掌握Node.js:实战编写一个爬虫程序
发表时间: 2018-02-07 15:20
这个Node.js爬虫是我之前写过的一个简单的小爬虫,我之前写的文章都是Python的爬虫,先来看看Node.js和Python的比较
Node.js优于Python的地方
快:这个快有两方面,第一是V8引擎快,在V8引擎背后操刀的是Lars Bak大神,他创造过高性能SmallTalk引擎和Java Hotspot引擎(现在Java的默认VM),他带领下的V8引擎让Javascript速度达到了一个新的阶段。第二是异步执行,Node.js功能上是一个基于V8引擎的异步网络和IO Library,和Python的Twisted很像,不同的是Node.js的event loop是很底层的深入在语言中的,可以想象成整个文件在执行的时候就在一个很大的event loop里。
npm:npm可以说是用起来最顺手的package management了,npm作为Node.js的官方package management,汇集了整个社区最集中的资源。不像Python经历过easy_install和pip,还有2to3的问题。
Windows支持:Node.js有微软的加持,Windows基本被视为一等公民来支持,libuv已经可以很好的做到统一跨平台的API;而Python虽然也对Windows有官方的支持,但是总感觉是二等公民,时不时出些问题。
Python优于Node.js的地方
语言:就单纯从语言的角度来说,Python写起来要比Javascript舒服很多。Javascript设计本身有许多缺陷,毕竟当时设计的时候只是作为在浏览器中做一些简单任务的script,所以代码一旦庞大,维护还是有困难(不过Node.js的module很大的改善了这个问题)。不过用Coffeescript可以很大的改善Javascript,几乎可以和Python等同。
成熟:成熟包括语言本身已经成熟,还有Framework和ecosystem也很庞大。Node.js的绝大多数framework都很新,有的API一直在变,有的感觉已经不在维护,总之没有一个像Django那种百足之虫感觉的framework。
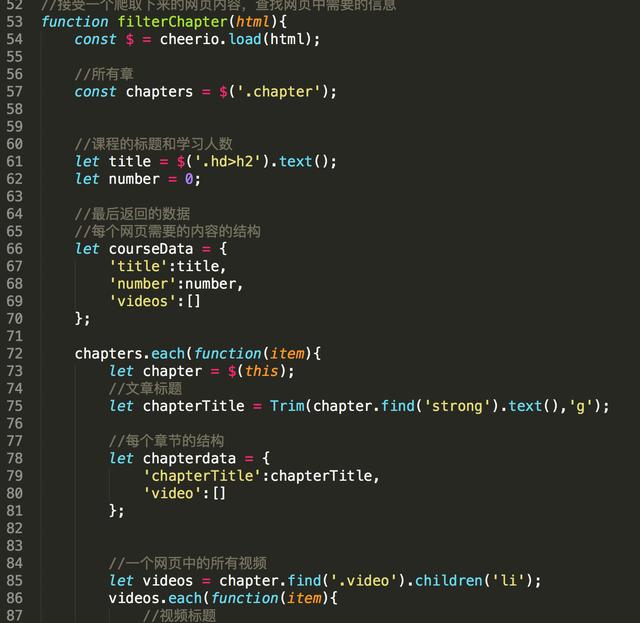
这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让我们方便的操作HTML,就像是用jQ一样
开始前,记得
npm install cheerio
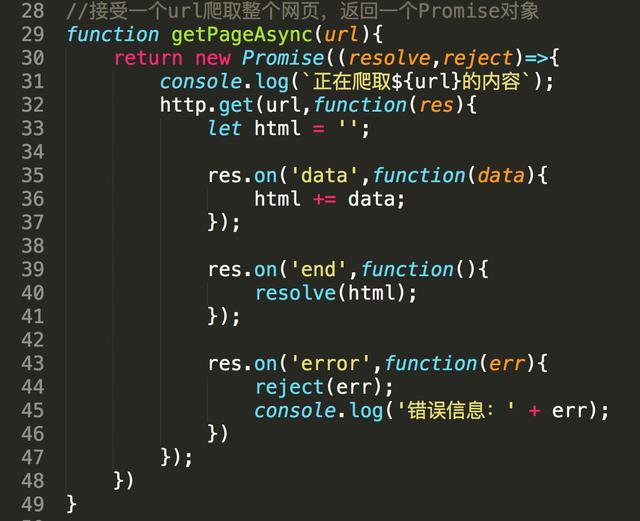
为了能够并发的进行爬取,用到了Promise对象
在慕课网中,每个课程都有一个ID,我们事先要把想要获取课程的ID写到一个数组中,而且每个课程的地址都是一个相同的地址加上ID,所以我们只要把地址和ID拼接起来就是课程的地址
为了使获取每个课程内容时并发执行,要使用Promise中的all方法
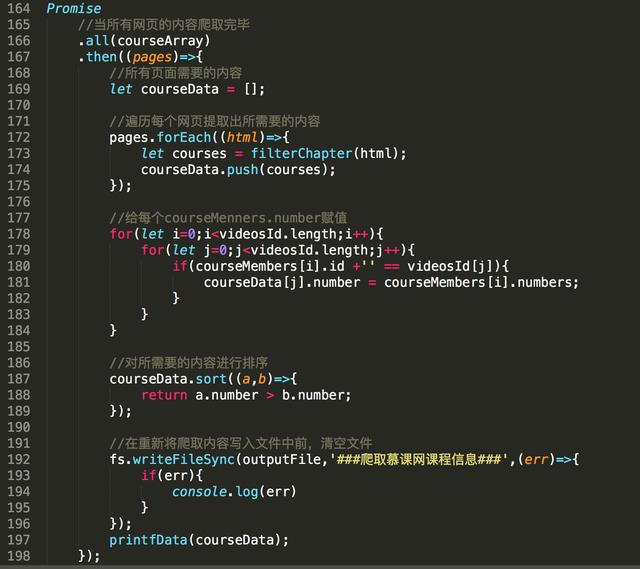
在then方法中,pages是每个课程的HTML页面,我们还得从中提取出我们需要的信息,需要使用下面的函数
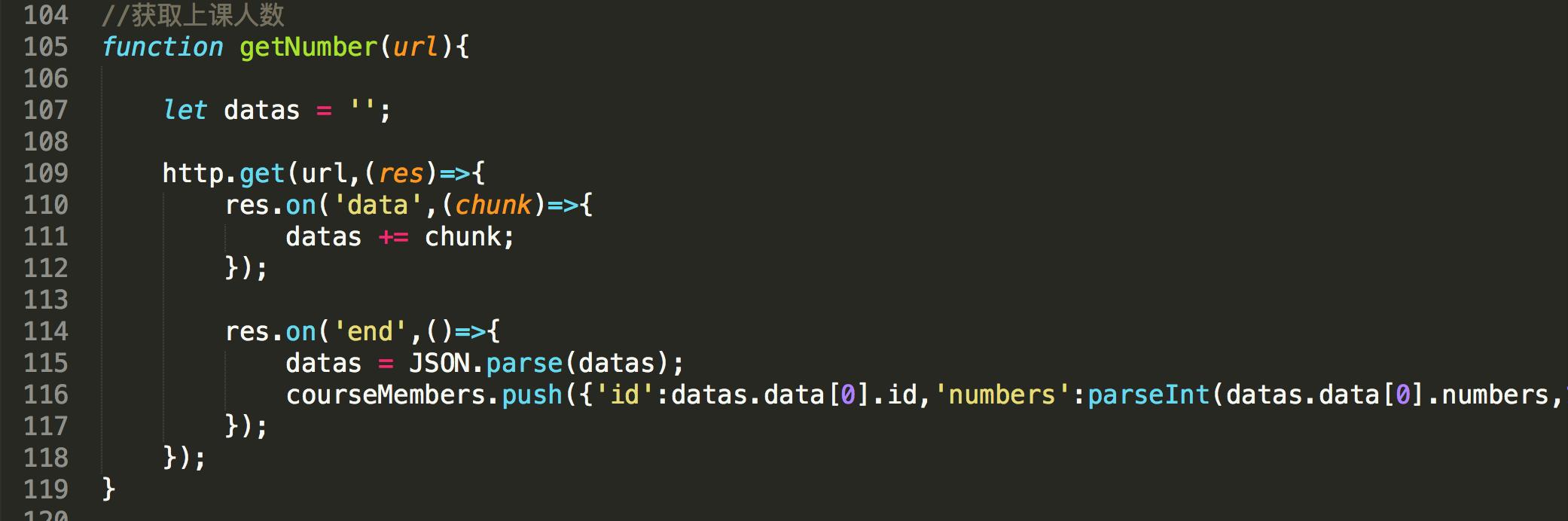
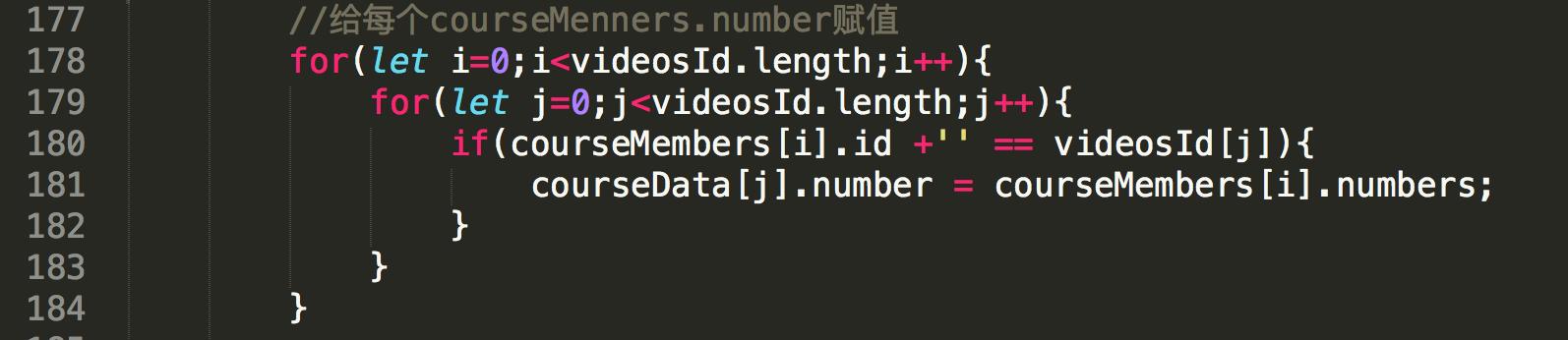
注意:在上面中将课程的学习人数设置为了0是因为学习课程人数是用Ajax动态获取,所以我在后面写了方法专门获取学习课程人数,其中用到的Trim()方法是去除文本中的空格
获取学习课程的人数:
这样就将想获取课程的学习人数都添加到了courseMembers数组中,在最后将学习课程的人数在赋值给相对应的课程
我们获取到了数据,就要把它按照一定的格式存到一个文件中
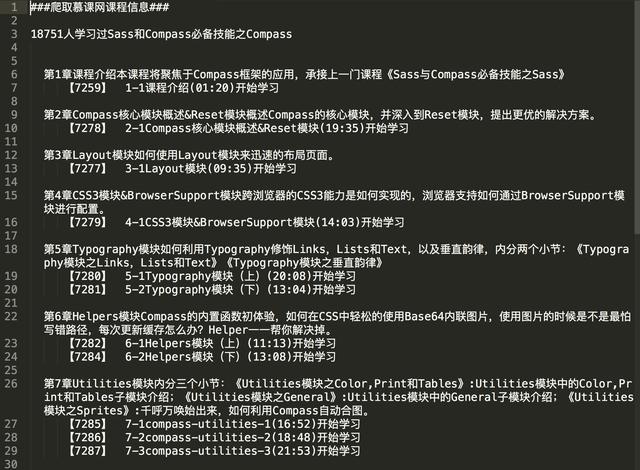
最后获取到的数据
本文章是由热衷python和前端原创发布,如需转载请注明出处
欢迎大家关注头条号:热衷python和前端
如果有需要源码的同学就留言或者私聊我吧
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12



 鲁公网安备37020202000738号
鲁公网安备37020202000738号