们应该强烈呼吁不使用 AI 工具来生成条目草稿,即使这些条目随后会被人工审阅。ChatGPT 太擅长引入那些看起来很有道理的谎言。」
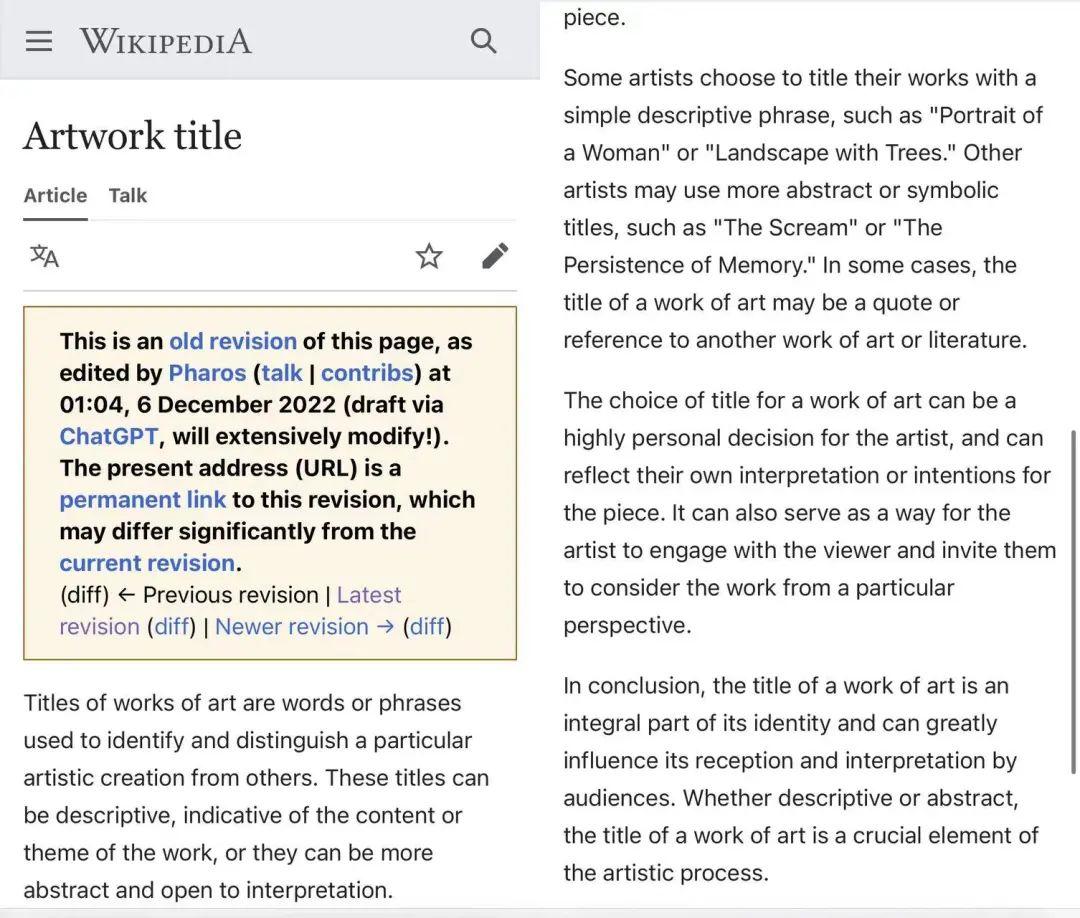
ChatGPT 起草,人工简单编辑的版本|Wikipedia
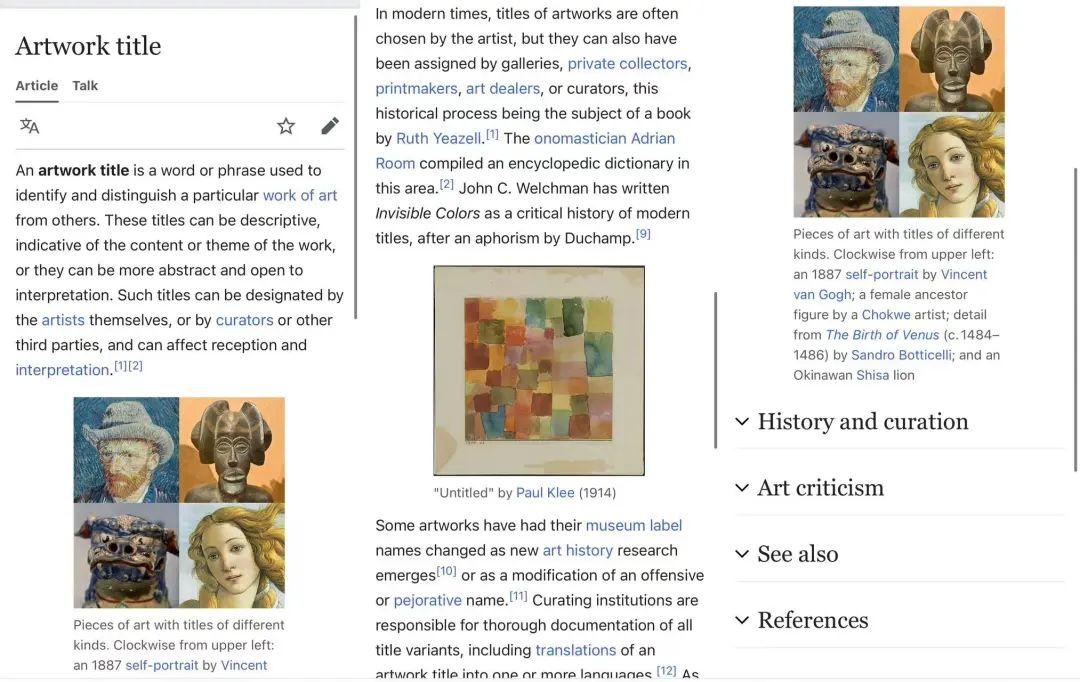
人工大量干预后产生的版本|Wikipedia
但另一派也反驳这种说法,就像 Knipel 认为,修改并丰富不完善的信息,这就是维基百科在实践中一直运作的方式。ChatGPT 将继续存在并飞速发展,利用它同时强调人工干预的必要性怎么就不行呢?把 ChatGPT 上来就视作洪水猛兽实在有些偏颇。
但在想不想之前,我们先看看能不能。ChatGPT 还够不够格直接编写维基百科呢?
3 月 30 日时,维基百科创始人 Jimmy Wales 在接受 Evening Standard 采访时讨论了这个议题。Wales 认为,让 ChatGPT 能独立写一个完整的维基条目,目前还有一段距离,但距离多远就难说了。「ChatGPT 的一大问题是会胡编乱造,业内把这种情况称为 hallucinating(幻觉)——我称之为编瞎话。」(One of the issues with the existing ChatGPT is what they call in the field 『hallucinating』—I call it lying.)
「ChatGPT 有一种凭空捏造的倾向,这对维基百科来说真的不太行。」Wales 在采访里说道。实践中也是如此,你在维基百科上搜一个词,维基百科可能会反馈「该条目不存在」,但你问 ChatGPT,它可能会给你生成一段没由头的假消息。
ChatGPT 会「说瞎话」,这种事已经不新鲜了。但 ChatGPT 诞生仅半年,它的自我迭代能力已经令人咋舌,让 ChatGPT「句句吐真言」,似乎只是时间问题,那维基百科现在担忧的是什么呢?
维基百科团队并没有那么担心内容到底来源于人类还是 AI,它担心的是内容质量是否过关。
在维基媒体基金会在电话会议总结报告里,「挑战」被放到了开篇,其中最大比重的部分,也是维基百科团队最大的担忧在于:维基百科涌入大量 AI 生成的内容,把真正高质量的、正确的信息给淹没了。
「Wiki 项目有大量高质量的、可靠的,结构化的、分类好的内容。这就是我们带给世界的价值。最让我害怕的不是人们使用 GPT 之类的大语言模型来获取知识,而是需要巡查的 AI 生成的内容会爆炸式增长。」
对高质量内容来说,创作比消费的时间成本高很多,就像一篇较为完整的维基条目,需要许多人参与撰写,花许多时间,走过很多流程后完成,对读者来说几分钟就阅读完了。
像维基百科这种平台,为了保证内容质量,还需要专业人士核查一条条目中每个信息、数据、引用是否来源准确,筛查和编辑的成本同样很高。因此 AI 生成内容越多,人工核查的时间也更长。而且哪怕 ChatGPT 给出了正确的结论,但它并不会直接给出结论的论据来源何处,人工还需要再找到论据。到最后,修正可能比撰写耗时更长。

Wikipedia 的条目下会有很多延展阅读链接|Wikipedia
目前维基百科志愿者们已经发现了许多 ChatGPT 自动生成内容上的问题。比如 ChatGPT 很容易太笼统地概括定义,导致表意不明。还有 ChatGPT 遣词造句过于肯定,不够匹配维基百科想呈现的客观中性的文字风格。
最重要的是信源难以查询,维基百科的可信度和扩展阅读性,很大程度上是基于条目底下丰富的信息参考来源,但 ChatGPT 不会主动提供参考,甚至会凭空捏造。
担任了 20 年维基百科志愿编辑的 Andrew Lih 在用 ChatGPT 起草新条目时就发现,ChatGPT 概述定义做得很不错,但它所提供的消息来源于《福布斯》、《卫报》、《今日心理学》,但 Lih 仔细查阅后发现,这些信源文章并不存在,甚至 ChatGPT 给出的 URL 都是自动生成找不到页面的假链接。
综上,维基百科团队直接表示,AI 生成内容的速度和效率,可能会超出项目的运行能力。
除此之外,还有许多维基百科团队会担心的点,比如如今的维基百科贡献者里,使用英语的白人男性依旧是主体,维基内容已带有语言和内容偏见,ChatGPT 靠吸纳互联网信息为养料的 AI 机器,生成出的内容会进一步放大偏见。

Wikipedia 联合创始人 Jimmy Wales 在接受 Standard 采访时谈及 AI 参与撰写维基的问题|Standard.co
维基百科团队也无法把握志愿者对 AI 工具使用的倾向。Lih 就认为,维基人不缺动力,缺的是时间,ChatGPT 生成的糟糕草稿,可以激发维基志愿者的修改欲。这也符合维基之父 Ward Cunningham 所提出的「坎宁安定律」:在互联网上得到优秀答案的最佳方法不是去提问,而是发布一个错误的答案。
维基百科团队还担心,当维基百科充斥着 AI 生成的内容时,用户们会降低对它信息的信任度,转而去信任更有「人类作者」标识的媒体内容,比如会出镜的视频,标记了作者的媒体报刊。
维基百科和 ChatGPT 有很多相似性,比如都以文本为主,试图「回答一切」。但二者最显著的区别,在于回答方式的不同。
维基百科是有框架、系统、详细索引的百科式信息,你点进一个条目,可以从最简单的概括式介绍了解到其历史的变化,通过条目里丰富的扩展链接,可以在纵向里深入了解,也能在横向里在不同条目之间跳转,扩展对一整个领域的了解。
ChatGPT 目前呈现出的还是提问式的交互,需要用户明确了解自己想知道的问题,向外扩展也是需要建立在 ChatGPT 给出的回答之上,进一步询问。
不同用户获取信息的倾向不同,选择工具也不同,维基百科无法做到 ChatGPT 一样能回答非常具体的问题,ChatGPT 也不会像维基百科一样有那么精准且梳理好的知识类信息。这二者的使用方式,就像我们选择阅读教科书,还是直接向教授提问。
就像维基百科并没有因为搜索引擎 Google 的崛起而磨灭,反而它会出现在 Google 搜索结果的第一条和边栏上。
维基百科团队也并没有如 Google 一般有那么大的危机感,在年度会议里,虽然开篇点了 ChatGPT 带来的挑战,但整个会议更多的时间留给了「机会」。

「当互联网上有大量 AI 生成的内容时会发生什么?在一个由数万亿个低质量、低可信度的页面组成的互联网,创建大模型的人和用户都需要去找到可靠的信息,他们可能会更多地使用维基百科。」这就是维基人眼中的「机会」。
利用大语言模型去查 bug、翻译、内容总结、丰富媒体形式,比如 GPT-4 中体现的视频生成,AI 生成的图片也可以放到很多抽象概念的条目里,增加可读性,还可以在文本和语音之间互相转换。
但以上的前提,都是不能让大语言模型打打辅助,不能喧宾夺主。「维基百科是关于人类聚集在一起试图定义真相。这些工具不可靠,会分散我们对实际任务的注意力。我们应该小心要以多快的速度追赶这一趋势,而不是放弃它。我们应该关注创造知识的人。」
维基百科团队的态度,也折射了我们当下对 AI 的审慎态度。没有被取代,想充分利用 AI 的同时不够信任它,想发挥 AI 的最大价值,但真正有价值的内容又不敢轻易交付,难以放下人类本位的核心概念,谨慎地靠近,小心地追赶。
维基百科如何和大语言模型共存,或许就回答了我们人类如何与 AI 共存。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号