具身智能系统基础模型的技术路线图:引领智能进化新篇章
发表时间: 2024-07-23 18:44
【导读】在探索人工智能的前沿领域,具身智能(EAI)正逐渐成为焦点。本文深入剖析了构建 EAI 系统基础模型的核心技术,特别强调了元学习与通用上下文学习(GPICL)的结合,为机器人等实体提供了更强大的学习和适应能力。文章不仅讨论了元学习如何使模型快速适应新任务,还介绍了上下文学习如何让模型即时利用输入数据进行推理,这些技术的应用前景令人瞩目。进一步地,文章对比了预训练大型模型与元训练+GPICL 方法的优劣,指出了在计算和内存资源受限的情况下,如何通过创新技术如 Infini-attention 和 StreamingLLM 来克服挑战,相信对于探索 EAI 领域开发者而言,一定会大有裨益。
具身智能(EAI)是指将人工智能嵌入机器人等有形实体,使其具备感知、学习和动态参与周围环境的能力。在本文中,我们将深入探讨为 EAI 系统构建基础模型的技术方向选择。相对于预训练好的世界模型系统,我们认为元学习 + GPICL(通用上下文学习)方法为具身智能系统提供更好的学习能力,具有更好的长期适应性和泛化能力,因此有可能是最适合具身智能系统基础模型技术路线。
背景知识
元学习
元学习(Meta-Learning)是一种机器学习方法,其目标是使模型能够快速适应新任务并提高学习效率。元学习的核心思想是通过学习如何学习,从而在面对新任务时能够迅速进行调整和适应。与传统的机器学习方法不同,元学习不仅关注模型在单一任务上的表现,还关注模型在多个任务上的泛化能力。
在元学习中,模型通常通过在多个任务上的训练来学习共享知识。每个任务可以被视为一个独立的学习过程,模型通过这些任务来提高其元学习能力。这种训练方式使得模型能够捕捉到任务之间的共性,从而在遇到新任务时能够利用这些共性进行快速学习和调整。
元学习的一个关键组件是元训练(Meta-Training),在这一阶段,模型通过大量不同任务的训练来学习元知识。这些任务可以是相似的,也可以是完全不同的。通过在不同任务上的反复训练,模型可以提取出能够在各种任务中使用的通用模式和策略。在元学习过程中,模型通常包含两个主要部分:快速适应和元知识。快速适应部分负责在每个具体任务中的学习和调整,而元知识部分则保存和管理从所有任务中提取的共性知识。这种结构使得模型既能够进行具体任务的快速学习,又能从多个任务中获取和利用元知识。
元学习的一个重要应用是具身智能(Embodied AI),例如机器人技术。在这些应用中,模型需要不断适应变化的环境和任务,通过元学习,机器人能够在不同环境和任务中快速调整和优化其行为,而不需要每次都从零开始进行学习。
元学习的方法有多种实现方式,包括基于梯度的元学习、基于记忆的元学习和基于模型的元学习。基于梯度的元学习方法,如 MAML(Model-Agnostic Meta-Learning),通过对多个任务的梯度信息进行优化,使模型能够快速适应新任务。基于记忆的元学习方法通过存储和检索任务相关的信息,来提高模型的学习效率。基于模型的元学习方法则通过设计特定的模型结构,使其能够更好地进行元学习。
上下文学习
上下文学习(In-Context Learning)旨在使模型能够利用当前输入的上下文信息进行即时学习和推理。与传统的训练-测试分离的学习方式不同,上下文学习允许模型在推理过程中动态地使用输入数据进行调整和改进,从而更好地理解和处理当前任务。
在上下文学习中,模型通过接收一系列上下文信息(例如,输入的句子、对话或任务描述)来调整其内部状态和参数。这种方法使得模型能够在不需要额外训练的情况下,利用上下文中的信息来进行推理和决策。这种即时学习的能力使得模型能够在处理新的和未见过的任务时表现出更高的灵活性和适应性。上下文学习的核心机制是模型利用输入序列中的信息来进行推理和调整。具体来说,模型会在处理每一个输入时,结合之前的上下文信息,对当前输入进行分析和理解。这种方法依赖于模型的内部记忆机制,如自注意力机制(Self-Attention),来捕捉和利用上下文中的关键信息。
上下文学习在大规模预训练语言模型中得到了广泛应用。例如,GPT 系列模型(如 GPT-3)通过大量的文本数据进行预训练,学习到丰富的语言表示和知识。在实际应用中,这些模型可以通过输入一段上下文(如问题和相关信息),即时生成相关的回答或解决方案,而不需要进行额外的微调。这种能力使得上下文学习在自然语言处理、对话系统和其他需要动态适应的任务中表现出色。
上下文学习的一个重要特征是其高效性和灵活性。模型能够根据上下文中的提示和示例,迅速调整其推理策略和行为,从而在面对不同任务和场景时表现出更好的适应性。此外,上下文学习还可以有效避免传统学习方法中的灾难性遗忘问题,因为它不依赖于长时间的训练和微调,而是通过即时利用上下文信息进行推理和调整。
在上下文学习的实现中,自注意力机制起到了关键作用。自注意力机制允许模型在处理每一个输入时,关注和利用之前输入中的相关信息,从而在上下文中建立起复杂的依赖关系和模式。这种机制使得模型能够捕捉到上下文中的长程依赖关系,并在推理过程中灵活应用。
模型预训练
模型预训练(Model Pretraining)通过在大规模数据集上训练模型,使其学习到广泛的特征表示和通用知识。预训练的目标是通过在多种任务和大量数据上训练模型,使其具备强大的泛化能力和丰富的知识储备。
在模型预训练过程中,通常会选择一个大型数据集,这些数据集涵盖了不同领域和主题,确保模型能够学习到多样化的信息。常见的数据集包括文本、图像和音频等,不同类型的数据集对应不同的预训练任务。例如,文本数据集可以用于训练语言模型,图像数据集可以用于训练卷积神经网络(CNN)。
预训练模型通常采用无监督学习或自监督学习的方法进行训练。在无监督学习中,模型通过对数据的内在结构进行建模来学习特征表示,而不依赖于人工标注的数据。在自监督学习中,模型通过生成部分标签或使用数据本身的结构信息来进行训练。例如,语言模型可以通过预测句子中的下一个词来进行自监督学习。预训练过程通常包括以下几个步骤:
首先,选择适当的数据集进行预处理。预处理步骤包括数据清洗、去除噪声、格式转换等,确保数据质量和一致性。
接下来,定义预训练任务和模型结构。对于语言模型,常见的预训练任务包括语言模型任务(预测下一个词)、掩码语言模型任务(预测被掩盖的词)和序列到序列任务(机器翻译、文本生成等)。对于图像模型,常见的预训练任务包括图像分类、目标检测和图像生成等。
然后,使用大规模数据集进行训练。预训练过程中通常会采用大批量训练和分布式计算,以加速训练速度。通过反向传播算法,不断调整模型参数,使其在预训练任务上达到最优表现。
在预训练完成后,模型会具备强大的特征提取能力和丰富的知识储备,这为后续的特定任务提供了良好的基础。例如,预训练的语言模型可以在较小的特定任务数据集上进行微调,从而快速适应新任务,提高模型的性能。模型预训练的优势在于通过在大规模数据上学习,使模型具备强大的泛化能力和丰富的知识储备,减少了对特定任务数据的依赖,提高了模型的训练效率和效果。此外,预训练模型还可以迁移到不同的任务和领域,实现跨任务和跨领域的知识共享。
模型微调
模型微调(Model Fine-Tuning)通过在预训练模型的基础上,进一步使用特定任务的数据进行训练,从而使模型在特定任务上达到更高的性能。微调的目标是使预训练模型适应特定应用场景,提高模型在特定任务上的表现。预训练模型通常是在大规模数据集上进行训练的,这些数据集涵盖了广泛的主题和领域。通过这种方式,模型能够学习到丰富的特征表示和通用知识。然而,在特定任务中,通常需要更加细致和专门化的能力,这就需要通过微调来实现。在微调过程中,需要先将预训练模型的参数作为初始值,然后使用特定任务的数据进行进一步训练。这个过程通常涉及以下几个步骤:
首先,收集并准备特定任务的数据集。这些数据通常是与特定应用场景相关的,并且比预训练数据集要小得多。数据集需要进行预处理,包括清洗、标注和格式转换等步骤。
接下来,将预训练模型加载到微调框架中。预训练模型的参数已经在大规模数据上学习到了一般性的特征表示,因此在微调过程中,可以快速适应特定任务的数据。然后,使用特定任务的数据进行训练。在这个阶段,通过反向传播算法,逐步调整模型的参数,使其在特定任务上的表现不断提升。训练过程中的学习率通常较低,以避免对预训练参数进行过大的调整,导致模型过拟合。在微调过程中,常常会采用一些正则化技术,如权重衰减和 Dropout,以防止模型过拟合。此外,还可能使用早停法(Early Stopping)来监控验证集上的性能,以决定训练何时停止。微调的最终目标是使模型在特定任务上具有较高的性能,同时保留预训练模型所学到的通用知识。这种方法的优势在于,通过利用预训练模型的已有知识,可以在较小的数据集上快速达到良好的效果,而不需要从头开始训练一个新模型。
模型微调广泛应用于各种自然语言处理任务,如文本分类、情感分析、问答系统和机器翻译等。通过微调,预训练模型可以有效地适应不同的应用场景,提高其在特定任务上的准确性和鲁棒性。
具身智能的基础模型
在此之前,我们已经概述了开发具身人工智能(EAI)系统的三个指导原则[1]。EAI 系统不应依赖预定义的复杂逻辑来处理特定场景。相反,它们必须结合进化学习机制,从而能够不断适应运行环境。此外,环境不仅会严重影响物理行为,还会影响认知结构。第三项原则侧重于模拟仿真,而前两项原则则强调建立能够从 EAI 系统运行环境中学习的 EAI 基础模型。
EAI 基础模型的常见方法是直接利用预训练的大型模型。例如,预训练的 GPT 模型可以作为基线,然后通过微调和上下文学习(ICL)来提高性能[2]。这些大型模型通常拥有大量参数来编码广泛的世界知识,并具有较小的上下文窗口以实现快速响应时间。这种广泛的预编码使这些模型能够提供出色的 Zero-shot 性能。然而,它们有限的上下文窗口给从 EAI 系统的运行环境中持续学习和连接各种使用场景带来了挑战。
另一种方法是利用参数少得多但上下文窗口更大的模型。这些模型并不编码全面的世界知识,而是专注于学习如何学习,即元学习[3]。有了大的上下文窗口,这些模型就可以执行通用上下文学习(GPICL),从而能够从其运行环境中不断学习,并在广泛的上下文中建立联系。
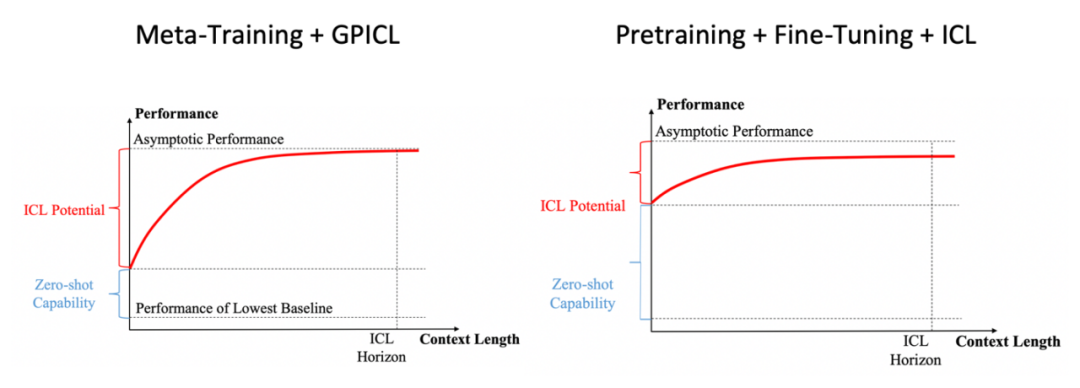
图 1 EAI 的基础模型选项
图 1 展示了这两种不同的方法。元训练 + GPICL 方法虽然 Zero-shot 性能较差,模型规模较小,但在不断从环境中学习方面表现出色,最终使 EAI 系统专门用于特定任务。相比之下,预训练 + 微调 + ICL 方法的特点是模型规模较大,上下文窗口较小,Zero-shot 性能优越,但学习能力较差。
GPT-3 论文中的经验证据支持了这一点,在该论文中,7B 少量学习模型优于 175B Zero-shot 学习模型[4]。如果用较长的上下文窗口来取代 Few-shot 学习,使 EAI 系统能够从其运行环境中学习,性能可能会进一步提高。
我们设想的 EAI 理想基础模型应符合几个关键标准。首先,它应该能够从复杂的指令、演示和反馈中普遍学习,而无需依赖精心设计的优化技术。其次,它在学习和适应过程中应表现出较高的样本效率。第三,它必须具备通过上下文信息持续学习的能力,有效避免灾难性遗忘问题。因此,我们认为元学习 + GPICL 方法适用于 EAI 系统。不过,在决定采用这种方法之前,我们先来看看这两种方法之间的权衡。
构建具身智能基础模型的关键权衡
在本节中,我们将回顾以通用上下文学习为基础的 EAI 预训练大模型方案和现有主流技术方案的差别。该技术方案背景可以参考“Benchmarking General-Purpose In-Context Learning”[5]。这篇论文受元学习和大语言模型训练流程启发,提出以元学习(Meta-training)+ 通用上下文学习(GPICL)替代预训练(Pre-training)+ 微调(Fine-Tuning)+ 上下文学习(ICL)的学习范式以实现更好的泛化性和解决更多样的任务,可以应用于大语言模型,也可以被应用到被认为是具身智能的基石的世界模型和决策模型类任务。
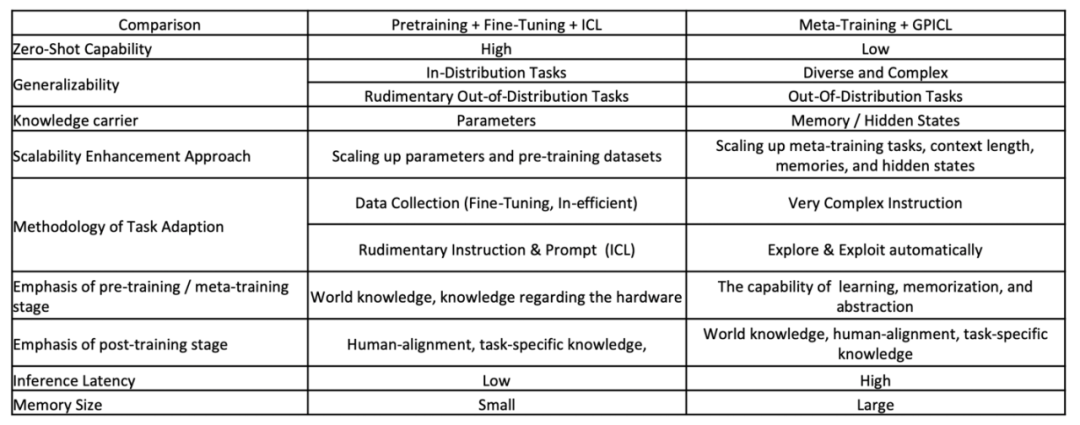
在 Zero-shot 能力方面,预训练 + 微调 + ICL 方法具有很高的性能,可以让模型很好地泛化到新任务中,而不需要任何特定任务的微调[2]。相比之下,元训练 + GPICL 方法的 Zero-shot 泛化能力较低,因为该方法的重点是通过上下文学习来适应各种任务,而不是 Zero-shot 泛化。
在泛化能力方面,预训练 + 微调 + ICL 方法在分布内任务中表现出色,但在训练数据集分布外任务中能力有限。另一方面,元训练 + GPICL 由于强调在不同情境下进行元训练,因此在训练数据集分布外任务中表现出多样化和复杂的泛化能力。
预训练 + 微调 + ICL 的可扩展性增强方法包括扩展参数和预训练数据集,以提高性能。元训练 + GPICL 通过扩大元训练任务、上下文长度、内存和隐藏状态来提高模型的适应性,从而增强可扩展性。
在任务适应方面,预训练 + 微调 + ICL 依赖于数据收集和微调,这可能效率不高。相比之下,元训练 + GPICL 利用非常复杂的指令,自动从不同的语境中学习。
在预训练或元训练阶段,预训练 + 微调 + ICL 侧重于世界知识和对硬件的理解。元训练 + GPICL 强调学习、记忆和抽象各种任务的能力。
在训练后阶段,预训练 + 微调 + ICL 涉及将模型与以人为中心的具体任务相匹配,强调人机匹配和任务特定知识。元训练 + GPICL 继续强调世界知识、人类对齐和特定任务知识。
预训练 + 微调 + ICL 的推理延迟一般较低,因为模型参数在训练后是固定的。然而,对于元训练 + GPICL,由于需要动态地利用和更新内存和隐藏状态,推理速度可能较慢。
预训练 + 微调 + ICL 所需的内存容量很小,因为大部分知识都包含在固定的模型参数中。相反,元训练 + GPICL 需要大量内存来处理复杂指令、扩展上下文和隐藏状态。
元训练 + GPICL 的优势在于能让系统通过情境不断学习各种任务,即学会不断学习[6]。这主要要求系统能够在不遗忘旧任务的情况下学习新任务,这通常会给基于梯度的微调带来巨大挑战(Catastrophic forgetting[7]),但对于情境内学习来说,挑战可能较小。
表 1 预训练大型模型与元训练 + GPICL 的利弊权衡
克服计算和内存瓶颈
从上述比较中可以看出,元训练与 GPICL 的结合可在各种复杂任务中提供卓越的适应性和泛化能力。然而,这种方法对资源的要求较高,对大多数 EAI 系统构成了挑战,因为这些系统通常是计算能力和内存有限的实时边缘设备。这种方法所需的大型上下文窗口会大大增加推理时间和内存占用,可能会阻碍其在 EAI 基础模型中的可行性。
幸运的是,最近的进步为基于变换器的大型语言模型(LLM)的扩展提供了创新解决方案,使其能够处理无限长的输入,同时保持有限的内存和计算效率。一个值得注意的创新是 Infini-attention(无限注意)机制,它在单个变换器块中集成了遮蔽局部注意和长期线性注意[8]。这样就能高效处理短程和远程上下文依赖关系。此外,压缩记忆系统允许模型以有限的存储和计算成本维护和检索信息,重复使用旧的键值(KV)状态,以提高记忆效率,实现快速流推理。实验结果表明,Infini-attention 模型在长语境语言建模基准测试中的表现优于基线模型,在涉及超长输入序列(多达 100 万个词组)的任务中表现出卓越的性能,并显著提高了内存效率和困惑度得分。
同样,StreamingLLM 框架能让使用有限注意力窗口训练的大型模型泛化到无限序列长度,而无需进行微调[9]。这是通过保留作为注意力汇的初始标记的键和值(KV)状态以及最新标记来实现的,从而稳定注意力计算,并在扩展文本中保持性能。StreamingLLM 擅长对多达 400 万个标记的文本进行建模,速度显著提高了 22.2 倍。
结论
总之,我们认为从环境中学习是 EAI 系统的基本特征,因此元训练 + GPICL 方法具有更好的长期适应性和泛化能力,有望用于构建 EAI 基础模型。虽然目前这种方法在计算和内存使用方面面临巨大挑战,但我们相信,Infini-attention 和 StreamingLLM 等创新技术将很快使这种方法在资源受限的实时环境中变得可行。
参考资料
1.A Brief History of Embodied Artificial Intelligence, and its Outlook, Communications of the ACM, https://cacm.acm.org/blogcacm/a-brief-history-of-embodied-artificial-intelligence-and-its-future-outlook/
2.Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744.
3.Kirsch, L., Harrison, J., Sohl-Dickstein, J. and Metz, L., 2022. General-purpose in-context learning by meta-learning transformers. arXiv preprint arXiv:2212.04458.
4.Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A. and Agarwal, S., 2020. Language models are few-shot learners. Advances in neural information processing systems, 33, pp.1877-1901.
5.Wang, F., Lin, C., Cao, Y. and Kang, Y., 2024. Benchmarking General Purpose In-Context Learning. arXiv preprint arXiv:2405.17234.
6.Beaulieu, Shawn, et al. "Learning to continually learn." ECAI 2020. IOS Press, 2020. 992-1001.
7.French, Robert M. "Catastrophic forgetting in connectionist networks." Trends in cognitive sciences 3.4 (1999): 128-135.
8.Munkhdalai, T., Faruqui, M. and Gopal, S., 2024. Leave no context behind: Efficient infinite context transformers with infini-attention. arXiv preprint arXiv:2404.07143.
9.Xiao, G., Tian, Y., Chen, B., Han, S. and Lewis, M., 2023. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453.
大模型刷新一切,让我们有着诸多的迷茫,AI 这股热潮究竟会推着我们走向何方?面对时不时一夜变天,焦虑感油然而生,开发者怎么能够更快、更系统地拥抱大模型?《新程序员 007》以「大模型时代,开发者的成长指南」为核心,希望拨开层层迷雾,让开发者定下心地看到及拥抱未来。
读过本书的开发者这样感慨道:“让我惊喜的是,中国还有这种高质量、贴近开发者的杂志,我感到非常激动。最吸引我的是里面有很多人对 AI 的看法和经验和一些采访的内容,这些内容既真实又有价值。”
注:头图由 DALL·E 生成
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12









 鲁公网安备37020202000738号
鲁公网安备37020202000738号