音视频编码技术:探索视频压缩与音频编码的奥秘
发表时间: 2022-11-08 16:25
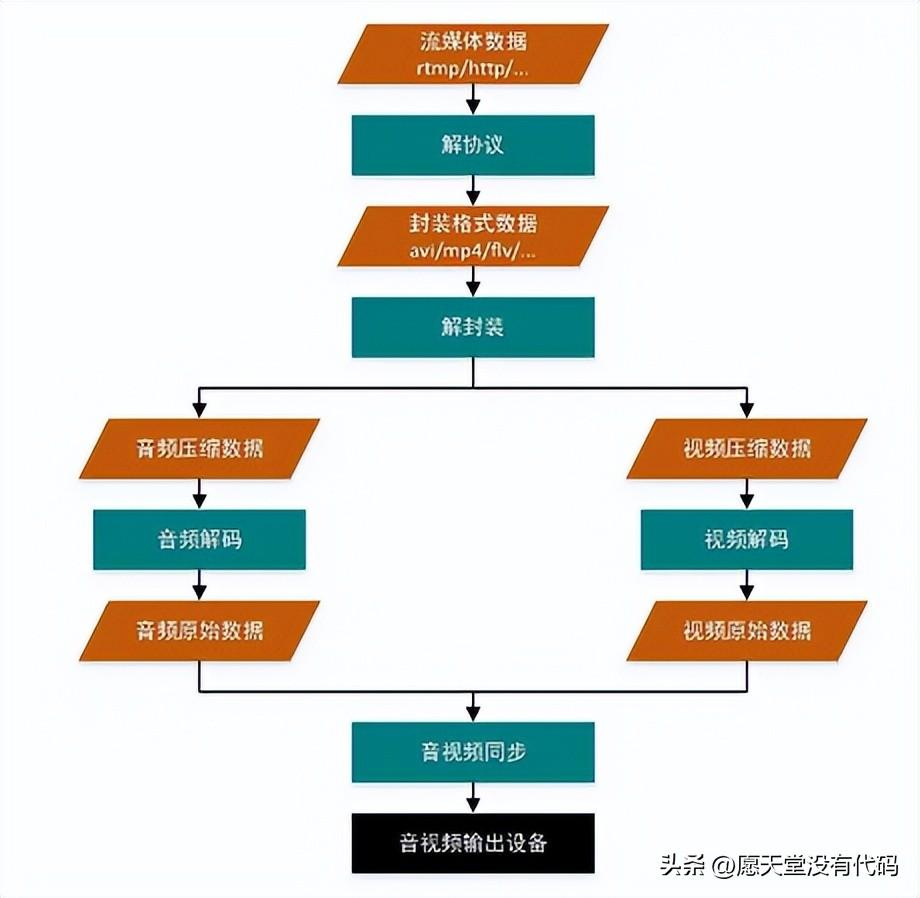
音视频技术主要包含以下几点:封装技术,视频压缩编码技术和音频编码压缩技术。
如果解码本地视频,则不需要解协议:解封装->解码音视频->音视频同步
将流媒体协议的数据解析为标准的响应的封装格式的数据,音视频在网络上传输时常常采用各种流媒体协议
解协议的过程就是去掉这些信令指令,只保留音视频数据
将输入的封装格式的数据,分离成音频流压缩的数据和视频流压缩的数据,封装格式种类很多
将解封装过程得到的参数信息和同步解码得到的音视频数据,推送到系统的显卡和声卡显示出来
编码算法具有高计算量和受实现平台的影响等特点,所以技术一直在不断地完善,主流是 MPEG-4 和 H.264。而且市场需求量也是很大的,但出现一个问题:就是每个领域都有几家特别牛逼的几家公司在哪里,人家大而不倒,你想跻身进入 500 强,没有强悍的身板(高质量的技术),你怕站不住啊!

H.264 算法还是基于块的混合编码技术,编码过程基本与以前的编码标准相同,只是每个功能模块都进行了技术更新,帧内预测、帧间预测、整数 DCT 变换、环路滤波、熵编码等模块都做了技术提升。
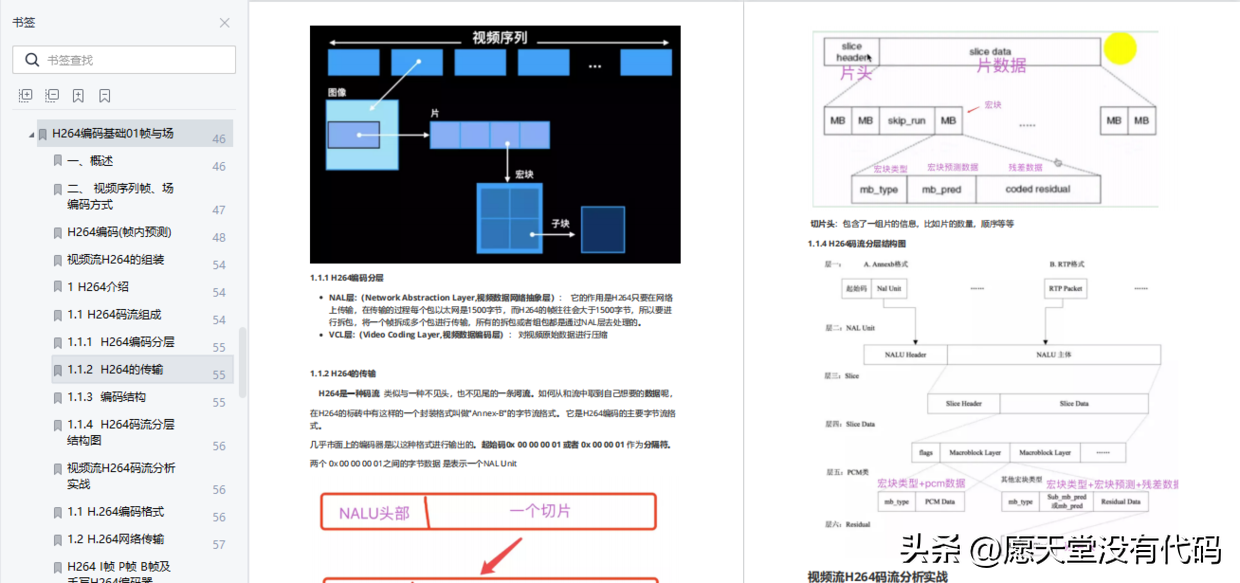
网络适配层 NAL(Network Abstraction Layer)是 H.264 为适应网络传输应用而制定的一层数据打包操作。传统的视频编码算法编完的视频码流在任何应用领域下(无论用于存储、传输等)都是统一的码流模式,视频码流仅有视频编码层 VCL(Video Coding Layer)。而 H.264 可根据不同应用增加不同的 NAL 片头,以适应不同的网络应用环境,减少码流的传输差错。
H.264 为能进一步利用图像的空间相关性,H.264 引入了多模式的帧内预测以提高压缩效率。简单地说,帧内预测编码就是用周围邻近的像素值来预测当前的像素值,然后对预测误差进行编码。预测是基于块的,亮度分量(Luma)块的大小可以在16×16和4×4之间选择,16×16块有4种预测模式,4×4块有9种预测模式;色度分量 (Chroma)预测是对整个8×8块进行的,预测模式同亮度16×16的4种预测模式。
帧间预测即传统的运动估计 ME 加运动补偿 MC,H.264 的运动估计更精准、快速,效果更好
首先解析码流的头数据,获取编码图像的有关参数:包括帧编码类型(I/P)、图像宽度或高度等,后续就是以宏块为单位循环解码,以宏块为处理单元循环执行。熵解码是可变长编码 VLC 的逆操作,即 VLD。H.263/MPEG-1/2/4 是 Huffman 熵解码,即通常意义上的 VLD,而 H.264 则是采用了算术解码,又包括 CAVLD、CABAD
另外
解码器中的最后处理是可选的去除块效应(MPEG-4)、环路滤波(H.264)、图像扩展等。
上面的技术点如果要学习的话的太多了,不方便展示。如果想转入音视频开发各位可以参考电子手册《音视频开发入门到精通》,私信发送 "音视频进阶" 即可 免费获取,电子手册里面记载了音视频开发从入门语言到最后的实战讲解。而且因为音视频开发门槛很高,技术知识范围广,所以必然需要系统性的学习才能快速掌握

资料整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下~
你的支持,就是我的动力;祝各位前程似锦
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号