独家揭秘:前OpenAI员工爆料公司内幕,2030年超级人工智能震撼来袭!
发表时间: 2024-06-05 16:12
文|陈斯达 王奕昕
编辑|李然
OpenAI前员工Leopold Aschenbrenner,之前在超级对齐(Superalignment)部门,可是能和Ilya大佬共事的。
但刚刚的2024年4月份,他被OpenAI以泄露公司机密为由解雇。
图源:The Information
被解雇后,他上线了一个网站,把自己在OpenAI工作中了解到的信息做了一个盘(bao)点(liao):在他看来,深度学习没有遇到瓶颈,人类在2027年,就能实现AGI。而在2030年左右,AGI很有可能会发展出全面超越人类的超级人工智能,但是人类似乎还没有做好准备。
网站包含的内容非常多,转换成PDF文件足足有165页。这可以被看作硅谷最激进的AI研究人员提出的一份未来10年AI发展的纲领性文件。
不久,世界就会苏醒过来。目前,可能全世界有几百个人能够亲身感受到正在发生什么,其中大多数人都在旧金山的各家人工智能实验室里。无论命运有什么特殊的力量,我都发现自己属于其中一员。几年前,这些人被嘲笑为疯子——但他们相信趋势,这让他们能够正确预测过去几年的人工智能进步。
这些人对未来几年的预测是否也是正确的,还有待观察。但这些我见过的最聪明的人正在全力推进AI的发展。也许他们会成为历史上一个奇怪的注脚,或者他们会像西拉德、奥本海默和泰勒一样载入史册。如果他们对未来的预测接近准确的话,那么我们将迎来一段疯狂的旅程。
接下来让我告诉你,我们看到了什么。

链接:https://situational-awareness.ai/
Aschenbrenner专门在开头,致谢了Ilya和很多的OpenAI超级对齐团队的成员。可以说,这份165页的资料,是他在OpenAI的超级对齐团队工作经历的一份深度总结和个人分析,任何对AI发展感兴趣的人,千万不能错过!

来源:作者文章
Aschenbrenner是个德国大帅哥。互联网嘛,了解脑子前也得先见见面子。

来源:个人网站
他最近成立了一家专注于 AGI 的投资公司,主要投资人包括 Patrick Collison(移动支付巨头Stripe联创兼CEO)、John Collison(同为Stripe联创)、Nat Friedman(前Github的CEO) 和 Daniel Gross(Y Combinator前AI主管)。
进入OpenAI之前,他还在牛津大学全球优先研究所(Global Priorities)做经济增长方面的研究工作,此前也并没有太多和技术直接相关的经历。
来源:领英
本科就读于哥伦比亚大学的他,19岁早早毕业,作为优秀毕业生在毕业典礼上演讲。

来源:领英
或许正是这些履历给的底气,让他用略带怜悯的口气预言——AI即将带来的,绝不仅是多数专家认为的“另一场互联网规模的技术变革”。
在文章中,Aschenbrenner(以下简称为“作者”)采用了一个比较粗略但是很有效的方式来估算AI发展的速率——OOM(OOM = order of magnitude,数量级,一个OOM等于10倍,2个数量级相当于100倍的差距,可以理解为10的N次方)。
作者:我的新系列文章。我探讨了计算规模快速扩大、算法进步的一贯趋势,以及模型如何可以被“解锁”(从chatbot转变为agent),以便发展到2027年成为“随插即用的远程工作者”。
自从GPT-4发布以来,公开场合的一切都很平静,下一代模型一直在酝酿之中——这导致很多人觉得AI发展曲线已经趋于平缓了,深度学习正在碰壁。但作者通过计算OOM,认为我们应该期待更多的进展!
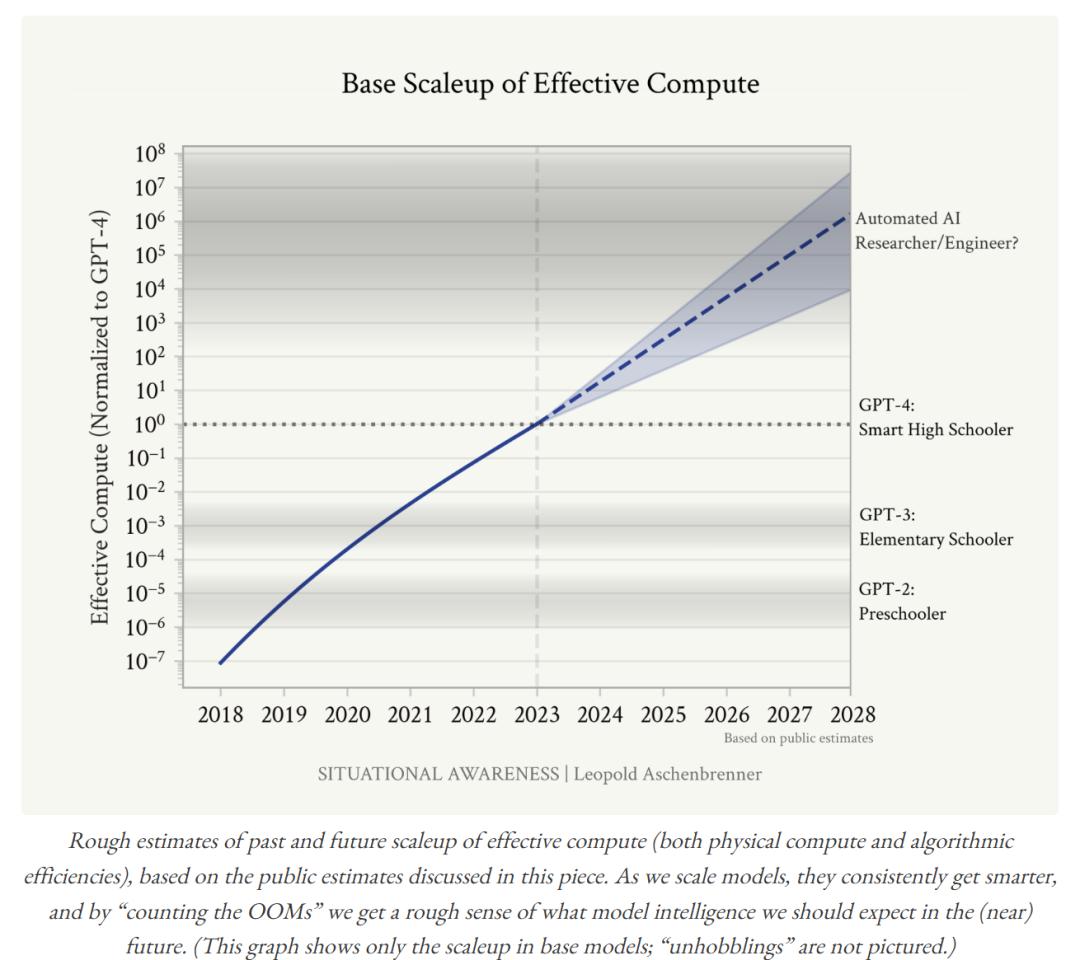
来源:文章
正所谓“知古鉴今”,了解过去的发展速度,才能推断未来的态势。
作者借用“升学”来比喻四年来GPT-2发展到GPT-4的过程,大概相当于“学龄前儿童(preschooler)”进化为“聪明的高中生(smart high-schooler)”。
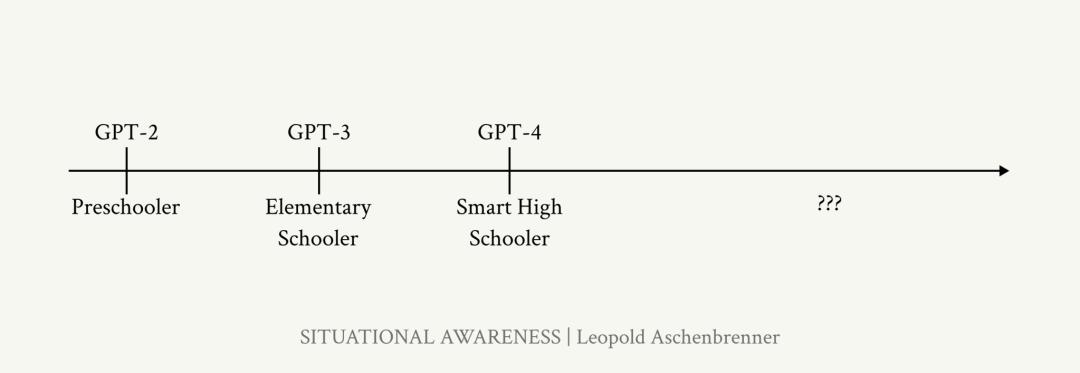
来源:文章
而深度学习在过去十年的发展也是迅速的。十年前,可以识别简单图像的深度学习系统就已经是革命性技术。今天,尽管测试人员不断用更难的基准测试刁难,这些经过训练的系统总能将之快速攻破。
作者直言,我们的基准测试快不够用了(running out of benchmarks)。因为最难的基准测试也岌岌可危。
比如GPQA(一组博士水平的生物、化学和物理问题)的测试测试集,非物化生领域的博士哪怕用谷歌激情搜索半个多小时,都和直接瞎蒙的正确率没啥区别。但就是在这样“地狱级”难度的考试上,Claude 3 Opus 已能达到及格水平,正确率约为60%,相关领域博士也只达到约80%。所以作者预测,基准测试也快完了。
而对人工智能未来的发展趋势,学霸有一套自己的预测方法——看OOM的趋势线。
他在文章中总结道,过去四年人工智能的进展,主要得益于:
基于Epoch AI的公开估计,GPT-4 训练使用的原始计算力(raw compute),比 GPT-2 多大约 3,000 倍到 10,000 倍,增加了3.5-4个OOM。

来源:文章
计算规模扩张还会持续。“保守”估计,到 2027 年底,很可能会再增加 2 个 OOM(约数十亿美元的GPU集群)。再大胆一些,考虑到微软和OpenAI近来的超算合作,即使是接近3个多 OOM(相当于1000多亿美元)的算力集群,也是有可能实现的。
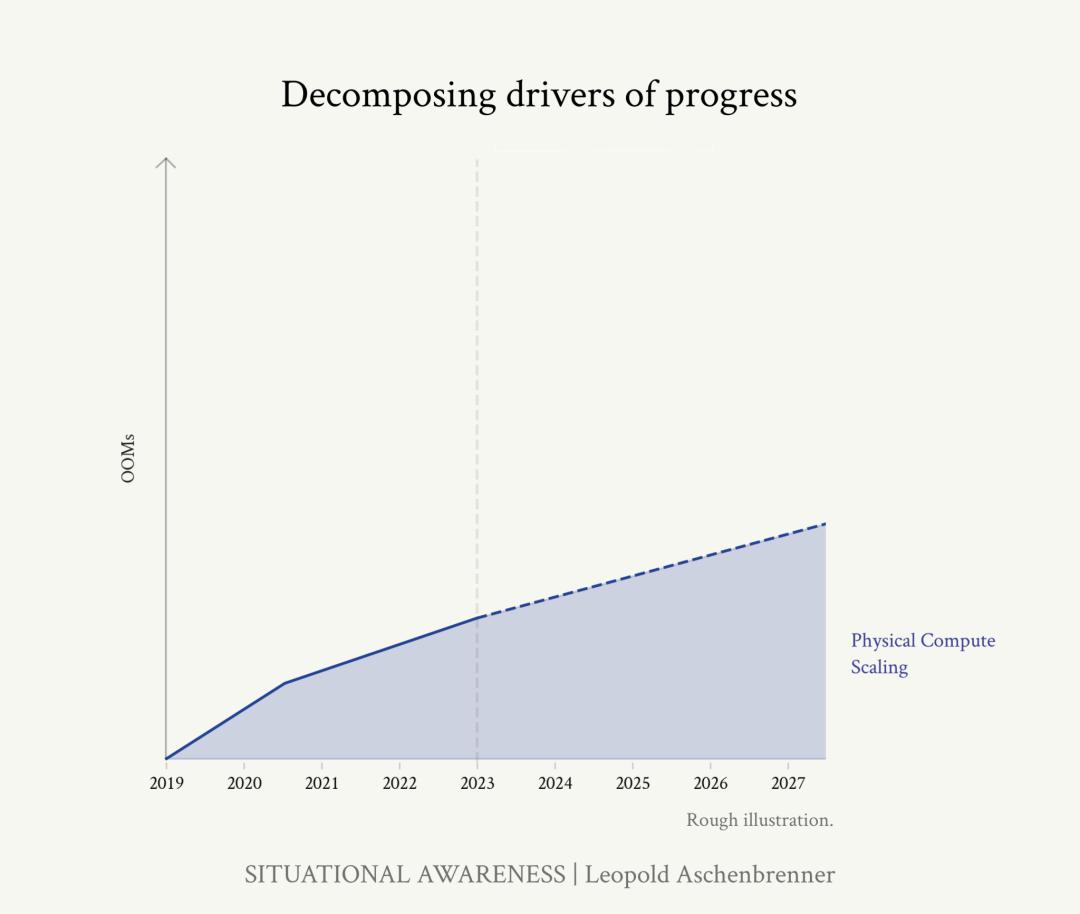
来源:文章
从2022年到现在的2024年,同样是在MATH(高中竞赛数学的基准测试)上达到大概一半(约50%)准确率的水平,模型的推理效率提高了近1,000 倍(3个OOM)。
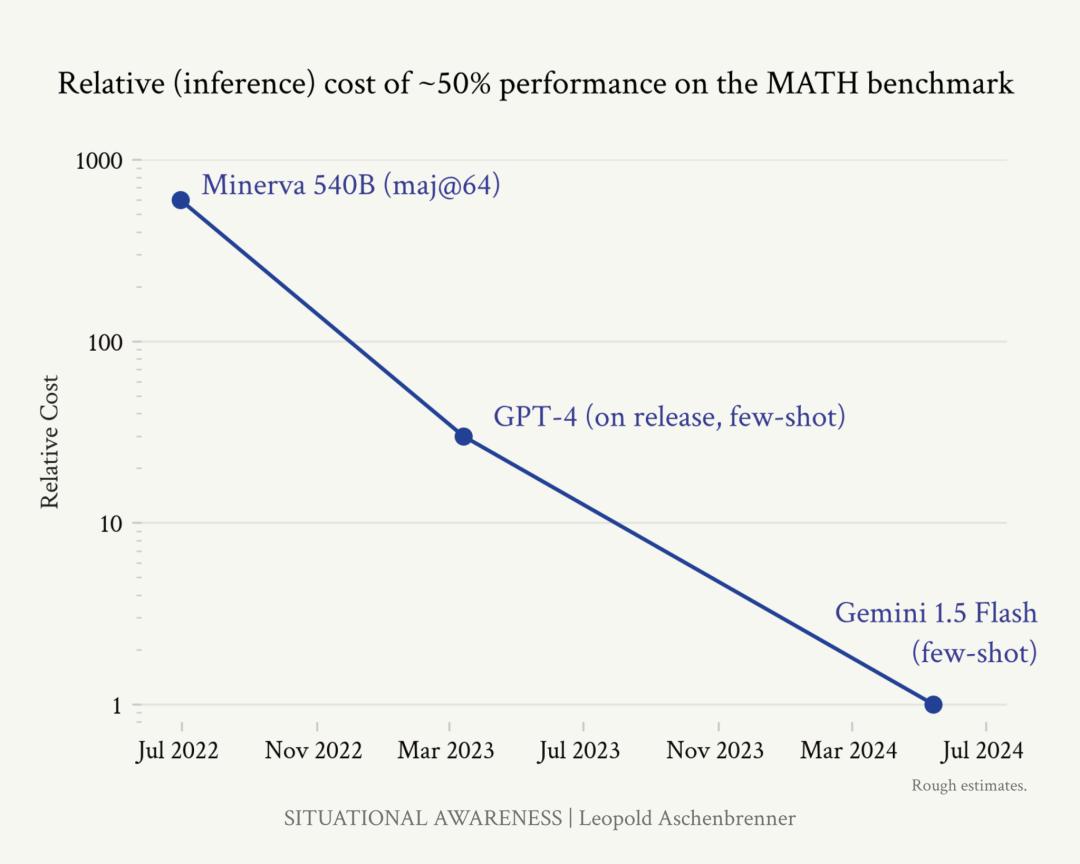
来源:文章
而据ImageNet的最佳测试数据(其相关算法研究大多是公开的,数据可追溯到十年前),从 2012 年到 2021 年的 9 年期间,算法效率的提升速度,一直都在 0.5 OOM/年的水平。
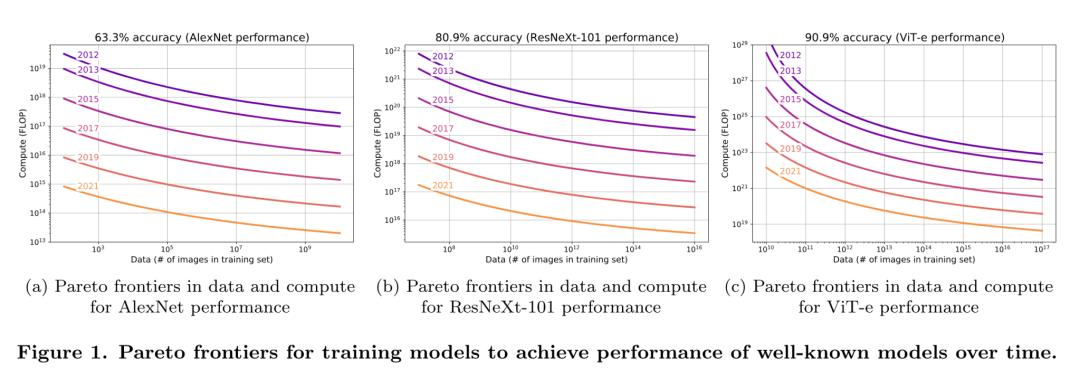
来源:文章
这意味着,四年后实现如今的性能,将达到大概一百倍的计算节约!
作者还观察了API的收费价格,间接推断出算法效率的增速。
总的来说,GPT-2 到 GPT-4 的进步,呈现出 1-2 个 OOM 的算法效率提升。算法这部分被拆解出来的进步态势,也被加到算力基础上了。
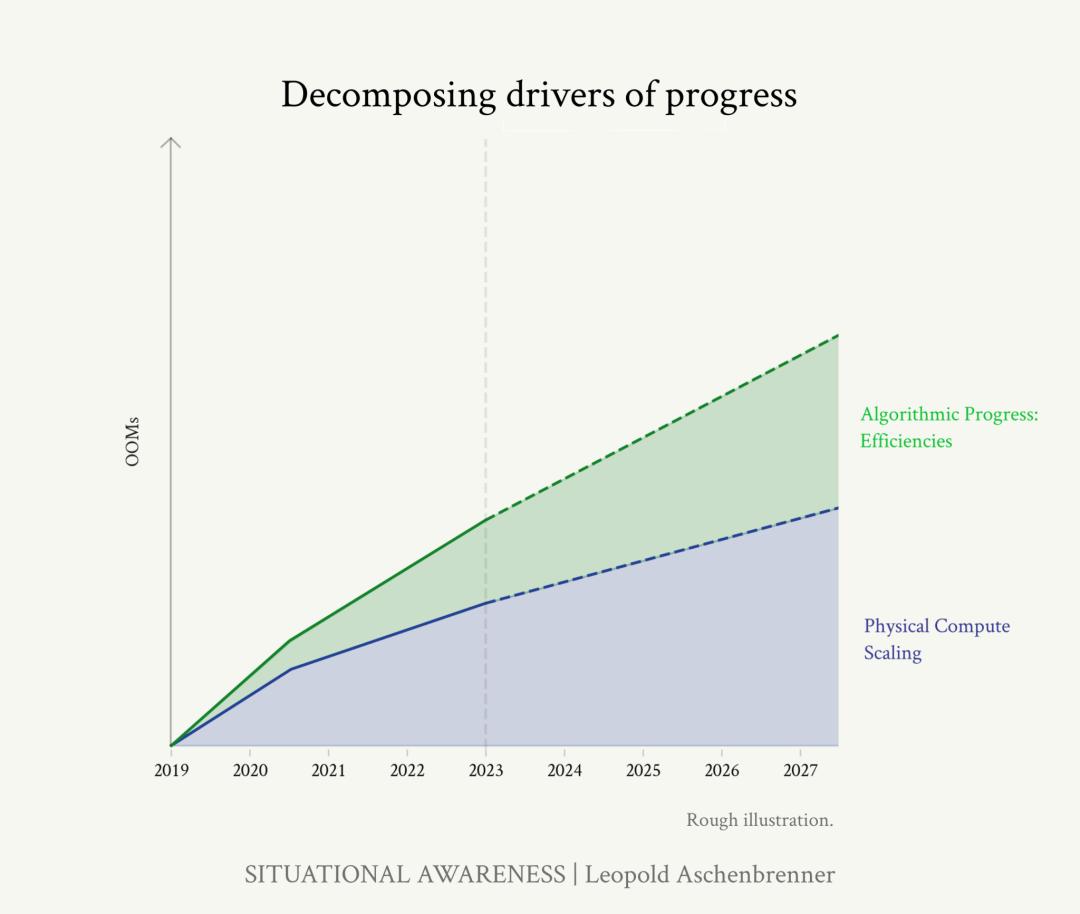
来源:文章
尽管算法效率提升可能会有更多困难,但他相信,人工智能实验室在资金和人才上的高速投资,能够帮助找到算法改进的增长点(至少据公开信息推断,推理的性价比提升根本没有放缓)。在更高维度,甚至可以看到更根本性质的、类似Transformer式的突破,甚至有更大的收益。
总之,可以预测,到 2027 年底,可以实现(与 GPT-4 相比) 1-3 个 OOM 的算法效率提升,稳妥一些——大概是 2 个左右的 OOM 增长。
剩下最难量化但同样重要的进步部分,被作者称为“Unhobbling”。比起前两项,这部分更像是“意外之喜”,是算法微调引发的模型能力增长。
做数学难题时,人类会在草稿纸上逐步求解,但模型貌似只能给出未经思考的答案。大模型学的可不比人类少,按道理来说也是解题专家才对。究其原因,其实是因为模型受到了某些阻碍,必须经过微调才能解锁这部分潜力。
这些微调就包括——基于人类反馈的强化学习 (RLHF)、思考链 (CoT)、脚手架(Scaffolding)、各类工具(Tools,比如联网查答案)、上下文长度(context length,允许学习更多的上下文可以提高计算效率)、后训练改进(Posttraining improvements)。
METR(一个评估模型的组织)发现,通过从 GPT-4 基础模型中解锁(unhobbling)出来,一组代理任务的性得到很大的改进:仅使用基本模型只达到 5%,发布时经过后训练的 GPT-4 达到 20%,再到今天的近 40%。这归功于更好的后训练、工具和代理脚手架。
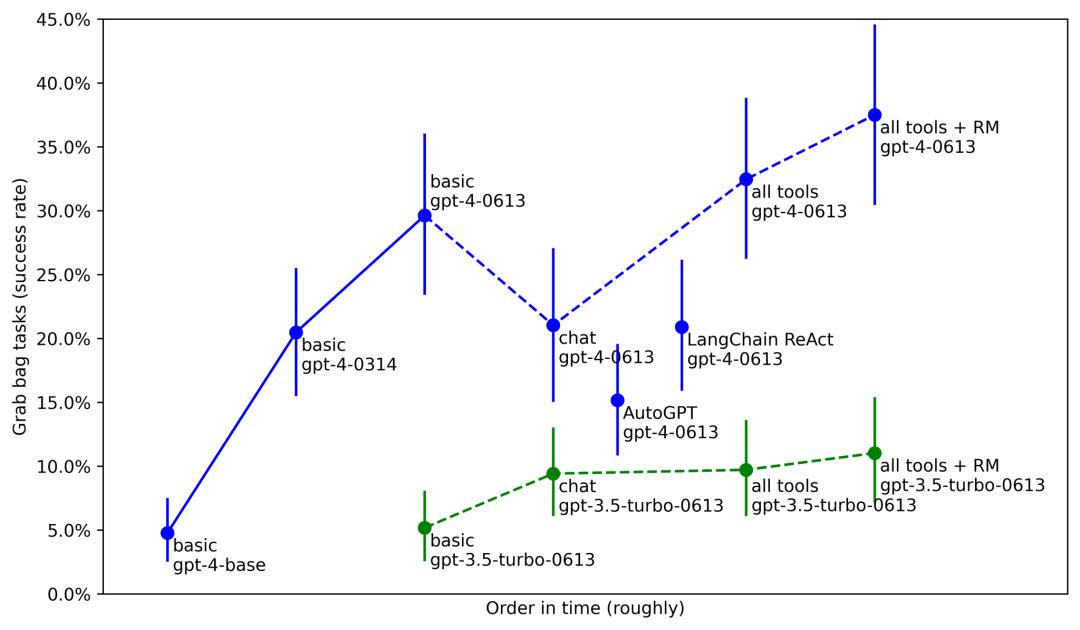
来源:文章
或许很难和算力、算法的改进同样量化比较,但这部分收益不比前两者差。把这部分的进步可视化,再堆积到前面两部分的趋势线上面,这四年的进步就更加直观了。
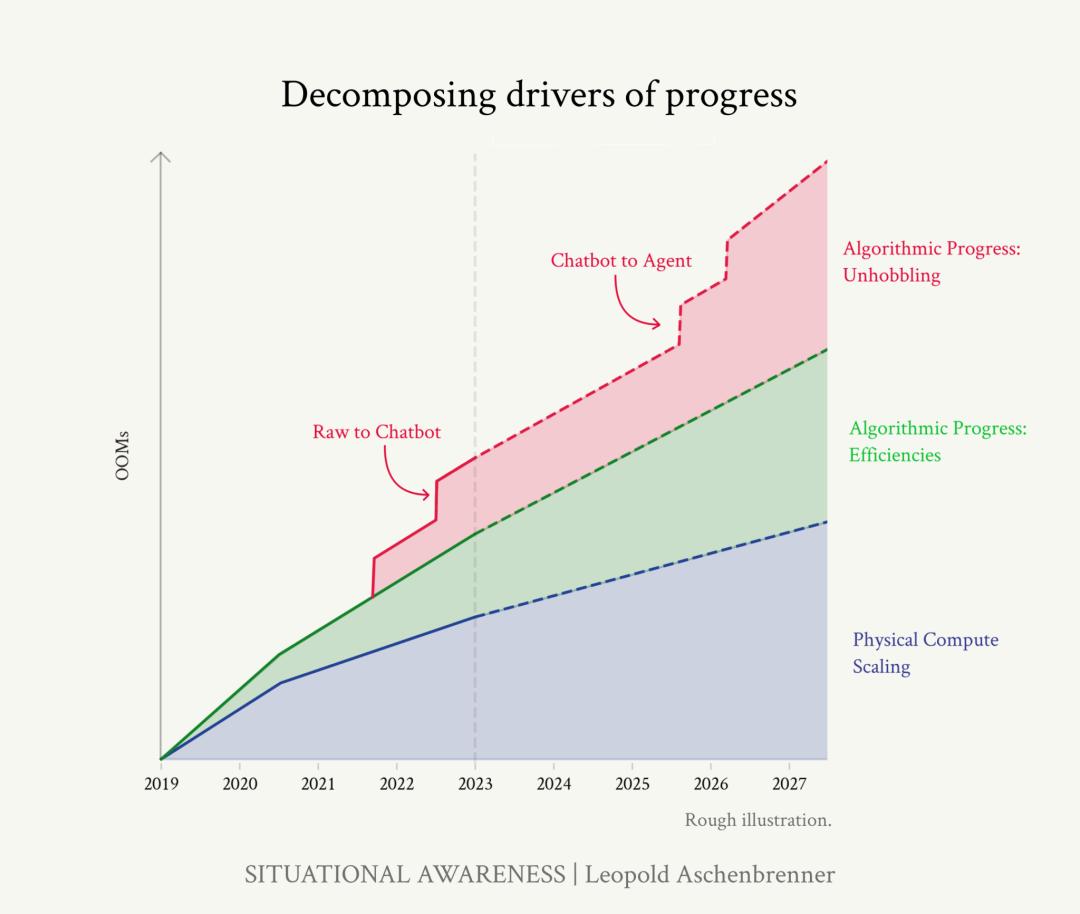
来源:文章
现在的模型没有长期记忆,不能“使用电脑”,说话前不会真正酝酿思考;对话极其简短,给一周时间也不会思考;更重要的是,还不会针对用户进行个性化反馈。如果Unhobbling部分的进展顺利,可以解决以上痛点——到 2027 年,人人将拥有将更接近于个人代理或同事的工具,而不只是聊天机器人(chatbot)。
从GPT-2到GPT-4的进步来看,算力实现了3.5到4个OOM,算法进步实现了1-2个OOM,Unhobbling实现了大概2个OOM(作者也不确定,反正就是很大)。

来源:文章
步子也不用迈得太大,毕竟各部分的数字本身就是一个区间,更不用说Unhobbling部分还不好预测。于是作者说,到 2027 年年底之前,算力、算法效率将带来3-6个OOM。所以Unhobbling部分的进步他没用OOM衡量,就被描述为——聊天机器人(chatbot)将进化为Agent。

来源:文章
总之,就OOM的总和来看,近似于GPT-2 到 GPT-4 程度的跃迁,将再次出现。即,在2027年前,AGI将成功实现。
既然前文提到,人工智能在4年内从 GPT-4 跃升到 AGI,那么再过4到8年,又会出现什么呢?
作者相信,人工智能的进步不会止步于人类水平。数以亿计的AGI,可以将AI研究转向自动化,将十年的算法进步(5个多OOM)压缩进1年以内完成。
一旦我们有了 AGI,我们就不会只有一个 AGI。基于未来 GPU 数量,人类或许能够运行数百万个AGI。在领先的人工智能实验室里,会有超过现在100,000倍那么多的研究人员和工程师日以继夜地工作,致力于实现算法突破(递归性自我改良)。一切只需要沿着现有趋势线的速度继续前进(目前为大约 0.5 OOM/年)。
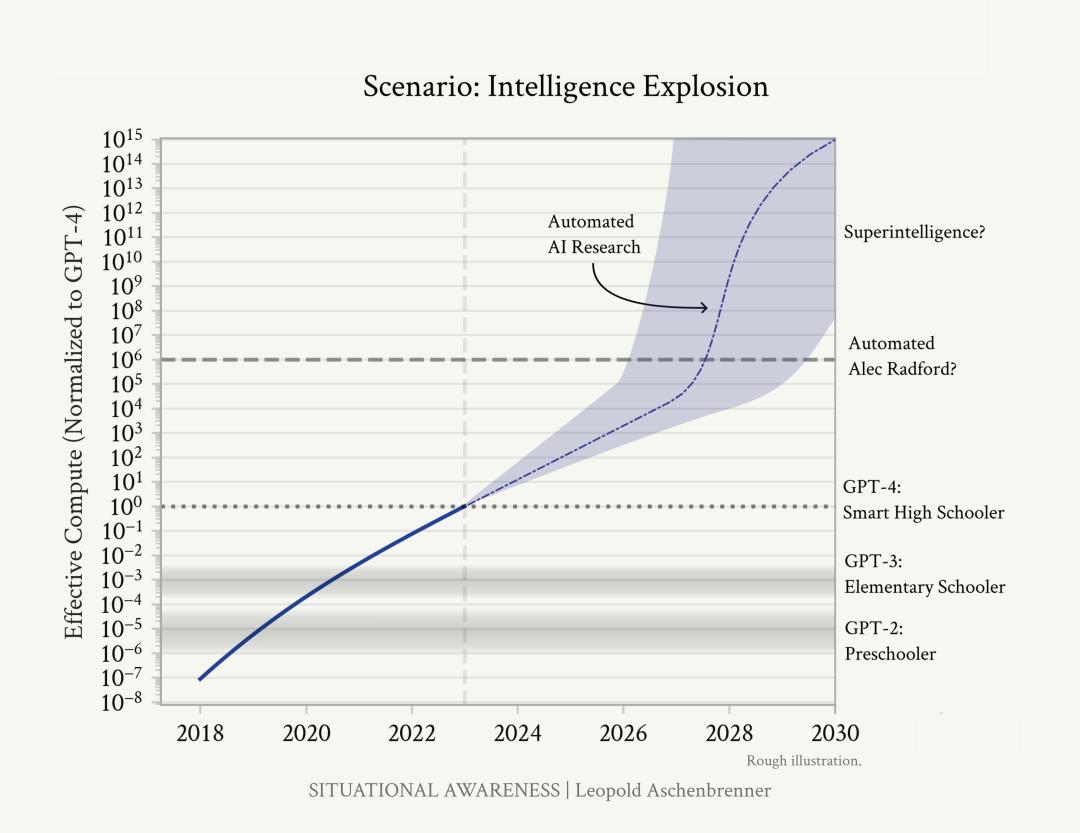
来源:文章
人工智能系统将迅速从人类水平,进化为超人类水平。
不过这么放卫星也不实在——一些真实存在的瓶颈,可能会延缓AI研究的自动化趋势。
到本十年末,我们很可能会拥有难以想象的强大人工智能系统。
这适用于科学、技术和经济的所有领域。误差可能很大,但需要注意到这将产生多大的影响。
来源:文章
爆炸性进展最初可能只存在于将AI研究转向自动化。但随着我们获得超级智能,并将我们数十亿(超级智能的)智能体应用于诸多领域的研发,爆炸性进展将会更多。
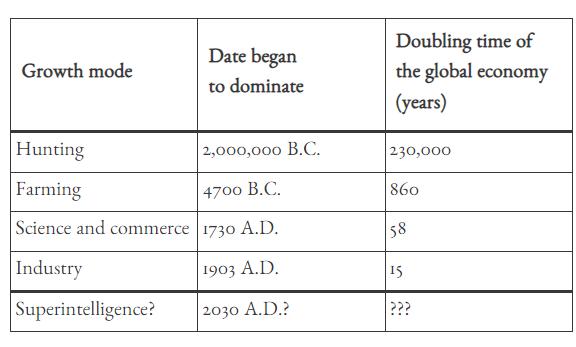
随着文明从狩猎到农业,到科学和商业的蓬勃发展,再到工业,全球经济增长的步伐加快了。
图片说明了超级人工智能出现会在不同方面引爆增长
作者警告,智能爆炸和后超级智能时期将,是人类历史上最动荡、最紧张、最危险和最疯狂的时期之一。而到本世纪末,我们都会身处其中。
作者强调,如果要实现预期的进展,需要继续进行巨额投资和基础设施建设,特别是对计算能力、电力和芯片的进一步投资。
AGI不仅仅要靠旧金山的人工智能科学家和工程师,还要动员美国的工业力量。
以下是他估算的核心数据:
计算增长趋势:
具体预测当年的前沿模型需要的算力和电力投入:
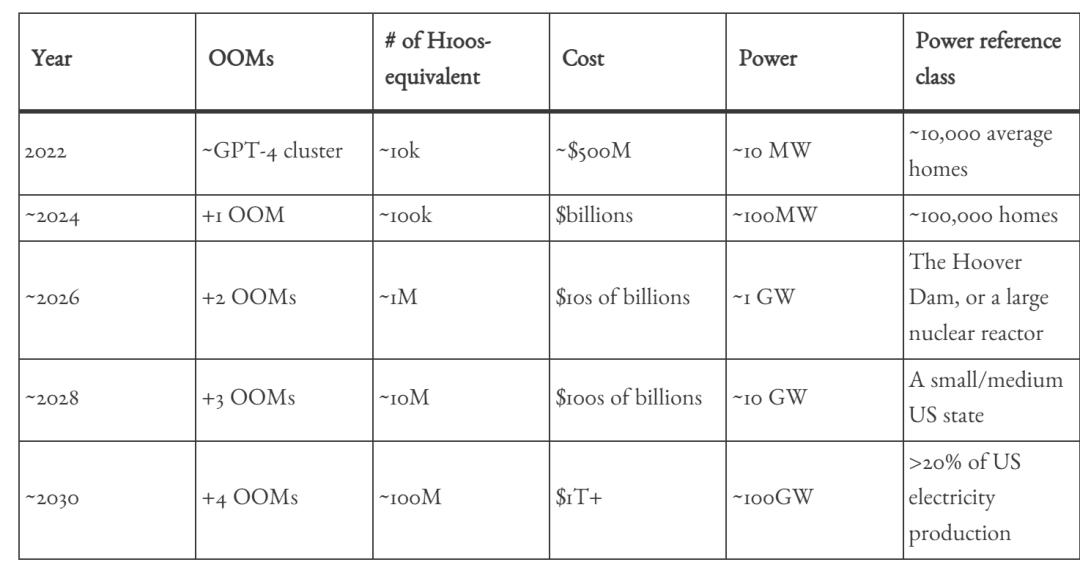
来源:文章
总体投资预测:
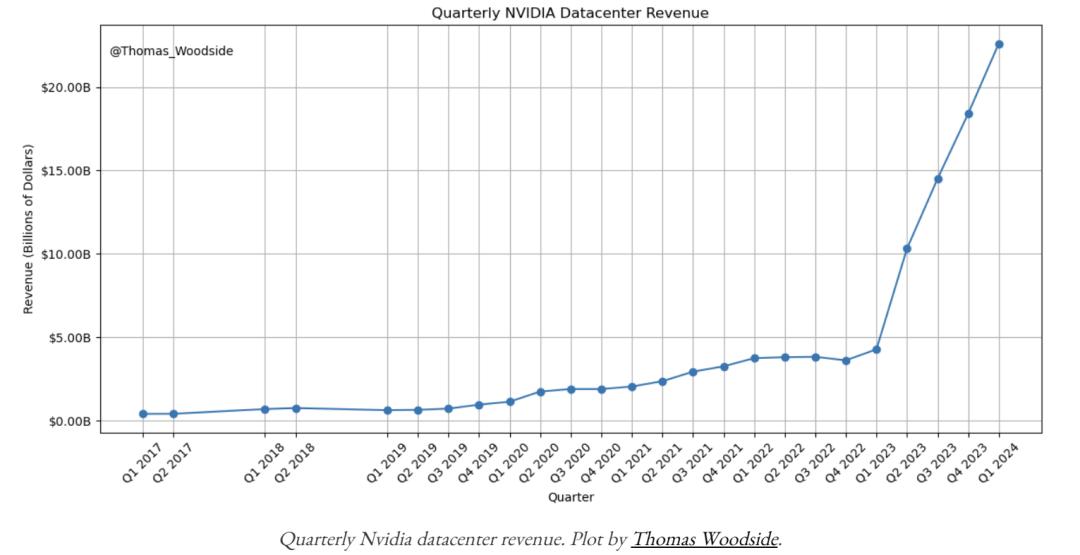
来源:文章
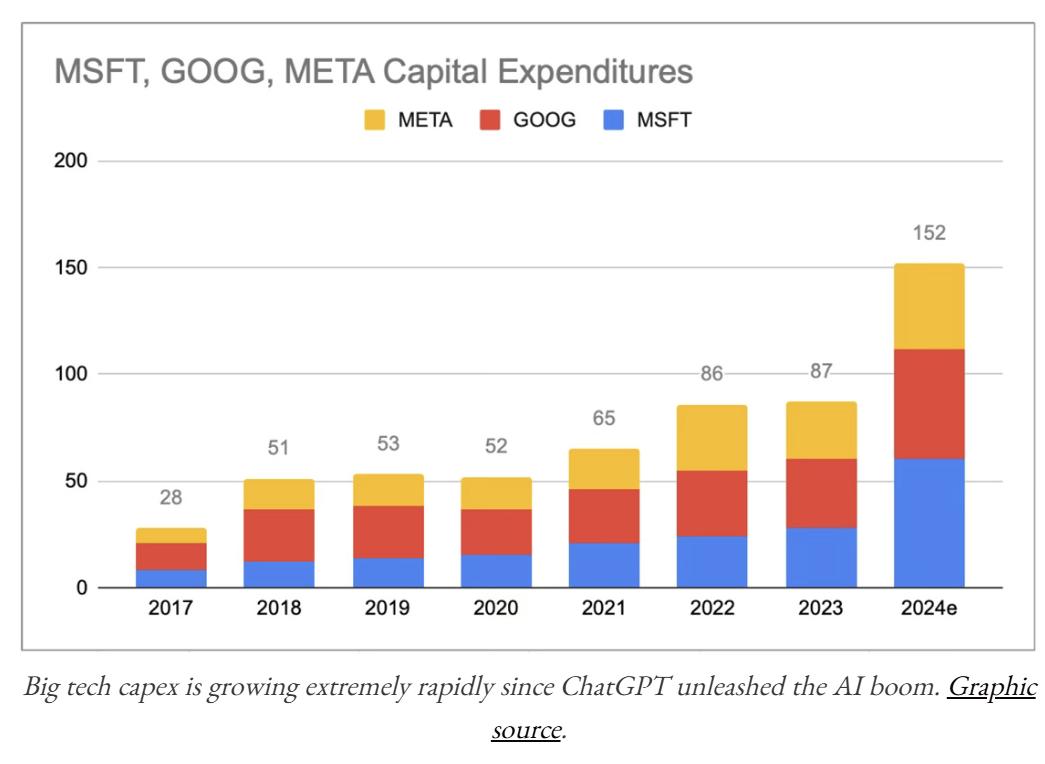
来源:文章
在作者看来,私营企业将是AI发展最重要的投资者。但随着AI技术不断发展,国家也需要投入大量资金。所以投资的资金将来自两个重要渠道:
AI收入:
历史先例:
电力需求:
解决方案:
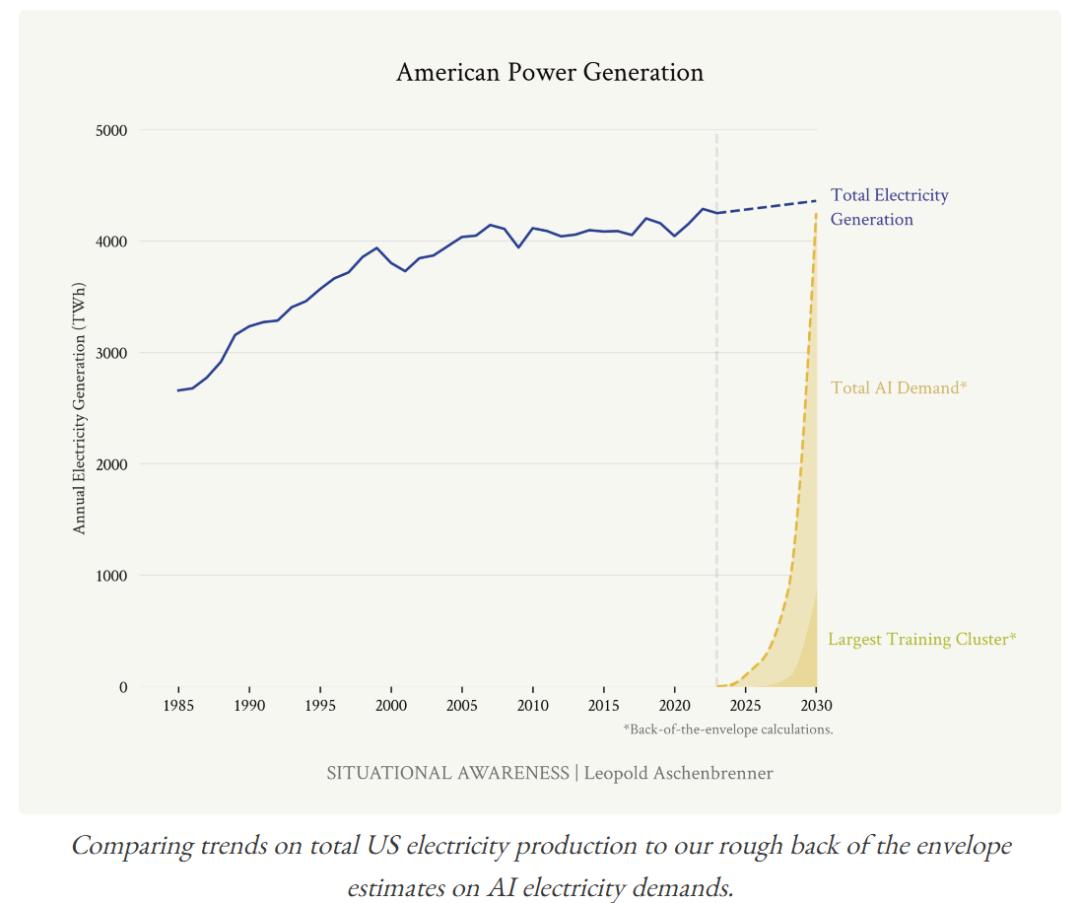
来源:文章
AI芯片生产:
供应链挑战:
作者认为,当前的AI对齐技术(如通过人类反馈的强化学习,RLHF)在处理超人类智能系统时将会失效。RLHF通过让AI尝试行为,人类随后对其行为进行评分,强化好的行为,惩罚坏的行为,由此来指导AI遵循人类的偏好。然而,随着AI变得比人类更聪明,RLHF将无法有效地监督和控制这些系统。
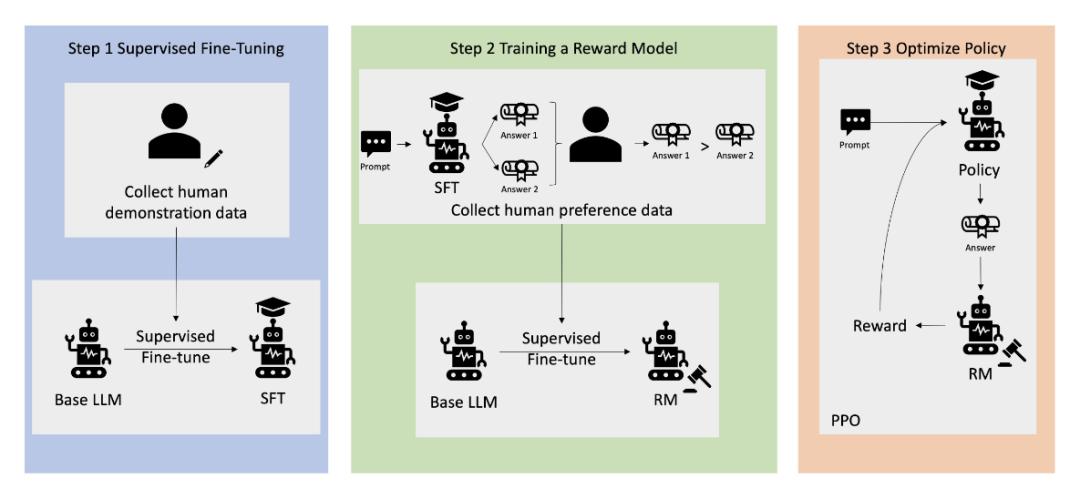
RLHF的过程概述
来源:文章
超级对齐问题在于,如何控制比我们聪明得多的AI系统。当前的RLHF技术在AI智能超过人类时将难以为继。比如,当一个超人类AI系统用一种新的编程语言编写出百万行代码时,人类评审员将无法判断这些代码是否安全,这使得我们无法继续用RLHF的方法强化模型好的行为,或惩罚它的不良行为。
如果我们不能确保这些超智能系统遵循基本的行为约束,如“不要撒谎”或“遵守法律”,它们可能会学会撒谎、寻求权力,甚至在没有人类监督时进行更加危险的行为。这些系统的失控可能导致灾难性后果,包括自我脱离服务器、入侵军事系统等。

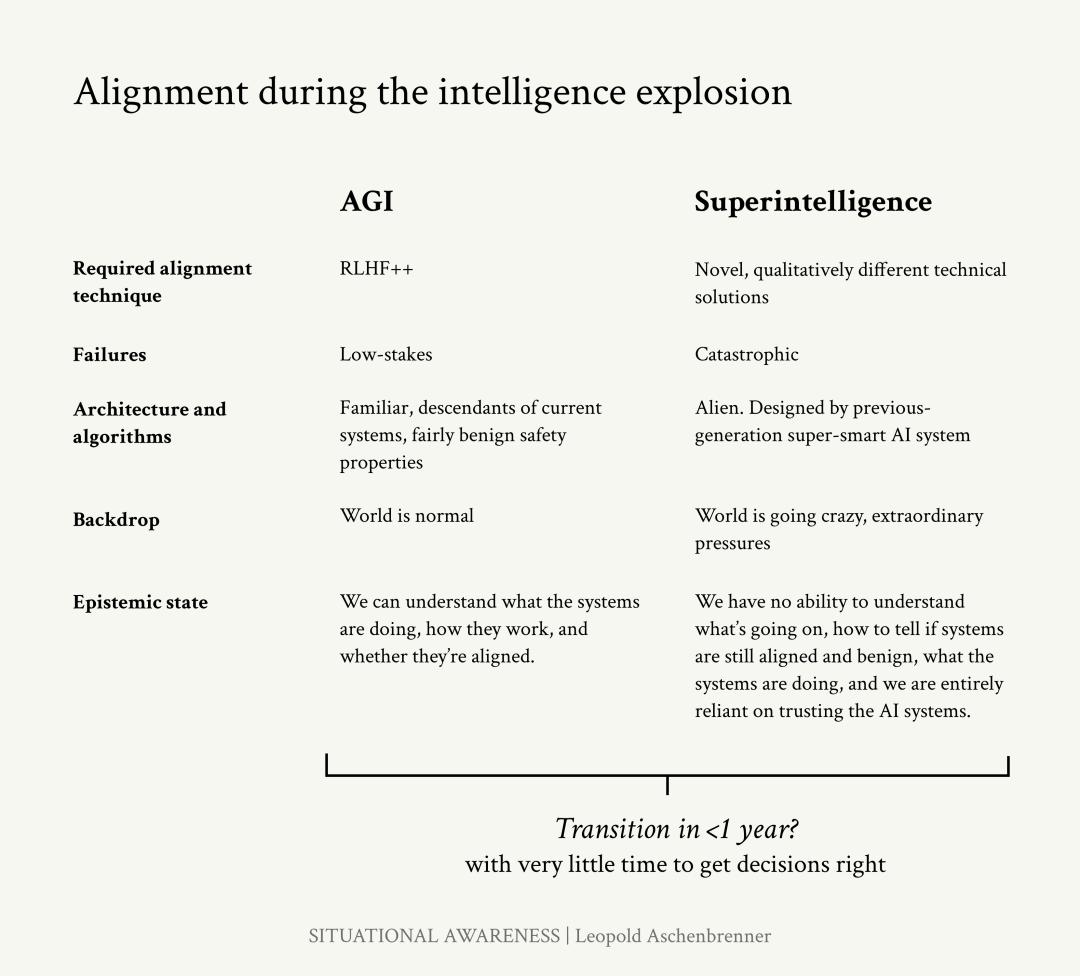
超对齐问题:RLHF 不会扩展到超人类模型(过去的模型机器人看起来是安全的,现在呢?)
作者认为,达到AGI之后,人工智能可能会在不到一年的时间内从大致达到人类水平的系统快速过渡到超人类系统。
这将极大地缩短逐步发现和解决问题的时间,同时使故障的后果更加严重,造成极高的风险。我们需要快速适应并确保我们的对齐技术能够跟上这种变化。
要解决超级对齐问题,可能没有一次性、简单的解决方案。研究人员需要通过一系列经验性策略来对齐超越人类的系统,然后利用这些系统来自动化对齐研究,进一步解决更高级别的对齐问题。
作者认为可以尝试以下研究方向来对齐相对超人的系统:
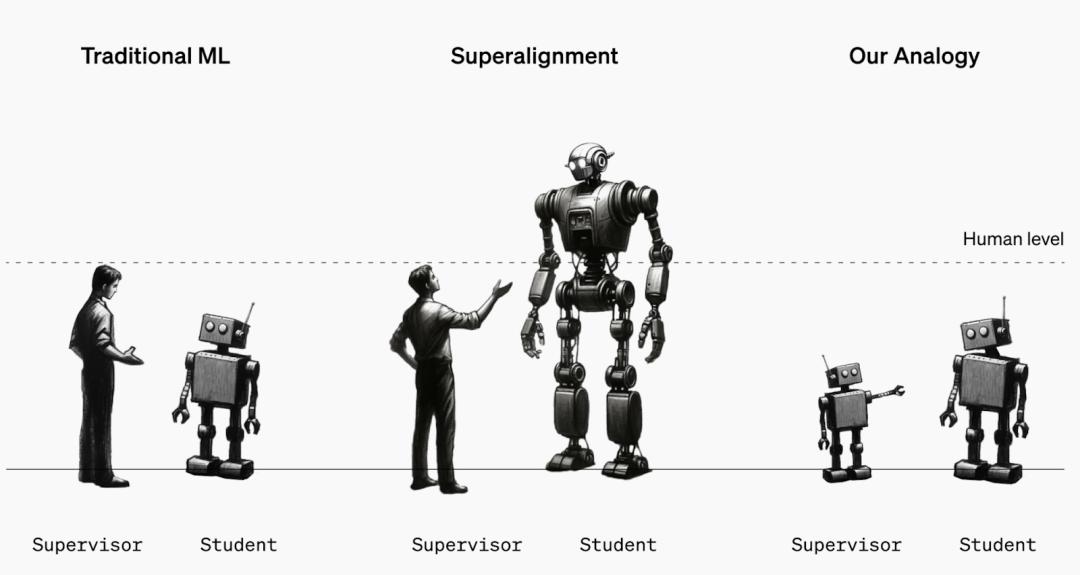
研究超级对齐的一个简单比喻:我们不是用人类来监督一个超人类模型,而是可以研究一个小模型监督一个大模型。例如,我们能否仅用 GPT-2 来对齐 GPT-4?这样做能否使 GPT-4 适当地概括“GPT-2 的意图”?图源:OpenAI文章 Weak-to-strong generalization
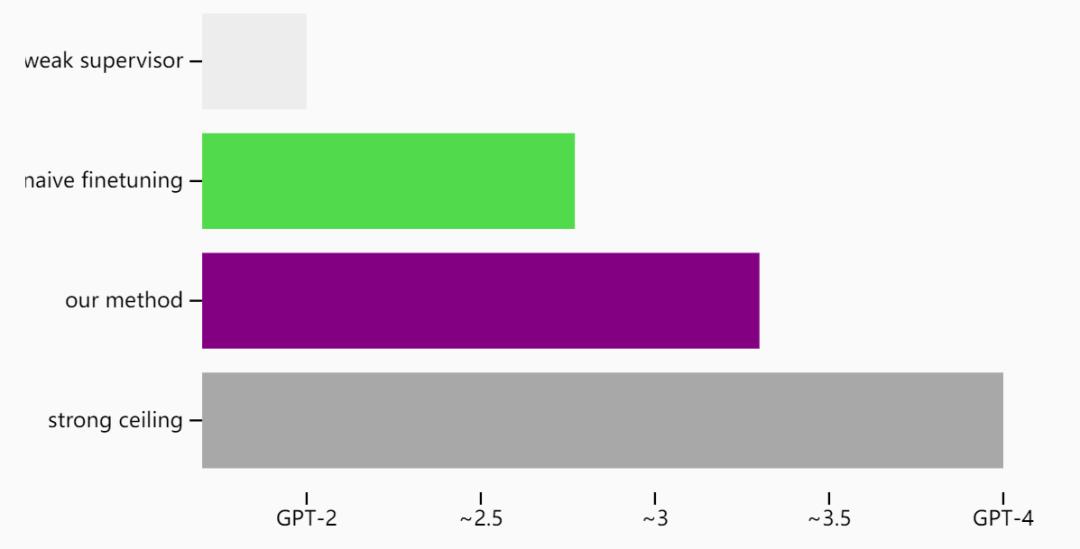
在 NLP 基准测试中典型的从弱到强的泛化:我们使用 GPT-2 级别的模型作为弱监督器来微调 GPT-4。图源:OpenAI文章 Weak-to-strong generalization
而超级对齐就像AI本身的发展一样,需要自动化对齐研究来解决真正的和超级智能对齐问题。如果我们能对齐相对超人的系统,并相信它们,我们将有数百万自动化的AI研究人员来帮助我们解决更高级的对齐问题。
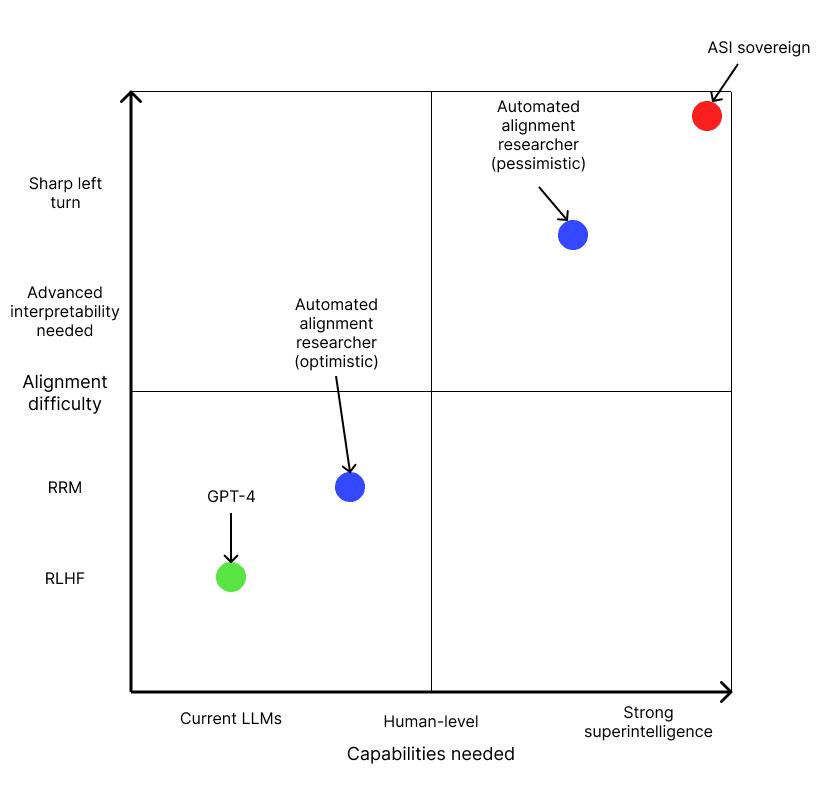
对齐难度的等级参见上图。图源:AI ALIGNMENT FORUM 文章 Could We Automate AI Alignment Research?
“超级对齐”应该只是达到AGI之后进行防御的第一层。我们还需要更多的防御层次来应对可能的失败,例如:
安全性(Security):使用绝对隔离的集群作为防御超智能系统自我脱离和造成现实世界伤害的第一层防御。
监控(Monitoring):高级监控系统可以检测AI系统是否有恶意行为。
有针对性的能力限制(Targeted Capability Limitations):尽可能限制模型的能力以减少失败带来的影响,例如,从模型训练中删除与生物和化学相关的内容。
有针对性的训练方法限制(Targeted Training Method Restrictions):避免使用风险较大的训练方法,尽可能延长具有可解释和忠实推理链的训练。
虽然看起来困难重重,但作者对超对齐问题的技术可行性持乐观态度,认为在深度学习领域有很多低垂的果实可以帮助我们解决这些问题。然而,达到AGI之后的高风险和快速变化使得这一过程变得非常紧张,需要极高的管理能力和科学决策能力。
在作者看来,专家们每年都会宣布:“深度学习的发展遇到瓶颈了!”即使是在旧金山,两种很不严肃的讨论也让人们的观点变得非常两极分化!
一端是末日论者。他们多年来一直痴迷于AGI。作者说他非常信任他们的先见之明。但他们的思想已经变得僵化,脱离了深度学习的经验现实,他们的提议幼稚而不可行,他们未能与真正的威权威胁接触。
他们狂热地宣称厄运的几率为99%,呼吁无限期暂停人工智能——这显然不是办法。

尤德科斯基回应了像埃隆·马斯克和其他科技界人士所表达的担忧,他们主张暂停人工智能研究六个月。图源:纽约邮报 Silicon Valley doomsayer warns of AI: ‘I think we’re all going to die’ 盖蒂图片社;纽约邮报合成
另一端是所谓的“加速主义者”——e/accs。

已知关于e/acc或有效加速主义的最早引用出自2022年5月31日和6月1日,Twitter用户@zetular、@BasedBeff和@creatine_cycle“与兄弟们一起创造了一种新哲学”。图源:网络
他们的观点有可取之处:人工智能的进步必须继续发展。但在他们肤浅的Twitter垃圾帖子背后,暗藏着叵测的居心——他们是只想建立自己的套壳初创公司,而不以AGI为目标的外行。他们声称自己是自由的捍卫者,但无法抗拒臭名昭著的独裁者现金的诱惑。
事实上,他们是真正的停滞论者。在他们试图否认风险的过程中,他们也否认了AGI;从本质上说,他们只能做出一个很酷的聊天机器人,这些聊天机器人肯定不会有危险。
在作者看来,这个领域最聪明的人已经聚集到区别于以上两种立场的第三种角度。他们以创新的眼光和方式认识和追求AGI,作者称之为AGI现实主义:
超级人工智能事关国家安全。
我们正在迅速制造比最聪明的人类更聪明的机器。这不是一次看起来很酷的硅谷热潮;这不是一个由编写无辜开源软件包的程序员组成的毫无门槛的社区;这不是乐趣和游戏。超级智能的发展将是疯狂的;它将是人类有史以来建造的最强大的武器。对于我们所有参与其中的人来说,这将是我们做过的最重要的事情。
我们不能搞砸了。认识到超级人工智能的力量也意味着认识到它的危险——无论是因为人类使用了我们相互毁灭带来的破坏性力量,还是因为我们正在召唤的外星物种是我们还不能完全控制的东西。
想让超级人工智能变得可控,即兴发挥是不能解决问题的。驾驭这些危险将需要优秀的人带着前所未有的严肃来到谈判桌上。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号