Redis:从单线程高效到引入多线程的背后原因
发表时间: 2021-03-15 13:08
Redis是目前广为人知的一个内存数据库,在各个场景中都有着非常丰富的应用,前段时间Redis推出了6.0的版本,在新版本中采用了多线程模型。
因为我们公司使用的内存数据库是自研的,按理说我对Redis的关注其实并不算多,但是因为Redis用的比较广泛,所以我需要了解一下这样方便我进行面试。
总不能候选人用过Redis,但是我非要问人家阿里的Tair是怎么回事吧。
所以,在Redis 6.0 推出之后,我想去了解下为什么采用多线程,现在采用的多线程和以前版本有什么区别?为什么这么晚才使用多线程?
Redis不是已经采用了多路复用技术吗?不是号称很高的性能了吗?为啥还要采用多线程模型呢?
本文就来分析下这些问题以及背后的思考。
Redis作为一个成熟的分布式缓存框架,它由很多个模块组成,如网络请求模块、索引模块、存储模块、高可用集群支撑模块、数据操作模块等。
很多人说Redis是单线程的,就认为Redis中所有模块的操作都是单线程的,其实这是不对的。
我们所说的Redis单线程,指的是"其网络IO和键值对读写是由一个线程完成的",也就是说,Redis中只有网络请求模块和数据操作模块是单线程的。而其他的如持久化存储模块、集群支撑模块等是多线程的。
所以说,Redis中并不是没有多线程模型的,早在Redis 4.0的时候就已经针对部分命令做了多线程化。
那么,为什么网络操作模块和数据存储模块最初并没有使用多线程呢?
这个问题的答案比较简单!因为:"没必要!"
为什么没必要呢?我们先来说一下,什么情况下要使用多线程?
一个计算机程序在执行的过程中,主要需要进行两种操作分别是读写操作和计算操作。
其中读写操作主要是涉及到的就是I/O操作,其中包括网络I/O和磁盘I/O。计算操作主要涉及到CPU。
而多线程的目的,就是通过并发的方式来提升I/O的利用率和CPU的利用率。
那么,Redis需不需要通过多线程的方式来提升提升I/O的利用率和CPU的利用率呢?
首先,我们可以肯定的说,Redis不需要提升CPU利用率,因为Redis的操作基本都是基于内存的,CPU资源根本就不是Redis的性能瓶颈。
所以,通过多线程技术来提升Redis的CPU利用率这一点是完全没必要的。
那么,使用多线程技术来提升Redis的I/O利用率呢?是不是有必要呢?
Redis确实是一个I/O操作密集的框架,他的数据操作过程中,会有大量的网络I/O和磁盘I/O的发生。要想提升Redis的性能,是一定要提升Redis的I/O利用率的,这一点毋庸置疑。
但是,提升I/O利用率,并不是只有采用多线程技术这一条路可以走!
我们在很多文章中介绍过一些Java中的多线程技术,如内存模型、锁、CAS等,这些都是Java中提供的一些在多线程情况下保证线程安全的技术。
线程安全:是编程中的术语,指某个函数、函数库在并发环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
和Java类似,所有支持多线程的编程语言或者框架,都不得不面对的一个问题,那就是如何解决多线程编程模式带来的共享资源的并发控制问题。
虽然,采用多线程可以帮助我们提升CPU和I/O的利用率,但是多线程带来的并发问题也给这些语言和框架带来了更多的复杂性。而且,多线程模型中,多个线程的互相切换也会带来一定的性能开销。
所以,在提升I/O利用率这个方面上,Redis并没有采用多线程技术,而是选择了多路复用 I/O技术。
Redis并没有在网络请求模块和数据操作模块中使用多线程模型,主要是基于以下四个原因:
还是要记住:Redis并不是完全单线程的,只是有关键的网络IO和键值对读写是由一个线程完成的。
多路复用这个词,相信很多人都不陌生。我之前的很多文章中也够提到过这个词。
其中在介绍Linux IO模型的时候我们提到过它、在介绍HTTP/2的原理的时候,我们也提到过他。
那么,Redis的多路复用技术和我们之前介绍的又有什么区别呢?
这里先讲讲Linux多路复用技术,就是多个进程的IO可以注册到同一个管道上,这个管道会统一和内核进行交互。当管道中的某一个请求需要的数据准备好之后,进程再把对应的数据拷贝到用户空间中。
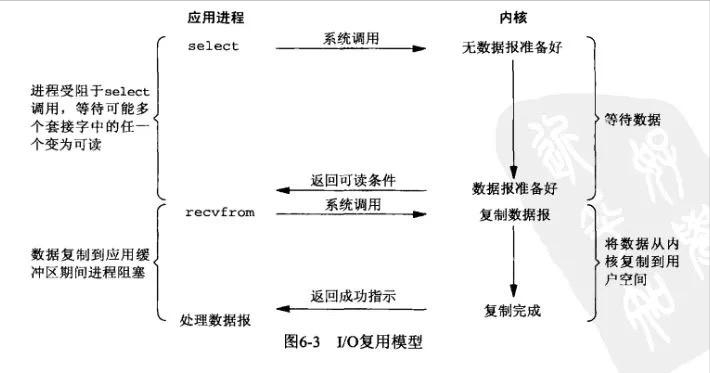

多看一遍上面这张图和上面那句话,后面可能还会用得到。
也就是说,通过一个线程来处理多个IO流。
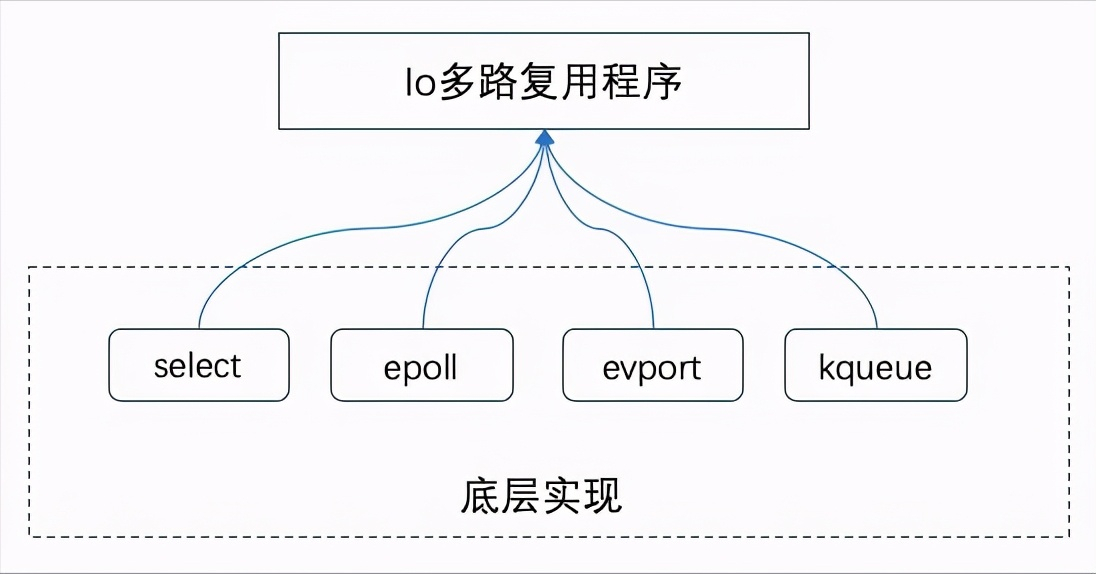
IO多路复用在Linux下包括了三种,select、poll、epoll,抽象来看,他们功能是类似的,但具体细节各有不同。
其实,Redis的IO多路复用程序的所有功能都是通过包装操作系统的IO多路复用函数库来实现的。每个IO多路复用函数库在Redis源码中都有对应的一个单独的文件。

在Redis 中,每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
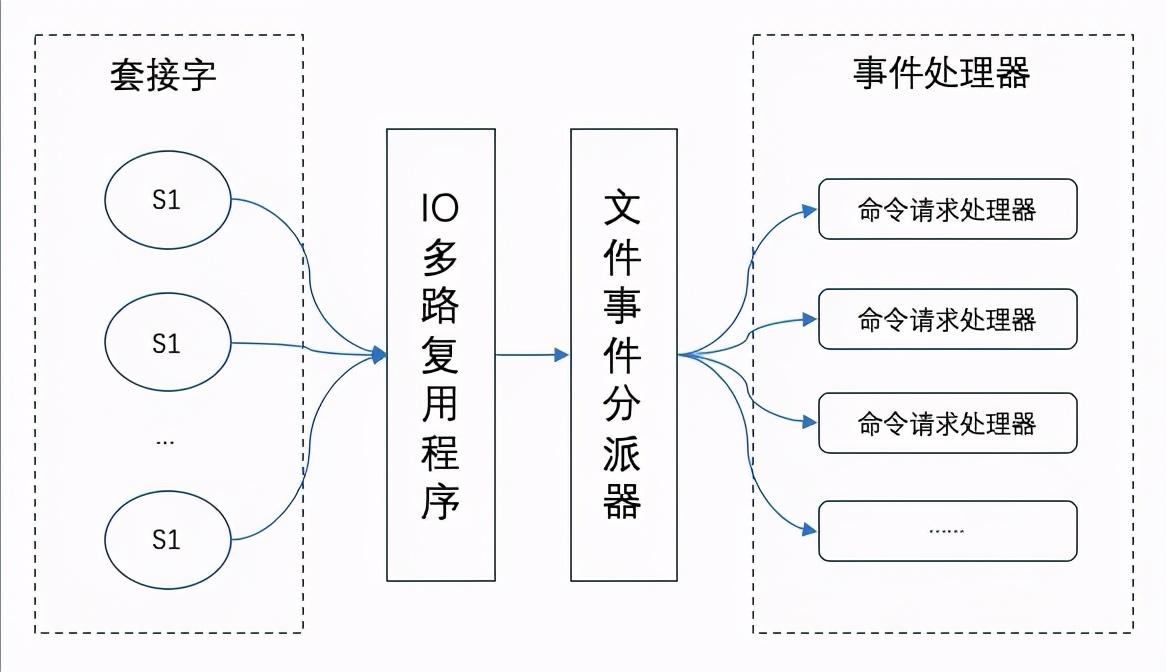

一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
所以,Redis选择使用多路复用IO技术来提升I/O利用率。
而之所以Redis能够有这么高的性能,不仅仅和采用多路复用技术和单线程有关,此外还有以下几个原因:
2020年5月份,Redis正式推出了6.0版本,这个版本中有很多重要的新特性,其中多线程特性引起了广泛关注。
但是,需要提醒大家的是,Redis 6.0中的多线程,也只是针对处理网络请求过程采用了多线程,而数据的读写命令,仍然是单线程处理的。
但是,不知道会不会有人有这样的疑问:
Redis不是号称单线程也有很高的性能么?
不是说多路复用技术已经大大的提升了IO利用率了么,为啥还需要多线程?
主要是因为我们对Redis有着更高的要求。
根据测算,Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,对于小数据包,Redis 服务器可以处理 80,000 到 100,000 QPS,这么高的对于 80% 的公司来说,单线程的 Redis 已经足够使用了。
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的 QPS。
为了提升QPS,很多公司的做法是部署Redis集群,并且尽可能提升Redis机器数。但是这种做法的资源消耗是巨大的。
而经过分析,限制Redis的性能的主要瓶颈出现在网络IO的处理上,虽然之前采用了多路复用技术。但是我们前面也提到过,多路复用的IO模型本质上仍然是同步阻塞型IO模型。
下面是多路复用IO中select函数的处理过程:
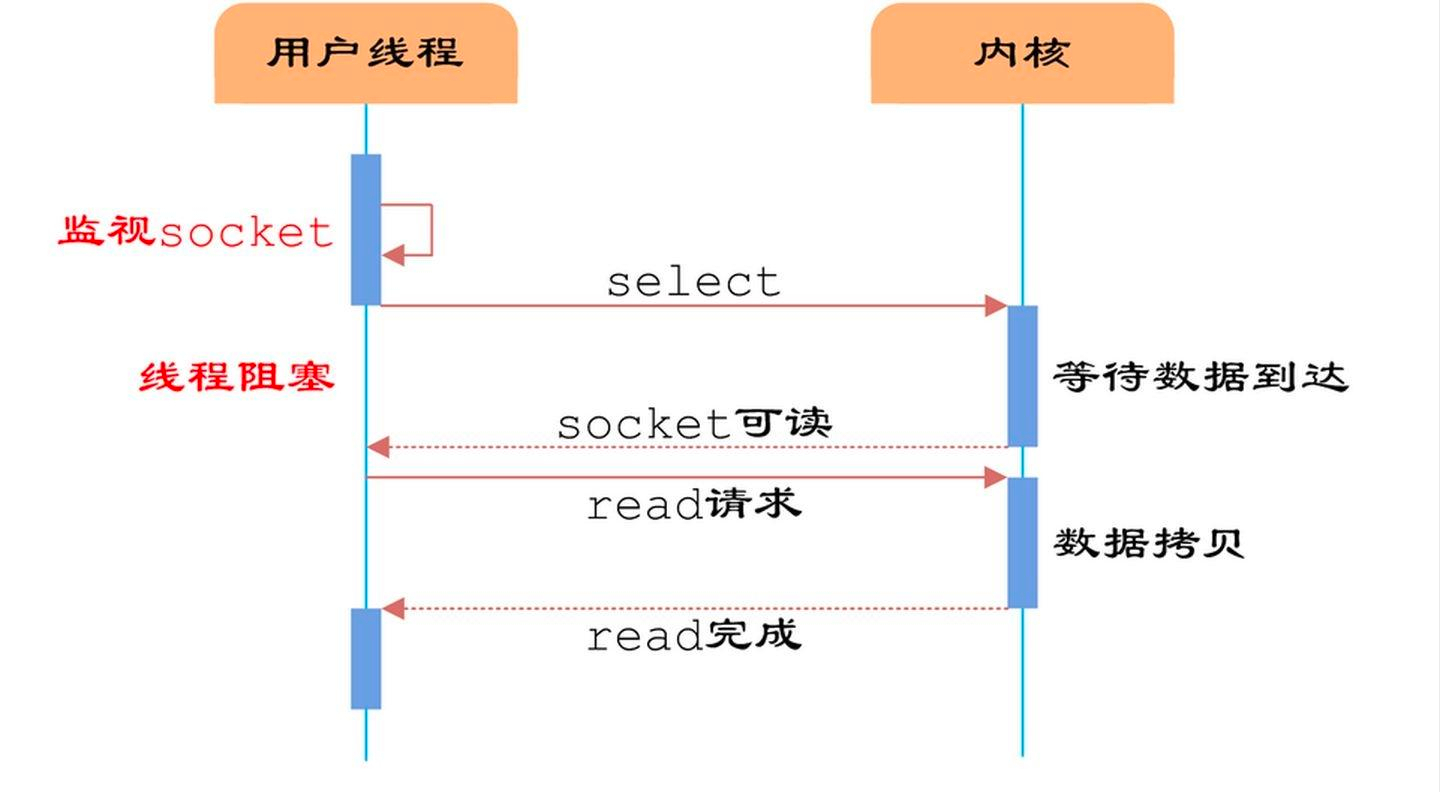

从上图我们可以看到,在多路复用的IO模型中,在处理网络请求时,调用 select (其他函数同理)的过程是阻塞的,也就是说这个过程会阻塞线程,如果并发量很高,此处可能会成为瓶颈。
虽然现在很多服务器都是多个CPU核的,但是对于Redis来说,因为使用了单线程,在一次数据操作的过程中,有大量的CPU时间片是耗费在了网络IO的同步处理上的,并没有充分的发挥出多核的优势。
如果能采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
所以,Redis 6.0采用多个IO线程来处理网络请求,网络请求的解析可以由其他线程完成,然后把解析后的请求交由主线程进行实际的内存读写。提升网络请求处理的并行度,进而提升整体性能。
但是,Redis 的多 IO 线程只是用来处理网络请求的,对于读写命令,Redis 仍然使用单线程来处理。
那么,在引入多线程之后,如何解决并发带来的线程安全问题呢?
这就是为什么我们前面多次提到的"Redis 6.0的多线程只用来处理网络请求,而数据的读写还是单线程"的原因。
Redis 6.0 只有在网络请求的接收和解析,以及请求后的数据通过网络返回给时,使用了多线程。而数据读写操作还是由单线程来完成的,所以,这样就不会出现并发问题了。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号