Redis简介:三次讲解让你明白Redis是什么
发表时间: 2021-04-08 14:10
此账号为华为云开发者社区官方运营账号,提供全面深入的云计算前景分析、丰富的技术干货、程序样例,分享华为云前沿资讯动态
本文分享自华为云社区《《三次给你聊清楚Redis》之Redis是个啥》,原文作者:兔老大。
Redis是一款基于键值对的NoSQL数据库,它的值支持多种数据结构:字符串(strings)、哈希(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)等。
• Redis将所有的数据都存放在内存中,所以它的读写性能十分惊人,用作数据库,缓存和消息代理。
• Redis具有内置的复制,Lua脚本,LRU逐出,事务和不同级别的磁盘持久性,并通过Redis Sentinel和Redis Cluster自动分区提供了高可用性。
• Redis典型的应用场景包括:缓存、排行榜、计数器、社交网络、消息队列等
1)单机Mysql的美好时代
瓶颈:
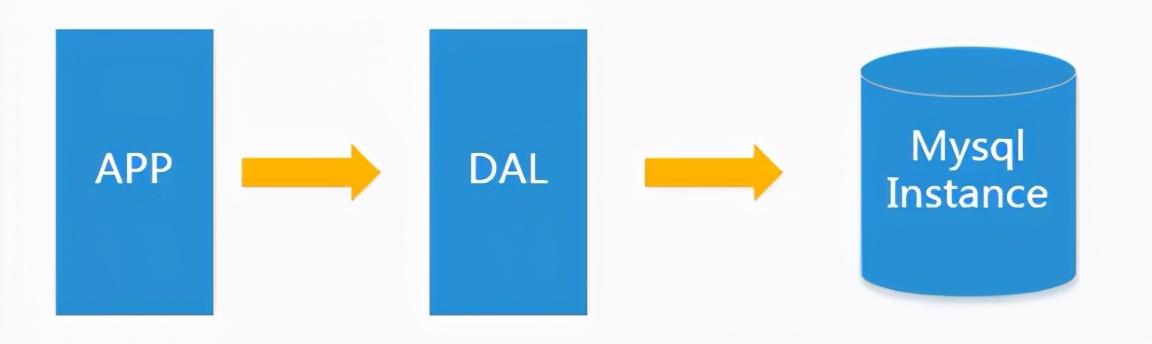
2)Memcached(缓存)+ MySql + 垂直拆分
通过缓存来缓解数据库的压力,优化数据库的结构和索引。
垂直拆分指的是:分成多个数据库存储数据(如:卖家库与买家库)。
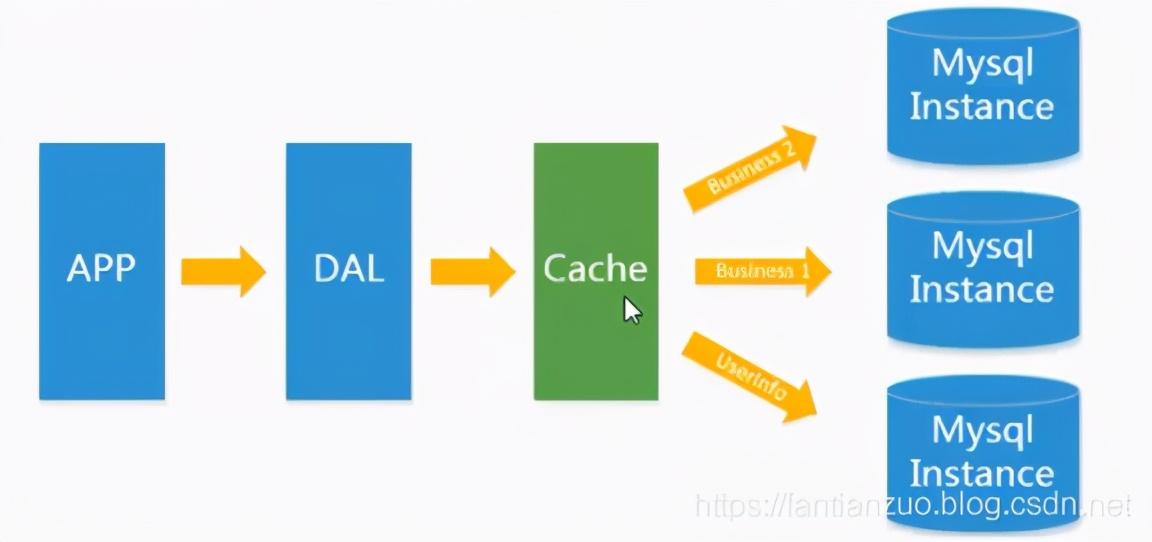
3)MySql主从复制读写分离
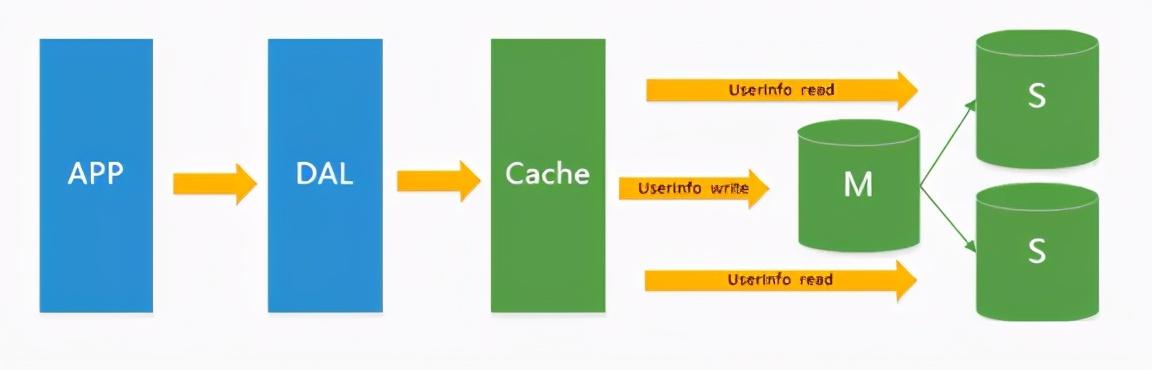
4)分表分库+水平拆分+MySql集群
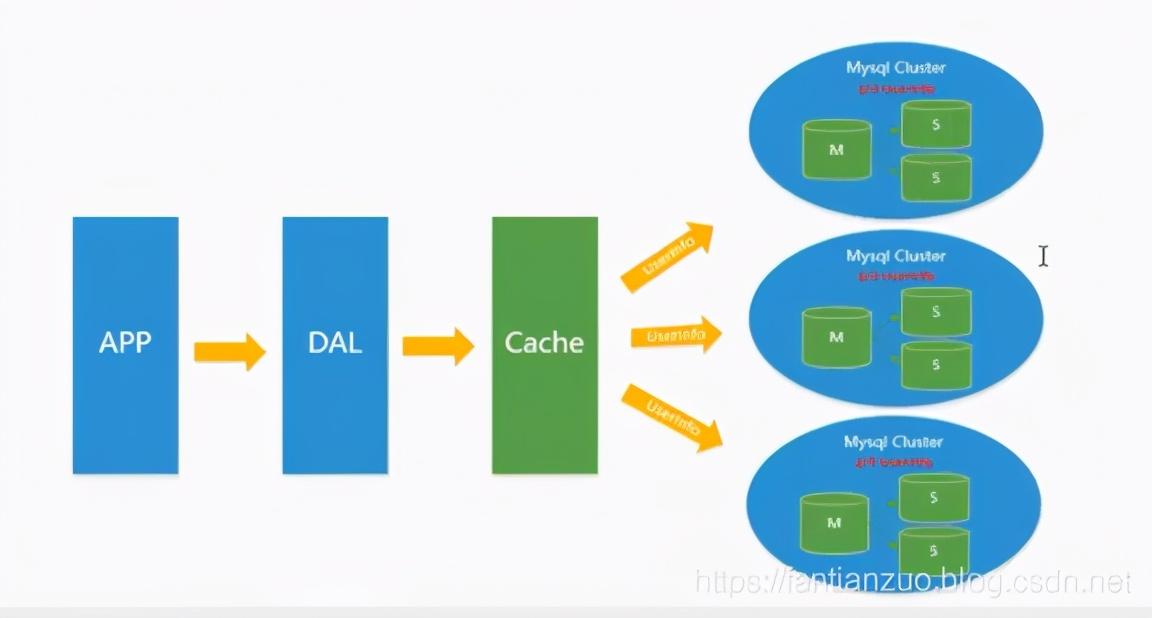
MySql扩展的瓶颈
常用的Nosql
Redis
memcache
Mongdb
以上几种Nosql 请到各自的官网上下载并参考使用
Nosql 的核心功能点
KV(存储)
Cache(缓存)
Persistence(持久化)
……
问题:
传统数据库:持久化存储数据。
solr索引库:大量的数据的检索。
在实际开发中,高并发环境下,不同的用户会需要相同的数据。因为每次请求,
在后台我们都会创建一个线程来处理,这样造成,同样的数据从数据库中查询了N次。
而数据库的查询本身是IO操作,效率低,频率高也不好。
总而言之,一个网站总归是有大量的数据是用户共享的,但是如果每个用户都去数据库查询,效率就太低了。
解决:
将用户共享数据缓存到服务器的内存中。
特点:
1、基于键值对
2、非关系型(redis)
关系型数据库:存储了数据以及数据之间的关系,oracle,mysql
非关系型数据库:存储了数据,redis,mdb.
3、数据存储在内存中,服务器关闭后,持久化到硬盘中
4、支持主从同步
实现了缓存数据和项目的解耦。
redis存储的数据特点:
大量数据
用户共享数据
数据不经常修改。
查询数据
redis的应用场景:
网站高并发的主页数据
网站数据的排名
消息订阅
redis官网
微软写的windows下的redis
我们下载第一个,然后基本一路默认就行了。
安装后,服务自动启动,以后也不用自动启动。
出现这个表示我们连接上了。
数据结构
struct sdshdr{ //记录buf数组中已使用字节的数量 int len; //记录buf数组中未使用的数量 int free; //字节数组,用于保存字符串 char buf[];}常见操作
127.0.0.1:6379> set hello worldOK127.0.0.1:6379> get hello"world"127.0.0.1:6379> del hello(integer) 1127.0.0.1:6379> get hello(nil)127.0.0.1:6379>应用场景
String是最常用的一种数据类型,普通的key/value存储都可以归为此类,value其实不仅是String,也可以是数字:比如想知道什么时候封锁一个IP地址(访问超过几次)。INCRBY命令让这些变得很容易,通过原子递增保持计数。
数据结构
typedef struct listNode{ //前置节点 struct listNode *prev; //后置节点 struct listNode *next; //节点的值 struct value;}常见操作
> lpush list-key item(integer) 1> lpush list-key item2(integer) 2> rpush list-key item3(integer) 3> rpush list-key item(integer) 4> lrange list-key 0 -11) "item2"2) "item"3) "item3"4) "item"> lindex list-key 2"item3"> lpop list-key"item2"> lrange list-key 0 -11) "item"2) "item3"3) "item"应用场景
Redis list的应用场景非常多,也是Redis最重要的数据结构之一。我们可以轻松地实现最新消息排行等功能。Lists的另一个应用就是消息队列,可以利用Lists的PUSH操作,将任务存在Lists中,然后工作线程再用POP操作将任务取出进行执行。
数据结构
dictht是一个散列表结构,使用拉链法保存哈希冲突的dictEntry。
typedef struct dictht{ //哈希表数组 dictEntry **table; //哈希表大小 unsigned long size; //哈希表大小掩码,用于计算索引值 unsigned long sizemask; //该哈希表已有节点的数量 unsigned long used;}typedef struct dictEntry{ //键 void *key; //值 union{ void *val; uint64_tu64; int64_ts64; } struct dictEntry *next;}Redis的字典dict中包含两个哈希表dictht,这是为了方便进行rehash操作。在扩容时,将其中一个dictht上的键值对rehash到另一个dictht上面,完成之后释放空间并交换两个dictht的角色。
typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */} dict;rehash操作并不是一次性完成、而是采用渐进式方式,目的是为了避免一次性执行过多的rehash操作给服务器带来负担。
渐进式rehash通过记录dict的rehashidx完成,它从0开始,然后没执行一次rehash例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],这一次会把 dict[0] 上 table[rehashidx] 的键值对 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。
采用渐进式rehash会导致字典中的数据分散在两个dictht中,因此对字典的操作也会在两个哈希表上进行。例如查找时,先从ht[0]查找,没有再查找ht[1],添加时直接添加到ht[1]中。
常见操作
> hset hash-key sub-key1 value1(integer) 1> hset hash-key sub-key2 value2(integer) 1> hset hash-key sub-key1 value1(integer) 0> hgetall hash-key1) "sub-key1"2) "value1"3) "sub-key2"4) "value2"> hdel hash-key sub-key2(integer) 1> hdel hash-key sub-key2(integer) 0> hget hash-key sub-key1"value1"> hgetall hash-key1) "sub-key1"2) "value1"常见操作
> sadd set-key item(integer) 1> sadd set-key item2(integer) 1> sadd set-key item3(integer) 1> sadd set-key item(integer) 0> smembers set-key1) "item2"2) "item"3) "item3"> sismember set-key item4(integer) 0> sismember set-key item(integer) 1> srem set-key item(integer) 1> srem set-key item(integer) 0> smembers set-key1) "item2"2) "item3"应用场景
Redis为集合提供了求交集、并集、差集等操作,故可以用来求共同好友等操作。
数据结构
typedef struct zskiplistNode{ //后退指针 struct zskiplistNode *backward; //分值 double score; //成员对象 robj *obj; //层 struct zskiplistLever{ //前进指针 struct zskiplistNode *forward; //跨度 unsigned int span; }lever[]; } typedef struct zskiplist{ //表头节点跟表尾结点 struct zskiplistNode *header, *tail; //表中节点的数量 unsigned long length; //表中层数最大的节点的层数 int lever; }跳跃表,基于多指针有序链实现,可以看作多个有序链表。
与红黑树等平衡树相比,跳跃表具有以下优点:
常见操作
> zadd zset-key 728 member1(integer) 1> zadd zset-key 982 member0(integer) 1> zadd zset-key 982 member0(integer) 0> zrange zset-key 0 -11) "member1"2) "member0"> zrange zset-key 0 -1 withscores1) "member1"2) "728"3) "member0"4) "982"> zrangebyscore zset-key 0 800 withscores1) "member1"2) "728"> zrem zset-key member1(integer) 1> zrem zset-key member1(integer) 0> zrange zset-key 0 -1 withscores1) "member0"2) "982"应用场景
以某个条件为权重,比如按顶的次数排序。ZREVRANGE命令可以用来按照得分来获取前100名的用户,ZRANK可以用来获取用户排名,非常直接而且操作容易。
Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。
引入依赖
- spring-boot-starter-data-redis
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>配置Redis
- 配置数据库参数
# RedisPropertiesspring.redis.database=11#第11个库,这个随便spring.redis.host=localhostspring.redis.port=6379#端口- 编写配置类,构造RedisTemplate
这个springboot已经帮我们配了,但是默认object,我想改成string
import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.redis.connection.RedisConnectionFactory;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.serializer.RedisSerializer;@Configurationpublic class RedisConfig { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(factory); // 设置key的序列化方式 template.setKeySerializer(RedisSerializer.string()); // 设置value的序列化方式 template.setValueSerializer(RedisSerializer.json()); // 设置hash的key的序列化方式 template.setHashKeySerializer(RedisSerializer.string()); // 设置hash的value的序列化方式 template.setHashValueSerializer(RedisSerializer.json()); template.afterPropertiesSet(); return template; }}访问Redis
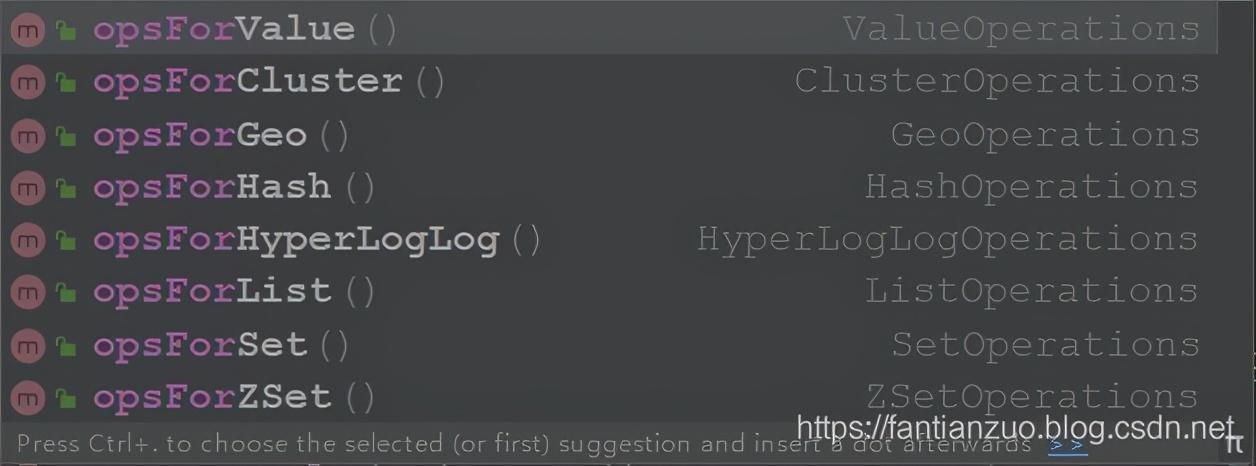
- redisTemplate.opsForValue()
- redisTemplate.opsForHash()
- redisTemplate.opsForList()
- redisTemplate.opsForSet()
- redisTemplate.opsForZSet()
@RunWith(SpringRunner.class)@SpringBootTest@ContextConfiguration(classes = CommunityApplication.class)public class RedisTests { @Autowired private RedisTemplate redisTemplate; @Test public void testStrings() { String redisKey = "test:count"; redisTemplate.opsForValue().set(redisKey, 1); System.out.println(redisTemplate.opsForValue().get(redisKey)); System.out.println(redisTemplate.opsForValue().increment(redisKey)); System.out.println(redisTemplate.opsForValue().decrement(redisKey)); } @Test public void testHashes() { String redisKey = "test:user"; redisTemplate.opsForHash().put(redisKey, "id", 1); redisTemplate.opsForHash().put(redisKey, "username", "zhangsan"); System.out.println(redisTemplate.opsForHash().get(redisKey, "id")); System.out.println(redisTemplate.opsForHash().get(redisKey, "username")); } @Test public void testLists() { String redisKey = "test:ids"; redisTemplate.opsForList().leftPush(redisKey, 101); redisTemplate.opsForList().leftPush(redisKey, 102); redisTemplate.opsForList().leftPush(redisKey, 103); System.out.println(redisTemplate.opsForList().size(redisKey)); System.out.println(redisTemplate.opsForList().index(redisKey, 0)); System.out.println(redisTemplate.opsForList().range(redisKey, 0, 2)); System.out.println(redisTemplate.opsForList().leftPop(redisKey)); System.out.println(redisTemplate.opsForList().leftPop(redisKey)); System.out.println(redisTemplate.opsForList().leftPop(redisKey)); } @Test public void testSets() { String redisKey = "test:teachers"; redisTemplate.opsForSet().add(redisKey, "刘备", "关羽", "张飞", "赵云", "诸葛亮"); System.out.println(redisTemplate.opsForSet().size(redisKey)); System.out.println(redisTemplate.opsForSet().pop(redisKey)); System.out.println(redisTemplate.opsForSet().members(redisKey)); } @Test public void testSortedSets() { String redisKey = "test:students"; redisTemplate.opsForZSet().add(redisKey, "唐僧", 80); redisTemplate.opsForZSet().add(redisKey, "悟空", 90); redisTemplate.opsForZSet().add(redisKey, "八戒", 50); redisTemplate.opsForZSet().add(redisKey, "沙僧", 70); redisTemplate.opsForZSet().add(redisKey, "白龙马", 60); System.out.println(redisTemplate.opsForZSet().zCard(redisKey)); System.out.println(redisTemplate.opsForZSet().score(redisKey, "八戒")); System.out.println(redisTemplate.opsForZSet().reverseRank(redisKey, "八戒")); System.out.println(redisTemplate.opsForZSet().reverseRange(redisKey, 0, 2)); } @Test public void testKeys() { redisTemplate.delete("test:user"); System.out.println(redisTemplate.hasKey("test:user")); redisTemplate.expire("test:students", 10, TimeUnit.SECONDS); }}这样还是稍微有点麻烦,我们其实可以绑定key
// 多次访问同一个key @Test public void testBoundOperations() { String redisKey = "test:count"; BoundValueOperations operations = redisTemplate.boundValueOps(redisKey); operations.increment(); operations.increment(); operations.increment(); operations.increment(); operations.increment(); System.out.println(operations.get()); }这部分在我看来是最有意思的,我们有必要了解底层数据结构的实现,这也是我最感兴趣的。比如,
包括数据库,持久化,处理事件、客户端服务端、事务的实现、发布和订阅等功能的实现,也需要了解。
redis并未使用传统的c语言字符串表示,它自己构建了一种简单的动态字符串抽象类型。
在redis里,c语言字符串只会作为字符串字面量出现,用在无需修改的地方。
当需要一个可以被修改的字符串时,redis就会使用自己实现的SDS(simple dynamic string)。比如在redis数据库里,包含字符串的键值对底层都是SDS实现的,不止如此,SDS还被用作缓冲区(buffer):比如AOF模块中的AOF缓冲区以及客户端状态中的输入缓冲区。
下面来具体看一下sds的实现:
struct sdshdr{ int len;//buf已使用字节数量(保存的字符串长度) int free;//未使用的字节数量 char buf[];//用来保存字符串的字节数组};sds遵循c中字符串以'sds遵循c中字符串以'\0'结尾的惯例,这一字节的空间不算在len之内。这样的好处是,我们可以直接重用c中的一部分函数。比如printf;'结尾的惯例,这一字节的空间不算在len之内。这样的好处是,我们可以直接重用c中的一部分函数。比如printf;
sds相对c的改进
获取长度:c字符串并不记录自身长度,所以获取长度只能遍历一遍字符串,redis直接读取len即可。
缓冲区安全:c字符串容易造成缓冲区溢出,比如:程序员没有分配足够的空间就执行拼接操作。而redis会先检查sds的空间是否满足所需要求,如果不满足会自动扩充。
内存分配:由于c不记录字符串长度,对于包含了n个字符的字符串,底层总是一个长度n+1的数组,每一次长度变化,总是要对这个数组进行一次内存重新分配的操作。因为内存分配涉及复杂算法并且可能需要执行系统调用,所以它通常是比较耗时的操作。
redis内存分配:
1、空间预分配:如果修改后大小小于1MB,程序分配和len大小一样的未使用空间,如果修改后大于1MB,程序分配 1MB的未使用空间。修改长度时检查,够的话就直接使用未使用空间,不用再分配。
2、惰性空间释放:字符串缩短时不需要释放空间,用free记录即可,留作以后使用。
二进制安全
c字符串除了末尾外,不能包含空字符,否则程序读到空字符会误以为是结尾,这就限制了c字符串只能保存文本,二进制文件就不能保存了。
而redis字符串都是二进制安全的,因为有len来记录长度。
作为一种常用数据结构,链表内置在很多高级语言中,因为c并没有,所以redis实现了自己的链表。
链表在redis也有一定的应用,比如列表键的底层实现之一就是链表。(当列表键包含大量元素或者元素都是很长的字符串时)发布与订阅、慢查询、监视器等功能也用到了链表。
具体实现:
//redis的节点使用了双向链表结构typedef struct listNode { // 前置节点 struct listNode *prev; // 后置节点 struct listNode *next; // 节点的值 void *value;} listNode;//其实学过数据结构的应该都实现过typedef struct list { // 表头节点 listNode *head; // 表尾节点 listNode *tail; // 链表所包含的节点数量 unsigned long len; // 节点值复制函数 void *(*dup)(void *ptr); // 节点值释放函数 void (*free)(void *ptr); // 节点值对比函数 int (*match)(void *ptr, void *key);} list;总结一下redis链表特性:
双端、无环、带长度记录
多态:使用 void* 指针来保存节点值, 可以通过 dup 、 free 、 match 为节点值设置类型特定函数, 可以保存不同类型的值。
其实字典这种数据结构也内置在很多高级语言中,但是c语言没有,所以redis自己实现了。应用也比较广泛,比如redis的数据库就是字典实现的。不仅如此,当一个哈希键包含的键值对比较多,或者都是很长的字符串,redis就会用字典作为哈希键的底层实现。
来看看具体是实现:
//redis的字典使用哈希表作为底层实现typedef struct dictht { // 哈希表数组 dictEntry **table; // 哈希表大小 unsigned long size; // 哈希表大小掩码,用于计算索引值 // 总是等于 size - 1 unsigned long sizemask; // 该哈希表已有节点的数量 unsigned long used;} dictht;table 是一个数组, 数组中的每个元素都是一个指向dictEntry 结构的指针, 每个 dictEntry 结构保存着一个键值对。
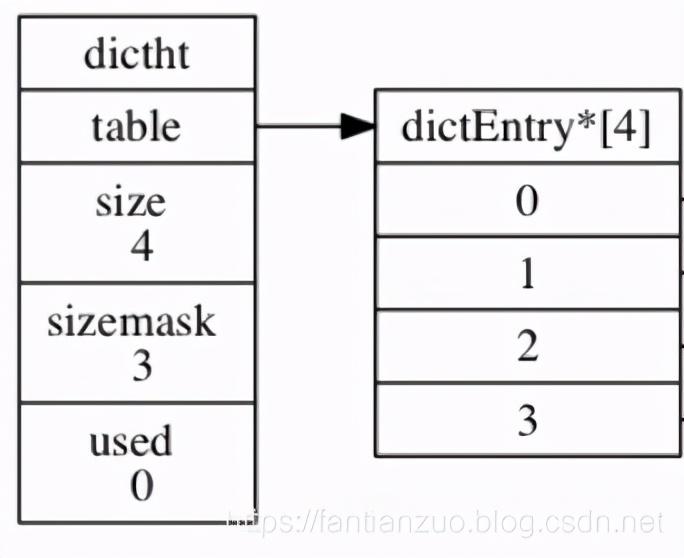
图为一个大小为4的空哈希表。我们接着就来看dictEntry的实现:
typedef struct dictEntry { // 键 void *key; // 值 union { void *val; uint64_t u64; int64_t s64; } v; // 指向下个哈希表节点,形成链表 struct dictEntry *next;} dictEntry;(v可以是一个指针, 或者是一个 uint64_t 整数, 又或者是一个 int64_t 整数。)
next就是解决键冲突问题的,冲突了就挂后面,这个学过数据结构的应该都知道吧,不说了。
下面我们来说字典是怎么实现的了。
typedef struct dict { // 类型特定函数 dictType *type; // 私有数据 void *privdata; // 哈希表 dictht ht[2]; // rehash 索引 int rehashidx; //* rehashing not in progress if rehashidx == -1 } dict;type 和 privdata 是对不同类型的键值对, 为创建多态字典而设置的:
type 指向 dictType , 每个 dictType 保存了用于操作特定类型键值对的函数, 可以为用途不同的字典设置不同的类型特定函数。
而 privdata 属性则保存了需要传给那些类型特定函数的可选参数。
dictType就暂时不展示了,不重要而且字有点多。。。还是讲有意思的东西吧
rehash(重新散列)
随着我们不断的操作,哈希表保存的键值可能会增多或者减少,为了让哈希表的负载因子维持在合理的范围内,有时需要对哈希表进行合理的扩展或者收缩。 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。
redis字典哈希rehash的步骤如下:
1)为ht[1]分配合理空间:如果是扩展操作,大小为第一个大于等于ht[0]*used*2的,2的n次幂。
如果是收缩操作,大小为第一个大于等于ht[0]*used的,2的n次幂。
2)将ht[0]中的数据rehash到ht[1]上。
3)释放ht[0],将ht[1]设置为ht[0],ht[1]创建空表,为下次做准备。
渐进rehash
数据量特别大时,rehash可能对服务器造成影响。为了避免,服务器不是一次性rehash的,而是分多次。
我们维持一个变量rehashidx,设置为0,代表rehash开始,然后开始rehash,在这期间,每个对字典的操作,程序都会把索引rehashidx上的数据移动到ht[1]。
随着操作不断执行,最终我们会完成rehash,设置rehashidx为-1.
需要注意:rehash过程中,每一次增删改查也是在两个表进行的。
整数集合(intset)是 Redis 用于保存整数值的集合抽象数据结构, 可以保存 int16_t 、 int32_t 、 int64_t 的整数值, 并且保证集合中不会出现重复元素。
实现较为简单:
typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[];} intset;各个项在数组中从小到大有序地排列, 并且数组中不包含任何重复项。
虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组, 但实际上 contents 数组并不保存任何 int8_t 类型的值 —— contents 数组的真正类型取决于 encoding 属性的值:
升级
c语言是静态类型语言,不允许不同类型保存在一个数组。这样第一,灵活性较差,第二,有时会用掉不必要的内存。
比如用long long储存1
为了提高整数集合的灵活性和节约内存,我们引入升级策略。
当我们要将一个新元素添加到集合里, 并且新元素类型比集合现有元素的类型都要长时, 集合需要先进行升级。
分为三步进行:
因为每次添加新元素都可能会引起升级, 每次升级都要对已有元素类型转换, 所以添加新元素的时间复杂度为 O(N) 。
因为引发升级的新元素比原数据都长,所以要么他是最大的,要么他是最小的。我们把它放在开头或结尾即可。
降级
略略略,不管你们信不信,整数集合不支持降级操作。。我也不知道为啥
压缩列表是列表键和哈希键的底层实现之一。
当一个列表键只包含少量列表项,并且列表项都是小整数或者短字符串,redis就会用压缩列表做列表键底层实现。
压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
一个压缩列表可以包含任意多个节点(entry), 每个节点可以保存一个字节数组或者一个整数值。
具体实现:

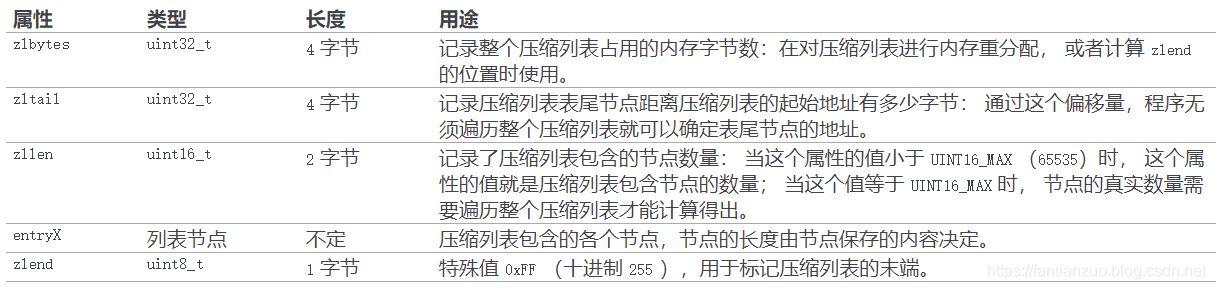
具体说一下entry:
由三个部分组成:
1、previous_entry_length:记录上一个节点的长度,这样我们就可以从最后一路遍历到开头。
2、encoding:记录了content所保存的数据类型和长度。(具体编码不写了,不重要)
3、content:保存节点值,可以是字节数组或整数。(具体怎么压缩的等我搞明白再补)
连锁更新
前面说过, 每个节点的 previous_entry_length 属性都记录了前一个节点的长度:
现在, 考虑这样一种情况: 在一个压缩列表中, 有多个连续的、长度介于 250 字节到 253 字节之间的节点 ,这时, 如果我们将一个长度大于等于 254 字节的新节点 new 设置为压缩列表的表头节点。。。。
然后脑补一下,就会导致连锁扩大每个节点的空间对吧?e(i)因为e(i-1)的扩大而扩大,i+1也是如此,以此类推... ...
删除节点同样会导致连锁更新。
这个事情只是想说明一个问题:插入删除操作的最坏时间复杂度其实是o(n*n),因为每更新一个节点都要o(n)。
但是,也不用太过担心,因为这种特殊情况并不多见,这些命令的平均复杂度依旧是o(n)。
点击关注,第一时间了解华为云新鲜技术~
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号