AMD RX 7900XT:AIGC专业高效利器,性能提升超乎想象
发表时间: 2023-12-08 14:38

对于AIGC设计师用户和AI出图爱好者来说,大显存高端显卡当然是最佳的高效工具。而目前由于众所周知的原因,部分高端显卡的价格被一炒再炒,大大增加了这类用户的装机成本。实际上,大家不要忘了AMD旗下的Radeon RX 7900系列其实在AIGC方面的性能也是非常强悍的,特别在是时下热门的AI出图应用中也有十分出色的表现。再加上AMD显卡的价格一直都稳中有降,因此Radeon RX 7900系列可以说是性价比非常高的AI出图利器,其中拥有20GB超大显存的Radeon RX 7900 XT更是爆款甜品。
RDNA3架构与超大显存加持,RX 7900 XT天生适合AIGC
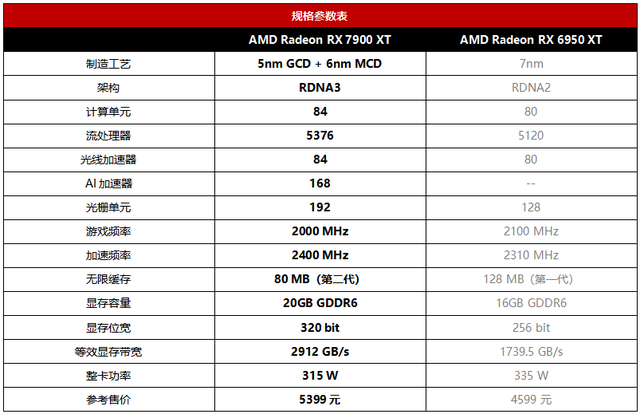
RX 7900 XT采用了小芯片设计的RDNA3架构,GCD芯片使用5nm工艺,MCD部分则使用6nm工艺,总面积与上代RX 6950 XT相同,但晶体管达到上代的2.15倍以上,因此能效表现相对上代RDNA2大幅提升。此外,RDNA3架构相对上代新增了AI加速器单元,无限缓存也升级到了第二代,等效显存带宽是RX 6950 XT的1.67倍,由此也带来了更为强悍的数据吞吐能力。
之所以说RX 7900 XT非常适合AIGC应用,一方面就是它拥有强悍的算力,单精度峰值性能高达52 TFLOPS,半精度峰值性能高达103 TFLOPS,分别是RX 6950 XT的2.2倍和2.18,算力直接决定了AI计算的速度,而这方面RX 7900 XT无疑是第一梯队的水平;另一方面就是它拥有320 bit位宽、容量高达20 GB的GDDR6显存,这对于AI出图来讲就意味着支持更高的图片分辨率上限,设计师可以直出大图而不用去花时间高清重建。这两大优势中后者尤其重要,也是小显存中低端显卡无法比拟的。
此外,放眼高端显卡市场,同代竞品16GB显存的RTX 4080售价已经超过八千元,再往上就是几万元天价且买不到的24GB显存RTX 4090,已经和性价比没什么关系了。相比之下,拥有20GB超大显存的RX 7900 XT仅需5000元出头真的可以说是性价比爆棚的AIGC利器,再加上现在A卡还可以通过微软Olive工具来优化模型提升出图速度,所以它特别适合需求比基础AI玩家更高更专业的AIGC设计师用户和AI深度爱好者。
接下来就让我们一起来看看RX 7900 XT在热门本地AI出图工具Stable Diffusion中的性能表现吧。
Stable Diffusion出图实测:RX 7900 XT大显存尤其抢眼
测试平台
显卡:AMD Radeon RX 7900 XT
处理器:AMD锐龙5 7600X
内存:阿斯加特DDR5 7200 16GB×2
主板:华硕TUF GAMING A620M-PLUS
硬盘:WD_BLACK SN850X 2TB
电源:ROG雷神THOR 1600W
操作系统:Windows 11专业版23H2
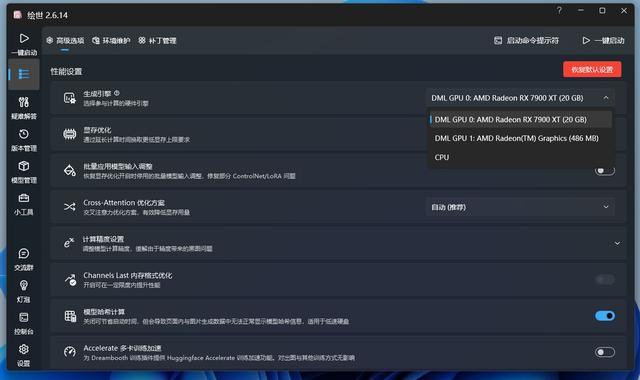
Stable Diffusion的Windows版早就已经添加了对DirectML的支持,因此AMD显卡也可以在Windows 10/11系统中实现对它的硬件加速。原版的Stable Diffusion环境配置和各种设定比较复杂(主要是受网络连接的影响),嫌麻烦也可以选用各位AI大佬制作的整合包,本次我们测试也选用了B站UP主秋葉制作的整合包,经过简单的设置后即可在高级选项中选择实用RX 7900 XT以DirectML的模式进行加速。此外,由于RX 7900 XT拥有20GB大显存,所以我们可以直接选择12GB以上显存的模式实现效率最大化。
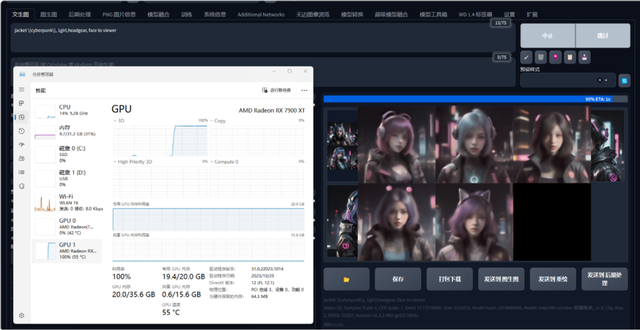
实测出图时,我们设置迭代步数20、Euler采样a、512×512分辨率、CFG为7,模型选用麦橘唯美人物模型。从图中可以看到,在一批次出五张图的设定下,20GB显存已经完全用满,此时RX 7900 XT已经做到了全速输出,完成时间大约为22秒。
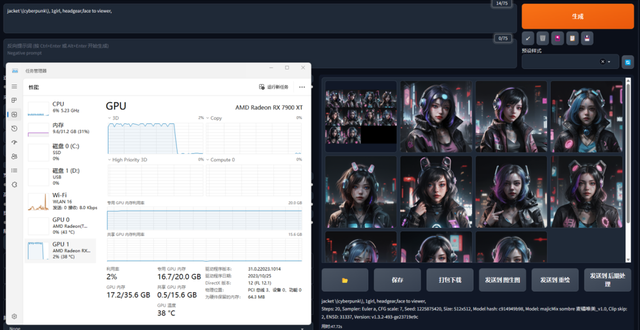
让我们再进一步增加计算压力,一次生成10张图,此时RX 7900 XT也处于满载输出状态,20GB显存占满也并没有明显拖慢速度,完成的时间大约为47秒,略高于5张图22秒的两倍。我们也用纯处理器试着出了一张图用作参考,以测试平台的6核处理器来看,出一张图大约需要3分18秒,而RX 7900 XT出一张图大约费时6.8秒,差不多快了28倍,很显然要做AIGC,高性能显卡确实是首选方案。
从Stable Diffusion的出图测试来看,在一次生成多张或生成更高分辨率的图片时,Stable Diffusion对显存的占用是非常高的,吃满20GB显存也并不稀奇,而显存低于20GB的话,就可能会因为爆显存影响效率或无法正常出图。因此,像是AIGC设计师或者是深度AI玩家,拥有20GB大显存且自身算力也过硬的RX 7900 XT确实是上佳之选。
支持Olive模型优化,RX 7900 XT的AI出图性能再度暴增

我们知道,在几个月前,AMD和微软合作优化了Microsoft Olive路径,可以把基本模型从PyTorch转换为ONNX,从而巨幅提升AMD显卡在文生图方面的计算效率。目前经过多个版本的迭代,AMD显卡使用Olive优化模型的设置也变得更加简单,普通玩家也可以轻松上手了,接下来就让我们实际体验一下。
测试环境依然是在Windows平台下,我们需要安装Git For Windows、Python For Windows和Miniconda For Windows,这些去官网下载安装就好,记得装完之后确保它们加入了系统变量Path。接下来就是配置虚拟环境、安装Olive、克隆Stable Diffusion到本地,启动Stable Diffusion自动下载需要的组件。具体的操作细节可以点击下方链接查看AMD官方教程(注意,遇到报错可能需要更新一下PIP和HTTPX到对应版本)。
(https://community.amd.com/t5/ai/updated-how-to-running-optimized-automatic1111-stable-diffusion/ba-p/630252)

运行Stable Diffusion(Olive版)之后,在ONNX页面下先下载原版模型,然后在Olive页面中点选Optimize ONNX model,然后点击Optimize model using Olive按键优化模型,大约3分27秒即可完成优化。
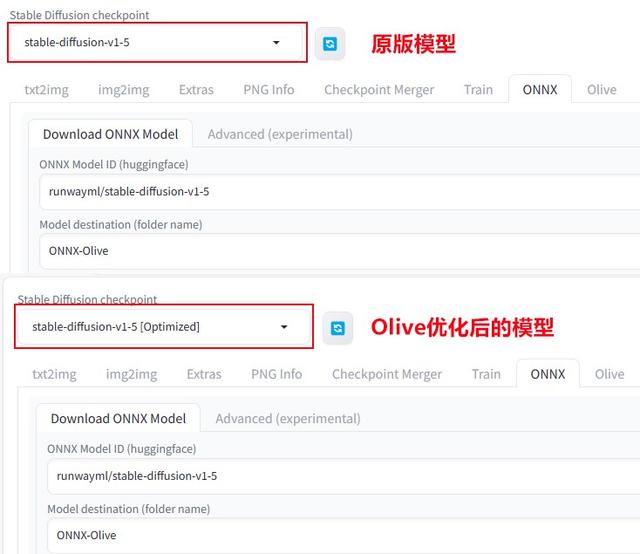
优化完成之后,此时在主界面左上角即可选择原版模型或Olive优化模型进行出图对比了。这里提醒大家在首次下载完ONNX原版模型之后备份一下,以免Olive优化模型直接在原路径上进行覆盖,不方便多次对比。

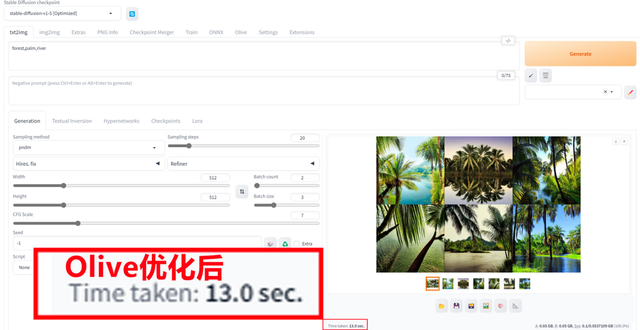
那么Olive优化模型之后RX 7900 XT出图速度提升有多大呢?从图上可以看到,我们选择一次出两批图,每批三张,总共六张。优化之前需要28.9秒完成,优化之后仅需13秒,出图速度提升幅度高达122%!可见优化效果是非常明显的。
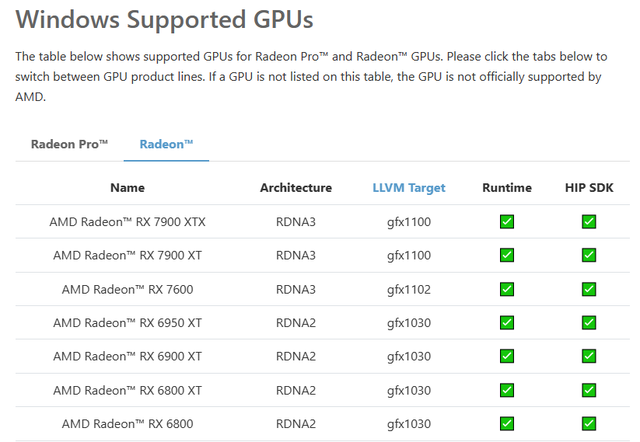
实际上,如果RX 7900 XT是在Linux环境下使用ROCm平台来运行 Stable Diffusion的话,出图效率还有数倍的提升,所以专业用户也可以关注一下Windows平台的ROCm版Stable Diffusion(RX 7900 XT是完全支持ROCm的Runtime和HIP SDK的,RX 6750以下只支持Runtime),从这一点来讲RX 7900 XT不但可以让你立刻享受极高的AI性能,它也拥有极其深厚的“战未来”潜力。
总结:AIGC专业高效利器,RX 7900 XT性价比遥遥领先
从前面的分析可以看到,RX 7900 XT不但本身拥有旗舰级的算力,而且还拥有20GB超大显存,超过了RTX 4080的16GB显存,更大的显存也更有利于AI出图的分辨率和效率。同时,RX 7900 XT在显存更大的情况下售价仅为RTX 4080的61%,性价比可以说是真的遥遥领先了。从Stable Diffusion的实测来看,在出图数量增多的情况下,对显存的需求确实是非常高的,RX 7900 XT的20GB大显存正好可以发挥威力,在连续出图的情况下也能保证图片不出错,同时也保障了出图效率。
此外,我们也可以看到,在使用Olive优化模型之后,RX 7900 XT的出图速度进一步实现了翻倍,相当于也是给用户带来了免费的性能升级,将来Windows平台有更加完善的ROCm版Stable Diffusion登场的话,RX 7900 XT更是可以如虎添翼,AI性能直接起飞。因此,对于有较高专业AIGC应用需求而不是简单出图玩玩的专业用户来讲,RX 7900 XT可以说是非常适合他们的选择。
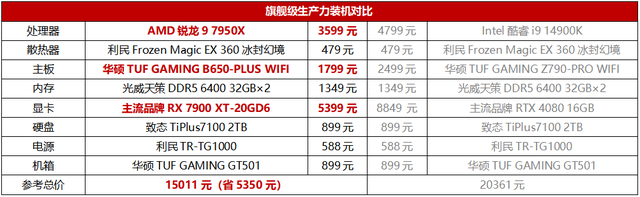
此外,我们也选择了两套旗舰级AI电脑配置进行对比,其中AMD平台采用了锐龙9 7950X与RX 7900 XT的组合,而Intel平台则是酷睿i9 14900K与RTX 4080的组合。从总价可以看到,AMD这套配置拥有5350元的价格优势,同时显存还多出4GB,不光在AIGC应用中可以发挥强悍的性能,在其他生产力应用中也有一流的表现,属于既全能性价比又高的方案。而Intel平台这边总价高出36%,性价比明显落后,显存也更小,在AI出图或其他生产力应用中不免受到更多限制。
总而言之,如果你需要经常面对比较专业的AIGC应用,特别看重超大显存,同时也想享受极致的性价比,那么RX 7900 XT确实是非常值得优先考虑的解决方案。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号