Redis 6.0正式支持多线程:新旧版本性能对比评测
发表时间: 2019-08-06 09:13
导读:Redis 6.0将在今年年底发布,其中引入的最重大的改变就是多线程IO。本文作者深入阅读并解析了关键代码,并且做了基准测试,揭示多线程 IO 特性对Redis性能的提升,十分值得一读。
林添毅,美图技术经理, 主要负责 NoSQL/消息队列/中间件等基础服务相关研发。在加入美图之前,曾就职于新浪微博架构平台从事基础服务的研发。
前天晚上不经意间看到 Redis 作者 Salvatore 在 RedisConf 2019 分享,其中一段展示了 Redis 6 引入的多线程 IO 特性对性能提升至少是一倍以上,内心很是激动,迫不及待地去看了一下相关的代码实现。
目前对于单线程 Redis 来说,性能瓶颈主要在于网络的 IO 消耗, 优化主要有两个方向:
提高网络 IO 性能,典型的实现像使用 DPDK 来替代内核网络栈的方式
使用多线程充分利用多核,典型的实现像 Memcached
协议栈优化的这种方式跟 Redis 关系不大,多线程特性在社区也被反复提了很久后终于在 Redis 6 加入多线程,Salvatore 在自己的博客 An update about Redis developments in 2019 也有简单的说明。但跟 Memcached 这种从 IO 处理到数据访问多线程的实现模式有些差异。Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。之所以这么设计是不想因为多线程而变得复杂,需要去控制 key、lua、事务,LPUSH/LPOP 等等的并发问题。整体的设计大体如下:

多线程 IO 的读(请求)和写(响应)在实现流程是一样的,只是执行读还是写操作的差异。同时这些 IO 线程在同一时刻全部是读或者写,不会部分读或部分写的情况,所以下面以读流程作为例子。分析过程中的代码只是为了辅助理解,所以只会覆盖核心逻辑而不是全部细节。如果想完全理解细节,建议看完之后再次看一次源码实现。
加入多线程 IO 之后,整体的读流程如下:
主线程负责接收建连请求,读事件到来(收到请求)则放到一个全局等待读处理队列
主线程处理完读事件之后,通过 RR(Round Robin) 将这些连接分配给这些 IO 线程,然后主线程忙等待(spinlock 的效果)状态
IO 线程将请求数据读取并解析完成(这里只是读数据和解析并不执行)
主线程执行所有命令并清空整个请求等待读处理队列(执行部分串行)
上面的这个过程是完全无锁的,因为在 IO 线程处理的时主线程会等待全部的 IO 线程完成,所以不会出现 data race 的场景。
注意:如果对于代码实现没有兴趣的可以直接跳过下面内容,对了解 Redis 性能提升并没有伤害。
下面的代码分析和上面流程是对应的,当主线程收到请求的时候会回调 network.c 里面的 readQueryFromClient 函数:
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) { /* Check if we want to read from the client later when exiting from * the event loop. This is the case if threaded I/O is enabled. */ if (postponeClientRead(c)) return; ...}readQueryFromClient 之前的实现是负责读取和解析请求并执行命令,加入多线程 IO 之后加入了上面的这行代码,postponeClientRead 实现如下:
int postponeClientRead(client *c) { if (io_threads_active && // 多线程 IO 是否在开启状态,在待处理请求较少时会停止 IO 多线程 server.io_threads_do_reads && // 读是否开启多线程 IO !(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ))) // 主从库复制请求不使用多线程 IO { // 连接标识为 CLIENT_PENDING_READ 来控制不会反复被加队列, // 这个标识作用在后面会再次提到 c->flags |= CLIENT_PENDING_READ; // 连接加入到等待读处理队列 listAddNodeHead(server.clients_pending_read,c); return 1; } else { return 0; }}postponeClientRead 判断如果开启多线程 IO 且不是主从复制连接的话就放到队列然后返回 1,在 readQueryFromClient 函数会直接返回不进行命令解析和执行。接着主线程在处理完读事件(注意是读事件不是读数据)之后将这些连接通过 RR 的方式分配给这些 IO 线程:
int handleClientsWithPendingReadsUsingThreads(void) { ... // 将等待处理队列的连接按照 RR 的方式分配给多个 IO 线程 listRewind(server.clients_pending_read,&li); int item_id = 0; while((ln = listNext(&li))) { client *c = listNodeValue(ln); int target_id = item_id % server.io_threads_num; listAddNodeTail(io_threads_list[target_id],c); item_id++; } ... // 一直忙等待直到所有的连接请求都被 IO 线程处理完 while(1) { unsigned long pending = 0; for (int j = 0; j < server.io_threads_num; j++) pending += io_threads_pending[j]; if (pending == 0) break; }代码里面的 io_threads_list 用来存储每个 IO 线程对应需要处理的连接,然后主线程将这些连接通过 RR 的方式分配给这些 IO 线程后进入忙等待状态(相当于主线程 blocking 住)。IO 处理线程入口是 IOThreadMain 函数:
void *IOThreadMain(void *myid) { while(1) { // 遍历线程 id 获取线程对应的待处理连接列表 listRewind(io_threads_list[id],&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); // 通过 io_threads_op 控制线程要处理的是读还是写请求 if (io_threads_op == IO_THREADS_OP_WRITE) { writeToClient(c->fd,c,0); } else if (io_threads_op == IO_THREADS_OP_READ) { readQueryFromClient(,c->fd,c,0); } else { serverPanic("io_threads_op value is unknown"); } } listEmpty(io_threads_list[id]); io_threads_pending[id] = 0; }}IO 线程处理根据全局 io_threads_op 状态来控制当前 IO 线程应该处理读还是写事件,这也是上面提到的全部 IO 线程同一时刻只会执行读或者写。另外,心细的同学可能注意到处理线程会调用 readQueryFromClient 函数,而连接就是由这个回调函数加到队列的,那不就死循环了?这个的答案在 postponeClientRead 函数,已经加到等待处理队列的连接会被设置 CLIENT_PENDING_READ 标识。postponeClientRead 函数不会把连接再次加到队列,那么 readQueryFromClient 会继续执行读取和解析请求。readQueryFromClient 函数读取请求数据并调用 processInputBuffer 函数进行解析命令,processInputBuffer 会判断当前连接是否来自 IO 线程,如果是的话就只解析不执行命令,代码就不贴了。
大家去看 IOThreadMain 实现会发现这些 io 线程是没有任何 sleep 机制,在空闲状态也会导致每个线程的 CPU 跑到 100%,但简单 sleep 则会导致读写处理不及时而导致性能更差。Redis 当前的解决方式是通过在等待处理连接比较少的时候关闭这些 IO 线程。为什么不适用条件变量来控制呢?我也没想明白,后面可以到社区提问。
Redis Server: 阿里云 Ubuntu 18.04,8 CPU 2.5 GHZ, 8G 内存,主机型号 ecs.ic5.2xlargeRedis Benchmark Client: 阿里云 Ubuntu 18.04,8 2.5 GHZ CPU, 8G 内存,主机型号 ecs.ic5.2xlarge多线程 IO 版本刚合并到 unstable 分支一段时间,所以只能使用 unstable 分支来测试多线程 IO,单线程版本是 Redis 5.0.5。多线程 IO 版本需要新增以下配置:
io-threads 4 # 开启 4 个 IO 线程io-threads-do-reads yes # 请求解析也是用 IO 线程压测命令:
redis-benchmark -h 192.168.0.49 -a foobared -t set,get -n 1000000 -r 100000000 --threads 4 -d ${datasize} -c 256
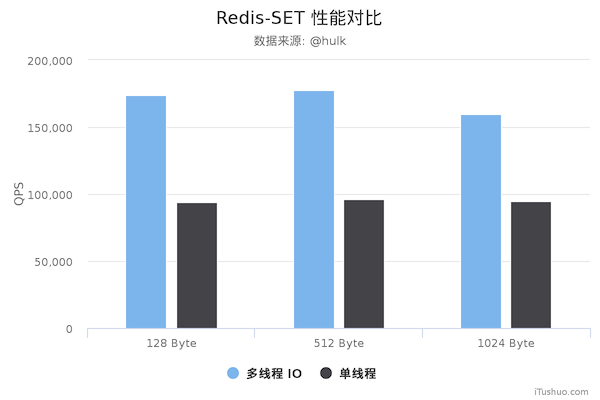
从上面可以看到 GET/SET 命令在 4 线程 IO 时性能相比单线程是几乎是翻倍了。另外,这些数据只是为了简单验证多线程 IO 是否真正带来性能优化,并没有针对严谨的延时控制和不同并发的场景进行压测。数据仅供验证参考而不能作为线上指标,且只是目前的 unstble分支的性能,不排除后续发布的正式版本的性能会更好。
注意: Redis Benchmark 除了 unstable 分支之外都是单线程,对于多线程 IO 版本来说,压测发包性能会成为瓶颈,务必自己编译 unstable 分支的 redis-benchmark 来压测,并配置 --threads 开启多线程压测。另外,如果发现编译失败也莫慌,这是因为 Redis 用了 Atomic_ 特性,更新版本的编译工具才支持,比如 GCC 5.0 以上版本。
Redis 6.0 预计会在 2019 年底发布,将在性能、协议以及权限控制都会有很大的改进。Salvatore 今年全身心投入在优化 Redis 和集群的功能,特别值得期待。另外,今年年底社区也会同时发布第一个版本 redis cluster proxy 来解决多语言 SDK 兼容的问题,期待在具备 proxy 功能之后 cluster 能在国内有更加广泛的应用。
参考阅读:
全面!一文理解微服务高可用的常用手段
一百人研发团队的难题:研发管理、绩效考核、组织文化和OKR
也许是最简洁版本,一篇文章上手Go语言
5G创新应用实践-赋能万物互联的引擎
KISS原则在订单装运模型中的应用
知乎已读服务的前生今世与未来
高可用架构
改变互联网的构建方式
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12

 鲁公网安备37020202000738号
鲁公网安备37020202000738号