数据库为何偏爱有序索引,程序员却钟情哈希表?
发表时间: 2019-12-21 18:19
为什么程序和数据库之间的“默认”选择会产生不同呢?

作者 | Evan Jones
译者 | 弯月,责编 | 屠敏
以下为译文:
我可以肯定地说,哈希表远比有序数据结构更常见,Go中的map、Python中的dict、Java中的HashMap等都是哈希表,而树结构只在保存有序数据结构时才使用。有一次,在谈到Google优化C++的哈希表时,有人指出在整个Google的服务器中,有1%的CPU和4%的内存都被哈希表使用了。然而,数据库默认总是会使用有序索引,通常是B树。为什么程序和数据库之间的“默认”选择会产生不同呢?说到底两者都是为了同一个目标:访问数据。一年前,我曾就这个问题在Twitter上发表了推文,并得到了许多有趣的答案。下面就来总结一下我得到的答案。
常见的答案是,当在内存中存储数据时,哈希表的效率很高,而B树的设计旨在以块的形式访问较慢的存储。然而,这不是决定性的属性。我们也有为访问磁盘而设计的哈希表,例如MySQL的哈希索引;也有许多在内存中使用的树,例如Java的TreeMap、C++的映射;甚至连B树都有内存中使用的版本。
我认为最重要的答案是,B树更适合于“一般用途”,它们能够以较低的总成本访问大规模的持久数据。换句话说,即使在访问大部分工作负载都是单个值的数据时,B树的速度较慢,但考虑到罕见的操作和多个索引的成本,B树的表现还是更为突出。在本文中,我将简要解释哈希表和B树之间的差异,然后讨论持久性数据与内存数据在需求上有何不同。最后,尽管我认为“内存应该使用有序的数据结构而数据库应该使用哈希表”这种默认的做法可能是正确的,但我仍然会提出一些自己的看法。
哈希表与树
首先,让我们回顾一下这些数据结构之间的根本区别。在访问单个值时,哈希表的访问时间是常数O(1),而树的访问时间是对数O(log n)。对于单值查找,这意味着无论数据存储在内存中还是磁盘中,哈希表的速度都比较快。但是,尽管树有额外开销,但树中的值都是有序的。因此,我们可以高效地访问范围值,这意味着它们可以有效地支持多种操作。例如,我们可以查找所有以某个前缀开头的值,或者“前k个”值,换作哈希表的话,则我们需要扫描整个表。关于数据库中B树的使用,我强烈建议你阅读《Modern B-Tree Techniques》(http
://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.219.7269),作者Goetz Graefe在书中奉上了一篇精妙易懂且全面的调查报告。
另一个区别是,哈希表仅提供平均的常数时间访问。有意或无意导致的哈希冲突可能会引发不良行为,但更大的问题出在重新散列上。有时,随着表的增大,本来需要O(1)的插入操作可能需要经过缓慢的O(n)扫描才能将数据插入更大的表。我们可以通过使用多级哈希表来减少这种影响,但仍然会导致某些不可预测性。相反,树最差也能保持O(log n)。
持久性数据与内存数据
通常,数据库都用于存储需要永久存在的持久性数据。而程序通常仅需要临时存储数据,只有在需要重新启动的时候才需要持久存储。这意味着最终数据库往往会存储大量的数据,无论是记录数量还是总字节数都非常大。由于以下三个原因,我认为数据库使用有序数据结构更好:
1.当n小时,数据结构不是特别重要
我觉得程序中的大多数哈希表都很小,只有数千个元素或更少。在这种规模下,O(1)、O(log n)和O(n)之间的差异无关紧要。因此,在程序中,对于常见的单值查找而言,哈希表的速度更快;而对于罕见的全表扫描而言,哈希表的速度则稍慢一些。但是,随着数据集的增大,需要O(n)才能找到相关值就会让人觉得过于缓慢。
具体来说,假设在某个应用程序中,99%的访问都仅限于单个记录,只有1%的访问涉及10个连续的记录,而且需要从某个值开始。这时,如果我们使用哈希表,则单个记录访问的开销为1,而访问某个范围的开销为n(扫描整个表),所以总开销为0.99×1 + 0.01×n。如果我们使用树,则单个记录访问的开销为log(n),而访问某个范围的开销为log(n)+9,所以总开销为0.99×log(n) + 0.01×(log(n) + 9)。如下图所示:
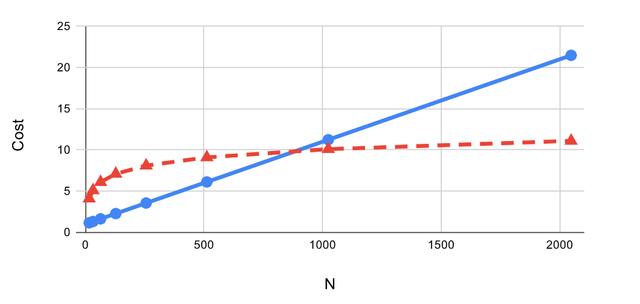
当然,这里的“开销”是我乱编的,但是我们可以从中看出趋势:如果n很小,那么哈希表是更好的选择;但是如果n较大,那么即便扫描整个表的操作非常罕见,也会给总开销带来很大影响。这就是我们常说的O(n)与O(log n)的比较,这意味着在处理大型数据集时,有序数据结构更“平衡”的性能拥有巨大优势。
2. 存储不是免费的
如果元素的数量很少,那么相对廉价的方式是存储多个数据副本,并建立不同的索引。程序和数据库都会使用该技巧。但是,添加一个索引就需要O(n)的存储空间和O(n)的构建时间。针对一个非常大的数据库,添加一个二级索引可能需要花费几个小时甚至几天。因此,数据规模越大,在不同种类的查询中重新利用索引的优势也会越大。这对于有序索引是一个优势,因为我们可以通过多种方式来使用有序属性。例如,一种常见的数据库技巧是建立包含多列的索引,例如(位置,商店名称)。然后我们可以使用这个索引访问特定的(位置,商店名称),而且还可以记录单个(位置),甚至是位置键的前缀。如果是哈希表,则每种查询都需要单独的索引。
3.持久数据结构更为复杂
将数据存储在磁盘上,就不会因为机器崩溃而导致数据损坏或丢失。你需要仔细按照顺序写入数据,在写入数据之前记录日志,而且可能还需要详细的并发控制。与内存的数据结构相比,这些操作都需要更多代码。因此,许多数据库仅支持单一类型的持久索引。如果你只选择一个索引,那么最好选择一个可以广泛用于各种负载的索引,即便它的效率稍低。
这种额外的复杂性意味着除了必要的数据结构访问外,你还有更多工作需要完成,这将对常量因素造成很大影响。例如,你需要通过网络发送请求、经过解析、从磁盘复制一些数据、经过解析,获取锁等。这些都会减少O(1)与O(log N)之间的差异。
总结和教训
我认为默认情况下,正确的选择是:在程序中使用哈希表,在数据库中使用有序数据结构。但是,可能在很多情况下,我们使用了错误的选择。我怀疑很多程序都未能有效利用有序数据结构,因为相比之下,顺序迭代的难度则小得多。例如,如果我有两个按时间排序的集合,而且我想按时间顺序输出合并后的集合,那么就可以同时迭代两个集合,并从适当的迭代中选择数据。但是,我也可以将所有事件放在一个列表中,对其进行排序,然后输出。我知道我会先想到哪个。这种复杂性的折衷让我不禁联想:有没有办法可以在使用集合时嵌入数据库查询优化……
原文:https://www
.evanjones.ca/ordered-vs-unordered-indexes.html
本文为 CSDN 翻译,转载请注明来源出处。
【End】
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号