探索LLM/AIGC带来的创新机遇
发表时间: 2023-06-21 09:22
2023年6月10日~11日,人人都是产品经理举办的【2023数字化产品经理大会·深圳站】完美落幕。远望资本创始合伙人@程浩老师,为我们带来《LLM/AIGC带来的创新机会》为题的分享。

ChatGPT的出现仿佛平地一声惊雷,无异于第四次工业革命。大模型对于人类的价值远超互联网的价值,互联网是搜索信息,大模型是理解信息。举个例子,图书馆有成千上万的书,互联网能帮我们做的是找到这本书,而大模型可以帮你理解、看懂、消化这本书。
而未来大模型对人类工作的替代会从初级白领开始,比如帮忙订酒店机票的助理,发展到后面可能也会取代高级白领,比如律师、医生等。
这就带来一个问题:未来,知识不是必选项。纯知识性的、重复性的工作将会被取代,留下来的岗位,都是在做创新的岗位。这也将会对国内的教育体系造成冲击。
接下来讲什么是LLM。这是一种压缩技术,提示语(Prompt)是解压缩。涌现是解压缩中,随机组合出现新的内容。它就相当于基因突变,但大部分基因突变都是错误的,涌现是好的基因突变。
泛化是LLM核心能力。什么是泛化?以前我在百度时,做问答的、客服的、新闻的都有自己的大模型和算法,但他们都只在垂直领域达到了59分,还不能商业化。而ChatGPT这个通用的模型,在每一个垂直领域都达到了80分,具有很好的泛化能力。
训练大语言模型模型,需要三个步骤。第一步是预训练,去互联网找很多语料,无监督学习。接下来第二步就是指令微调,给Q&A,预训练做得好,指令微调的成本越低。第三步是reinforcement learning。根据用户反馈不断调整,你问AI一个问题,AI给你回答,你可以告诉他是对的,给他正向回馈;也可以告诉他是错的,要他进行修正,让AI不断优化。还包括对齐,比如对其价值观,不能有地域歧视、残疾人歧视等等。
这三个步骤中,预训练的成本是最高的,没有上亿都不要搞预训练。很多创业公司都是先找好一个预训练模型,再进行后面两个步骤。
从大模型角度来说,数据质量是最重要的,其次是数据多样性,然后是数据规模,再是模型,最后才是模型参数。这也解释了为什么英文状态下的大模型效果会更好,因为不管是从数据质量还是数量或者多样性上,英文都是远超其他语言的。
如今,千亿参数可能是极限,未来的趋势是小型化,比如把大语言模型集成到手机里。
未来,还有一个趋势是从GUI(图形界面)到NLUI(自然语言交互)。现在打车还需要用滴滴,订外卖还要用美团,未来可以直接拿手机说打车去机场,订票去上海。
现在几乎每个企业都有自己的数据库,未来大语言模型也会像数据库一样,成为企业的重要基础措施。
未来大语言模型会让那些行业受益呢?主要是以文字语言交互为主导的行业,对纯数字化行业影响不大。
在C端领域,受益的可能是写作、问答、总结、法律、招聘、售前、客服、营销等这些以文字交互为主的行业。
那么,想要做大语言模型,是用开源模型还是闭源模型呢?像ChatGPT、文心一言这些都是闭源模型,但开源模型的趋势正愈演愈烈。
创业公司选择开源还是闭源呢?各有优势。开源你只需要买TOKEN就好了,再加上 Prompt engineering和向量数据库等。闭源的优势在于,保护数据隐私,并且可以不断用数据填充完善自己的模型。
C端有做开源的也有闭源的,但是B端几乎都是开源的。在做demo的时候,通常会用闭源的,效果最好,还不用买云计算资源,等到要形成行业壁垒了,再改回到开源模型。
那么,大语言模型,也就是通用模型,它的泛化能力足够好之后,是不是不需要垂直模型了?
不是的。通用模型很难替代垂直模型。
因为80%的有价值的行业知识和数据都在企业防火墙内,通用模型没办法接触到这些数据,自然也就没办法推导出答案。并且,通用模型具有一定的模糊性,所以它更适合一些容错率高的、低价值的行业。垂直模型更适合容错率低的、高价值的行业。
比如炒股票、自动驾驶这类需要精确、可控的事情显然不能用通用模型,但是聊天、写作就可以。
大语言模型有四个架构,最底层的是Infrastructure,例如算法、算力,这些和创业公司都没关系,都是巨头在参与。
第二层是large language models,比如ChatGPT、文心一言、通义千问都是属于第二层的。
第三层是LLMOPs,这层实际上是工具层,像向量数据库就是典型的LLMOPs。
第四层是应用APP。
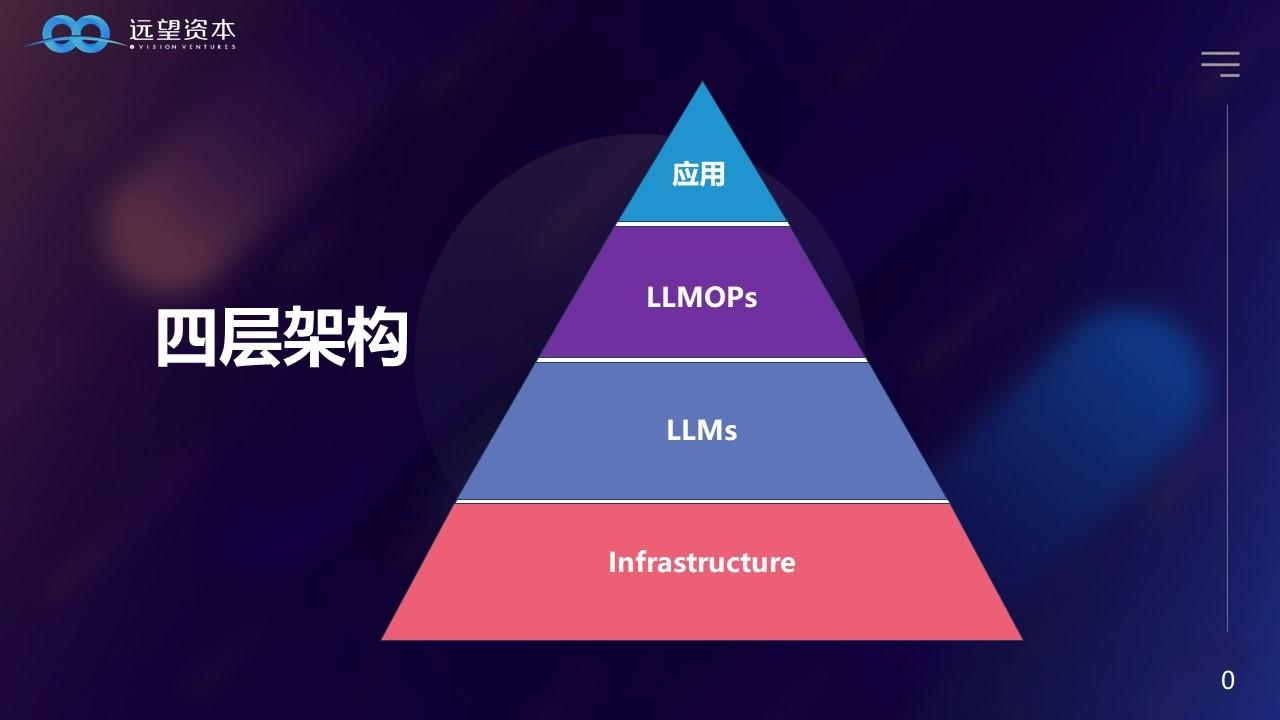
最下面两层没有上亿的资金很难做出来,适合大公司去做,上面两层比较适合创业公司,尤其是应用层,可应用的行业太多了。
那么,创业公司能不能做通用大语言模型呢?很难。
首先,缺乏先发优势。创业公司能突破大公司的包围,核心原因就是你跑得快,有先发优势。要么是大公司没看上、没看懂或者走错方向了,所以创业公司能冲出来。但在大语言模型这块,这些情况都不成立,每个大公司都无比重视。
第二,没有Dummy Period。现在做大模型已经成为了共识,但是创业公司要想跑出来,那就得留有一定的非共识期来发育。
第三,缺乏场景。大公司都有很好的落地场景,比如百度可以把问答和搜索引擎结合,腾讯的语言模型可以和微信结合。但是创业公司有什么可落地的场景呢?
在垂直领域,创业的机会还是挺多的。我分成B端、C端、国内、国外四个方面来讲。
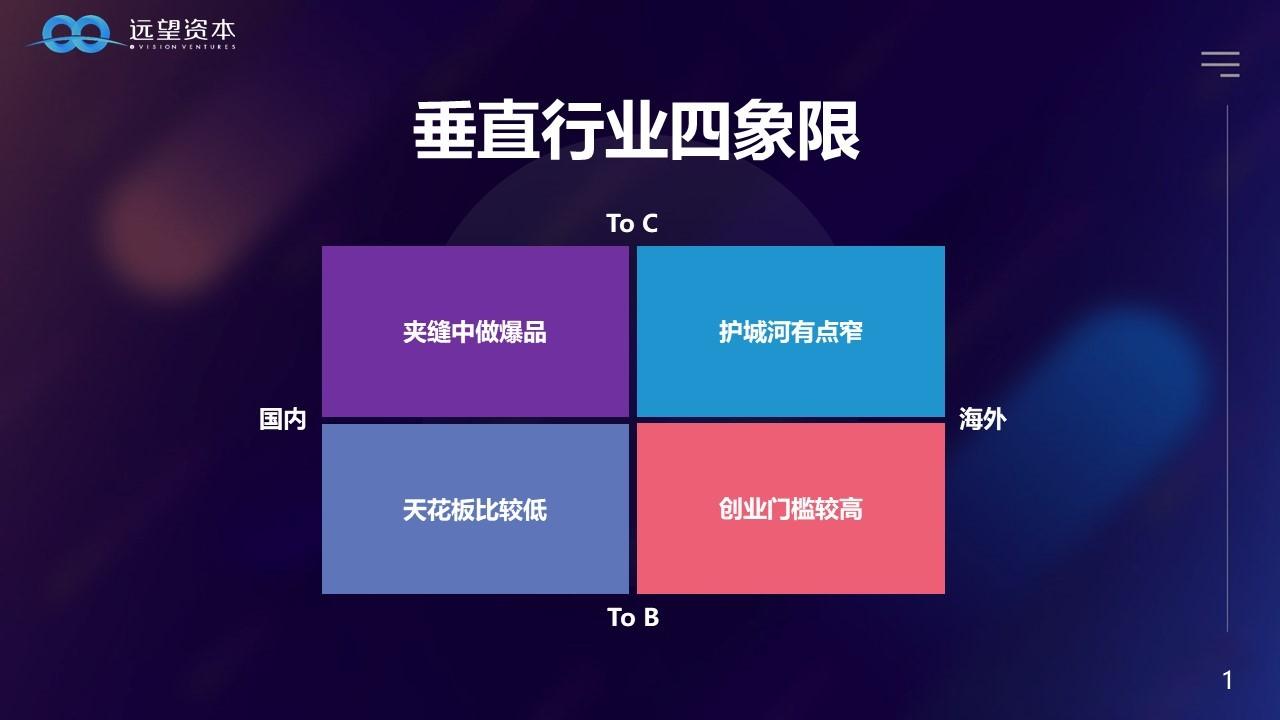
在国内做TO C的好处是什么呢?高爆发。在国内几个月做成几百万DAU是非常有可能的。但问题是什么呢?第一,壁垒低。你能做的,竞争对手也能做。第二,C端的流量红利没了。想想大家手机的首页APP已经有多久没更新过就知道了,几年都不会下载一个新应用。第三,巨头抄袭。你做了一个APP,那字节跳动、腾讯跟你做一个类似的,你怎么办?第四,合规成本高。做C端的大语言模型,用户问的问题是千奇百怪的,指不定哪个问题就违规了。第五,只能用国内的大模型。
在国内做TO B的好处是离钱近,壁垒相对高一些。但问题是,天花板低。在中国做TO B最大的痛苦就是企业的付费能力不好,这是受限于国内B端市场的规模。中国的IT Spending只有美国的六分之一,国内上市SaaS公司的人均产值只有30—60万人民币。所以在中国做企业服务就比较辛苦,核心原因就是民企没钱。
在国际做C端的好处是增长快,问题同样是壁垒低,而且市场已经是红海了。并且,即使是海外AIGC独角兽也面临巨头竞争。
在国际做B端的好处是海外企业付费好,天花板高。有垂直壁垒,巨头不会进入,而且国外的大模型相对更成熟。但问题是团队得懂海外的企业服务市场。
最后,我们在创业的时候,是AIGC+还是+AIGC呢?这两者的区别是你是用AIGC原生还是用AIGC赋能。比如要做一个客服系统,一个团队是之前就做AI的,先做好了问答机器人,再去添加客服系统的其他功能;另一个团队是本来就是做客服SaaS的,只不过之前的SaaS不是智能的而是人在后面回答,现在要把AI的自动回答功能加到已有的客服系统里去。
如何判断你更适合哪一种?第一个判断依据,如果公司70%的价值链都是AI,那么很显然就适合AIGC+的赛道。如果本身是SaaS,而AI只占到10%,那显然更适合+AIGC。第二个判断依据,看AI本身的技术壁垒怎么样。如果你选择AIGC+的赛道,那就必须补充业务工作流,完善价值链。未来,AIGC+和+AIGC一定会相互渗透的。
本文为直播专场分享整理内容,由人人都是产品经理运营 @Darcy 整理发布。未经许可,禁止转载,谢谢合作。
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。息存储空间服务。储空间服务。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号