探索得物社区:Golang灰度环境的实践与应用
发表时间: 2023-03-14 13:48
1
背景
灰度发布可以在服务正式上线前,提前用小流量对新功能进行验证,提前发现问题,避免故障影响所有用户,对业务稳定性非常有价值。
得物社区后端技术栈以 golang 为主,本文记录了社区后端在灰度环境建设过程中遇到的挑战,以及对应的探索和实践。
本文对涉及内部敏感信息部分做了打码和脱敏处理,敬请理解。
2
小得物灰度引流架构优化
2.1 小得物 V1
跟 Java 网关对接注册中心不同,社区 HTTP 是依赖容器 Service 和 Ingress。
对社区来说,因为只有 C 端有外部流量的应用才有部署小得物的价值,所以希望:
gRPC 流量比较简单,通过 RPC 系统流量路由功能即可实现,这个在后面流量路由部分会介绍。
要实现小得物环境只部署部分应用,正确路由流量而不报错,需要网关层、RPC 等调用层感知集群内后端服务有没有部署。
Ingress 这层,其实相当于接了 k8s 的注册中心,它是可以感知到集群是否有可用 upstream。但开源配置无法支持这个需求,二开比较复杂,这个也不在社区的控制范围内。
这个时期社区应用正在进行容器新老集群迁移,在容器 Ingress 之前加了一层 DLB(可以简单理解为 Nginx),通过 location 来区分应用是否部署新集群,以及新老集群流量灰度。
于是参考生产环境在小得物 Ingress 之前加了一层 DLB,通过 location 和 upstream 配置实现流量有生产应用兜底。虽然依赖人工配置,但中间件都是现成的,而且这部分配置变化频率较低,只有应用上下架时需要修改。
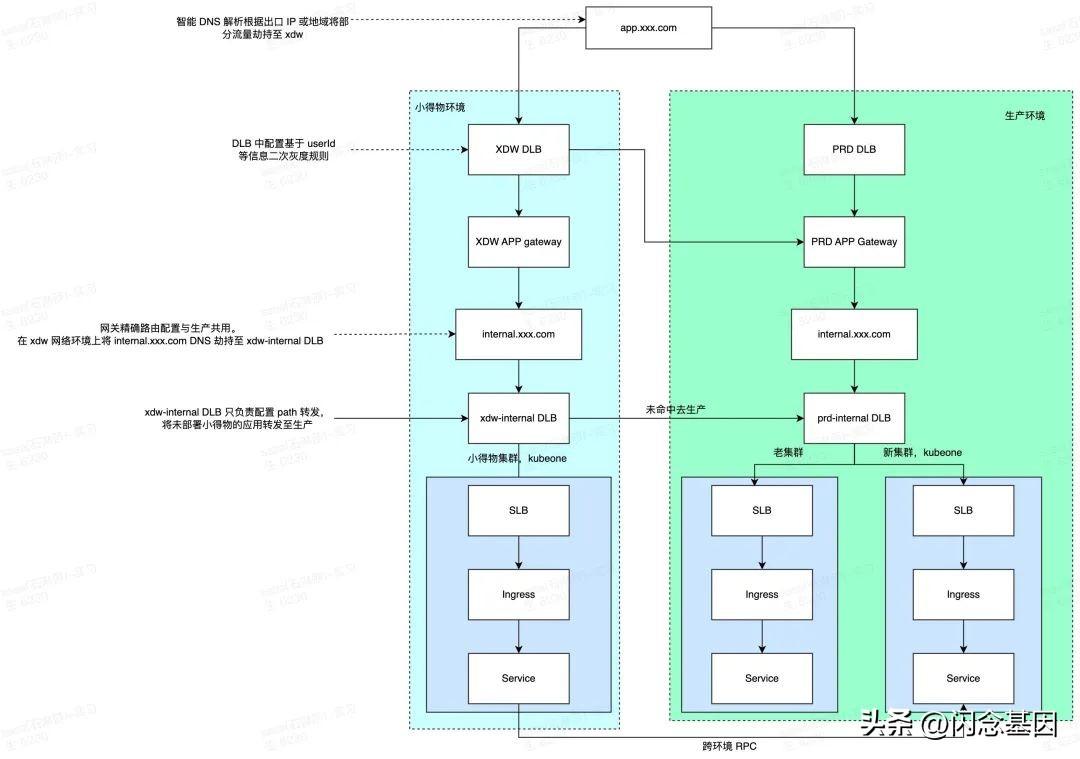
年中时社区第一批约 15 个 C 端应用上线小得物,同时对小得物环境的监控告警等基础设施进行了完善。
2.2 小得物 V2
V1 的核心问题在于引流机制是 DNS。DNS 的优势在于它是在客户端生效,是去中心化的。但也有很多缺点,比如控制维度单一,只有客户端 IP、地域。只依靠这个,灰度流量大小难以精准控制,想要的基于 UID、header 的灰度规则也没法实现。
想要做 UID 灰度引流,一般都是在入口网关上做。灰度配置可能经常需要开关、调整流量大小,如果配置错误或出现 bug,则影响所有流量。
因此想到一个折中的方案,从生产 DLB 根据 UID 引入 5% 灰度流量至小得物 DLB,小得物上再通过二次灰度规则控制流量大小在 0-5%。最大流量限定为 5%,生产只配置一次,后续开关、规则调整均在小得物 DLB 上进行。虽然多用了一个 DLB,但减少生产 DLB 配置变更频率,缩小了爆炸半径。
之前做新老集群迁移的生产 DLB,本来准备下掉,现在正好可以利用起来。对 DLB 进行了版本升级,配置好灰度规则后,就有了现在 V2 的架构。
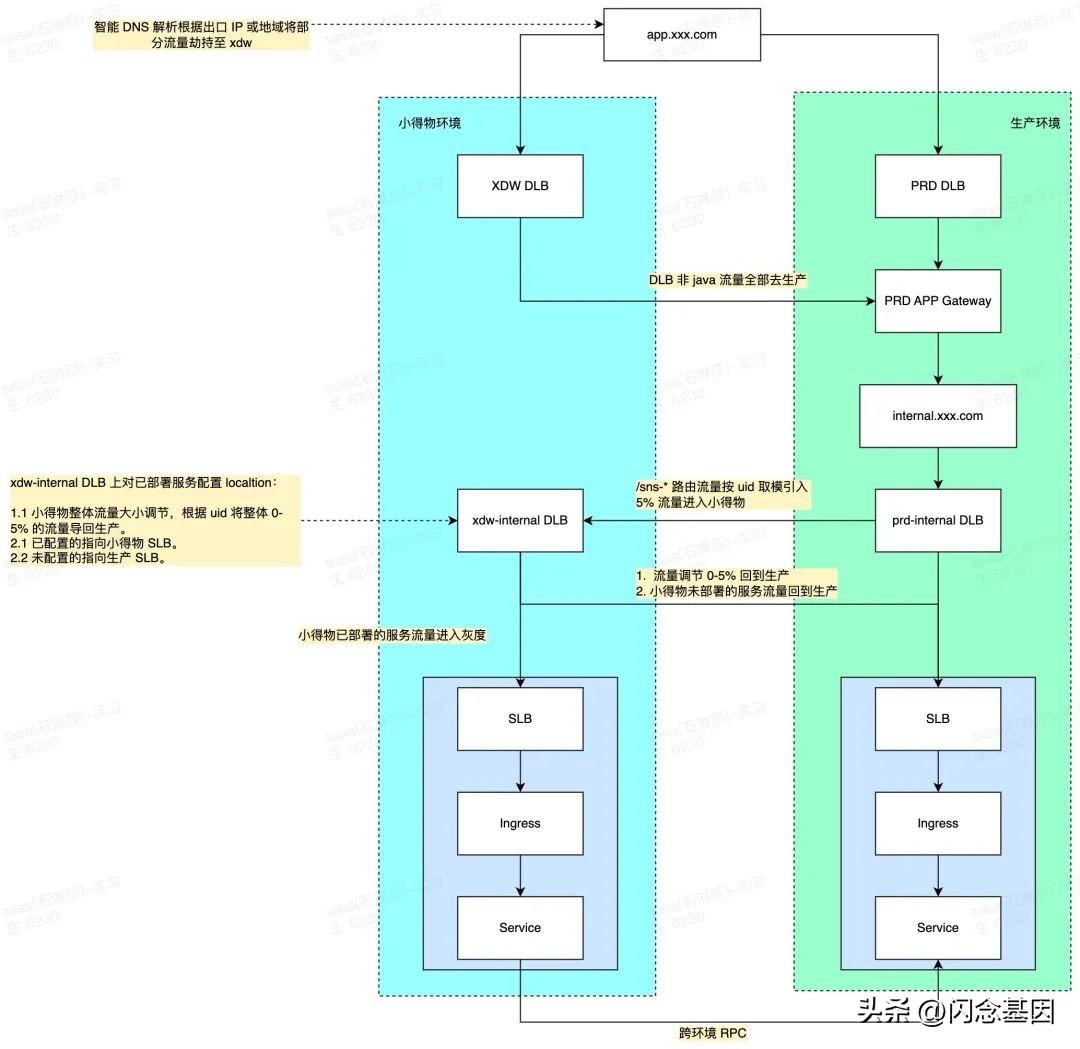
架构升级后:
# uid 路由规则uidRoute: start: 2000 end: 2500# header 头路由规则headerRoute: X-Flow-Flag: xdw3
发布流程优化
3.1 依赖队列自动生成
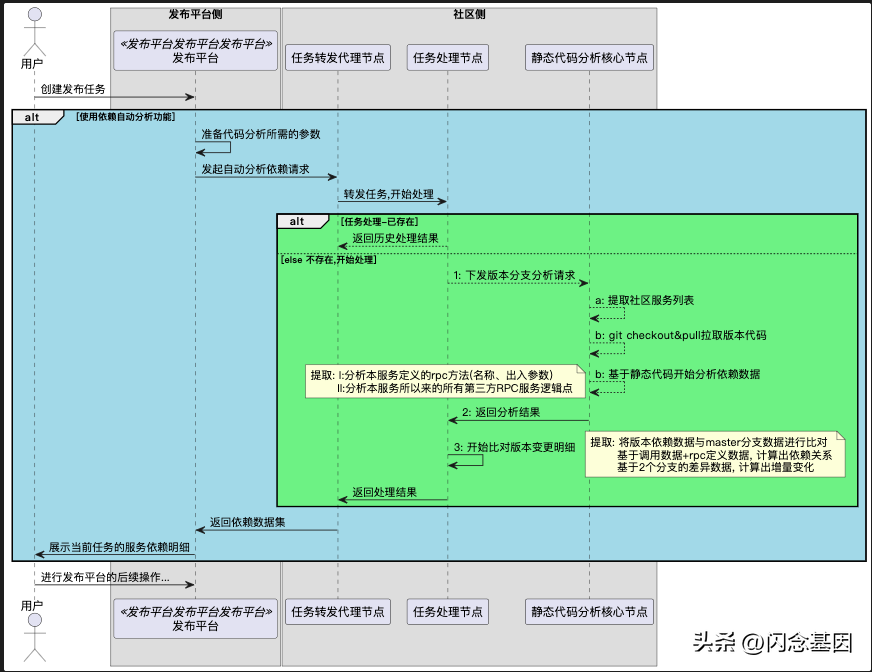
每个版本版本 owner 都需要整理版本清单,标记出应用的依赖关系,最后手动导入到发布平台,生产依赖梯队。
组内大佬觉得这些工作可以自动化完成,便写了一个代码静态分析工具来解决:
可以有人会问,为什么不基于 trace 来做?原因新功能可能没有流量,或是有些路径执行不到,trace 数据需要线上流量跑一段时间才能完整。而通过静态分析,源码中没有秘密,只要是写在代码中的依赖都能覆盖到。这套静态分析工具还可以实现循环调用分析,RPC 圈复杂度分析,帮助开发进行微服务治理。
同时与发布平台打通,发布时触发静态分析,自动生成发布依赖状态图。以前都是版本 owner 手动画这个图,在办公沟通群众同步。通过自动化手段,大幅提高了效率和用户体验。
流程图:
效果图:
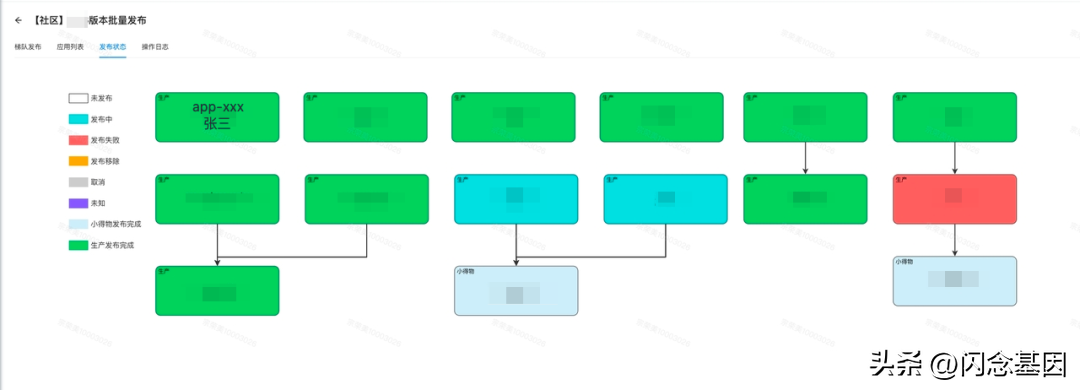
3.2 批量发布、梯度引流、灰度分析
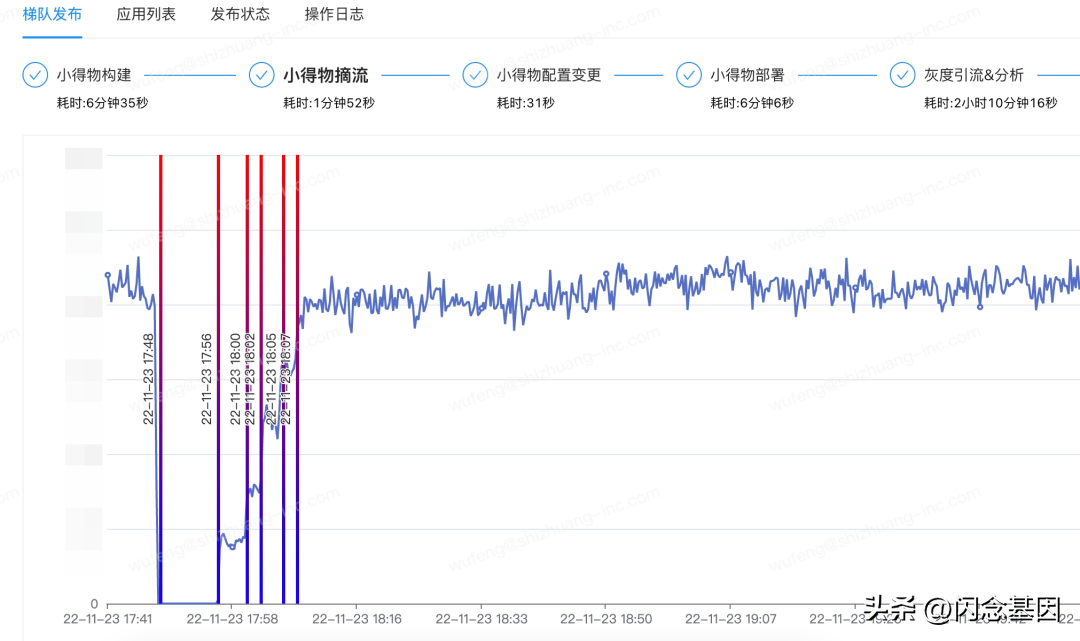
在发布平台和稳定生产小得物团队的帮助下,社区小得物发布使用了新的批量发布流程。
发布时同时支持同时发布 ARK 配置,版本变更在发布平台内完成闭环。不必喊应用 owner 去 ARK 修改配置,再人工确认后,再发布程序代码。

在前文提到的小得物 V2 架构中,灰度流量在社区小得物 DLB 中控制。因此在小得物发布过程中,可以直接通过 openAPI 将小得物流量摘除。没有了流量,就可以无视应用间依赖,直接批量将所有应用并发部署,大幅提高小得物环境部署效率。
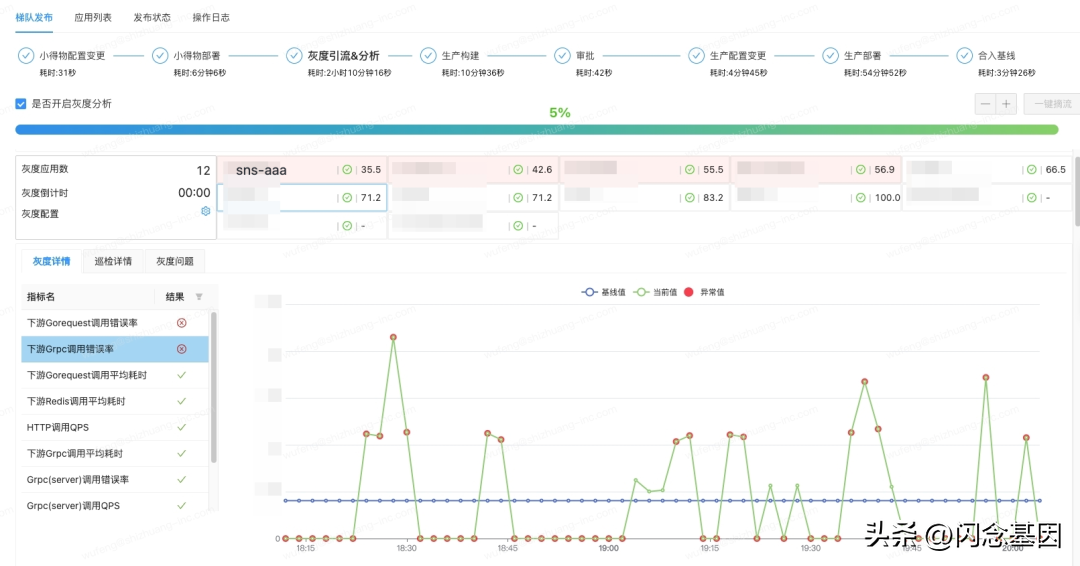
同时摘流后,再通过 API 将流量梯度拉升,从 0% 缓慢提升至 5%,每次引流都会触发稳定生产 SOS 事件中心的自动巡检,根据配置的巡检规则,计算出得分,展示与七天平均值偏差较大的异常点,帮助版本 owner 提前发现灰度问题。
效果图:
4
全链路灰度
4.1 RPC 调用路由
RPC 路由这个功能,大多数据 RPC 调用系统都有。社区目前的 RPC 是基于 grpc-go 扩展实现的,很多人都说 grpc 没有服务治理功能,但实际上 grpc 有着良好的扩展性和丰富的生态。得物 go 框架基于 grpc-go 只用了千余行代码即可实现拥有服务发现、多注册中心、多服务名、地址路由、自定义 interceptor 等完备功能的 RPC 调用系统。
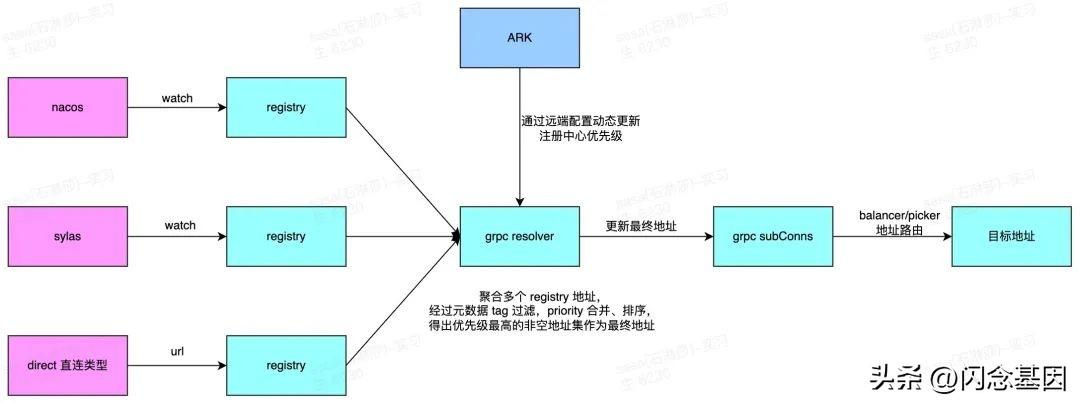
在 grpc resolver 扩展点,在服务发现阶段根据规则过滤调用不包含 xdw 元数据的地址,即可实现服务路由功能。
在 drpc pickers 配置项中配置注册中心元数据表达式 env == "xdw" ,优先路由至小得物节点,在下游服务未部署小得物时兜底至生产节点,保证可用性。
同时为了解决业务应用 RPC 服务名、注册中心地址、路由规则等配置维护困难、且不统一的痛点,我们做了点微创新,参考 Istio 做了一个中心配置下发,懒加载的功能。
在所有应用中都相同的注册中心地址、服务名配置维护在控制中心配置中。server 会查找与 target 同名的 service 作为服务名注册,client 根据 target 名来查找服务名,只有被客户端桩代码实际调用的服务才会被 watch。
应用配置只需要引用 drpc 控制中心配置地址即可,pickers 路由规则可以统一下发到所有服务。而像超时等个性化配置应用端可以覆盖远端,框架会将其做合并处理。
控制中心远端配置:
metadata: env: xdwregistries: # grpc 协议 nacos-grpc: type: nacos-grpc url: http://xdw.xxx.com:80 priority: 11 # http 协议 nacos-http: type: nacos-http url: http://xdw.xxx.com:80 priority: 11 # 备用注册中心 nacos-bak: type: nacos-grpc url: http://bak.xxx.com:80 priority: 11 # java 服务 java-nacos: type: java-dubbo url: http://java.xxx.com:80 priority: 11 multi-nacos: type: ref refs: # 多注册中心引用 - nacos-grpc - nacos-bak direct: type: direct priority: 15client: requestTimeout: 700 pickers: - target: "*" desc: "优先使用小得物地址" match: tag: env == "xdw" - target: "*" desc: "兜底,无小得物地址时使用所有地址" match: tag: "*" targetMap: sns-aaa: services: # 多服务名 - registryName: muilti-nacos serviceName: sns-aaa - registryName: nacos-http serviceName: sns-aaa-http sns-bbb: services: - registryName: muilti-nacos serviceName: sns-bbb # java dubbo 服务 java-ccc: services: - registryName: java-nacos serviceName: "com.xxx.DubboTestGrpcServiceGrpc$ITestGrpcService:1.0:" # 直连地址 direct-ddd: services: - registryName: direct serviceName: ddd.xxx.com:8080应用端配置:
drpc: remoteConfig: type: ark url: https://ark.xxx.com?ns=XDW&cf=drpc.yaml client: targetMap: sns-aaa: # 超时配置 methodTimeout: AaaService/FooMethod: 100 sns-bbb: methodTimeout: BbbService/BarMethod: 504.2 MQ 消息路由
社区小得物与生产环境公用一套 DB、 MQ 中间件。应用代码中 MQ producer、comsuer,HTTP、GRPC API 是在一个进程中。如果消息没有隔离逻辑,小得物打开消费,则会与生产节点成为同级消费者,消费生产消息。而小得物环境机器配置较低,消费速度慢会影响业务。
在没有 MQ 消息隔离前,采取一个笨办法,直接关闭小得物 MQ 消费。但这样小得物的消息是靠生产处理,在小得物有 MQ 相关新版本变更时,需要考虑新老兼容的问题。
随着社区阿里云 MQ 迁移 DMQ 进入收尾阶段,DMQ Go SDK 也趋于稳定,开始尝试使用程序化方案解决 MQ 灰度消费的问题。
最开始跟小得物团队了解了一下最初的方案,小得物和生产使用不同的 MQ 实例,这样就要求 producer、consumer 在小得物全量部署。对于跨业务域的 topic 需要消息同步机制。感觉复杂度过高,资源成本和维护成本都很高。
后面看到一篇 阿里云分享的 RocketMQ 灰度方案,其采用消息打标、group 隔离、SQL 属性过滤实现消息灰度,感觉这才是理想的方案。
这里说一下 tag 过滤和 SQL 过滤,tag 过滤大家比较常用,但一条消息只能有一个 tag,常被业务占用,且不能支持 != 这样的条件。而 SQL 过滤就灵活得多,可以使用消息 properties 自定义 kv 键值对,SQL 的 NOT、BETWEEN、IN 等关键词都可以使用。
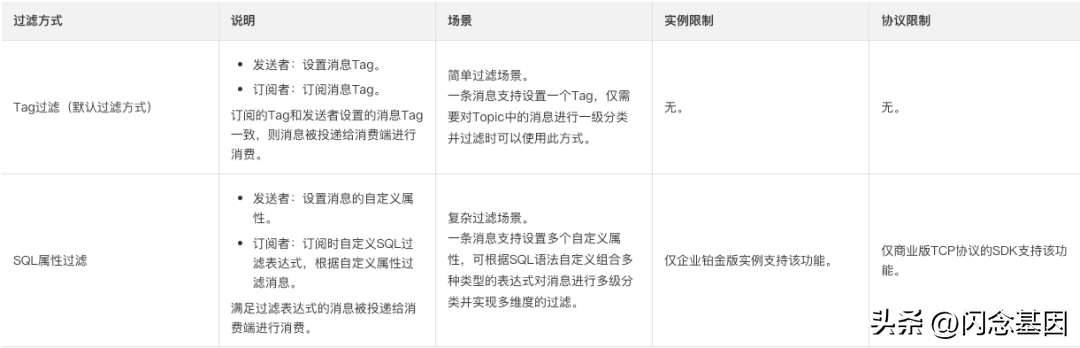
找中间件团队沟通,他们表示 SQL 过滤性能较差,暂不支持。建议使用 Java 染色环境类似的方案,在客户端过滤。虽然客户端过滤,有很多无效的网络传输,但成本较低,只需要改造一下业务框架中 MQ SDK 即可,也能解决 MQ 灰度的问题。经过压测,小得物环境过滤生产环境高 QPS 生产的消息或是 group 积压的大量消息, 对应用不会造成较大的性能影响,于是采用了此方案。
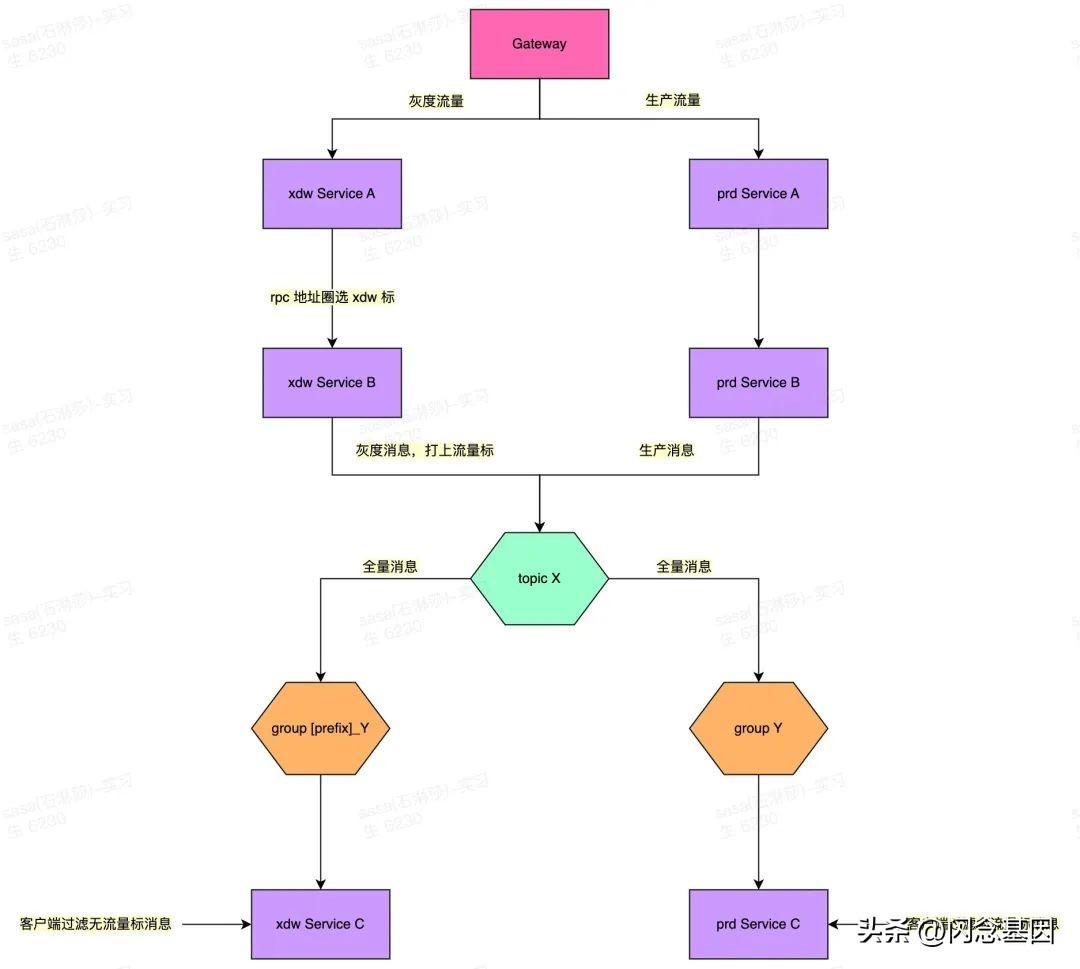
consumer 消费的隔离比较简单,MQ 的机制是不同 group 消息消费都是独立的,每个 group 都能收到topic 全量消息。
在业务框架中根据染色环境配置,增加不同的处理逻辑。
如果是染色环境(小得物):
trafficRoute: colorEnv: xdw如果是基准环境(生产):
trafficRoute: excludeEnvList: [xdw]事务消息比较特殊,主要体现在 trans producer 有一个回查逻辑。trans producer 不光会向 server 发消息,还会接受 server 发送的回查消息。
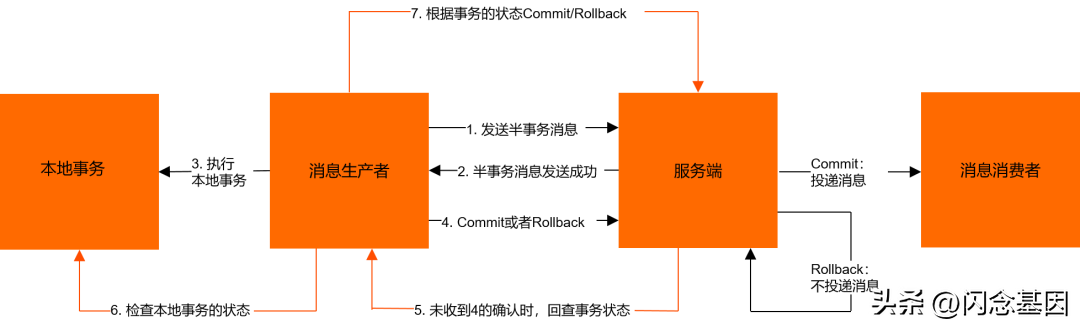
查看了一下 DMQ 的 Java 源码,发现 Boroker 回查时是通过消息 properties 中的 group 来查找在线 producer。那么跟 consumer 类似,给 trans producer 配上 group ,给小得物 group 加上环境前缀即可实现事务回查隔离。用于 trans producer 的 group 只是一个标识,甚至不需要在 DMQ 后台申请。
5
总结
目前社区已经通过小得物灰度环境的运营取得一些收益:
但社区灰度环境只解决了部分问题,还有很多技术难点、体验优化、流程规范待完善,例如:
革命尚未成功,同志仍需努力!
作者:无风
来源:微信公众号:得物技术
出处
:https://mp.weixin.qq.com/s/ZTWI6Oade6vwyw3pRonBag
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号