抖音Android性能优化指南:启动优化实战
发表时间: 2022-03-28 16:38
启动性能是 APP 使用体验的门面,启动过程耗时较长很可能使用户削减使用 APP 的兴趣,抖音通过对启动性能做劣化实验也验证了其对于业务指标有显著影响。抖音有数亿的日活,启动耗时几百毫秒的增长就可能带来成千上万用户的留存缩减,因此,启动性能的优化成为了抖音 Android 基础技术团队在体验优化方向上的重中之重。
在上一篇抖音 Android 性能优化系列:启动优化之理论和工具篇中,已经从原理、方法论、工具的角度对抖音的启动性能优化进行了介绍,本文将从实践的角度通过具体的案例分析介绍抖音启动优化的方案与思路。
启动是指用户从点击 icon 到看到页面首帧的整个过程,启动优化的目标就是减少这一过程的耗时。
启动过程比较复杂,在进程与线程维度,它涉及到多次跨进程的通信与多个线程之间的切换;在耗时成因维度,它包括 CPU、CPU 调度、IO、锁等待等多类耗时。虽然启动过程比较复杂,但是我们最终可以把它抽象成主线程的一个线性过程。因此对于启动性能的优化,就是去缩短主线程的这个线性过程。
接下来,我们将按照主线程直接优化、后台线程间接优化、全局优化的逻辑,介绍团队在启动优化的实践中遇到的一些比较典型的案例,其间对于业界一些比较优秀的方案也会进行简要介绍。
对于主线程的优化,我们将按照生命周期先后的顺序展开介绍。
首先我们来看第一个阶段,也就是 Application 的 attachBaseContext 阶段。这个阶段由于 Applicaiton Context 赋值等问题,一般不会有太多的业务代码,预期中也不会有多少耗时。但在实际测试过程中,我们发现在某些机型上,应用安装后的首次启动耗时非常严重,经过初步定位,主要耗时在MultiDex.install。

在经过详细分析后,我们确定该问题集中在4.x的机型上,其影响首次安装及后续更新后的首次启动。
造成这一问题的原因为:dex 的指令格式设计并不完善,单个 dex 文件中引用的 Java 方法总数不能超过 65536 个,在方法数超过 65536 的情况下,将拆分成多个 dex。一般情况下 Dalvik 虚拟机只能执行经过优化后的 odex 文件,在 4.x 设备上为了提升应用安装速度,其在安装阶段仅会对应用的首个 dex 进行优化。对于非首个 dex 其会在首次运行调用 MultiDex.install 时进行优化,而这个优化是非常耗时的,这就造成了 4.x 设备上首次启动慢的问题。
造成这个问题的必要条件有多个,它们分别是:dex 被拆分成多个 dex 文件、安装过程中仅对首个 dex 进行的优化、启动阶段调用 MultiDex.install 以及 Dalvik 虚拟机需要加载 odex。
很明显前两个条件我们是没办法破坏的——对于抖音来说,我们很难将其优化成只有单 dex,系统的安装过程我们也无法改变。启动阶段调用MultiDex.install这个条件也比较难以破坏——首先,随着业务的膨胀我们很难做到用一个 dex 去承载启动阶段的代码;其次,即使做到了后续也比较难以维护。
因此我们选择破坏“Dalvik 虚拟机需要加载 odex”这一限制,即绕过 Dalvik 的限制直接加载未经优化的 dex。这个方案的核心在 Dalvik_dalvik_system_DexFile_openDexFile_bytearray 这个 native 函数,它支持加载未经优化后的 dex 文件。具体的优化方案如下:
关于 MutilDex 优化的更多细节可以参照之前的一篇公众号文章,目前该方案已经开源,具体见该项目的 github 地址(https://github.com/bytedance/BoostMultiDex)。
接下来介绍的是ContentProvider的相关优化,ContentProvider 作为 Android 四大组件之一,其在生命周期方面有着独特性——Activity、Service、BroadcastReceiver 这三大组件都只有在它们被调用到时,才会进行实例化,并执行它们的生命周期;ContentProvider 即使在没有被调用到,也会在启动阶段被自动实例化并执行相关的生命周期。在进程的初始化阶段调用完 Application 的 attachBaseContext 方法后,会再去执行 installContentProviders 方法,对当前进程的所有 ContentProvider 进行 install。
这个过程将会对当前进程的所有 ContentProvider 通过 for 循环的方式逐一进行实例化、调用它们的 attachInfo 与 onCreate 生命周期方法,最后将这些 ContentProvider 关联的 ContentProviderHolder 一次性 publish 到 AMS 进程。

ContentProvider 这种在进程初始化阶段自动初始化的特性,使得在其作为跨进程通信组件的同时,也被一些模块用来进行自动初始化,这其中最为典型的就是官方的 Lifecycle 组件,其初始化就是借助了一个叫 ProcessLifecycleOwnerInitializer 的 ContentProvider 进行初始化的。
LifeCycle 的初始化只是进行了 Activity 的 LifecycleCallbacks 的注册耗时不多,我们在逻辑层面上不需要做太多的优化。值得注意的是,如果这类用于进行初始化的 ContentProvider 非常多,ContentProvider 本身的创建、生命周期执行等堆积起来也会非常耗时。针对这个问题,我们可以通过 JetPack 提供的 Startup 将多个初始化的 ContentProvider 聚合成一个来进行优化。
除了这类耗时很少的 ContentProvider,在实际优化过程中我们也发现了一些耗时较长的 ContentProvider,这里大致介绍一下我们的优化思路。
public class ProcessLifecycleOwnerInitializer extends ContentProvider { @Override public boolean onCreate() { LifecycleDispatcher.init(getContext()); ProcessLifecycleOwner.init(getContext()); return true; }}对于我们自己的 ContentProvider,如果初始化耗时我们可以通过重构的方式将自动初始化改为按需初始化。对于一些三方甚至是官方的 ContentProvider,则无法直接通过重构的方式进行优化。这里以官方的 FileProvider 为例,来介绍我们的优化思路。
FileProvider 使用
FileProvider 是 Android7.0 引入的用于进行文件访问权限控制的组件,在引入 FileProvider 之前我们对于拍照等一些跨进程的文件操作,是以直接传递文件 Uri 的方式进行的;在引入 FileProvider 后,我们的整个过程则为:
耗时分析
从上面的过程来看,只要我们在启动阶段没有 FileProvider 的调用,是不会有 FileProvider 的相关耗时的。但实际上从启动 trace 来看,我们的启动阶段是存在 FileProvider 相关耗时的,具体的耗时则是在 FileProvider 的生命周期方法 attachInfo 方法中,FileProvider 的 attachInfo 方法除了会去调用我们最为熟悉的 onCreate 方法,同时还会去调用 getPathStrategy 方法,我们的耗时则是集中在这个 getPathStrategy 方法中。
从实现来看, getPathStrategy 方法主要是进行 FileProvider 关联 xml 文件的解析,解析结果将会赋值给 mStrategy 变量。进一步分析我们会发现 mStrategy 会在 FileProvider 的 query、getType、openFile 等接口进行文件路径校验时用到,而我们的 query、getType、openFile 等接口在启动阶段是不会被调用到的,因此 FileProvider attachInfo 方法中的 getPathStrategy 是完全没有必要的,我们完全可以在 query、getType、openFile 等接口被调用到的时候再去执行 getPathStrategy 逻辑。

优化方案
FileProvider 是 androidx 中的代码,我们无法直接修改,但是它会参与我们的代码编译,我们可以在编译阶段通过修改字节码的方式去修改它的实现,具体的实现方案为:
public void attachInfo(@NonNull Context context, @NonNull ProviderInfo info) { super.attachInfo(context, info); // Sanity check our security if (info.exported) { throw new SecurityException("Provider must not be exported"); } if (!info.grantUriPermissions) { throw new SecurityException("Provider must grant uri permissions"); } mStrategy = getPathStrategy(context, info.authority);}2. 对 FileProvider 的 query、getType、openFile 等方法进行插桩,在调用原方法之前首先进行 getPathStrategy 的初始化,完成初始化之后再调用原始实现。
单个 FileProvider 的耗时虽然不多,但是对于一些大型的 app,为了模块解耦其可能会有多个 FileProvider,在这种情况下 FileProvider 优化的收益还是比较可观的。与 FileProvider 类似,Google 提供的 WorkManager 也会存在初始化的 ContentProvider,我们可以采用类似的方式进行优化。
启动的第三个阶段是 Application 的 onCreate 阶段,这个阶段是启动任务执行的高峰阶段,该阶段的优化就是针对各类启动任务的优化,具有极强的业务关联性,这里简单介绍一下我们优化的大概思路。

抖音启动任务优化的核心思想是代码价值最大化和资源利用率最大化。其中代码价值最大化主要是确定哪些任务应该在启动阶段执行,它的核心目标是将不应该在启动阶段执行的任务从启动阶段去除掉;资源利用率最大化则是在启动阶段任务已经确定的情况下,尽可能多的去利用系统资源以达到减少任务执行耗时的目的。对于单个任务而言,我们需要去优化它的内部实现,减少它本身的资源消耗以提供更多资源给其他任务执行,对于多个任务则是通过合理的调度以充分利用系统的资源。
从落地角度而言我们主要围绕两个事情开展:启动任务重构与任务调度。
启动任务重构
由于业务复杂度较高且前期对启动任务的管控较为宽松,抖音启动阶段的任务有超过 300 个,这种情况下对启动阶段的任务进行调度能够在一定程度上提升启动速度,但是仍然比较难将启动速度提升到一个较高的水平,因此启动优化中非常重要的一个方向就是减少启动任务。
为此我们将启动任务分成了配置任务、预加载任务和功能任务三大类。其中配置任务主要用于对各类 sdk 进行初始化,在它没有执行之前相关的 sdk 是无法工作的;预加载任务主要是为了对后续的某些功能进行预热,以提升后续功能的执行速度;功能任务则是在进程启动这一生命周期执行的与功能相关的任务。对于这三类任务我们采用了不同的改造方式:
任务调度
关于任务调度业界有过比较多的介绍,这里对于任务的依赖分析、任务排布等不再进行介绍,主要介绍抖音在实践过程中一些可能的创新点:
之前的几个阶段都属于 Application 阶段,接下来看一下 Activity 阶段的相关优化,这个阶段我们将介绍 Splash 与 Main 合并、反序列化优化两个典型例子。

首先来看一下 SplashActivity 与 MainActivity 的合并,在之前的版本中抖音的 launcher activity 是 SplashActivity,它主要承载着广告、活动等开屏相关逻辑。一般情况下我们的启动流程为:
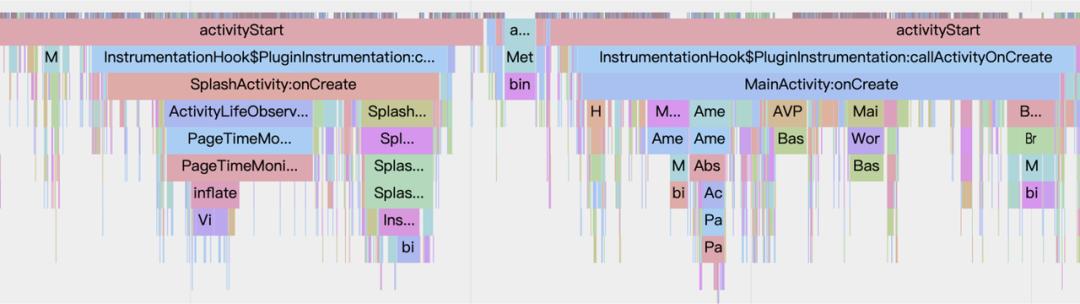
在这个流程下,我们的启动需要经历两个 Activity 的启动,如果把这两个 Activity 进行合并,我们可以取得两方面的收益:
要实现 Splash 与 Main 合并,我们需要解决的问题主要有 2 个:
第 1 个问题比较容易解决,我们可以通过 activity-alias+targetActivity 将 SplashActivity 指向 MainActivity 解决。接下来我们来看一下第二个问题。

launchMode 问题
在 Splash 与 Main 合并之前,SplashActivity 与 MainActivity 的 LaunchMode 分别是 standard 和 sinngletask,这种情况下我们能够确保 MainActivity 只有一个 实例,并且在我们从应用 home 出去再次进入时,能够重新回到之前的页面。
将 SplashActivity 与 MainActivity 合并以后,我们的 launcher Activity 变成了 MainActivity,如果继续使用 singletask 这个 launchMode,当我们从二级页面 home 出去再次点击 icon 进入时,我们将无法回到二级页面,而会回到 Main 页面,因此合并后 MainActivity 的 launch mode 将不再能够使用 singletask。经过调研,我们最终选择了使用 singletop 作为我们的 launchMode。
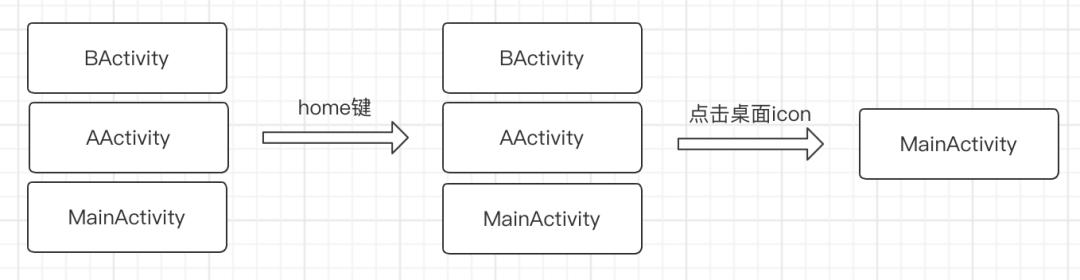
多实例问题
1、内部启动多实例的问题
使用 singletop 虽然能够解决 home 出去再次进入无法回到之前页面的问题,但是随之而来的是 MainActivity 多实例的问题。在抖音的逻辑中存在一些与 MainActivity 生命周期强关联的逻辑,如果 MainActivity 存在多个实例,这部分逻辑将会受到影响,同时多个 MainActivity 的实现,也会导致我们不必要的资源开销,与预期是不符的,因此我们希望能够解决这个问题。
针对这个问题我们的解决方案是,对于应用内所有启动 MainActivity 的 Intent 增加 FLAG_ACTIVITY_NEW_TASK 与 FLAG_ACTIVITY_CLEAR_TOP 的 flag,以实现类似于 singletask 的 clear top 的特性。
使用 FLAG_ACTIVITY_NEW_TASK + FLAG_ACTIVITY_CLEAR_TOP 的方案,我们基本能够解决内部启动 MainActivity 多实例的问题,但是实际测试过程中,我们发现在部分系统上,即使实现了 clear top 的特性,依然存在多实例的问题。
经过分析,我们发现在这部分系统上,即使通过 activity-alias+targetActivity 方式将 SplashActivity 指向了 MainActivity,但是在 AMS 侧它仍然认为启动的是 SplashActivity,后续再启动 MainActivity 时会认为之前是不存在 MainActivity 的,因此会再次启动一个 MainActivity。
针对这个问题我们的解决方案是,修改启动 MainActivity Intent 的 Component 信息,将其改从 MainActivity 改为 SplashActivity,这样我们就彻底解决了内部启动 MainActivity 导致的多实例的问题。
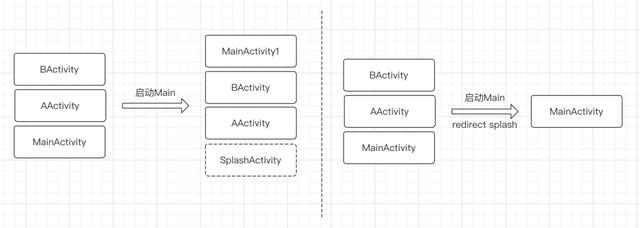
为了尽可能少的侵入业务,同时也防止后续迭代再出现内部启动导致 MainActivity 问题,我们对 Context startActivity 的调用进行了插桩。对于启动 MainActivity 的调用,在完成向 Intent 中添加 flag 和替换 Component 信息后再调用原有实现。之所以选择插桩方式实现,是因为抖音的代码结构比较复杂,存在多个基类 Activity,且部分基类 Activity 无法直接修改到代码。对于没有这方面问题的业务,可以通过重写基类 Activtity 及 Application 的 startActivity 方法的方式实现。
2、外部启动多实例问题
以上解决 MainActivity 多实例的方案,是建立在启动 Activity 之前去修改待启动 Activity 的 Intent 的方式实现的,这种方式对于应用外部启动 MainActivity 导致的 MainActivity 多实例的问题显然是无法解决的。那么针对外部启动 MainActivity 导致的多实例问题,我们是否有其他解决方案呢?
我们先回到解决 MainActivity 多实例问题的出发点。之所以要避免 MainActivity 多实例,是为了防止同时出现多个 MainActivity 对象,出现不符合预期的 MainActivity 生命周期的执行。因此只要确保不会同时出现多个 MainActivity 对象,一样可以解决 MainActivity 多实例问题。
要避免同时出现多个 MainActivity 对象,我们首先需要知道当前是否已经存在 MainActivity 对象,解决这个问题的思路比较简单,我们可以去监听 Activity 的生命周期,在 MainActivity 的 onCreate 和 onDestroy 中分别去增加减少 MainActivity 的实例数。如果 MainActivity 实例数为 0 则认为当前不存在 MainActivity 对象。
解决了 MainActivity 对象数统计的问题,接下来我们就需要让 MainActivity 同时存在的对象数永远保持在 1 个以下。要解决这个问题我们需要回顾一下 Activity 的启动流程,启动一个 Activity 首先会经过 AMS,AMS 会再调用到 Activity 所在的进程,在 Activity 所在的进程会经过主线程的 Handler post 到主线程,然后通过 Instrumentation 去创建 Activity 对象,以及执行后续的生命周期。对于外部启动 MainActivity ,我们能够控制的是从 AMS 回到进程之后的部分,这里可以选择以 Instrumentation 的 newActivity 作为入口。
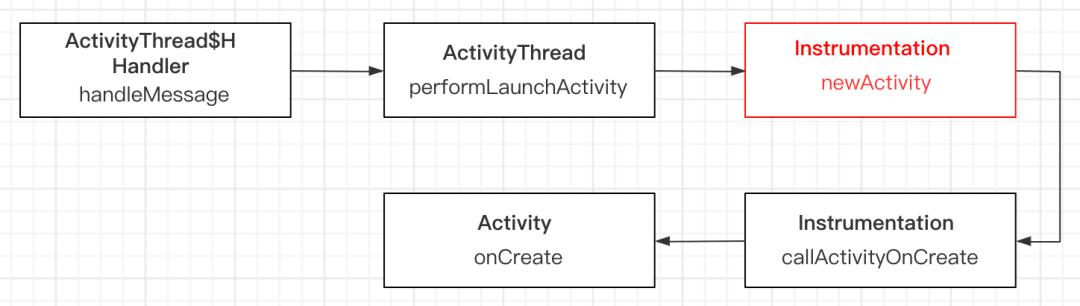
具体来说我们的优化方案如下:
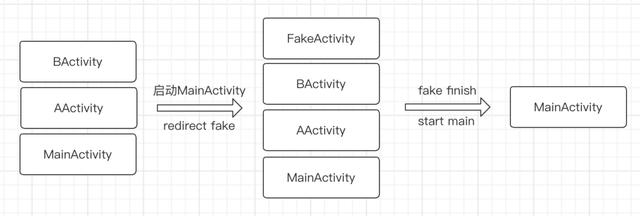
需要注意的是我们这里 hook Instrumentaion 的实现方案,在高版本的 Android 系统上我们也可以以 AppComponentFactory instantiateActivity 的方式替换。
抖音 Activity 阶段另一个典型的优化是反序列化的优化——在抖音使用过程中会在本地序列化一部分数据,在启动过程中需要对这部分数据进行反序列化,这个过程会对抖音的启动速度造成影响。在之前的优化过程中,我们从业务层面对 block 逻辑进行了异步化、快照化等 case by case 的优化,取得了不错的效果,但是这样的方式维护起来比较麻烦,迭代过程也经常出现劣化,因此我们尝试以正面优化反序列化的方式进行优化。
抖音启动阶段的反序列化问题具体来说就是 Gson 数据解析耗时问题,Gson 是 Google 推出的一个 json 解析库,其具有接入成本低、使用便捷、功能扩展性良好等优点,但是其也有一个比较明显的弱点,那就是对于它在进行某个 Model 的首次解析时会比较耗时,并且随着 Model 复杂程度的增加,其耗时会不断膨胀。
Gson 的首次解析耗时与它的实现方案有关,在 Gson 的数据解析过程中有一个非常重要的角色,那就是 TypeAdapter,对于每一个待解析的对象的 Class,Gson 会首先为其生成一个 TypeAdapter,然后利用这个 TypeAdapter 进行解析,Gson 默认的解析方案采用的是 ReflectiveTypeAdapterFactory 创建的 TypeAdapter 的,其创建与解析过程中涉及到大量的反射调用,具体流程为:
因此对于 Gson 解析耗时优化的核心就是减少反射,这里具体介绍一下抖音中使用到的一些优化方案。
自定义 TypeAdapter 优化
通过对 Gson 的源码分析,我们知道 Gson 的解析采用的是责任链的形式,如果在 ReflectiveTypeAdapterFactory 之前已经有 TypeAdapterFactory 能够处理某个 Class,那么它是不会执行到 ReflectiveTypeAdapterFactory 的,而 Gson 框架又是支持注入自定义的 TypeAdapterFactory 的,因此我们的一种优化方案就是注入一个自定义的 TypeAdapterFactory 去优化这个解析过程。
这个自定义 TypeAdapterFactory 会在编译期为每个待优化的 Class 生成一个自定义的 TypeAdapter,在这个 TypeAdapter 中会为 Class 的每个字段生成相关的解析代码,以达到避免反射的目的。
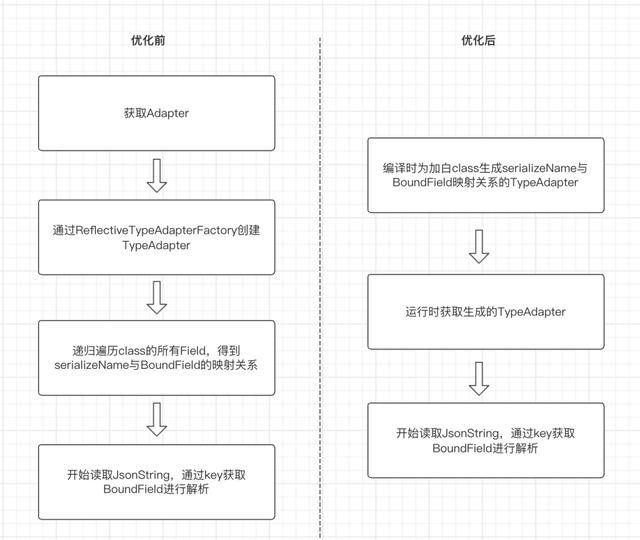
生成自定义 TypeAdapter 过程中的字节码处理,我们采用了抖音团队开源的字节码处理框架 Bytex(https://github.com/bytedance/ByteX/blob/master/README_zh.md),具体的实现过程如下:
public class GsonOptTypeAdapterFactory extends BaseAdapterFactory { protected BaseAdapter createTypeAdapter(String var1) { switch(var1.hashCode()) { case -1939156288: if (var1.equals("xxx/xxx/gsonopt/model/Model1")) { return new TypeAdapterForModel1(this.gson); } break; case -1914731121: if (var1.equals("xxx/xxx/gsonopt/model/Model2")) { return new TypeAdapterForModel2(this.gson); } break; return null; }}public abstract class TypeAdapterForModel1 extends BaseTypeAdapter { protected void setFieldValue(String var1, Object var2, JsonReader var3) { Object var4; switch(var1.hashCode()) { case 110371416: if (var1.equals("field1")) { var4 = this.gson.getAdapter(String.class).read(var3); ((Model1)var2).field1 = (String)var4; return true; } break; case 1223751172: if (var1.equals("filed2")) { var4 = this.gson.getAdapter(String.class).read(var3); ((Model1)var2).field2 = (String)var4; return true; } } return false;}}优化 ReflectiveTypeAdapterFactory 实现
上面这种自定义 TypeAdapter 的方式可以对 Gson 的首次解析耗时优化 70%左右,但是这个方案需要在编译期增加解析代码,会增加包体积,具有一定的局限性,为此我们也尝试了对 Gson 框架的实现进行了优化,为了降低接入成本我们通过修改字节码的方式去修改 ReflectiveTypeAdapterFactory 的实现。
原始的 ReflectiveTypeAdapterFactory 在进行实际数据解析之前,会首先去反射 Class 的所有字段信息,再进行解析,而在实际解析过程中并不是所有的字段都是会使用到的,以下面的 Person 类为例,在进行 Person 解析之前,会对 Person、Hometown、Job 这三个类都进行解析,但是实际输入可能只是简单的 name,这种情况下对于 Hometown、Job 的解析就是完全没有必要的,如果 Hometown、Job 类的实现比较复杂,这将导致较多不必要的时间开销。
class Person { @SerializedName(value = "name",alternate = {"nickname"}) private String name; private Hometown hometown; private Job job;}class Hometown { private String name; private int code;}class Job { private String company; private int type;}//实际输入{ "name":"张三"}针对这类情况我们的解决方案就是“按需解析”,以上面的 Person 为例我们在解析 Person 的 Class 结构时,对于基本数据类型的 name 字段会进行正常的解析,对于复杂类型的 hometown 和 job 字段,会去记录它们的 Class 类型,并且返回一个封装的 TypeAdapter;在实际进行数据解析时,如果确实包含 hometown 和 job 节点,我们再去进行 Hometown 与 Job 的 Class 结构解析。这种优化方案对于 Class 结构复杂但是实际数据节点缺失较多情况下效果尤为明显,在抖音的实践过程中某些场景优化幅度接近 80%。
其他优化方案
上面介绍了两种比较典型的优化方案,在抖音的实际优化过程中还尝试了其他的优化方案,在特定的场景也取得了不错的优化效果,大家可以参考:
介绍完 Activity 阶段的优化我们再来看一下 UI 渲染阶段的相关优化,这个阶段我们将介绍 View 加载的相关优化。

一般来说创建 View 有两种方式,第一种方式就是直接通过代码构建 View,第二种方式就是 LayoutInflate 去加载 xml 文件,这里将重点介绍LayoutInflate 加载 xml 的优化。LayoutInflate 进行 xml 加载包括三个步骤:
这 3 个步骤整体上是比较耗时的。在业务层面上,我们可以通过优化 xml 层级、使用 ViewStub 方式进行按需加载等方式进行优化,这些优化可以在一定程度上优化 xml 的加载时长。
这里我们介绍另一种比较通用优化方案——异步预加载方案,以下图中 fragment 的 rootview 为例,它是在 UI 渲染的 measure 阶段被 inflate 出来的,而从应用启动到 measure 是有一定的时间 gap 的,我们完全可以利用这段时间在后台线程提前将这些 view 加载到内存,在 measure 阶段再直接从内存中进行读取。
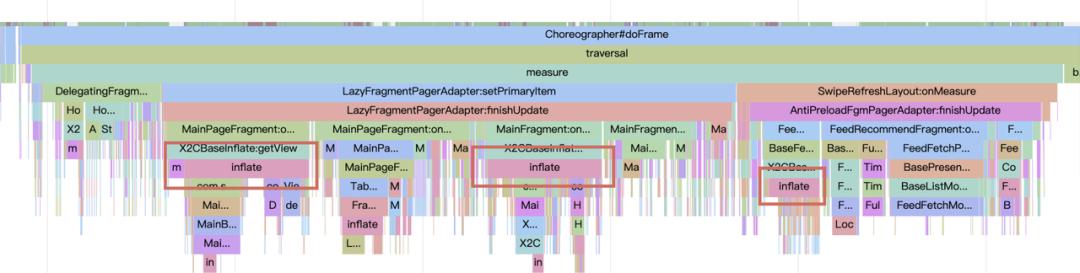
x2c 解决锁的问题
在 androidx 中已经有提供了 AsyncLayoutInflater 用于进行 xml 的异步加载,但是实际使用下来会发现直接使用 AsyncLayoutInflater 很容易出现锁的问题,甚至导致了更多的耗时。
通过分析我们发现,这是因为在 LayoutInflate 中存在着对象锁,并且即使通过构建不同的 LayoutInflate 对象绕过这个对象锁,在 AssetManager 层、Native 层仍然会有其他锁。我们的解决方案就是 xml2code,在编译期为添加了注解的 xml 文件生成创建 View 的代码,然后异步进行 View 的预创建,通过 x2c 方案在解决了多线程锁的问题的同时,也提升了 View 的预创建效率。目前该方案正在打磨中,后续在打磨完毕后将会进行详细介绍。
LayoutParams 的问题
异步 Inflate 除了多线程锁的问题,另一个问题就是 LayoutParams 问题。
LayoutInflater 对 View LayoutParam 处理主要依赖于 root 参数,对于 root 不为 null 的情况,在 inflate 的时候将会为 View 构造一个 root 关联类型的 LayoutParams,并且为其设置 LayoutParams,但是我们在进行异步 Inflate 的时候是拿不到根布局的,如果传入的 root 为 null,那么被 Inflate 的 View 的 LayoutParams 将会为 null,在这个 View 被添加到父布局时会采用默认值,这会导致被 Inflate view 的属性丢失,解决这个问题的办法就是在进行预加载时候 new 一个相应类型的 root,以实现对待 inflate view 属性的正确解析。
public View inflate(XmlPullParser parser, @Nullable ViewGroup root, boolean attachToRoot) { // 省略其他逻辑 if (root != null) { // Create layout params that match root, if supplied params = root.generateLayoutParams(attrs); if (!attachToRoot) { // Set the layout params for temp if we are not // attaching. (If we are, we use addView, below) root.setLayoutParams(params); } }}public void addView(View child, int index) { LayoutParams params = child.getLayoutParams(); if (params == null) { params = generateDefaultLayoutParams(); if (params == null) { throw new IllegalArgumentException("generateDefaultLayoutParams() cannot return null"); } } addView(child, index, params);}其他问题
除了上面提到的多线程锁的问题和 LayoutParams 的问题,在进行预加载过程中还遇到了一些其他的问题,这些问题具体如下:
以上我们基本介绍了主线程各大生命周期的相关优化,在抖音的实际优化过程中我们发现一些被 post 在这些生命周期之间的主线程耗时消息也会对启动速度造成影响。比如 Application 和 Activity 之间、Activity 和 UI 渲染之间。这些主线程消息会导致我们后续的生命周期被延后执行,影响启动速度,我们需要对它们进行优化。
对于自己工程中的代码,我们可以比较方便的优化;但是有些是第三方 SDK 内部的逻辑,我们比较难以进行优化;即使是方便优化掉的消息后期的防止劣化成本也非常高。我们尝试从另外一个角度解决这个问题,在优化部分往主线程 post 消息的同时,对主线程消息队列进行调整,让启动相关的消息优先执行。
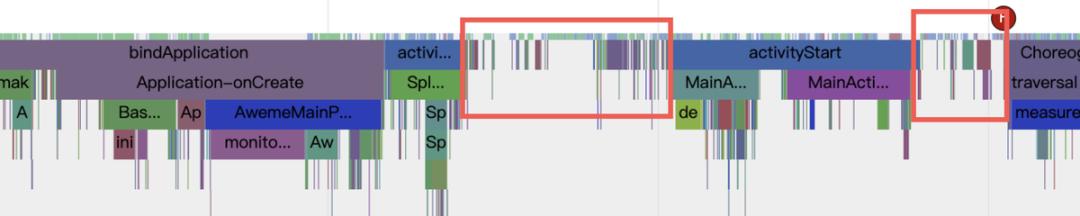
我们的核心原理是根据 App 启动流程确定核心启动路径,利用消息队列调整来保证冷启动场景涉及相关消息优先调度,进而提高启动速度,具体来说包括如下:
通过主线程消息调度,我们可以在一定程度上解决主线程消息对启动速度的影响,但是其也存在一定的局限性:
基于这两个原因我们需要对启动阶段主线程的耗时消息进行优化。
一般来说主线程耗时消息大部分是业务强相关的,可以直接通过 trace 工具输出的主线程的堆栈发现问题逻辑并进行针对性的优化,这里主要介绍一个其他产品也可能会遇到的 case 的优化——WebView 初始化造成的主线程耗时。
在我们的优化过程中发现一个主线程较大的耗时,其调用堆栈第一层为 WebViewChromiumAwInit.startChromiumLocked,是系统 Webview 中的代码,通过分析 WebView 代码发现其是在 WebViewChromiumAwInit 的 ensureChromiumStartedLocked 中 post 到主线程的,在每个进程周期首次使用 Webview 都会执行一次,无论是在主线程还是子线程调用最终都会被 post 到主线程造成耗时,因此我们无法通过修改调用线程解决主线程卡顿的问题;同时由于是系统代码我们也无法通过修改代码实现的方式去进行解决,因此我们只能从业务层从使用的角度尝试是否可以进行优化。
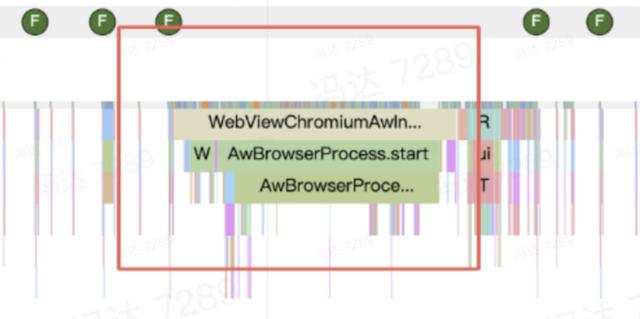
void ensureChromiumStartedLocked(boolean onMainThread) { //省略其他逻辑 // We must post to the UI thread to cover the case that the user has invoked Chromium // startup by using the (thread-safe) CookieManager rather than creating a WebView. PostTask.postTask(UiThreadTaskTraits.DEFAULT, new Runnable() { @Override public void run() { synchronized (mLock) { startChromiumLocked(); } } }); while (!mStarted) { try { // Important: wait() releases |mLock| the UI thread can take it :-) mLock.wait(); } catch (InterruptedException e) { } } }问题定位
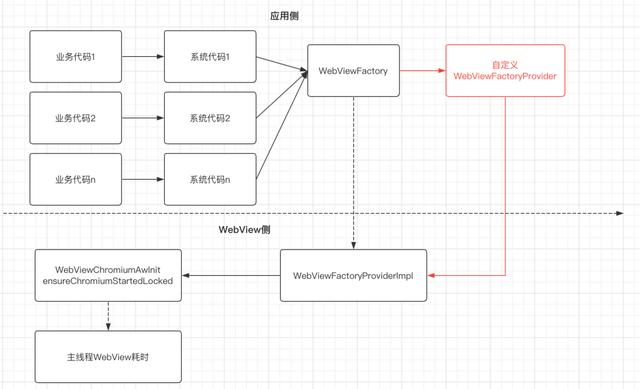
从业务角度优化我们首先需要找到业务的使用点,虽然我们通过分析代码定位到耗时消息是 Webview 相关的,但是我们仍然无法定位到最终的调用点。要定位最终的调用点,我们需要对WebView 相关调用流程有所了解。系统的 WebView 是一个独立的 App,其他应用对于 Webview 的使用都需要经过一个叫 WebViewFactory 的 framework 类,在这个类中首先会通过 Webview 的包名获取到 Webview 应用的 Context,然后通过获取到的 Context 获得 Webview 应用的 Classloader,最后通过 ClassLoader 去加载 Webview 的相关 so,反射加载 Webview 中的 WebViewFactoryProvider 的实现类并进行实例化,后续对于 WebiView 的相关调用都是通过 WebViewFactoryProvider 接口进行的。
通过后续分析发现对于 WebViewFactoryProvider 接口的 getStatics、 getGeolocationPermission、createWebView 等多个方法的首次调用都会触发 WebViewChromiumAwInit 的 ensureChromiumStartedLocked 往主线程 post 一个耗时消息,因此我们的问题就变成了对于WebViewFactoryProvider 相关方法的调用定位。
一种定位办法就是通过插桩的方式实现,由于 WebViewFactoryProvider 并不是应用能够直接访问到的类,因此我们对于 WebViewFactoryProvider 的调用必然是通过调用 framework 其他代码实现的,这种情况下我们需要去分析 framework 中所有对于 WebViewFactoryProvider 的调用点,然后把应用中所有对于这些调用点的调用都进行插桩,进行日志输出以进行定位。很显然这种方式成本是比较高的,比较容易出现漏掉的情况。
事实上对于 WebViewFactoryProvider 的情况我们可以采用一个更便捷的方式。在前面的分析中我们知道 WebViewFactoryProvider 是一个接口,我们是通过反射的方式获得其在 Webview 应用中实现的方式获得的,因此我们完全可以通过动态代理方式生成一个 WebViewFactoryProvider 对象,去替换 WebViewFactory 中的 WebViewFactoryProvider,在生成的 WebViewFactoryProvider 类的 invoke 方法中通过方法名过滤,对于我们的白名单方法输出其调用栈。通过这样的方式我们最终定位到触发主线程耗时逻辑的是我们的 WebView UA 的获取。
解决方案
确认到我们的耗时是由获取 WebView UA 引起的,我们可以采用本地缓存的方式解决:考虑到 WebView UA 记录的是 Webview 的版本等信息,其在绝大部分情况下是不会发生变化的,因此我们完全可以把 Webview UA 缓存在本地,后续直接从本地进行读取,并且在每次应用切到后台时,去获取一次 WebView UA 更新到本地缓存,以避免造成使用过程中的卡顿。
缓存的方案在 Webview 升级等造成 Webview UA 发生变化的情况下可能会出现更新不及时的情况,如果对 WebView 的实时性要求非常高,我们也可以通过调用子进程 ContentProvider 的方式在子进程去获取 WebView UA,这样虽然会影响到子进程的的主线程但是不会影响到我们的前台进程。当然这种方式由于需要启动一个子进程同时需要走完整的 Webview UA 读取,相对本地缓存的方式在读取速度方面是有明显的劣势的,对于一些对读取速度有要求的场景是不太适合的,我们可以根据实际需要采用相应的方案。
前面的案例基本都是主线程相关耗时的优化,事实上除了主线程直接的耗时,后台任务的耗时也是会影响到我们的启动速度的,因为它们会抢占我们前台任务的 cpu、io 等资源,导致前台任务的执行时间变长,因此我们在优化前台耗时的同时也需要优化我们的后台任务。一般来说后台任务的优化与具体的业务有很强的关联性,不过我们也可以整理出来一些共性的优化原则:
除了这些通用的原则,这里也介绍两个抖音中比较典型的后台任务优化的案例。
我们优化过程中除了需要关注当前进程后台线程的运行情况,也需要关注后台进程的运行情况。目前绝大部分应用都会有 push 功能,为了减少后台耗电、避免因为占用过多内存导致进程被杀,一般情况下会把 push 相关功能放在独立的进程。如果在启动阶段去启动 push 进程,其也会对我们的启动速度造成比较大的影响,我们尽量对 push 进程的启动去进行适当延迟,避免在启动阶段启动。
在线下情况下我们可以通过对 logcat 中“Start proc”等关键字进行过滤,去发现是否存在启动阶段启动子进程的情况,以及获得触发子进程启动的组件信息。对于一些复杂的工程或者是三方 sdk,我们即使知道了启动进程的组件,也比较难定位到具体的启动逻辑,我们可以通过对 startService、bindService 等启动Service、Recevier、ContentProvider组件调用进行插桩,输入调用堆栈的方式,结合“Start proc”中组件的去精准定位我们的触发点。除了在 manifest 中生命的进程可能还存在一些 fork 出 native 进程的情况,这种进程我们可以通过adb shell ps的方式去进行发现。

后台任务影响启动速度中还有还有另一个比较典型的 case 就是 GC,触发 GC 后可能会抢占我们的 cpu 资源甚至导致我们的线程被挂起,如果启动过程中存在大量的 GC,那么我们的启动速度将会受到比较大的影响。
解决这个问题的一个方法就是减少我们启动阶段代码的执行,减少内存资源的申请与占用,这个方案需要我们去改造我们的代码实现,是解决 gc 影响启动速度的最根本办法。同时我们也可以通过 GC 抑制的通用办法去减少 GC 对启动速度的影响,具体来说就是在启动阶段去抑制部分类型的 GC,以达到减少 GC 的目的。
近期公司的 Client Infrastructure-App Health 团队调研出了 ART 虚拟机上的 GC 抑制方案,在公司的部分产品上尝试对应用的启动速度有不错的优化效果,详细的技术细节在后续打磨完成后将会在“字节跳动终端技术”公众号分享出来。
前面介绍的案例基本都是针对某个阶段一些比较耗时点的优化,实际上我们还存在一些单次耗时不那么明显,但是频率很高可能会影响到全局的点,比如我们业务中的高频函数、比如我们的类加载、方法执行效率等,这里我们将对抖音在这些方面的优化尝试做一些介绍。
首先我们来看一下抖音在类加载方面的一个优化案例。谈到类加载我们就离不开类加载的双亲委派机制,我们简单回顾一下这种机制下的类加载过程:
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException{ Class<?> c = findLoadedClass(name); if (c == null) { try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { } if (c == null) { c = findClass(name); } } return c;}Android 中的 ClassLoader
双亲委派机制中很重要的一个点就是 ClassLoader 的父子关系,我们再来看一下 Android 中 ClassLoader 情况。一般情况下 Android 中有两个 ClassLoader,分别是 BootClassLoader 和 PathClassLoader,BootClassLoaderart 负责加载 android sdk 的类,像我们的 Activity、TextView 等都由 BootClassLoader 加载。PathClassLoader 则负责加载 App 中的类,比如我们的自定义的 Activity、support 包中的 FragmentActivity 这些会被打进 app 中的类则由 PathClassLoader 进行加载。BootClassLoader 是 PathClassLoader 的 parent。
ART 虚拟机对类加载的优化
ART 虚拟机在类加载方面仍然遵循双亲委派的原则,不过在实现上做了一定的优化。一般情况下它的大致流程如下:

可以看到当 PathClassLoader 到 BootClassLoader 的 ClassLoadeer 链路上只有 PathClassLoader 时,java 层的 findLoadedClass 方法调用后,并不止如其字面含义的去已加载的类中查找,其还会在 native 层直接通过 DexFile 去加载类,这种方式相对于回到 java 层调用 findClass 再调回 native 层通过 DexFile 加载可以减少一次不必要的 jni 调用,在运行效率上是更高的,这是 art 虚拟机对类加载效率的一个优化。
抖音中 ClassLoader 模型
在前面我们介绍了 Android 中的类加载相关机制,那么我们究竟在类加载方面做了哪些优化,要解答这个问题我们需要了解一下抖音中的ClassLoader 模型。在抖音中为了减少包体积,一些非核心功能我们通过插件化的方式进行了动态下发。在接入插件化框架后抖音中的 ClassLoader 模型如下:
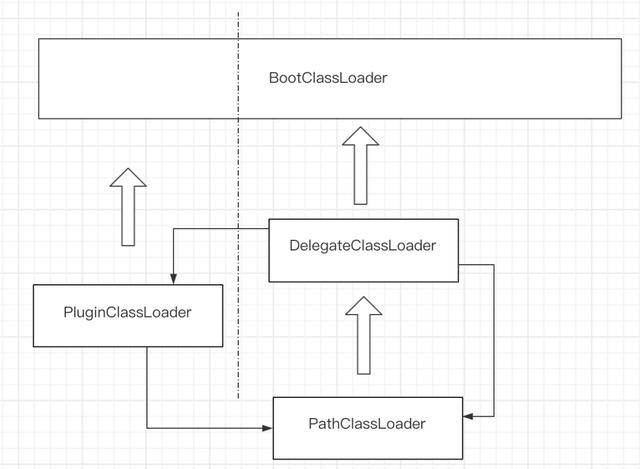
这种 ClassLoader 模型有一个非常明显的优点,那就是它能够非常方便的同时支持类的隔离、复用以及插件化与组件化的切换;
ART 类加载优化机制被破坏
上面介绍了抖音的 ClassLoader 模型的优点,但是其也有一个比较隐蔽的不足,那就是它会破坏 ART 虚拟机对类加载的优化机制。
通过前面的介绍我们了解,当 PathClassLoader 到 BootClassLoader 的 ClassLoader 链路上只有 PathClassLoader 时,则可以在 native 层进行类的加载,以减少一次 jni 的调用。在抖音的 ClassLoader 模型中,PathClassLoader 与 BootClassLoader 之间存在一个 DelegateClassLoader,它的存在会导致“PathClassloader 到 BootClassLoader 的 ClassLoader 链路上只有 PathClassLoader”这一条件被破坏,这导致我们 app 中所有类的首次加载都需要多一次 jni 的调用。一般情况下多一次 jni 的调用不会带来多少消耗,但是对于启动阶段大量类加载的场景,这个影响也是比较大的,会对我们的启动速度造成一定的影响。
非侵入式优化方案:延迟注入
了解插件化对类加载造成负向的原因,优化思路也就比较清晰了——将 DelegateClassLoader 从 PathCLasLoader 和 BootClassLoader 之间移除掉。
通过前面的分析,我们知道引入 DelegateClassLoader 是为了在使用 PathClassLoader loadClass 失败时,可以使用 PluginClassloader 去插件中加载,因此对于不使用插件的场景,DelegateClassloader 是完全没有必要的,我们完全可以在需要用到插件功能时再进行 DelegateClassloader 的注入。
但在实际执行过程中,这种完全进行按需注入会比较困难,因为我们无法精确掌握插件加载时机,比如我们的可能通过是通过 compileonly 的方式隐式的依赖、加载插件的类,也可能在 xml 中使用某个插件的 view 的方式触发插件的加载,如果要进行适配会对业务开发带来比较大的侵入。
这里尝试换一个思路进行优化——我们虽然没法精确地知道插件加载时机,但却可以知道哪里没有插件加载。比如 Application 阶段是没有插件加载的,那么完全可以等 Applicaiton 阶段执行完成再进行 DelegateClassloader 的注入。事实上在启动过程中,类的加载主要集中在 Application 阶段,通过在 Applicaiton 执行完成再去进行 DelegateClassloader 进行注入,可以极大地减少插件化方案对启动速度的影响,同时也可以避免对业务的侵入。
侵入式优化方案:改造 ClassLoader 模型
上面的方案无需侵入业务改造成本很小,但是它只是优化了 Application 阶段的类加载,后续阶段 ART 对类加载的优化仍然无法享受到,从极致性能的角度我们做了进一步的优化。我们优化的核心思想就是把 DelegateClassloader 从 PathClassLoader 和 BootClassLoader 之间彻底去除掉,通过其他方式来解决宿主加载插件类的问题。通过分析我们可以知道宿主加载插件的类主要有几种方式:
因此我们的问题就变成了在不注入 ClassLoader 的情况下,如何实现宿主加载插件的这四大类。
首先是Class.forName 的方式,解决这种方式下插件类加载的问题最直接的解决办法就是调用 Class.forName 时显示的去指定 ClassLoader 为 DelegateClassloader,不过这样的方式对业务开发不够友好,且存在一些三方 sdk 中代码我们无法修改的问题。我们最终的解决办法就是对 Class.forName 调用进行字节码插桩,在类加载失败时再尝试使用 DelegateClassloader 去进行加载。
接下来是compileOnly 的隐式依赖,这种方式比较难进行通用处理,因为我们无法找到一个合适的时机去对类加载失败进行兜底。针对这个问题我们的解决办法就是进行业务的改造,将 compileOnly 的隐式依赖调用的方式改成通过 Class.forName 的方式,之所以进行这样的改造主要是基于几下几点考虑:
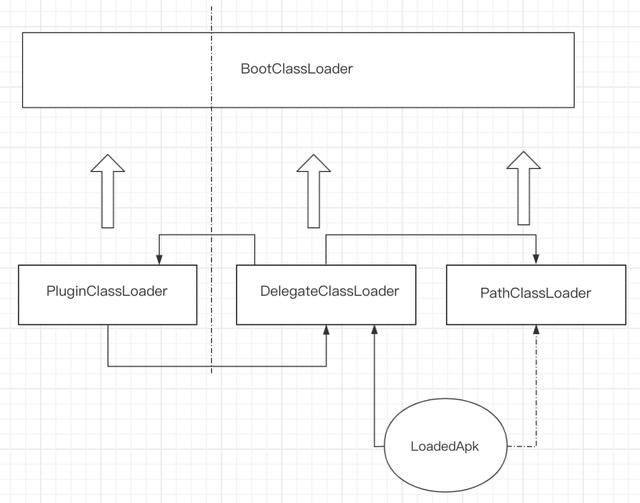
插件四大组件类的加载和 xml 中使用插件类的问题都可以通过同一个方案来解决——将 LoadedApk 中的 ClassLoader 替换为DelegateClassLoader,这样无论是四大组件 class 的加载还是 LayoutInflate 加载 xml 时的 class 加载都会使用 DelegateClassLoader 加载,关于这部分的原理大家可以参考 DroidPlugin、Replugin 等相关插件化原理解析,这里就不展开介绍了。
对于 ClassLoader 的优化,优化的是类加载过程中的 load 阶段,对于类加载的其他阶段也可以进行一定的优化,比较典型的一个案例就是classverify的优化,classverify 过程主要是校验 class 是否符合 java 规范,如果不符合规范则会在 verify 阶段抛出 verify 相关的异常。
一般情况下 Android 中的 class 在应用安装或插件加载时就会进行 verify,但是存在一些特定 case,比如 Android10 之后的插件、插件编译采用 extract filter 类型、宿主与插件相互依赖导致静态 verify 失败等情况,则需要在运行时进行 verify。运行 verify 的过程除了会校验 class,还会触发它所依赖 class 的 load,从而造成耗时。

事实上 classverify 主要是针对网络下发的字节码进行校验,对于我们的插件代码其在编译的过程中就会去校验 class 的合法性,而且即使真的出现了非法的 class,最多也是将 verify 阶段抛出的异常转移到 class 使用的时候。
因此我们可以认为,运行时的 classverify 是没有必要的,可以通过关闭 classverrify来优化这些类的加载。关于关闭 classverify 目前业界已经有一些比较优秀的方案,比如运行时在内存中定位出 verify_所在内存地址,然后将其设置成跳过 verify 模式以实现跳过 classverify。
// If kNone, verification is disabled. kEnable by default. verifier::VerifyMode verify_; // If true, the runtime may use dex files directly with the interpreter if an oat file is not available/usable. bool allow_dex_file_fallback_; // List of supported cpu abis. std::vector<std::string> cpu_abilist_; // Specifies target SDK version to allow workarounds for certain API levels. int32_t target_sdk_version_;当然关闭 classverify 的优化方案并不一定对所有的应用都有价值,在进行优化之前可以通过 oatdump 命令输出一下宿主、插件中在运行时进行 classverify 的类信息,对于存在大量类在运行时 verify 的情况可以采用上面介绍的方案进行优化。
oatdump --oat-file=xxx.odex > dump.txtcat dump.txt | grep -i "verified at runtime" |wc -l在全局优化方面,还有一些其他比较通用的优化方案,这里也进行一些简单的介绍,以供大家参考:
至此,我们已经对抖音启动优化中比较典型、通用的案例进行了介绍,希望这些案列能够为大家的启动优化提供一些参考。回顾抖音以往的所有启动相关的优化,通用的优化只是占了其中一小部分,更多的是与业务相关的优化,这部分优化有着极强的业务关联性,其他业务无法直接进行迁移,针对这部分优化我们总结了一些优化的方法论,具体可以参见抖音 Android 性能优化系列:启动优化之理论和工具篇。最后从实践的角度对我们的启动优化做一些总结与展望, 希望能对大家有所帮助。
启动优化是一个需要持续迭代与打磨的的过程,一般来说最开始的是“快、猛”的快速优化阶段,这个阶段优化空间会比较大,优化粒度会相对较粗,在投入不多的人力情况下就能取得不错的收益;第二个阶段难点攻坚阶段,这个阶段需要的投入相对第一个阶段要大,最终的提升效果也取决于难点的攻坚情况;第三个阶段是防劣化与持续的精细化优化过程,这个过程是最为持久的一个过程,对于快速迭代的产品,这个阶段也非常重要,是我们通向极致化启动性能的必经之路。
启动优化也需要进行一定扩展与泛化的,一般情况下我们关注的是用户点击 icon 到首页首帧的时间,但是随着商业化开屏、push 点击等场景的增加,我们也需要扩展到这些场景。另外很多时候虽然页面的首帧出来了,但用户还是无法看到想看的内容,因为用户关注的可能不是页面首帧的时间,而是有效内容加载出来的时间。以抖音为例,我们在关注启动速度的同时,也会去关注视频首帧的时间,从 AB 实验来看这个指标甚至比启动速度更重要,其他产品也可以结合自己的业务,去定义一些对应的指标,验证对用户体验的影响,决定是否需要进行优化。
一般来说,我们以启动速度来衡量启动性能。为了提升启动速度,我们可能会把一些原本在启动阶段执行的任务进行延后或者按需,这种方式能够有效优化启动速度,但同时也可能损害后续的使用体验。比如,如果将某个启动阶段的后台任务延后到后续使用时,如果首次使用是在主线程,则可能会造成使用卡顿。因此,我们在关注启动性能的同时,也需要关注其他可能影响的指标。
性能上我们需要有一个能体现全局性能的宏观指标,以防止局部最优效应。业务上我们需要建立启动性能与业务的关系,具体来说就是在优化过程中尽可能对一些较大的启动优化支持 AB 能力,这样做一方面可以实现对优化的定性分析,防止一些有局部性能收益但是对全局体验有损害的负优化被带到线上去;另一方面也可以利用实验的定性分析能力,量化各个优化对业务的效果,从而为后续的优化方向提供指导。同时也可以对一些可能造成稳定性或者功能异常的改动,提供回滚能力以及时止损。
目前,字节跳动旗下的企业级技术服务平台火山引擎已经对外开放了 AB 实验能力,感兴趣的同学可以到火山引擎官网进行了解。
未来抖音的启动优化有两个大的目标,第一个目标是启动优化的覆盖率做到最大化:架构方面我们希望启动阶段的代码能够做到依赖简单、清晰,模块粒度尽可能的小,后续优化与迭代成本低;体验方面在做好性能优化的同时做好交互、内容质量等功能优化,提升功能的触达效率与品质;场景方面做到冷启动、温启动、热启动等各类启动方式、落地页的全面覆盖;优化方向上覆盖 CPU、IO、内存、锁、UI 渲染等各类优化方向。第二个目标是实现启动优化精细化运营,做到千人千时千面,对于不同的用户、不同的设备性能与状况、不同的启动场景等采用不同的启动策略,实现体验优化的最大化。
抖音 Android 基础技术团队是一个深度追求极致的团队,我们专注于性能、架构、包大小、稳定性、基础库、编译构建等方向的深耕,保障超大规模团队的研发效率和数亿用户的使用体验。目前北京、上海、杭州、深圳都有大量人才需要,欢迎有志之士与我们共同建设亿级用户的 APP!
对抖音工作机会感兴趣的同学,可以进入字节跳动招聘官网查询「抖音基础技术 Android」相关职位,也可以邮件联系:fengda.1@bytedance.com 咨询相关信息或者直接发送简历内推!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号