斯坦福70亿参数「羊驼」的短板被弥补,中文大模型开源发布
发表时间: 2023-03-22 09:45
机器之心报道
机器之心编辑部
BELLE 基于 Stanford Alpaca,对中文做了优化,模型调优仅使用由 ChatGPT 生产的数据(不包含任何其他数据)。
距离 ChatGPT 的最初发布,过去差不多四个月的时间了。就在上星期 GPT-4 发布时,ChatGPT 第一时间上线了新版本。不过众所周知的一个秘密是,不管是 ChatGPT 还是 GPT-4 都不大可能开源。加上巨大的算力投入以及海量的训练数据等,都为研究界复制其实现过程设下重重关卡。
面对 ChatGPT 等大模型的来势汹汹,开源平替是一个不错的选择。本月初,Meta「开源」了一个新的大模型系列 ——LLaMA(Large Language Model Meta AI),参数量从 70 亿到 650 亿不等。130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过参数量达 1750 亿的 GPT-3,而且可以在单块 V100 GPU 上运行。
时隔几天,斯坦福基于 LLaMA 7B 微调出一个具有 70 亿参数的新模型 Alpaca,他们使用了 Self-Instruct 论文中介绍的技术生成了 52K 条指令数据,同时进行了一些修改,在初步的人类评估中,Alpaca 7B 模型在 Self-Instruct 指令评估上的表现类似于 text-davinci-003(GPT-3.5)模型。
但遗憾的是,Alpaca 的种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。为了提升对话模型在中文上的效果,有没有更好的方法呢?别急,接下来介绍的这个项目就能很好的解决这个问题。
开源中文对话大模型70 亿参数的 BELLE(Bloom-Enhanced Large Language model Engine)来了。它基于斯坦福的 Alpaca 完成,但进行了中文优化,并对生成代码进行了一些修改,不仅如此,模型调优仅使用由 ChatGPT 生产的数据(不包含任何其他数据)。
在数据方面,该项目开源了基于 Alpaca 的数据收集代码,基于这段代码生成了约 100 万条中文数据,结合 Alpaca 的 5 万条英文数据,在 BLOOMZ-7B 模型训练得到的 checkpoint 上传在 Hugging Face。
Hugging Face 地址:
https://huggingface.co/BelleGroup
项目作者表示:该项目旨在促进中文对话大模型开源社区的发展。
项目地址:
https://github.com/LianjiaTech/BELLE
项目介绍
该项目主要包含以下四部分内容:
数据发布
1. zh_seed_tasks.jsonl:包含 175 个种子任务,样例如下
{"id": "seed_task_20", "name": "horror_movie_opening", "instruction": "你需要为一部恐怖电影写一个创意的开场场景。", "instances": [{"input": "","output":" 太阳已经落山,留下了一个黑暗的小镇。微风吹拂空荡的街道,让每一个冒险走出门外的人感到一阵寒意。唯一的声音是被风吹动的树叶发出的轻微沙沙声。突然,一声令人毛骨悚然的尖叫声划破了寂静,随后是玻璃破碎的声音。一所房子亮起了灯光,可以看到一个人影朝镇中心奔跑。当> 那个人影越来越靠近时,清楚地看到那是一个年轻女子,她浑身血迹斑斑。"}],"is_classification": false}
2. prompt_cn.txt: 生成所使用的提示语
3. 0.5M 生成的数据
数据生成
沿用 Alpaca 的方式:
pip install -r requirements.txtexport OPENAI_API_KEY=YOUR_API_KEYpython generate_instruction.py generate_instruction_following_data默认使用 Completion API,模型 text-davinci-003。如果想使用 Chat API 并使用 gpt-3.5-turbo 模型,可通过参数控制:
python generate_instruction.py generate_instruction_following_data \ --api=chat --model_name=gpt-3.5-turbo模型调优
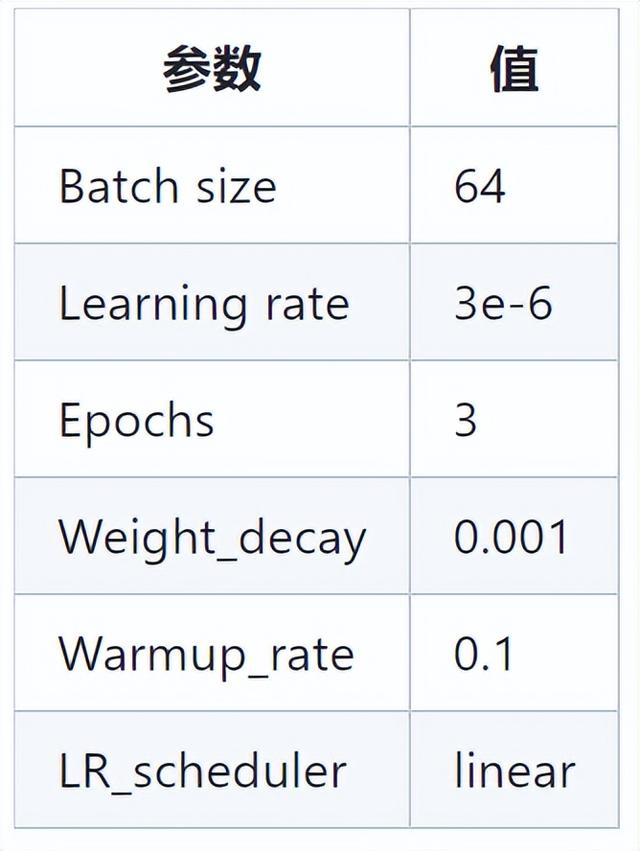
此外,该项目还采取了不同大小规模(20 万、60 万、100 万和 200 万样本)的指令学习的数据集训练模型,得到不同的模型版本如下所示:

模型使用例子

局限性和使用限制
基于当前数据和基础模型训练得到的 SFT 模型,在效果上仍存在以下问题:
基于以上模型局限性,该项目要求开发者仅将开源的代码、数据、模型及后续用此项目生成的衍生物用于研究目的,不得用于商业,以及其他会对社会带来危害的用途。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号