Redis使用全解析:一篇让你彻底掌握的终极指南!
发表时间: 2023-10-10 22:26
小郭在此之前已经分章节发布过相关笔记,本篇是对之前发布过的笔记做的一次汇总和补充,记录了小郭学习redis时总结的所有笔记,方便后续查找!
后续也会基于本文进行持续补充,欢迎大家点赞关注收藏,以防丢失!
一、前言二、Redis简介 1、是什么 2、为什么用它 3、优点三、如何安装 1、版本管理 2、windows安装 3、linux安装四、基础知识-架构 1、单机架构 2、主从架构 3、哨兵架构 4、集群架构五、基础知识-模块组成 1、网络访问框架 2、操作模块 3、索引模块 4、存储模块 5、高可用模块 6、高扩展模块 7、其它模块六、基础知识-请求执行流程 1、概述 2、客户端发送命令请求 3、服务器端读取命令请求 4、服务器端执行命令 5、服务器端将命令回复发送回客户端 6、客户端接收并打印命令回复七、基础知识-配置文件解读八、基础知识-数据类型九、基础知识-事务 1、简介 2、语法十、基础知识-淘汰策略 1、过期删除策略 2、内存淘汰策略十一、基础知识-持久化机制 1、RDB 2、AOF 3、总结十二、基础知识-发布与订阅 1、简介 2、使用 3、常用命令十三、应用接入十四、常见问题 1、缓存击穿 2、缓存穿透 3、缓存雪崩 4、双写一致性问题 5、其它十五、参考资料目前计算机世界中的数据库共有2种类型:关系型数据库、非关系型数据库。
常见的关系型数据库解决方案
MySQL、MariaDB(MySQL的代替品)、Percona Server(MySQL的代替品·)、Oracle、PostgreSQL、Microsoft Access、Google Fusion Tables、SQLite、DB2、FileMaker、SQL Server、INFORMIX、Sybase、dBASE、Clipper、FoxPro、foshub。
几乎所有的数据库管理系统都配备了一个开放式数据库连接(ODBC)驱动程序,令各个数据库之间得以互相集成。
常见的非关系型数据库解决方案(NoSQL)
NoSQL = Not Only SQL
Redis、MongoDB、Memcache、HBase、BigTable、Cassandra、CouchDB、Neo4J。
目前小郭的工作经历里使用最多的就是Redis了。
关系型数据库和非关系型数据库的区别
区别就是一个叫关系型,一个叫非关系型~ 这么解释网友们会不会打残我? 哈哈哈 下面来个正经一点的解释。
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织,有如下优缺点。
1)优点
SQL语言通用,可用于复杂查询;
都是使用表结构,格式一致;
支持SQL,可用于一个表以及多个表之间非常复杂的查询。
2) 缺点
尤其是海量数据的高效读写场景性能比较差,因为硬盘I/O是一个无法避免的瓶颈。
表结构固定,DDL修改对业务影响大。
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。有如下优缺点。
1)优点
IO快,可以使用内存、硬盘或者其它随机存储器作为数据载体,而关系型数据库只能使用硬盘
存储数据格式可以是kv、文档、图片等等,限制少,应用场景广,而关系型数据只能是内置的基础数据类型
部署简单,大部分开源免费,社区活跃。
2)缺点
暂时不提供SQL支持,会造成开发任意额外的学习成本
再来说说为什么需要非关系型数据库技术。
小郭结合自己的工作经验来总结一下(不喜轻点喷~),目前的软件产品从用户角度主要分为几个方向:
这个方向的软件产品是目前市面上最多的,面向的主要是个人用户,遵循比较规范的产品流程。 通常这类软件的用户量基数巨大且增长快,比如美团的年度交易用户数已从2015年的2亿人,增长到2022年的6.87亿人(2022年Q3财报),平均每2个中国人就有一个在美团上花过钱。用户量大,对性能的要求也会比较高,有可能一瞬间成千上万的请求到来(抢购、促销活动场景不可控),需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是关系型数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题, 因此需要引入缓存解决方案,减少对关系型数据库的影响。 Redis就是一个不二选择。
随着近年来不断倡导互联网+,政府也纷纷进行转型,寻求更好的商业模式。To G是从 To B衍生出来的一种特殊划分,面向的企业为政府或相关事业单位,主要是根据每年政府投入的财政预算,然后去做的一系列信息化项目,可以说是“指标驱动,为做项目而做项目”。这类项目有两个极端场景,一类是用户量极低,提供给内部使用的,本地化部署; 还有一类是面向老百姓的,用户量也大,但是对并发要求并不高,比如政务类软件。
举个栗子:智能考车系统,是典型的公安部主导的一款To G产品,使用对象是考官和公安部相关管理等内部人员,用户量不多;而“交管12123”是直接提供给老百姓使用的APP,可以自行预约考试,处理违章等,面向的是全国十几亿人,用户基数大,海量数据,完全依赖传统的关系型数据库肯定会降低应用访问性能,因此也需要引入新的非关系型数据库解决方案来开发程序功能。
这个方向的产品一般是面向商业企业用户的,一般不向大众用户公开。用户量相对较少,通常情况对性能的要求比To C类产品要低一些,一般大部分场景都是直接使用关系型数据库进行数据存储,少部分场景也会额外依赖非关系型数据库。
一句话总结:To C使用场地是随时对地;ToB更多是内网;To G是内外网相结合(互联网+政务)
软件研发产品大体是包括这三大类(当然还有To VC , To P 的一些分法,也没错,只是立足点不同)
目前业界的技术选型原则基本是:核心数据存储选择关系型数据库,次要数据存储选择非关系型数据库。
本文接下来主要总结非关系型数据库中的Redis技术的相关知识。
redis的官网地址,是redis.io。(域名后缀io属于国家域名,是british Indian Ocean territory,即英属印度洋领地),Vmware在资助着redis项目的开发和维护。
从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
据说有一名意大利程序员,在 2004 年到 2006 年间主要做嵌入式工作,之后接触了 Web,2007 年和朋友共同创建了一个网站,并为了解决这个网站的负载问题(为了避免 MySQL 的低性能),于是亲自定做一个数据库,并于 2009 年开发完成,这个就是 Redis。这个意大利程序员就是 Salvatore Sanfilippo 江湖人称 Redis 之父,大家更习惯称呼他 Antirez。
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。Redis属于非关系型数据库中的一种解决方案,目前也是业界主流的缓存解决方案组件。
数百万开发人员在使用Redis用作数据库、缓存、流式处理引擎和消息代理。
Redis是当前互联网世界最为流行的 NoSQL(Not Only SQL)数据库,它的性能十分优越,其性能远超关系型数据库,可以支持每秒十几万此的读/写操作,并且还支持集群、分布式、主从同步等配置,理论上可以无限扩展节点,它还支持一定的事务能力,这也保证了高并发的场景下数据的安全和一致性。
最重要的一点是:Redis的社区活跃,这个很重要。
Redis 已经成为 IT 互联网大型系统的标配,熟练掌握 Redis 成为开发、运维人员的必备技能。
官方的 Benchmark 数据:测试完成了 50 个并发执行 10W 个请求。设置和获取的值是一个 256 字节字符串。
测试结果:Redis读的速度是110000次/s,写的速度是81000次/s 。
支持 Strings, Lists, Hashes, Sets 及 Ordered Sets 数 据类型操作。
所有的操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
提供了缓存淘汰策略、发布定义、lua脚本、简单事务控制、管道技术等功能特性支持
Redis 使用标准的做法进行版本管理: 主版本号.副版本号.补丁号。 偶数 副版本号 表示一个 稳定的 发布,像 1.2, 2.0, 2.2, 2.4, 2.6, 2.8。奇数副版本号表示 不稳定的 发布,例如 2.9.x 发布是一个不稳定版本,下一个稳定版本将会是Redis 3.0。
Redis在Windows上不受官方支持。但是,我们还是可以按照下面的说明在Windows上安装Redis进行开发。
官方window安装教程:
https://redis.io/docs/getting-started/installation/install-redis-on-windows
上面这个照着安装是行不通的!!!!
但是有开源爱好者提供了window的免安装方式,操作非常简单,下面进行步骤说明。
直接下载开源的redis-window版本安装包:
https://github.com/tporadowski/redis/releases

下载好后解压到本地磁盘某个目录,目录结构如下:
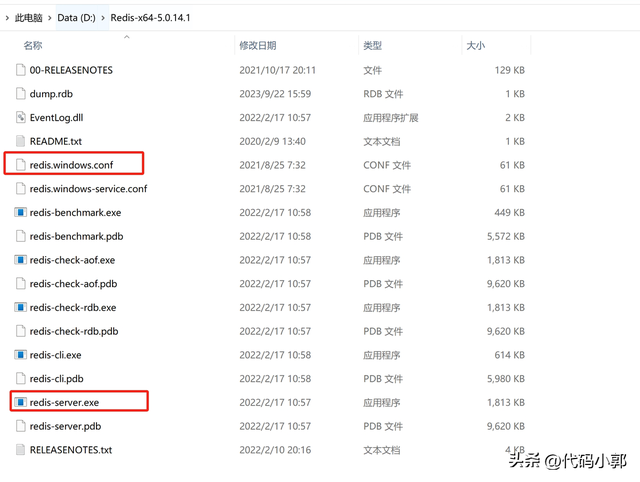
redis-server.exe和redis.windows.conf就是我们接下来要用到的重要文件了。
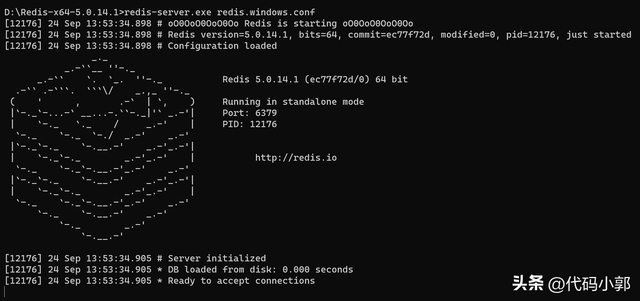
打开一个 cmd 窗口 使用 cd 命令切换目录到 D:\Redis-x64-5.0.14.1 运行如下命令:
redis-server.exe redis.windows.conf如果想方便的话,可以把 redis 的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个 redis.windows.conf 可以省略,如果省略,会启用默认的。输入之后,会显示如下界面:
接下来保持这个cmd界面不要关闭,我们启动一个客户端去连接服务端。
服务端程序启动好之后,我们就可以用客户端去连接使用了,目前已经有很多开源的图形化客户端比如Redis-Desktop-Manager,redis本身也提供了命令行客户端连接工具,接下来我们直接用命令行工具去连接测试。
另启一个 cmd 窗口,原来的不要关闭,不然就无法访问服务端了。切换到目录D:\Redis-x64-5.0.14.1,执行如下命令:
redis-cli.exe -h 127.0.0.1 -p 6379设置一个key名为"hello",value是"world"的键值对:
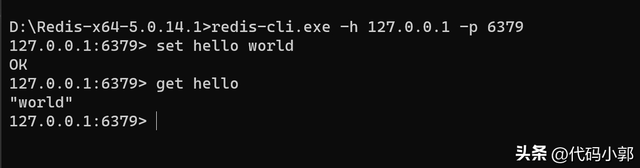
上面的日志显示成功连接到了redis服务,并且设置了一个key名为"hello",value是"world"的键值对数据。
linux安装redis的方式也有多种,小郭这里仅演示源码安装的方式。
使用wget命令从
https://redis.io/download/下载最新的源码包
root@xxx guoyd]# wget https://download.redis.io/redis-stable.tar.gz
解压源码包并进入根目录:
root@xxx guoyd]# tar -xvf redis-stable.tar.gz root@xxx guoyd]# cd redis-stableroot@xxx guoyd]# ll[root@xxx redis-stable]# lltotal 244-rw-rw-r-- 1 guoyd guoyd 18320 Sep 7 01:56 00-RELEASENOTES-rw-rw-r-- 1 guoyd guoyd 51 Sep 7 01:56 BUGS-rw-rw-r-- 1 guoyd guoyd 5027 Sep 7 01:56 CODE_OF_CONDUCT.md-rw-rw-r-- 1 guoyd guoyd 2634 Sep 7 01:56 CONTRIBUTING.md-rw-rw-r-- 1 guoyd guoyd 1487 Sep 7 01:56 COPYINGdrwxrwxr-x 8 guoyd guoyd 4096 Sep 7 01:56 deps-rw-rw-r-- 1 guoyd guoyd 11 Sep 7 01:56 INSTALL-rw-rw-r-- 1 guoyd guoyd 151 Sep 7 01:56 Makefile-rw-rw-r-- 1 guoyd guoyd 6888 Sep 7 01:56 MANIFESTO-rw-rw-r-- 1 guoyd guoyd 22607 Sep 7 01:56 README.md-rw-rw-r-- 1 guoyd guoyd 107512 Sep 7 01:56 redis.conf-rwxrwxr-x 1 guoyd guoyd 279 Sep 7 01:56 runtest-rwxrwxr-x 1 guoyd guoyd 283 Sep 7 01:56 runtest-cluster-rwxrwxr-x 1 guoyd guoyd 1772 Sep 7 01:56 runtest-moduleapi-rwxrwxr-x 1 guoyd guoyd 285 Sep 7 01:56 runtest-sentinel-rw-rw-r-- 1 guoyd guoyd 1695 Sep 7 01:56 SECURITY.md-rw-rw-r-- 1 guoyd guoyd 14700 Sep 7 01:56 sentinel.confdrwxrwxr-x 4 guoyd guoyd 4096 Sep 7 01:56 srcdrwxrwxr-x 11 guoyd guoyd 4096 Sep 7 01:56 tests-rw-rw-r-- 1 guoyd guoyd 3628 Sep 7 01:56 TLS.mddrwxrwxr-x 9 guoyd guoyd 4096 Sep 7 01:56 utils执行make命令进行源码编译
root@xxx redis-stable]# make编译时间大概需要几分钟,如果编译成功,将看到如下输出日志:
.....日志太多,略......Hint: It's a good idea to run 'make test' ;)make[1]: Leaving directory `/home/guoyd/redis-stable/src'同时,在src目录中会生成几个 新的Redis 二进制文件:
redis-server: 代表redis服务本身的可执行程序redis-cli:redis提供的命令行工具,用于和redis服务端进行交互编译成功后,我们继续在源码根目录下使用make install将redis服务安装到默认目录usr/local/bin中:
[root@iZbp128dczen7roibd3xciZ redis-stable]# make installcd src && make installwhich: no python3 in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/jdk1.8.0_201/bin:/root/bin)make[1]: Entering directory `/home/guoyd/redis-stable/src'CC Makefile.depmake[1]: Leaving directory `/home/guoyd/redis-stable/src'which: no python3 in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/jdk1.8.0_201/bin:/root/bin)make[1]: Entering directory `/home/guoyd/redis-stable/src'Hint: It's a good idea to run 'make test' ;)INSTALL redis-serverINSTALL redis-benchmarkINSTALL redis-climake[1]: Leaving directory `/home/guoyd/redis-stable/src'[root@iZbp128dczen7roibd3xciZ redis-stable]#redis安装好了,我们可以在任意目录下执行redis-server命令启动服务端:
因为redis-server已经被配置到了环境变量中,所以可以在任意目录执行
[root@xxx ~]# redis-server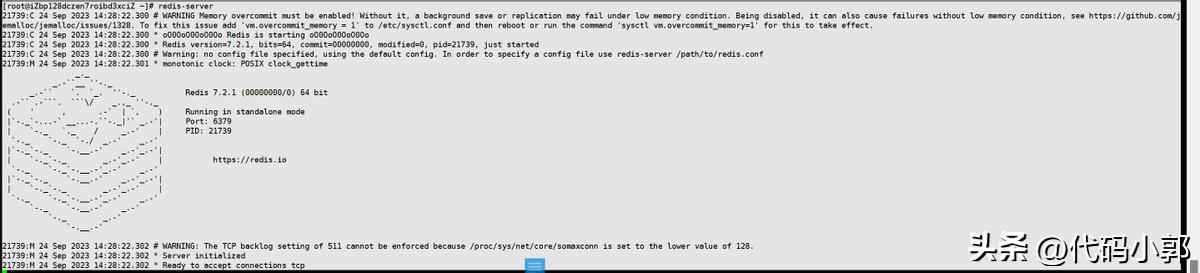
上面演示的是使用默认配置启动redis服务,如果我们想自定义配置,可以使用如下方式:
redis-server /xxx/xxx/redis.confredis.conf是redis的核心配置文件,我们可以按需进行配置修改。
在源码redis-stable的根目录中也提供了配置文件的模板redis.conf, 小郭会在本文后续章节中对这个配置文件做详细说明。
和window版本一样,有很多开源图形化客户端,我们这里还是使用redis自带的命令行工具去连接。
另启一个 linux终端,原来的不要关闭,不然就无法访问服务端了。重新打开一个linux终端,执行如下命令:
当然这里也有办法直接让redis在后台运行,重新打开一个终端的操作不是必要的。
[root@xxx ~]# redis-cli.exe -h 127.0.0.1 -p 6379-bash: redis-cli.exe: command not found[root@iZbp128dczen7roibd3xciZ ~]# redis-cli -h 127.0.0.1 -p 6379127.0.0.1:6379> set hello worldOK127.0.0.1:6379> get hello"world"127.0.0.1:6379>上面的操作成功连接到了redis服务,并且使用set命令设置了一个key名为"hello",value是"world"的键值对数据。
此时,我们的linux服务器上就同时存在一个redis服务端进程和一个redis客户端连接进程:
[root@xxx ~]# ps -ef|grep redisroot 21739 1 0 14:28 ? 00:00:00 redis-server *:6379 # redis服务端进程root 22007 21982 0 14:33 pts/0 00:00:00 redis-cli -h 127.0.0.1 -p 6379 # redis客户端进程root 22143 22121 0 14:35 pts/2 00:00:00 grep --color=auto redis[root@xxx ~]#redis支持许多客户端同时建立连接,接下来我们就可以在业务系统中同时开启多个客户端去访问redis了。
注意:本文接下来的笔记都基于Redis的版本7.2.1
Redis 支持单机、主从、哨兵、集群多种架构模式,本节来总结一下其中的区别。

单机模式是最原始的模式,非常简单,就是安装运行一个Redis实例,然后业务项目调用即可。一些非常简单的应用,并非必须保证高可用的情况下完全可以使用该模式。
优点
缺点
单机 Redis 能够承载的 QPS(每秒查询速率)取决于业务操作的复杂性,Lua 脚本复杂性就极高。假如是简单的 key value 查询那性能就会很高,单机支持10W+的QPS。
但是在单机架构下,系统的最大瓶颈就出现在 Redis 单机问题上,此时我们可以通过将架构演化为主从架构解决该问题。
我们可以部署多个 Redis 实例,单机架构模型就演变成了下面这样:

我们把同时接收读/写操作的节点称为Master(主节点), 接收读操作和数据同步的节点称为Slave(从节点)。
只要主从节点之间的网络连接正常,主节点就会将写入自己的数据同步更新给从节点,从而保证主从节点的数据一致性。
主从架构比较适合读高并发场景。
主从架构存在的问题是:当主节点宕机,需要在众多从节点中选一个作为新的主节点,同时需要修改客户端保存的主节点信息并重启客户端,还需要通知所有的从节点去复制新的主节点数据,从而保证服务的高可用性。整个切换过程需要人工干预,而这个过程很明显会造成服务的短暂不可用。
优点
当QPS 增加时,增加 从节点 即可
缺点
一旦主节点挂掉,在人工做主从切换过程中,对外失去了写的能力
每个从节点都有一份完整数据
哨兵架构主要解决了主从架构中存在的高可用性问题,在主从架构的基础上,哨兵架构实现了自动化故障检测和恢复机制,全过程无需人工干预。
Redis 2.8 版本开始,引入哨兵(Sentinel)这个概念
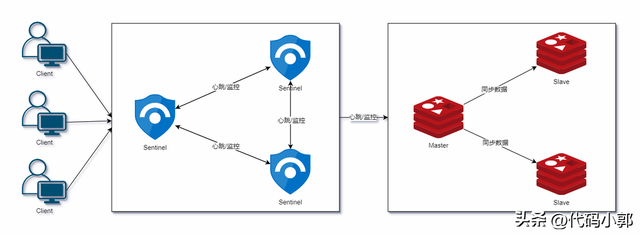
如上图所示,哨兵架构由两部分集群组成,哨兵节点集群和数据节点集群:
该集群中的节点不存储数据,是特殊的redis节点,主要完成监控、提醒、自动故障转移这三大功能。
1)监控(Monitoring):哨兵节点会不断地发送ping消息检测数据节点是否正常;
2)提醒(Notification):当监控到某个数据节点有问题时, 哨兵可以通过 API 向管理员或者其他应用程序发送通知
3)自动故障迁移(Automatic failover):当一个主数据节点不能正常工作时, 哨兵会开始一次自动故障迁移操作,将该主节点下线,选举一个从数据节点升级为主节点(这里也就是将主从架构中的人工干预过程自动化)
该集群中的节点分为主从模式,都存储业务数据,这块其实就是之前的主从架构模式部分
哨兵模式工作原理
优点
缺点
集群架构可以说是Redis的王炸方案了!一经推出,便深得广大开发者喜爱。
Redis 3.0 版本正式推出 Redis Cluster 集群模式,有效地解决了 Redis 分布式方面的需求。Redis Cluster 集群模式具有高可用、可扩展性、分布式、容错等特性。
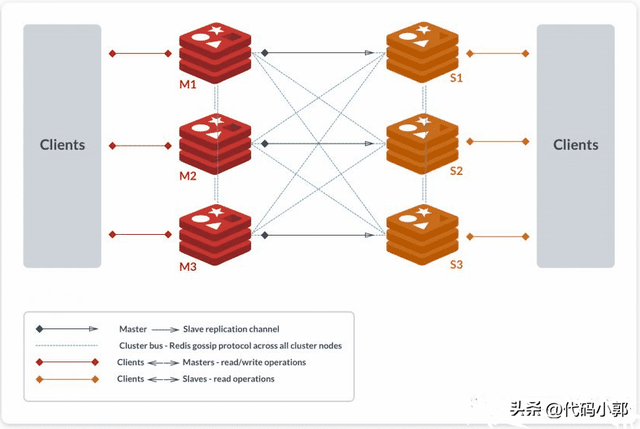
如上图所示,该集群架构中包含 6 个 Redis 节点,3 主 3 从,分别为 M1,M2,M3,S1,S2,S3。除了主从 Redis 节点之间进行数据复制外,所有 Redis 节点之间采用 Gossip 协议进行通信,交换维护节点元数据信息。
客户端读请求分配给 Slave 节点,写请求分配给 Master,数据同步从 Master 到 Slave 节点。读写能力都可以快速进行横向扩展!!!
Redis的集群模式采用的是无中心结构,每个节点都可以保存部分数据和整个集群状态,每个节点都和其他所有节点连接。集群一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点。
分片
单机、主从、哨兵的架构中每个数据节点都存储了全量的数据,从节点进行数据的复制。然而单个节点存储能力受限于机器资源,是存在上限的,集群模式就是把数据进行分片存储,当一个分片数据达到上限的时候,还可以分成多个分片。
Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:HASH_SLOT = CRC16(key) % 16384。每一个节点负责维护一部分槽以及槽所映射的键值数据。

槽是 Redis Cluster 管理数据的基本单位,集群扩缩容其实就是槽和数据在节点之间的移动。
假如,这里有 3 个节点的集群环境如下:
此时,我们如果要存储数据,按照 Redis Cluster 哈希槽的算法,假设结果是: CRC16(key) % 16384 = 3200。 那么就会把这个 key 的存储分配到 A节点。此时连接 A、B、C 任何一个节点获取 key,都会这样计算,最终是通过 B 节点获取数据。
假如这时我们新增一个节点 D,Redis Cluster 会从各个节点中拿取一部分 Slot 到 D 上,比如会变成这样:
这种特性允许在集群中轻松地添加和删除节点。同样的如果我想删除节点 D,只需要将节点 D 的哈希槽移动到其他节点,当节点是空时,便可完全将它从集群中移除。
主从切换
Redis Cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点复制主节点数据备份,当这个主节点挂掉后,就会通过这个主节点的从节点选取一个来充当主节点,从而保证集群的高可用。
回到前面分片的例子中,集群有 A、B、C 三个主节点,如果这 3 个节点都没有对应的从节点,如果 B 挂掉了,则集群将无法继续,因为我们不再有办法为 5501 ~ 11000 范围内的哈希槽提供服务。
所以我们在创建集群的时候,一定要为每个主节点都添加对应的从节点。比如,集群包含主节点 A、B、C,以及从节点 A1、B1、C1,那么即使 B 挂掉系统也可以继续正确工作。
因为 B1 节点属于 B 节点的子节点,所以 Redis 集群将会选择 B1 节点作为新的主节点,集群将会继续正确地提供服务。当 B 重新开启后,它就会变成 B1 的从节点。但是请注意,如果节点 B 和 B1 同时挂掉,Redis Cluster 就无法继续正确地提供服务了。
以上几种架构模式,每种都有各自的优缺点,在实际场景中要根据业务特点去选择合适的模式使用。
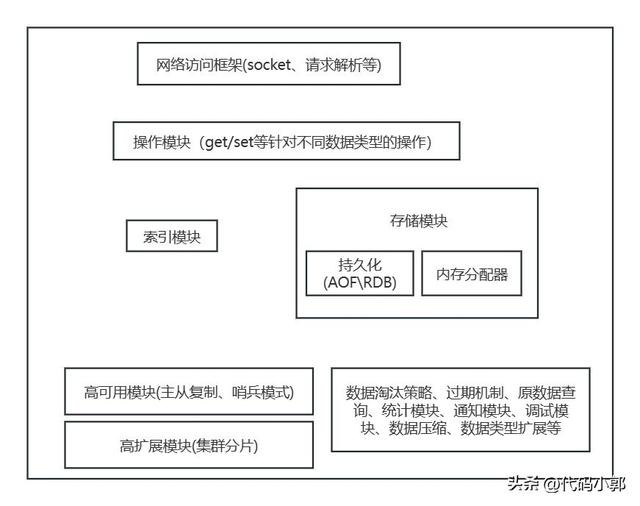
通过网络框架以 Socket 通信的形式对外提供键值对操作,包括socket服务,和协议解析,客户端发送命令时,命令会被封装到网络请求中传输给redis。
主要对各种数据进行操作,如get 、put 、delete 、scan操作等。
索引模块主要目的是为了通过key值快速定位value值,从而进行操作。 redis使用的索引模块为哈希表。redis存储内存的高性能随机访问特性可以很好地与哈希表 O(1) 的操作复杂度相匹配。
主要完成保存数据的工作,存储数据模型为 key-value形式,value支持丰富的数据类型。包括字符串,列表 ,哈希表,集合等。不同的数据类型能支持不同的业务需求。
其中的持久化模块主要对数据进行持久化,当系统重启时,能够快速恢复服务。redis的持久化策略分为:日志(AOF)和快照(RDB)两种方式。
主从复制:主从架构中用到(一个Master至少一个slave),master -> slave 数据复制
哨兵:主从架构实现高可用(一个Master至少一个slave),在master故障的时候,快速将slave切换成master,实现快速的灾难恢复,实现高可用性;
切片集群,也叫分片集群(集群分片),就是指启动多个 Redis 实例组成一个集群,然后按照一定的规则,把收到的数据划分成多份,每一份用一个实例来保存。
Redis Cluster是Redis提供的分布式高可扩展解决方案。
还有一些其他模块,例如:数据压缩、过期机制、数据淘汰策略、主从复制、集群化、高可用等功能,另外还可以增加统计模块、通知模块、调试模块、元数据查询等辅助功能。
一个redis命令请求从用户端发起到获得结果的过程中,redis客户端和服务器端都需要完成一系列操作。
比如发送一个set命令:
set key value这个过程中经历了如下的几个处理阶段:
1)客户端发送命令请求
2)服务器端读取命令请求
3)服务器端执行命令
4)服务器端将命令回复发送回客户端
5)客户端接收并打印命令回复
整体流程图如下:

下面小郭将针对图中的每个处理阶段展开说一说细节。
当用户在客户端中键入一个命令请求时, 客户端会将这个命令请求转换成约定的协议格式, 然后通过连接到服务器的套接字, 将协议格式的命令请求发送给服务器。

当客户端与服务器之间的连接套接字因为客户端的写入而变得可读时, 服务器将调用命令请求处理器来执行以下操作:
1)读取套接字中协议格式的命令请求,并将其保存到客户端状态的输入缓冲区里面。
2)对输入缓冲区中的命令请求进行分析,提取出命令请求中包含的命令参数,以及命令参数的个数,然后分别将参数和参数个数保存到客户端状态的argv属性和argc属性里面。
3)调用命令执行处理器,执行客户端指定的命令。
1)命令执行器:查找命令实现
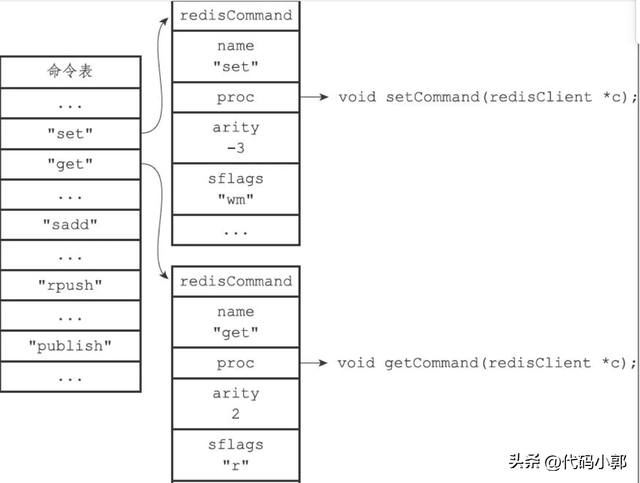
命令执行器根据客户端状态的argv[0]参数,在命令表(command table)中查找参数所指定的命令,并将找到的命令保存到客户端状态的cmd属性里面。
命令表是一个字典,字典的键是一个个命令名字,比如"set"、"get"、"del"等等。而字典的值则是一个个redisCommand结构,每个redisCommand结构记录了一个Redis命令的实现信息。
需要注意的是命令名字的大小写不影响命令表的查找结果:
因为命令表使用的是大小写无关的查找算法, 无论输入的命令名字是大写、小写或者混合大小写, 只要命令的名字是正确的, 就能找到相应的 redisCommand 结构。
比如说, 无论用户输入的命令名字是 "SET" 、 "set" 、 "SeT" 又或者 "sEt" , 命令表返回的都是同一个 redisCommand 结构。下面是redisCommand结构 的属性描述:
属性名 | 类型 | 作用 |
name | char * | 保存命令的名字,比如“set” |
proc | redisCommandProc * | 函数指针,指向命令的具体实现函数,比如setCommand。redisCommandProc类型的定义为typedef void redisCommandProc(redisClient *c); |
arity | int | 命令参数的个数,用于检查命令请求的格式是否正确。如果这个值为-N,那么表示参数的数量大于等于N。注意命令的名字本身也是一个参数,比如说SET msg "hello world"命令的参数分别是"SET"、"msg"、"hello world"。而不仅仅是"msg"和"hello world" |
sflags | char * | 字符串形式的标识值,这个值记录了命令的属性,比如这个命令是写命令还是读命令,这个命令是否允许在载入数据时使用,这个命令是否允许在Lua脚本中使用等等含义。接下来的表格有详细说明 |
flags | int | 对sflags标识进行分析得出的二进制标识,由程序自动生成。服务器对命令标识进行检查时使用的都是flags属性而不是sflags属性,因为对二进制标识的检查可以方便地通过&、^、~等操作来完成 |
calls | long long | 服务器总共执行了多少次这个命令 |
milliseconds | long long | 服务器执行这个命令所耗费的总时长 |
sflags标识 | 含义 | 带有这个标识的命令 |
w | 这是一个写入命令,可能会修改数据库 | SET、RPUSH、DEL等等 |
r | 这是一个只读命令,不会修改数据库 | GET、STRLEN、EXISTS等等 |
m | 这个命令可能会占用大量内存,执行之前需要先检查服务器的内存使用情况,如果内存紧缺的话就可以禁止执行这个命令 | SET、APPEND、RPUSH、LPUSH、SADD等等 |
a | 这是一个管理命令 | SAVE、BGSAVE、SHUTDOWN等等 |
P | 这是一个发布与订阅功能方面的命令 | PUBLISH、SUBSCRIBE、PUBSUB等等 |
s | 这个命令不可以在Lua脚本中使用 | BRPOP、BLPOP、BRPOPLPUSH、SPOP等等 |
R | 这是一个随机命令,对于相同的数据集和相同的参数,命令返回的结果可能不同 | SPOP、SRANDMEMBER、SSCAN、RANDOMKEY等等 |
S | 当在Lua脚本中执行这个命令时,对这个命令的输出结果进行一次排序,使得命令的结果有序 | SINTER、SUNION、SDIFF、SMEMBERS、KEYS等等 |
l | 这个命令可以在服务器载入数据的过程中使用 | INFO、SHUTDOWN、PUBLISH等等 |
t | 这是一个允许从服务器在带有过期数据时使用的命令 | SLAVEOF、PING、INFO等等 |
M | 这个命令在监视器(monitor)模式下不会自动被传播(propagate) | EXEC |
举个栗子:
GET命令的名字为"get",实现函数为getCommand函数;命令的参数个数为2,表示命令只接受两个参数;命令的标识为"r",表示这是一个只读命令。
SET命令的名字为"set",实现函数为setCommand;命令的参数个数为-3,表示命令接受三个或以上数量的参数;命令的标识为"wm",表示SET命令是一个写入命令,并且在执行这个命令之前,服务器应该对占用内存状况进行检查,因为这个命令可能会占用大量内存。
2)命令执行器:执行校验
经过之前的阶段, 服务器端已经将执行请求命令所需的参数(保存在客户端状态的 argv 属性)、参数个数(保存在客户端状态的 argc 属性)、命令实现函数(保存在客户端状态的 cmd 属性)都解析齐了, 但是在真正执行命令之前, 还需要进行一些预备操作, 从而确保命令可以正确、顺利地被执行, 这些主要操作包括:
检查客户端状态的cmd指针是否指向NULL。如果是的话, 那么说明用户输入的命令名字找不到相应的命令实现, 服务器不再执行后续步骤, 并向客户端返回一个错误。
根据客户端cmd属性指向的redisCommand结构的arity属性,检查命令请求所给定的参数个数是否正确。当参数个数不正确时, 不再执行后续步骤, 直接向客户端返回一个错误。 比如说, 如果 redisCommand 结构的 arity 属性的值为 -3 , 那么用户输入的命令参数个数必须大于等于 3 个才行。
检查客户端是否已经通过了身份验证,未通过身份验证的客户端只能执行AUTH命令。如果未通过身份验证的客户端试图执行除 AUTH 命令之外的其他命令, 那么服务器将向客户端返回一个错误。
如果服务器打开了maxmemory功能,那么在执行命令之前,先检查服务器的内存占用情况,并在有需要时进行内存回收,从而使得接下来的命令可以顺利执行。 如果内存回收失败, 那么不再执行后续步骤, 向客户端返回一个错误。
Redis设计者是非常严谨的,每个环节都考虑的非常齐全,执行命令前还校验了许多方面,例如:
如果服务器上一次执行 BGSAVE 命令时出错, 并且服务器打开了
stop-writes-on-bgsave-error 功能, 而且服务器即将要执行的命令是一个写命令, 那么服务器将拒绝执行这个命令, 并向客户端返回一个错误。
如果客户端当前正在用 SUBSCRIBE 命令订阅频道, 或者正在用 PSUBSCRIBE 命令订阅模式, 那么服务器只会执行客户端发来的 SUBSCRIBE 、 PSUBSCRIBE 、 UNSUBSCRIBE 、 PUNSUBSCRIBE 四个命令, 其他别的命令都会被服务器拒绝。
如果服务器正在进行数据载入, 那么客户端发送的命令必须带有 l 标识(比如 INFO 、 SHUTDOWN 、 PUBLISH ,等等)才会被服务器执行, 其他别的命令都会被服务器拒绝。
如果服务器因为执行 Lua 脚本而超时并进入阻塞状态, 那么服务器只会执行客户端发来的 SHUTDOWN nosave 命令和 SCRIPT KILL 命令, 其他别的命令都会被服务器拒绝。
如果客户端正在执行事务, 那么服务器只会执行客户端发来的 EXEC 、 DISCARD 、 MULTI 、 WATCH 四个命令, 其他命令都会被放进事务队列中。
如果服务器打开了监视器功能, 那么服务器会将要执行的命令和参数等信息发送给监视器。
只有当通过了上面的所有校验,命令才会真正的开始执行。
3)命令执行器:调用命令实现函数
经过前面的步骤,服务器将要执行命令的实现保存到了客户端状态的cmd属性里面,并将命令的参数和参数个数分别保存到了客户端状态的argv属性和argv属性里面,当服务器执行命令时,只需要一个指向客户端状态的指针作为参数,调用实际执行函数。如下图所示:
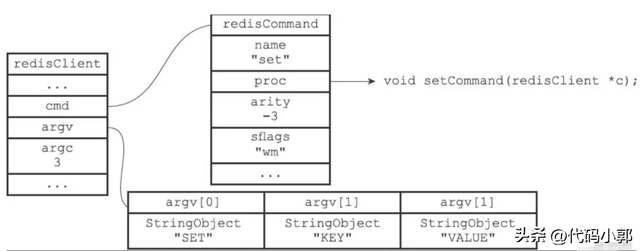
命令实现函数内部会执行指定的操作,并产生相应的命令回复,这些回复会被保存在客户端状态的输出缓冲区里面(buf属性和reply属性),之后实现函数还会为客户端的套接字关联命令回复处理器,这个处理器负责将命令回复返回给客户端。
4)命令执行器:执行收尾工作
如在Redis.config里面有相关配置,则后续操作包含:慢日志记录、redisCommand结构属性更新、AOF持久化记录、主从复制命令传播等。
当以上操作都执行完了之后, 服务器对于当前命令的执行到此就告一段落了, 之后服务器就可以继续从文件事件处理器中取出并处理下一个命令请求了。
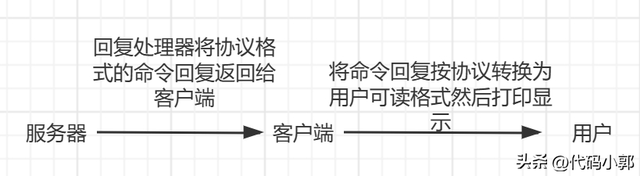
命令实现函数执行完成后会将命令回复保存到客户端的输出缓冲区里面, 并为客户端的套接字关联命令回复处理器, 当客户端套接字变为可写状态时, 服务器就会执行命令回复处理器, 将保存在客户端输出缓冲区中的命令回复发送给客户端。
当命令回复发送完毕之后, 回复处理器会清空客户端状态的输出缓冲区, 为处理下一个命令请求做好准备。
当客户端接收到协议格式的命令回复之后, 它会将这些回复转换成人类可读的格式, 并打印给用户观看(Redis 自带的 客户端和开源的客户端都需要遵循redis的协议格式进行转换)
以上就是 Redis 客户端和服务器执行命令请求的整个过程了。
彻底搞懂Redis系列《二》全量配置文件详细说明
彻底搞懂Redis系列《三》数据类型总览
说到事务,大家可能最先想到的就是关系型数据库中的事务管理,其实redis中的事务也有类似的特点:
但是redis的事务和关系型数据库的事务有一个最大的区别:redis事务不会回滚,即使事务中有某条/某些命令执行失败了, 事务队列中的其他命令仍然会继续执行完毕。
为什么 Redis 不支持回滚(roll back)?
redis官方文档中大概是这样解释的:
1)redis 命令只会因为错误的语法而失败,或是命令用在了错误类型的键上面:也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该带到生产环境中。
2)因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
Redis 中的脚本(比如lua)本身也是一种事务, 所以任何在事务里可以完成的事, 在脚本里面也能完成。 并且一般来说, 使用脚本要来得更简单,并且速度更快。因为脚本功能是 Redis 2.6 才引入的, 而事务功能则更早之前就存在了, 所以 Redis 才会同时存在两种处理事务的方法。
本小节只总结原始的事务功能。
MULTI 、 EXEC 、 DISCARD 和 WATCH 是 Redis 事务相关的命令。
MULTI负责开启一个事务,执行它总是返回’OK‘,只有当执行了MULTI,才可以继续接下来的操作。
MULTI执行之后, Redis客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行, 而是被放到一个队列中, 当EXEC命令被调用时, 所有队列中的命令才会被执行。 通过调用DISCARD, 客户端可以清空事务队列, 并放弃执行事务。
EXEC命令负责触发并顺序执行事务的命令队列中的全部命令。
当使用 AOF 方式做持久化的时候, Redis 会使用单个 write(2) 命令将事务写入到磁盘中,然而,如果 Redis 服务器因为某些原因被管理员杀死,或者遇上某种硬件故障,那么可能只有部分事务命令会被成功写入到磁盘中。
如果 Redis 在重新启动时发现 AOF 文件出了这样的问题,那么它会退出,并汇报一个错误。
使用redis-check-aof程序可以修复这一问题:它会移除 AOF 文件中不完整事务的信息,确保服务器可以顺利启动。
从 redis的2.2 版本开始,Redis 还可以通过乐观锁(optimistic lock)实现 CAS (check-and-set)操作。
以下是一个事务例子, 它原子地增加了 A 和 B 两个键的值:
[root@XXX ~]# redis-cli -h 127.0.0.1 -p 6379127.0.0.1:6379> MULTIOK127.0.0.1:6379(TX)> INCR AQUEUED127.0.0.1:6379(TX)> INCR BQUEUED127.0.0.1:6379(TX)> EXEC1) (integer) 12) (integer) 1127.0.0.1:6379>EXEC 命令的回复是一个数组, 数组中的每个元素都是执行事务中的命令所产生的回复。 其中, 回复元素的先后顺序和命令发送的先后顺序一致。
在 EXEC 命令执行之后所产生的错误, 并没有对它们进行特别处理: 即使事务中有某个/某些命令在执行时产生了错误, 事务中的其他命令仍然会被继续执行。
通过DISCARD命令,客户端可以清空事务中的命令队列, 并放弃执行当前事务。
下面演示如何使用DISCARD:
127.0.0.1:6379> SET AAA 10OK127.0.0.1:6379> GET AAA"10"127.0.0.1:6379> MULTIOK127.0.0.1:6379(TX)> INCR AAAQUEUED127.0.0.1:6379(TX)> DISCARDOK127.0.0.1:6379> GET AAA"10"127.0.0.1:6379>在上面的示例中,创建了一个初始值为10的key"AAA", 然后开启一个事务对该key进行自增,在执行EXEC之前,执行了DISCARD放弃执行。
假如我们在执行redis事务操作某些键的过程中,有其它客户端对相同的键做了修改,那么此时事务执行就会导致业务问题,Redis提供了WATCH机制来监控某个键是否被修改。
WATCH命令可以为 Redis 事务提供 check-and-set (CAS)行为。
被 WATCH 的键会被监视, 如果有至少一个被监视的键在EXEC执行之前被修改了, 那么整个事务都会被取消,EXEC返回nil-reply来表示事务已经失败。
WATCH 命令可以被调用多次。 对键的监视从WATCH执行之后开始生效, 直到调用 EXEC为止。当客户端断开连接时, 该客户端对键的监视也会被取消。
我们可以在单个WATCH 命令中监视任意多个键,示例:
redis> WATCH key1 key2 key3OKRedis提供了四个命令来设置过期时间(生存时间)。
EXPIRE <key> <ttl> :表示将键 key 的生存时间设置为 ttl 秒。PEXPIRE <key> <ttl> :表示将键 key 的生存时间设置为 ttl 毫秒。EXPIREAT <key> <timestamp> :表示将键 key 的生存时间设置为 timestamp 所指定的秒数时间戳。PEXPIREAT <key> <timestamp> :表示将键 key 的生存时间设置为 timestamp 所指定的毫秒数时间戳。在Redis内部实现中,前面三个设置过期时间的命令最后都会转换成最后一个PEXPIREAT 命令来完成。
另外还有三个命令:
//移除键的过期时间PERSIST <key> :表示将key的过期时间移除。//返回键的剩余生存时间TTL <key> :以秒的单位返回键 key 的剩余生存时间。PTTL <key> :以毫秒的单位返回键 key 的剩余生存时间。redis对于已过期的key,有下面两种清理策略:
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。
Redis 默认每秒进行十次过期扫描(100ms一次),过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略:
a.从过期字典中随机 20 个 key;b.删除这 20 个 key 中已经过期的 key;c.如果过期的 key 比率超过 1/4,那就重复步骤 1;redis默认是每隔 100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的,为什么要随机呢?想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载。
在Redis 2.8 版本后,可以通过修改配置文件redis.conf 的 hz 选项来调整这个扫描次数,默认是10:
# The range is between 1 and 500, however a value over 100 is usually not# a good idea. Most users should use the default of 10 and raise this up to# 100 only in environments where very low latency is required.hz 10惰性策略就是在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除,不会给你返回任何东西。
redis.conf中MEMORY MANAGEMENT部分就是对内存淘汰策略的相关配置。
我们的机器资源是有限的,安装完redis之后最好是在redis根目录中找到redis.conf文件,在配置文件中设置redis的最大可用内存大小:
# 设置 Redis 最大使用内存大小为200Mmaxmemory 200mb //指定最大内存为200mb# 下面的写法均合法:# maxmemory 1024000# maxmemory 1GB# maxmemory 1G# maxmemory 1024KB# maxmemory 1024K# maxmemory 1024MB上面的配置,当 Redis 使用的内存超过 200Mb 时,就开始对数据进行淘汰。
每进行一次redis操作的时候,redis都会检测可用内存,判断是否要进行内存淘汰,当超过可用内存的时候,redis就会使用对应淘汰策略。
内存淘汰策略有8种,分别如下:
该策略对于写请求不再提供服务,会直接返回错误,当然排除del等特殊操作,redis默认是no-envicition策略。
从redis的数据集(server.db[i].dict)随机选取key进行淘汰
使用LRU(Least Recently Used,最近最少使用)算法,从redis从redis的数据集(server.db[i].dict)中选取使用最少的key进行淘汰
从已设置过期时间的数据集中任意选择key,进行随机淘汰
从已设置过期时间的数据集中选取即将过期的key,进行淘汰
使用LRU(Least Recently Used,最近最少使用)算法,从已设置过期时间的数据集中,选取最少使用的进行淘汰
使用LFU(Least Frequently Used,最不经常使用),从设置了过期时间的键中选择某段时间之内使用频次最小的键值对清除掉
使用LFU(Least Frequently Used,最不经常使用),从所有的键中选择某段时间之内使用频次最少的键值对清除
上面这八种策略可以分为4种类型:lru、lfu、random、ttl。默认是no-envicition,可以通过修改配置redis.conf来调整策略:
每个配置项的具体含义可以查看全量配置文件详细说明
############################## MEMORY MANAGEMENT(内存策略管理) ################################# maxmemory <bytes># maxmemory-policy noeviction# maxmemory-samples 5# maxmemory-eviction-tenacity 10# replica-ignore-maxmemory yes# active-expire-effort 1redis 提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
RDB 方式,是定期将 redis 某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法。
Redis会单独创建一个子进程(执行文件IO操作),将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。而主进程是不会进行任何 IO 操作的,这样也确保了 redis 极高的性能。
RDB持久化主要是通过SAVE和BGSAVE两个命令对Redis中当前的数据做snapshot并生成rdb文件来实现的。其中SAVE是阻塞的,BGSAVE是非阻塞的(通过fork了一个子进程来完成的)在Redis启动的时候会检查这些rdb文件,然后载入rdb文件中未过期的数据到服务器中。
RDB模块相关配置汇总如下:
每个配置项的具体含义可以查看全量配置文件详细说明
################################ SNAPSHOTTING (RDB持久化配置) ################################# save 3600 1 300 100 60 10000# save ""stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdbfilename dump.rdbrdb-del-sync-files nodir ./AOF,英文是 Append Only File,即只允许追加不允许改写的文件。
和RDB相比,其实是换了一个角度来实现持久化,那就是将 redis 执行过的所有写指令记录下来,在下次 redis 重新启动时,只要把这些写指令按先后顺序再重复执行一遍,就可以实现数据恢复了。
通过配置 redis.conf 中的 appendonly yes 就可以打开 AOF 功能。
appendonly yes开启AOF配置后,只要有写操作(如 SET 等),命令就会被追加到 AOF 文件的末尾。
默认的 AOF 持久化策略是每秒钟 fsync 一次(fsync 是指把缓存中的写指令记录到磁盘中):
//everysec代表每秒一次,在这种情况下,redis 仍然可以保持很好的处理性能,即使 redis 故障,也只会丢失最近 1 秒钟的数据。appendfsync everysec如果在AOF追加日志时,恰好遇到磁盘空间满、inode 满或断电等情况导致日志写入不完整,也没有关系,redis 提供了 redis-check-aof 工具,可以用来进行日志修复。
AOF 文件重写(rewrite)机制
采用文件追加方式不断追加写入命令,且不做任何限制措施的话,会使得AOF 文件会变得越来越大。
因此,redis 设计者加入了 AOF 文件重写(rewrite)机制,即当 AOF 文件的大小超过所设定的阈值时,redis 就会主动压缩 AOF 文件的内容,只保留可以恢复数据的最小指令集。
举个栗子:假如我们对同一个key,执行了200次set指令,在 AOF 文件中就要存储 200 条指令,其实完全可以把这 200 条指令合并成一条 SET 指令,也就是取最后一次set指令进行追加就行了,这就是重写机制的核心逻辑。
文件重写原理
在进行 AOF 重写时,也是采用先写临时文件,全部完成后再替换的流程,所以断电、磁盘满等问题都不会影响 AOF 文件的可用性。
在重写即将开始时,redis 会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的 AOF 文件,并将其包含的指令进行分析压缩写入到一个临时文件中。
与此同时,主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的 AOF 文件中,这样做是保证原有的 AOF 文件的可用性,避免在重写过程中出现意外。
当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新 AOF 文件中。
当追加结束后,redis 就会用新 AOF 文件来整体代替旧 AOF 文件,之后再有新的写指令,就都会追加到新的 AOF 文件中了。
AOF相关的配置项汇总如下:
每个配置项的具体含义可以查看全量配置文件详细说明
################APPEND ONLY MODE(AOF持久化配置) ###############################appendonly noappendfilename "appendonly.aof"appenddirname "appendonlydir"appendfsync everysecno-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yesaof-use-rdb-preamble yesaof-timestamp-enabled no官方的建议是两种持久化方式同时使用,这样可以提供更可靠的持久化方案。在这种情况下,如果 redis 重启的话,则会优先采用 AOF 方式来进行数据恢复,这是因为 AOF 方式的数据恢复完整度更高。
如果项目种没有数据持久化的需求,也完全可以关闭 RDB 和 AOF 方式,这样的话,redis 将变成一个纯内存数据库,就像 memcache 一样。
下面对AOF和RDB在多个维度做对比:
1)持久化方式
RDB定时对整个内存做快照;AOF记录每一次执行的命令。
2)数据完整性
RDB不完整,两次备份之间会存在数据丢失;AOF相对完整,取决于刷盘策略配置。
3)文件大小
RDB有压缩,文件体积小;AOF记录命令,文件体积大,但是经过重写后会减小。
3)宕机恢复速度
RDB很快,AOF慢
4)数据恢复优先级
RDB低,因为数据完整性不如AOF;AOF高,因为数据完整性更高
5)系统资源占用
RDB高,大量CPU和内存的消耗;AOF低,主要是磁盘IO资源,但AOF重写时会占用大量CPU和内存资源
6)使用场景
RDB使用于可以容忍数分钟的数据丢失,追求赶快的启动速度的场景;AOF使用于对数据安全性要求较高的场景。
由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。
这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
Redis 发布/订阅是一种消息通信模式,发送者(pub)发布消息,而订阅者(sub)接收消息。
传递消息的通道称为channel(频道),Redis客户端可以订阅任意数量的频道。
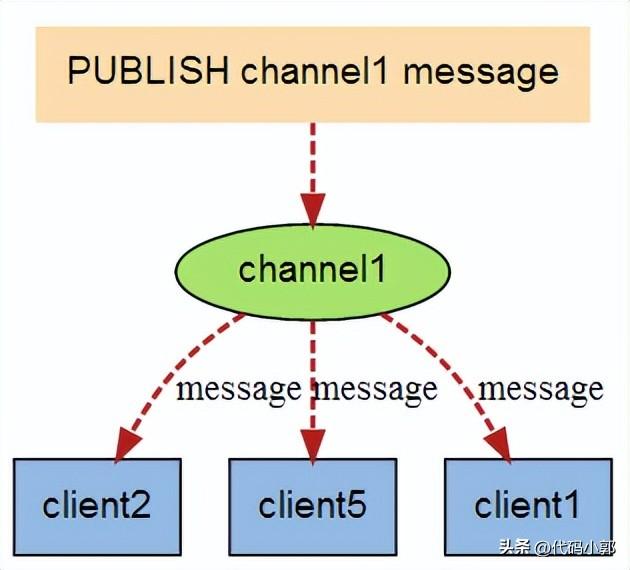
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
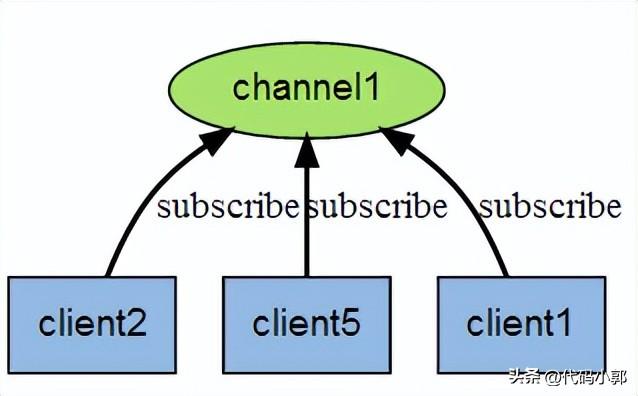
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
使用非常简单,在下面的例子中我们创建了订阅频道名为 pubsubdemo,
先开启一个redis客户端A,代表消息订阅者,订阅频道pubsubdemo的消息:
127.0.0.1:6379> subscribe pubsubdemo1) "subscribe"2) "pubsubdemo"3) (integer) 1再重新开启一个新的 redis 客户端B,代表消息发布者,在频道 pubsubdemo发布消息,订阅者A就能接收到消息。
127.0.0.1:6379> publish pubsubdemo "helloredis"(integer) 1127.0.0.1:6379># 订阅者A的客户端会显示如下消息1) "message"2) "pubsubdemo"3) "helloredis"命令语法 | 描述 |
PSUBSCRIBE pattern [pattern ...] | 订阅一个或多个符合给定模式的频道 |
PUBSUB subcommand [argument [argument ...]] | 查看订阅与发布系统状态 |
PUBLISH channel message | 将信息发送到指定的频道 |
PUNSUBSCRIBE [pattern [pattern ...]] | 退订所有给定模式的频道 |
SUBSCRIBE channel [channel ...] | 订阅给定的一个或多个频道的信息 |
UNSUBSCRIBE [channel [channel ...]] | 指退订给定的频道 |
本节以SpringBoot应用来示范如何接入redis
1、添加redis所需依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId></dependency>这里我们直接引入了
spring-boot-starter-data-redis这个springBoot本身就已经提供好了的starter, 我们可以点击去看一下这个starter中包含了哪些依赖:
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <version>2.7.14</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> <version>2.7.14</version> <scope>compile</scope> </dependency> <dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>6.1.10.RELEASE</version> <scope>compile</scope> </dependency> </dependencies>可以发现,里面包含了spring-data-redis和 lettuce-core两个核心包,这就是为什么说我们的
spring-boot-starter-data-redis默认使用的就是lettuce这个客户端。
如果我们想要使用jedis客户端怎么办呢?只需要排除lettuce这个依赖,再引入jedis的相关依赖就可以了,这里得亏springboot强大的自动配置功能。
2、添加redis配置
# redisspring.redis.host=localhostspring.redis.port=6379spring.redis.password=spring.redis.database=0如果是使用的集群模式部署redis,那么配置如下:
#spring.redis.cluster.nodes=10.255.144.115:7001,10.255.144.115:7002,10.255.144.115:7003#spring.redis.cluster.max-redirects=3如果我们想要给我们的redis客户端(lettuce)配置上连接池,可以增加如下配置:
spring.redis.lettuce.pool.max-idle=16spring.redis.lettuce.pool.max-active=32spring.redis.lettuce.pool.min-idle=8#如果使用的是jedis,就把lettuce换成jedis(同时要注意依赖也是要换的)。#spring.redis.jedis.pool.max-idle=16#spring.redis.jedis.pool.max-active=32#spring.redis.jedis.pool.min-idle=8上面增加了连接池的配置,还需要引入一个连接池依赖,才会生效,pom依赖如下:
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId></dependency>3、使用redis进行读写
使用spring-data-redis中为我们提供的 RedisTemplate 这个类,就可以操作redis读写缓存了
package com.gyd.contoller;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestController@RequestMapping("/redis")public class RedisController { private final RedisTemplate redisTemplate; public RedisController(RedisTemplate redisTemplate) { this.redisTemplate = redisTemplate; } @GetMapping("/save") public String save(String key, String value){ redisTemplate.opsForValue().set(key, value); return "success"; } @GetMapping("/get") public String get(String key){ Object value = redisTemplate.opsForValue().get(key); return null != value ? (String) value :null; }}上面代码简单演示了使用set和get命令和redis服务端进行交互,实际业务中可能涉及到其它的命令,一般是将RedisTemplate封装为工具类,然后提供给业务类进行调用。
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞 。
常见解决方案:
1)设置热点数据永远不过期
2)接口限流与熔断,降级
3)布隆过滤器
4)加互斥锁
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。
常见解决方案:Bitmap布隆过滤器、缓存空对象
缓存雪崩是指,缓存层不能正常工作了(服务器重启期间、大量缓存集中在某个时间失效)。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
缓存雪崩的解决方案:redis高可用(集群部署)、限流降级、数据预热、多级缓存、key有效期增加随机数等
一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。
只要涉及到数据库和缓存双写,就必然会存在不一致的问题。如果我们的业务场景对数据有强一致性要求,那就不能放缓存。
既然使用了缓存,我们所做的一切方案,就只能保证数据最终一致性。只能降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
那么如何尽最大可能保证双写的一致性呢?
这里可以采取一些手段,比如:
1)缓存延时双删
2)删除缓存重试机制
3)读取binlog异步删除缓存
持续补充...
https://redis.io/docs/
http://www.redis.cn/documentation.html
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号