ID3决策树分类算法详解:从入门到精通
发表时间: 2017-08-21 21:29
上一章为大家介绍了决策树分类算法概述,今天为大家介绍具体的ID3决策树分类算法,并附有详细的案例帮助大家理解。
基本决策树构造算法都是一个贪婪算法,采用自顶向下的递归方法构造决策树,ID3决策树分类算法的基本策略如下:
决策树以代表训练样本的的单个节点开始
如果样本都在同一个类中,则这个节点称为树叶节点并标记类别
否则算法使用信息熵(信息增益)作为启发知识来帮助选择合适的将样本分类的属性,以便将样本集划分为若干子集,该属性就是相应节点的“测试”或“判定”属性,同时所有属性应当是离散值
对测试属性的每个已知的离散值创建一个分支,并据此划分样本
算法使用类似的方法,递归地形成每个划分上的样本决策树,一个属性一旦出现在某个节点上,那么它就不能再出现在该节点之后所产生的子树节点中
整个递归过程在满足下列条件之一时停止:
给点节点的所有样本属于同一类
没有剩余属性可以用来进一步划分样本,这时候该节点作为树叶,并用剩余样本中出现最多的类型作为该叶子节点的类型
某一分支没有样本,在这种情况下以训练样本集中占绝大多数的类创建一个树叶
ID3算法的核心是,在决策树各级节点上选择属性时,用信息增益作为属性的选择标准,使得在每一个非节点进行测试时,能获得关于被测试记录最大的类别信息。
熵(entropy)的概念
在信息论中,熵是接收的每条消息中包含的信息的平均量,熵越大,每条消息中包含的信息量越大
表示随机变量不确定性的度量,系统越无序、越混乱,熵就越大。熵越大,随机变量的不确定性就越大
比如:小概率事件比大概率事件包含的信息量大。如果某件事情是“百年一见”则肯定比“习以为常”的事件包含的信息量大
在分类算法中,熵可以作为训练集的不纯度(impurity),熵越大,样本集的信息量就越大,样本集的混杂程度也越高,不纯度就越高。因此,决策树的分支原则就是使划分后的样本的子集越纯越好,即他们的熵越小越好
信息量/熵的度量
熵的计算
当随机变量只有两个值,例如1,0时,即X的分布为:P(X=1)=p , P(X=0)=1-p , 0<=p<=1
布尔分类的熵函数
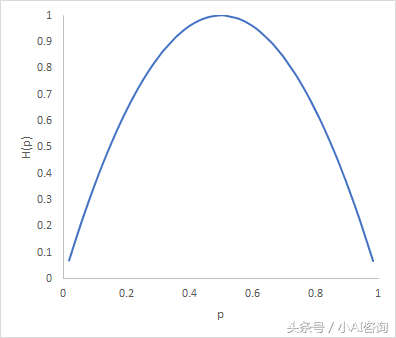
熵H(p)随概率p变化的曲线如图所示:
布尔分类的熵函数图像
由图可知,当样本属于每个类的概率相等时,即p=0.5,熵最大,即分类的不确定性最大
当p=0或p=1时,H(p)=0,随机变量完全没有不确定性,即分类结果是确定的
条件熵
条件熵的概念及计算
信息增益
信息增益表示得知特征X的信息而使得类Y的信息不确定性减少的程度
信息增益:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
信息增益
根据信息增益准则的特征选择方法是:对训练数据集(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征,也就是选出的特征是最大程度地减少训练数据集的不纯度的,使划分后的样本的子集越来越纯
参数定义
参数定义
信息增益计算
信息增益算法
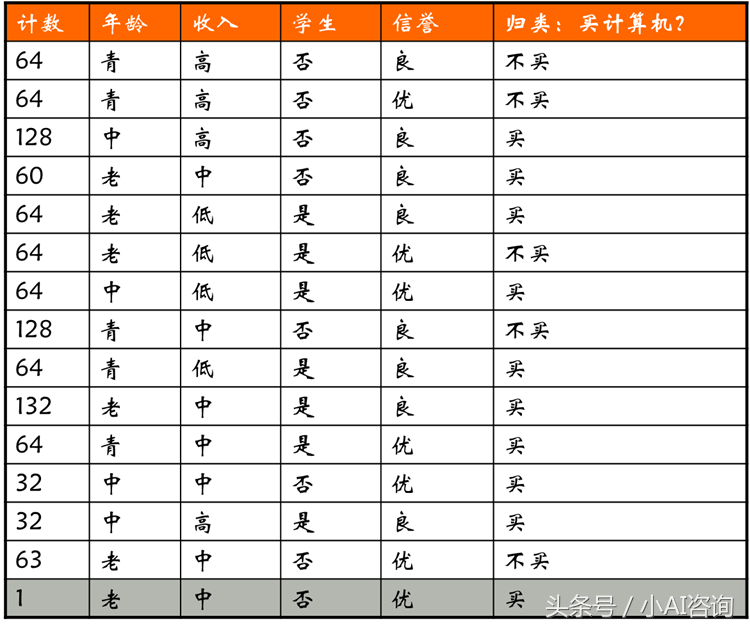
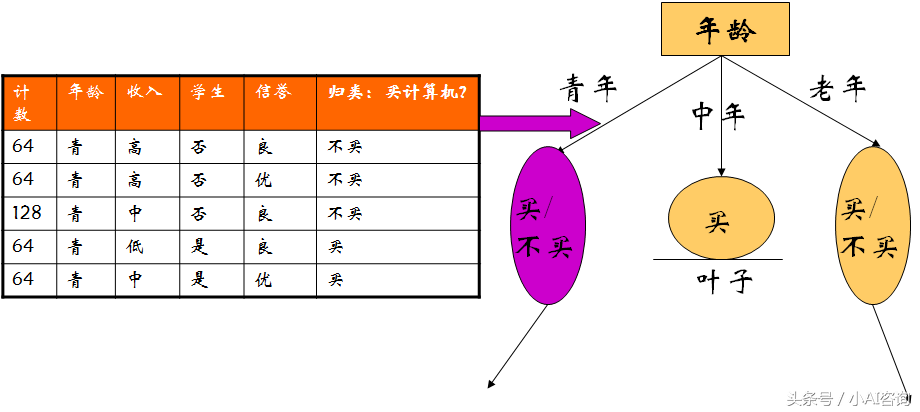
训练数据
第1步计算决策属性的熵——经验熵
决策属性的熵
第2步计算条件属性的熵——条件经验熵
2-1步计算年龄的条件熵和信息增益
年龄的条件熵和信息增益
2-2步计算收入的条件熵和信息增益
收入的条件熵和信息增益
2-3步计算学生的条件熵和信息增益
学生的条件熵和信息增益
2-4步计算信誉的条件熵和信息增益
信誉的条件熵和信息增益
选择节点 :选择信息增益最大的属性
选择信息增益最大的属性
选择年龄属性作为分类节点
继续重复以上步骤,选择下一个属性继续构造决策树。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12

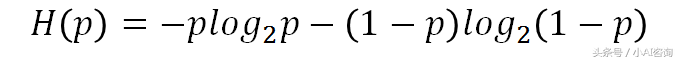

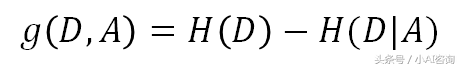







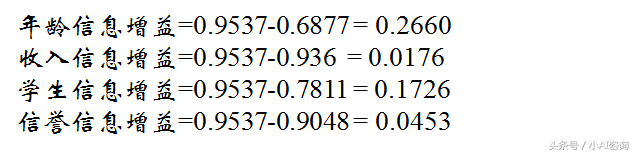
 鲁公网安备37020202000738号
鲁公网安备37020202000738号