2022年及以后的服务器规划展望
发表时间: 2021-08-08 16:27
更多互联网精彩资讯、工作效率提升关注【飞鱼在浪屿】(日更新)

Servers 2022的变化
2022 年服务器架构的转变将与 2012 年至 2017 年的至强 E5 时代所看到的完全不同,即使2019 年出世的Skylake/Naples 。大约七年相对较低的创新的事实意味着,现在有 9 到 10 年经验的人从未见过服务器架构的大规模转变。本文将展示 2022 年及以后的服务器规划系列在不久的将来会有多少变化。
2022 年服务器 CPU 相对众所周知的变化将是 向DDR5 过渡以及更高的内核数,向小芯片和更先进封装的转变,这些技术将有助于推动未来几年行业的大部分变革。

Intel Xe HPC Ponte Vecchio 封装
此外还有一些讨论较少的变化。其中之一就是 CPU 上板载“close”内存的增加。
计算的最基本挑战之一是保持执行单元忙着做有用的工作。每年,全球计算能力的很大一部分被浪费在等待数据进入执行核心。除了分支预测器、推测执行等机制,以及业界用来应对这一效率挑战的更多机制,其中一个关键组件是片上缓存。这些缓存使执行单元可以轻松访问数据。
十多年来,我们一直在讨论缓存大小在 MB 范围内的服务器 CPU。自Intel 45nm芯片代号NehalemEP售卖的同一时间,STH成立于于2009年,这些芯片部分有四个核心,8MB三级缓存,和IO集线器。从那时起,英特尔 CPU 上的 L3 缓存通常变得更小,但随着系统变得更大,这个时代可能会在未来几年发生变化。在不久的将来,我们将开始用 GB 单位而不是 MB 来参考 CPU缓存。

AMD V-Cache在这方面是一个信号。AMD V-Cache 是增加其处理器中缓存数量的一种方式。实现这一点的方法是在计算芯片上方堆叠 SRAM 缓存硅芯片。一旦这两块硅片堆叠在一起,支撑结构采用一种称为硅通孔或 TSV 的技术。
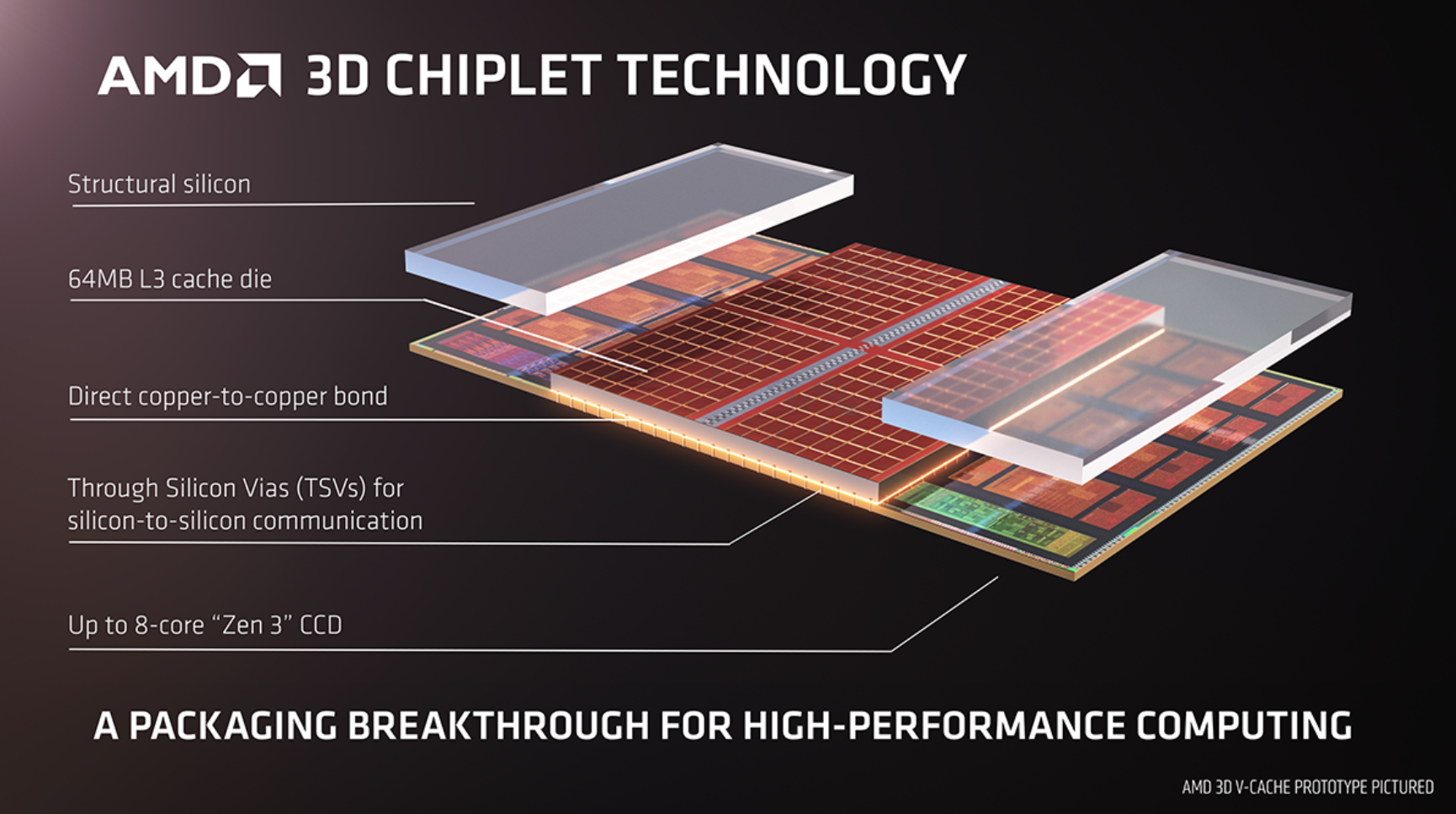
AMD 3D Chiplet 技术
AMD V-Cache 有效地允许公司简单地向处理器包添加更多缓存。

从 2022 年开始,CXL(Compute Express Link) 将成为行业中的一股巨大力量,但随着CXL 2.0 及更高版本,CXL 将逐渐增强。
Compute Express Link 是一个缓存一致性链接系统,旨在帮助那些尤其是带有加速器的系统,更有效地运行。CXL 位于 PCIe Gen5 链路基础架构之上。可以有 PCIe Gen5 设备,但许多 PCIe Gen5(或 PCIe 5.0)设备还将支持在 PCIe 或 CXL 模式下运行通道的能力。在某些方面,这类似于 AMD EPYC CPU 如何将其 I/O 通道作为 PCIe 或 Infinity Fabric 运行。这将成为一个广泛的行业标准,而不是特定于供应商的实现。CXL 的主要优点是它允许加载/存储发生在直接连接到不同终端的内存中。
可以查看文章:Compute Express Link 或 CXL 是什么以及更多相关示例。
https://www.servethehome.com/compute-express-link-or-cxl-what-it-is-and-examples/
也许更重要的是,CPU 在服务器中的作用将在未来几个季度发生巨大变化。在 CXL 之后,我们将来到 Gen-Z时代,例如Dell EMC PowerEdge MX 中的 Gen-Z。

最大趋势之一是 EDSFF 转向各种 E1 和 E3 外形尺寸。这将是从基于机械旋转磁盘的外形尺寸转变为专为 PCIe/CXL 设备(包括闪存存储)设计的产品。EDSFF 为更高功率的设备提供了更多的功率和冷却能力,无论是传统的 SSD、计算存储设备,还是 AI 加速器。
E1 和 E3 EDSFF 将取代固态硬盘中的 M.2 和 2.5。
Intel Optane 持久内存以及它在未来几代中将如何改变,包括为什么美光将重点从 DIMM 连接的 3D XPoint 转移。

还有一些存储部分。Intel的 SAS4将是更具影响力的变化。继续阅读:
https://www.servethehome.com/glorious-complexity-of-intel-optane-dimms-and-micron-exiting-3d-xpoint/
网络在过去 12 个月左右的时间里已经围绕 DPU 术语进行了整合。
NVIDIA Networking(前身为 Mellanox)将其 SmartNIC 的命名从“IPU”改为“DPU”或数据处理单元。行业似乎正在将这些本身用作微型服务器的网络设备称为 DPU,
继续阅读:
https://www.servethehome.com/what-is-a-dpu-a-data-processing-unit-quick-primer/
网络是一个必须不断演进到更快迭代的领域,不仅要处理更大的服务器,而且还要处理具有 5G 等边缘技术的连接速度更快的设备。比如下面的基于 Innovium Teralynx 7 的 32x 400GbE 交换机内部。

除了这些 32x 400GbE 交换机之外,我们将过渡到需要硅光子学和光学器件共同封装的时代。这可能不会在 2022 年发生,但将会几年时间的不远将来。

未来边缘网络还会向 2.5GbE 过渡,但这些不太关注传统服务器。 5G 基础设施的一些加速器是一个需要大量投资的行业。
AI 加速器市场将转向于 2019 年Facebook 推出的OCP Accelerator Module OAM Launched和Facebook Zion Accelerator Platform for OAM 中的 OAM 外形。

带冷却功能的 Facebook Zion OAM 模块
OAM 被视为是 2022 年及以后 AI 加速器行业的主要力量,即使有一些非常酷的替代方案,例如像Cerebras Systems那样制造一个大型芯片。

NVIDIA Tesla T4 背面
诸如NVIDIA T4或基于 PCIe 的 A100 模块之类的卡在传统服务器以及移动/加固和 ORAN 风格的外形中进行边缘推理。一个巨大的应用将是视频分析,我们已经开始使用视频/边缘 AI 平台,例如Xilinx Kria KV260 基于 FPGA 的视频 AI 开发套件,因为这些平台将成为数据从边缘到网络的核心。在不久的将来,人工智能推理将成为几乎所有服务器的一项功能,并且在该声明中将涵盖云到边缘。

最近,我们刚刚查看了液体冷却是下一代服务器中的冷却选项,下一代服务器肯定会使用更多功率并需要更多冷却,因此我们已经开始介绍这些解决方案。继续阅读:
https://www.servethehome.com/liquid-cooling-next-gen-servers-getting-hands-on-3-options-supermicro/
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号