117种备案的生成式AI服务:大模型底层创新是否达标?
发表时间: 2024-04-03 14:12
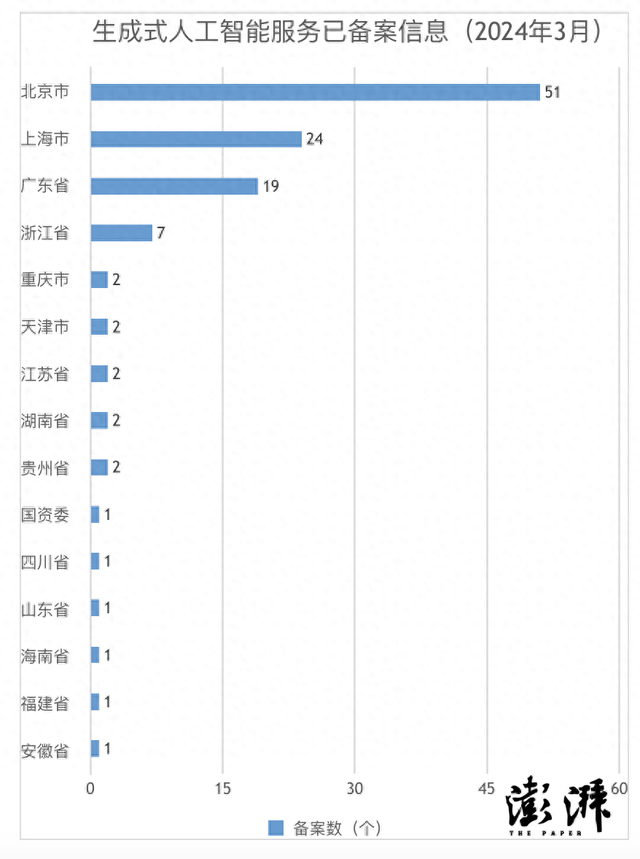
·目前已有117款生成式人工智能服务通过备案。属地以北京、上海、广东为主。其中北京51款,上海24款,广东19款。浙江和江苏分别有7款和2款。
·清华大学苏世民书院院长薛澜表示,在AI大模型方面,单从量上讲中国进步很大,但实际上还存在不少问题,因为有不少是用套壳和拼装的方式构建的。中国数据质量较低也是一个问题。
4月2日,国家互联网信息办公室发布《关于发布生成式人工智能服务已备案信息的公告》(以下简称“《公告》”)。根据《公告》,目前已有117款生成式人工智能服务通过备案。从属地来看,生成式人工智能服务集中在北京、上海、广东,其中北京51款,上海24款,广东19款。
不过,清华大学苏世民书院院长薛澜日前表示,在AI大模型方面,单从量上讲中国进步很大,但实际上还存在不少问题,因为有不少是用套壳和拼装的方式构建的。中国数据质量较低也是一个问题。
深圳元始智能有限公司首席运营官(RWKV元始智能)罗璇表示,中国大部分模型基于美国的一些开源开放模型进行微调或重训练,大部分模型类似于LLaMA模型,底层原始创新少,“国内如果还在照着LLaMA的方向做,永远没办法商业落地、突破天花板。”他认为一定要找到新的架构。
117款生成式人工智能服务已备案
《公告》提出,提供具有舆论属性或社会动员能力的生成式人工智能服务的,可通过属地网信部门履行备案程序,属地网信部门应及时将已备案信息对外公开发布。已上线的生成式人工智能应用或功能,应在显著位置或产品详情页面公示所使用已备案生成式人工智能服务情况,注明模型名称及备案号。
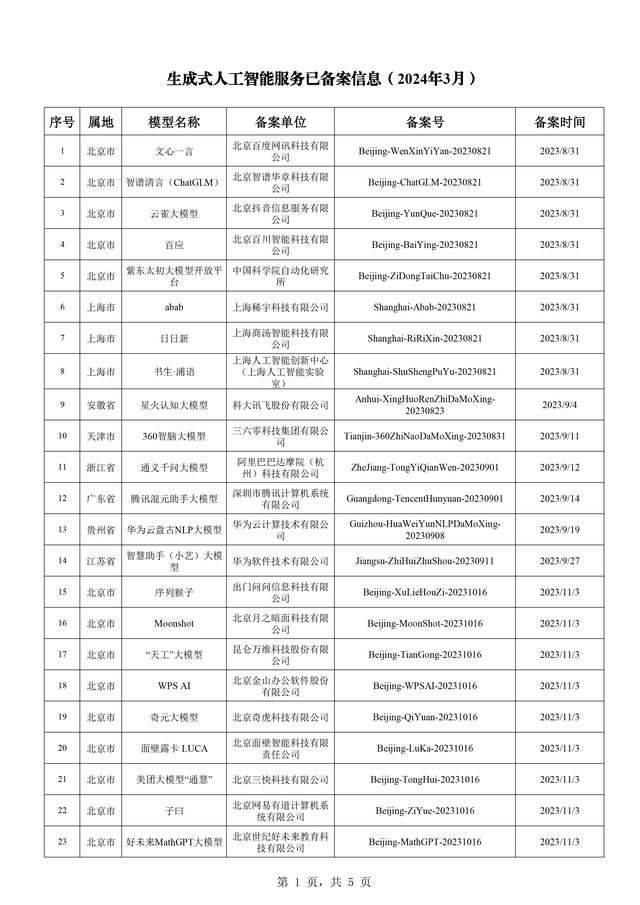
《公告》显示,去年8月,智谱“智谱清言”、百度“文心一言”、抖音“云雀大模型”、百川智能“百应”、中国科学院自动化研究所“紫东太初大模型开放平台”,以及上海稀宇科技“abab”、商汤科技“日日新”、上海人工智能实验室“书生·浦语”8项生成式人工智能服务完成首批备案。
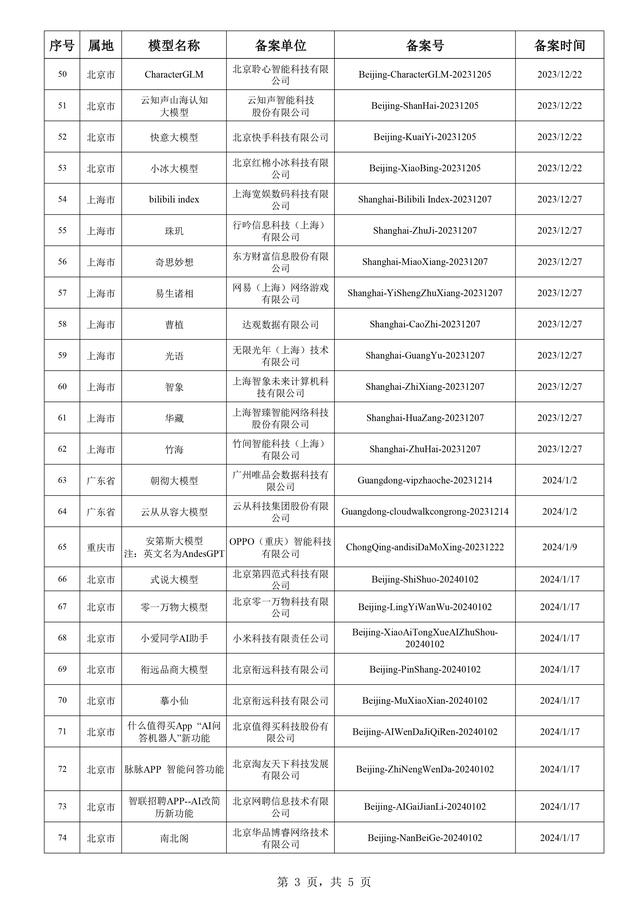
新近完成备案的有四川长虹电器的“长虹云帆”、OPPO的“AndesGPT-LVM”、深圳荣耀软件技术公司的“YOYO助理(移动版)”等。
澎湃科技(www.thepaper.cn)统计发现,通过备案的117款生成式人工智能服务中,属地以北京、上海、广东为主。其中北京51款,上海24款,广东19款。浙江和江苏分别有7款和2款。天津、贵州、湖南、重庆各有2款,安徽、海南、四川、福建、山东各有1款。此外,中国移动备案了一款“九天自然语言交互大模型”,属地为国资委。
套壳导致大模型缺乏原始创新
ChatGPT问世后,人工智能领域风起云涌,技术创新加速。中国人工智能大模型形成“百模大战”局面。
金沙江创投董事总经理朱啸虎去年11月曾表示,生成式人工智能百花齐放,但200多个大模型很快就会进入收敛期,未来可能只会剩下10-20个大模型,因为大部分大模型现在很难差异化和商业化。
清华大学苏世民书院院长薛澜2月份在中国数字经济发展和治理学术年会(2024)上表示,在AI大模型方面,单从量上讲中国进步很大,但实际上还存在不少问题,因为有不少是用套壳和拼装的方式构建的。“具体而言,目前很多国外的模型是开源的,那么在开源的基础上进行套壳就可以形成一个套壳的大模型,接着再将一些这样的大模型拼装在一起就变成更大的大模型,这种方式做出来的大模型背后的原创性是有限的。”
“过去一年多,中国的大部分模型还是基于美国的一些开源开放模型进行微调或重训练。有一些预训练能力的企业也是拿着LLaMA架构重新训练,所以整体来说国内大部分模型是类似于LLaMA的模型。”RWKV元始智能COO罗璇对澎湃科技(www.thepaper.cn)表示,中国大模型的底层原始创新少,更多是探索落地应用等垂直领域创新。
LLaMA是一个基于Transformer架构的大语言模型。“大家的底层架构都在用别人的技术,而Transformer这个架构本身就是有问题的。”罗璇表示,从第一性原理角度来看,Transformer的计算复杂度高,算力需求巨大,算法效率低。这会加重芯片“卡脖子”问题,具身智能、多智能体、世界模型的开发也会被计算复杂度“卡脖子”。“国内如果还在照着LLaMA的方向做,永远没办法商业落地、突破天花板。”他认为未来一定会出现一个新的架构替代现在的Transformer。
此外,中国数据质量较低也是一个问题。薛澜表示,“中国的数据量很大,但没有真正产业化,相对标准化的数据服务商还比较少,因为大数据服务不赚钱,公共数据企业没有意愿去清洗,定制化服务一般收费又比较高。因此,数据市场如何构建也是需要解决的问题。”
多元公平竞争,相信第一性原理
中国人工智能的发展有雄厚积累与先发优势,但薛澜认为也面临着一些挑战。首先是如何形成不同企业公平竞争的市场环境,包括民营企业、国有企业、外资企业,以及大中小企业,多元公平竞争的市场环境对人工智能发展至关重要。其次是产业生态问题,如何建立企业、资金、人才等多方面主体和多方面资源有效流通、协调一致的产业生态。第三是治理问题,怎样形成可预期、包容审慎、敏捷有效的治理框架,为形成鼓励人工智能发展的市场环境和产业生态奠定制度基础。最后是如何聚集全球顶尖人工智能人才,中国要加大开放力度。
从技术角度来看,对于人工智能未来发展趋势,上海人工智能实验室领军科学家乔宇表示有两条路径,一是延续大模型路线,用更大的算力扩大模型规模,拓宽能力边界,向产业渗透,模型也从语言大模型向多模态大模型、具身大模型的方向发展。多模态大模型是现在的竞争热点,未来的大模型要能和物理世界交流,完成更复杂的任务,所以具身大模型是重要发展方向。但单纯扩大规模存在幻觉、效率、可信、安全等瓶颈,这就涉及到第二条新技术路线的探索,要探索强化学习、知识计算、符号推理、类脑计算及其他新型路径。基于知识、符号、推理的方法,可解释性和安全性强。
“不要相信美国的权威在说什么,一定要相信第一性原理。”罗璇则表示,Transformer架构和芯片卡住了商业落地和前端研究,遭遇了尺度定律(Scaling Law)的困境,当参数到达六七百亿时,尺度定律的边际效益会下降,因此要探索新的模型架构。兼具Transformer和RNN(循环神经网络)优势的RWKV就是一种新架构,“我们做了4年。RWKV不但是一个计算效率非常高的大模型,解决了Transformer的计算复杂度问题,而且它已经在商业化落地了。”罗璇表示,RWKV可以解决计算效率低、计算成本高难题,可直接在手机、电脑、机器人等端侧运行。所以一定要找到新的架构,企业才能跑出PMF(产品市场匹配度)。“我不希望中国的人工智能落后,我希望中国有真正的全球化开源开放的生态。”
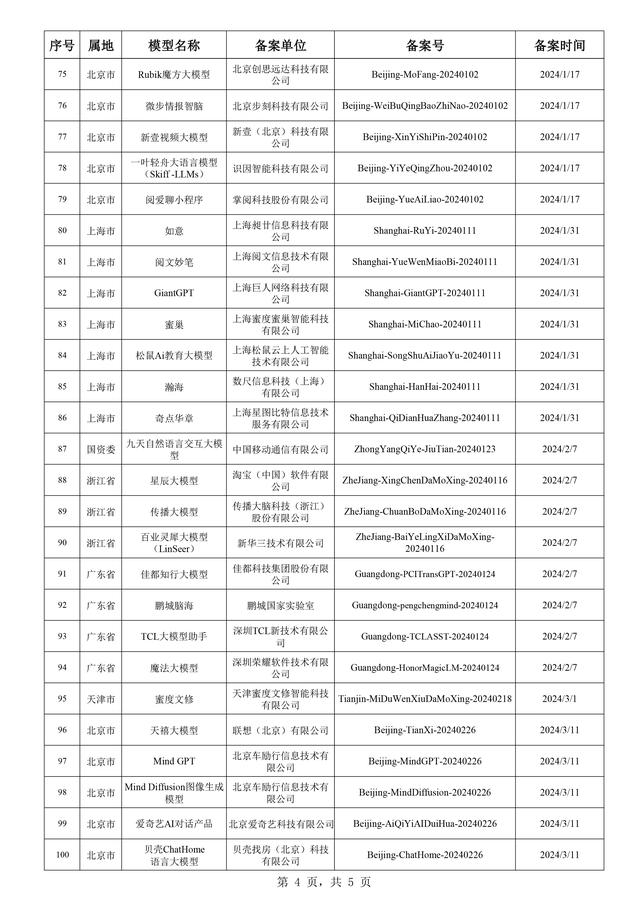
附件:生成式人工智能服务已备案信息(2024年3月)


声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号