数据结构:基本概念与算法解析
发表时间: 2021-03-04 16:15
本文非原创,内容来自cnblogs的【湫兮如风】(
https://www.cnblogs.com/qiuxirufeng/p/10391938.html) 数据结构系列博文,写得真的非常棒,可以去看看,所以小编我也是一边学,一遍与大家分享,如有不足之处,还请大家多多指教,谢谢
数据(Data):信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。例如在生活中,我们的身份信息、看到的图片、听到的音乐都可以作为数据来进行输入和处理。
数据对象:具有相同性质的数据元素的集合,是数据的一个子集。例如把所有人的身份信息作为一个数据对象。
数据元素(Data Element):数据的基本单位,通常作为一个整体进行考虑和处理。例如每一个人的身份信息可能就是一个数据元素。
数据项(Data Item):构成数据元素的不可分割的最小单位。在身份信息中,有姓名、有身份证编号,这样的信息就是数据元素中的数据项。
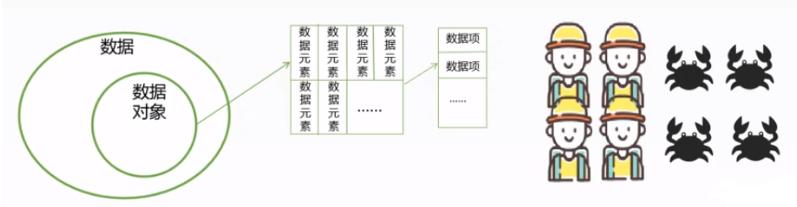
例如,上图是具有人物和螃蟹的数据的集合。其中所有的人物就是一个数据对象,它是具有相同性质的数据元素的集合;每一个人物都是一个数据元素,可能在该人物当中,帽子的颜色、书包的颜色都可以作为数据项。从数据-->数据对象-->数据元素-->数据项,这是一个将抽象一步步实例化的过程。
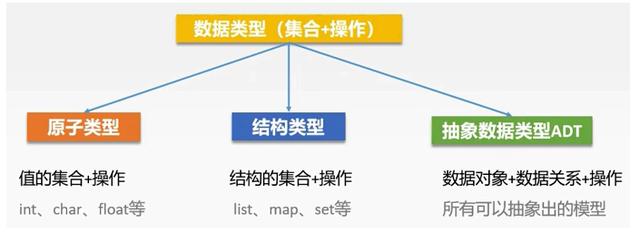
数据类型:是一组值的集合和定义在该集合上的操作的总和。其中有原子类型,原子就是不可再分割的意思,它是原子类型值的集合和定义在该集合上的操作。例如在 C 语言中的 int、char、float 等都是原子类型。除了原子类型,还有结构类型,它是结构的集合和定义在集合上的操作。结构就是多个原子类型值的组合,其中有 list、map、set 等。最后还有抽象数据类型,它是数据模型以及定义在该数据模型上的操作,可以用一个三元组来表示,分别是数据对象、数据关系和相关的操作。对于抽象数据类型,只考虑它的逻辑特性,具体的内部实现是不考虑的。例如在生活中所有的人、汽车都可以把它抽象出来作为一种抽象数据类型。
什么叫数据结构,简单地说就是数据元素之间的关系,以一张成绩单为例
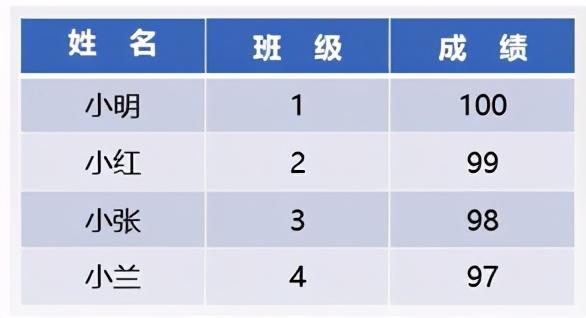
这是一张成绩单,如果把这张成绩单叫做一个数据对象的话,那么每一个人所有的信息是一个数据元素,而每一个人的姓名可以称作为一个数据项。这张表还有类似于小明排在小红前面这样的关系,这样的关系就是所说的结构。能称之为结构:就说明数据不是孤立存在的,它们存在着某种关系,这种相互的关系我们叫做结构。这样就有了数据结构的一个概念。数据结构是相互之间存在一种或多种特定关系的数据元素的集合。数据接口三个要素:逻辑结构、物理结构、数据的运算。
逻辑结构是指数据元素之间的逻辑关系,它更贴近于现实,即从逻辑关系上来描述数据。它是独立于计算机的,与计算机内部如何存储是无关的。在逻辑结构中,具体分为四种:线性结构、集合、树形结构、图状结构。其中,把集合、树形结构、图状结构统称为非线性结构。
存储结构是指数据结构在计算机内的存储方法,也称为物理结构。它既包括数据元素本身的表示,也包括数据元素之间关系的表示。存储结构也分为四种:顺序存储、链式存储、索引存储、散列存储。
顺序存储:数据在内存当中,会把它存放在一个一个的存储单元之中,而顺序存储的意思是指在逻辑上相邻的元素在物理存储上也让它相邻。
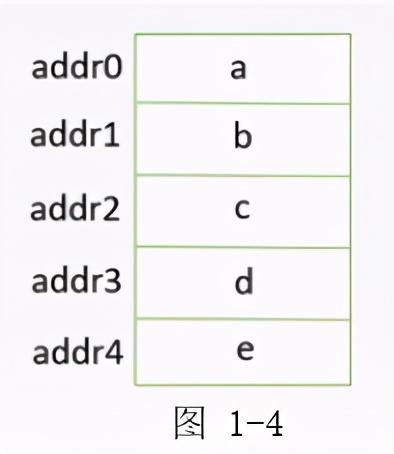
例如,a、b、c、d、e 五个元素在逻辑上是相邻的,那么把它存放到存储单元之中也让它相邻。顺序存储元素之间的关系是通过物理位置相邻来体现的,其最大的好处就是可以实现随机存储,在知道第一个单元的位置时,通过简单运算,根据它相邻的特性也就知道其后所有元素的数据位置。
链式存储:链式存储是指在逻辑上相邻的元素,在物理存储位置上是不相邻的。链式存储通过名字来看,它有一个链接的含义,它在具体的实现上也是利用这样一个具体操作的。
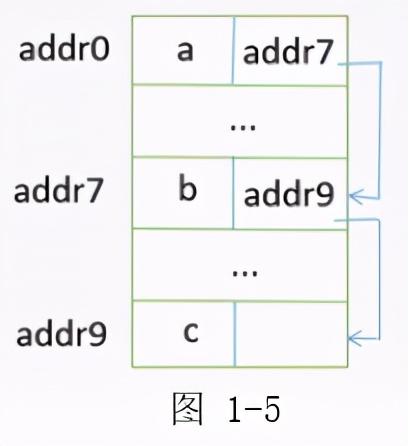
存放数据元素 a 的位置同时后面也存放了下一个元素的地址,通过这个地址来体现元素之间的关系达到一个指针的效果。在链式存储当中,每一个数据元素存放的物理单元位置是不确定的,它们的距离可能很远也可能很近,无法通过顺序存储那样的手段来找到下一个元素的位置。但是在链式存储中,是通过指针来表示相邻元素的关系的。所以在存取手段上,要通过指针来找到下一个元素的位置。所以在链式存储中只能实现顺序存储而无法实现随机存储。
例如在图 1-4 中 a、b、c 三个元素在逻辑上是相连的,假设它是顺序存取的,那么想要找到 c 这个元素,就可以通过锁定 addr2 找到了,因为它在逻辑单元上是连续存放的。而在图 1-5 中,首先通过存放 a 元素的存储单元知道下一个存储单元的地址是 addr7 ,找到了 b 的位置之后,再通过 b 存储单元中 c 的指针,也就是 addr9 找到了 c,只有这样以此的查找才能找到 c 的位置。
索引存储:索引存储在内存中不仅仅要存放每一个数据元素,还要建立一张索引表。在索引表中有一个个索引项,每一个索引项都存放两个信息,一个是关键字,另一个是该关键字查找数据对应的地址。
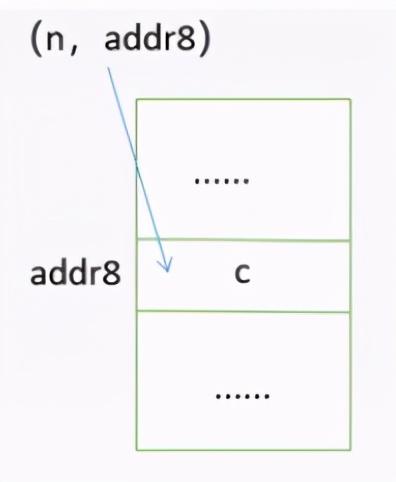
例如,想要锁定 c 在存储单元中的位置,通过关键字 n 找到了 c 对应的存储单元地址是 addr8 。通过这样一个个索引项可以非常快速地找到对应存储数据的地址。但是,索引存储有一个缺点,就是既要存放数据元素,又要存放索引表,在存放索引表的时候会消耗内存资源。
散列存储:散列存储也称为哈希存储,它是通过关键字的相应函数运算直接求得对应数据元素的地址
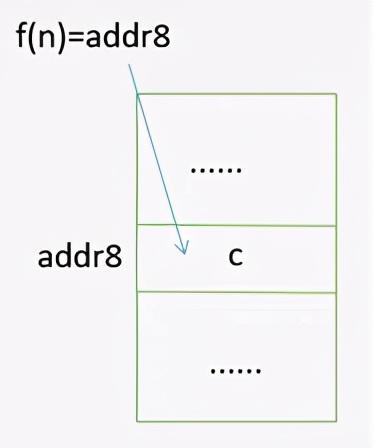
例如,通过 f(n) 的这个函数运算直接求得数据元素 c 的存放地址 addr8 。它的查找速度也是非常快的。
数据的运算包括运算的定义和实现方式,运算的定义针对逻辑结构,运算的实现针对存储结构。
例如:现在有这样一个简单的逻辑结构,其中 C 是 A 的后继节点,B 是 C 的后继节点,为了理解对应关系,设计了这样一个存储结构,数据元素 A 存放在了地址单元当中的 addr0 ,数据元素 B 存放在了 addr1 ,数据元素 C 存放在了 addr2 。现在要实现的运算是找到 A 的下一个节点。可以发现,在这个例子中,A 的下一个节点是有所不同的

根据上述的概念,运算的定义针对逻辑结构,找到的 A 的下一个节点是 C,运算的实现针对存储结构,找到的 A 的下一个节点是 B,所以说不同的结构,数据的运算也是不同的。
数据结构是一个二元组,形式定义如下:
Data_Structures=(D, S)
其中,D是数据元素的集合,S是D上的关系集合 (也可以理解成D是数据元素的有限集,S是D上关系的有限集)
算法即对特定问题求解步骤的一种描述,它是指令的有限序列,其中的每条指令表示一个或多个操作。根据以上定义,可以知道,算法一定是可以解决特定问题的,其次,它是有限的,然后,每一个指令都表示特定的操作。
算法为什么是有穷的?在操作系统中使用了很多无穷的代码语句,它们也是非常有用的,它们不是算法,那它们又是什么?对此,引入了一个程序的概念,什么是算法,什么又是程序?根据上面的算法的定义,可以知道,算法是解决问题的一种方法或一个过程,例如如何将输入转换成输出。一个问题可以有很多不同的算法。而程序是某种程序设计语言对算法的具体实现。我们可以用 C 语言来编写,也可以用 Python 语言来编写,只要是在计算机内部运行的程序设计语言都可以。这是对算法和程序的简单描述。我们发现,算法更像一个解决问题的 “指导者”,而程序更像一个具体实现的 “实施者”,可以利用算法来指导程序的编写和实施。算法和程序主要有三方面的区别:
如何设计一个 "好" 的算法?
在学习时间复杂度之前,先掌握两个概念:语句的频度、T(n)
语句频度:该条语句可能重复执行的次数
T(n):所有语句的频度之和,其中 n 为问题的规模
int sum = 0; for(int i=1; i<=n; i++) sum += i;第一句是初始化 sum 为 0,它的语句频度是 1,因为它只被执行了一次。第二个是循环体中的语句 sum += i 根据它的判断条件,可以知道它执行了 n 次,所以该条语句的语句频度是 n。那么该段代码的语句频度之和就是 T(n)=1+n 。时间复杂度:记作 T(n) = O(f(n)) ,其中 O 表示 T(n) 与 f(n) 在 n 趋向于正无穷时为同阶无穷大,可以把 f(n) 理解为某一个数量级或者是当 n 趋于正无穷时的一种增长率。根据同阶无穷大的知识,可以知道:
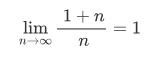
如果两个无穷大在趋近于∞时比值的极限等于一个不等于0的常数,那么这两个无穷大就是同阶无穷大
时间复杂度有三种分类:最坏时间复杂度、最好时间复杂度、平均时间复杂度
int sum = 0; if(n != 0) for(int i=1; i<=n; i++) sum += i;这段代码中,如果 n 不等于 0 ,它的 T(n) = 1 + n,它的时间复杂度为 O(n) ,如果当 n 等于 0 ,它仅仅执行了第一条语句,也就是说它的 T(n) = 1,则它的时间复杂度为 O(1) 。所以说在不同的判断中,时间复杂度是不同的,所以有最坏和最好之分,平均时间复杂度就是在所有输入的概率的情况下,求一个时间复杂度的期望值。在分析一个算法时, 往往会使用最坏时间复杂度,这个是最具有实际意义的。学习了时间复杂度的分类后,来看一下时间复杂度在运算上有怎样的规则。
加法规则:当对两个时间复杂度进行求和运算时,可以将较大数量级的代码的时间复杂度作为它们的和,可以通过同阶无穷大来进行验证
T(n) = T1(n)+T2(n)
= O(f(n))+O(g(n))
=O(max(f(n),g(n)))
乘法规则:两个时间复杂度的乘积可以使它先对数量级进行乘积再求同阶无穷大
T(n) = T1(n)*T2(n)
= O(f(n))*O(g(n))
= O(f(n)*g(n))
通常采用基本运算频度来分析算法时间复杂度,基本运算频度也就是指最深层的循环语句的频度。
int sum = 0;for(int i=1; i<=n; i++) sum += i;for(int i=1; i<=n; i++) for(int j=1; j<=n; i++) sum += i;这段代码中,第一句的语句频度是 1,然后第三句循环执行 n 次,语句频度是 n,第四句第五句是一个双层循环,并且都是循环 n 次,因此它的语句频度是n^2 ,所以这段代码的 T(n) = 1 + n + n^2。根据加法规则,它的时间复杂度是 O(n2) 。它的最深层的循环语句的时间复杂度为 O(n2) ,采用基本运算频度来分析算法时间复杂度,也可以得出它的时间复杂度是 O(n2) 。
常见时间复杂度
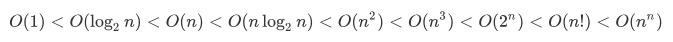
三种最常见时间复杂度描述
O(1): 常量级
O(n): 线性级
O(n2):平方级
空间复杂度
算法的空间复杂度是指算法消耗的存储空间(一般是算法执行过程中所需的最大空间),记作 S(n) = O(g(n)) ,O 表示同阶无穷大,g(n) 表示数量级,n 代表问题规模。在计算算法空间复杂度时,要注意一点,就是什么是消耗的存储空间,它是除本身所用的指令、常数、变量和输入数据外的辅助空间。算法原地工作时指算法所需辅助空间为常量,记作 O(1)
估算方法:输入数据所占空间+程序所占空间+辅助变量所占空间
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号