前端开发者如何掌握机器学习?Google Brain工程师分享秘诀
发表时间: 2019-09-19 15:10


演讲者 | 俞玶
整理 | 伍杏玲
出品 | CSDN(ID:CSDNnews)
【CSDN 编者按】9 月 7 日,在CSDN主办的「AI ProCon 2019」上,Google Brain 工程师,TensorFlow.js 项目负责人俞玶发表《TensorFlow.js 遇到小程序》的主题演讲,分享 TensorFlow.js 的技术实现和与微信小程序相结合的落地实践。
详情如何?一起来看看。
以下为演讲内容:
首先想问问大家有多少人了解或听过 Tensorflow.js 的?
不多。
再提问一个问题:这里有哪些同学希望把机器学习(Machine Learning, ML)落地到小程序或者前端?
也不多。
没关系,希望以下的分享可以帮助大家了解它。

初识 Tensorflow.js
Tensorflow.js 的目的是为了帮助前端工程师,降低加强学习的门槛。另外,让大家充分地发挥自身创造性,把机器学习落地到前端各个应用里。
它本身是一个全方位平台,它不是调用服务端的简单平台,而是完全由JavaScript 实现的平台,它可以让你已有的模型从 Python 转换过来,在浏览器里执行。也可以通过转移学习或者加强学习的方式对已有模型进行再训练。另外,它更能允许你创建模型,如果大家熟悉 Tensorflow.js,它有对应的 API,你可以创建模型,可以通过 JavaScript 来训练,一般是在 Node.js 比较合适,所以我们也支持 Node.js。
为什么大家对这个东西并不了解?可能大家并不了解它的应用场景是什么,大家普遍关注在大数据等比较宏大的问题上。个人认为,有很多小的问题也可以用它来解决,比如酷炫的交互方式完全可以用它来实现。

Tensorflow.js应用场景
Tensorflow.js 的应用场景有:
1、增强现实AR
比如抖音这些功能都是在端的实现,用 JavaScript 同样也可以实现。
2、基于手势或肢体的交互
现在我们的交互方式有手机用手指,网站用鼠标。通过它可以增加新的交互方式,比如用嘴型、眼神、手势。
3、语音识别
使用它后,可以把语音识别注入到网站里,还可以增加一些新的体验、新的交互方式,后面我会举一些例子。不管怎样,Web是一个以文字为主的环境,针对文字的模型在这个交互环境里是非常合适的,比如语义分析、智能会话,这些模型可以直接在 App 里执行。最后,可以通过分析,用设备本身的性能或者网络情况,来优化网页。
这些场景为什么用端上的机器学习来实现而不是用服务器呢?其优势是:
1、保护用户隐私
2、减少响应延迟,减少流量
它并不需要网络,如果网络不好或者本身流量有限制,可以帮助用户减少流量。
3、提高用户体验
有些功能无法做到实时的,可能 5G 将来有可能,但现在是做不到的。
4、降低服务器费用
通过把 ML 放到端上,减少了在服务端的依赖。如果开发者自己搭建服务的话,费用会很高,这可以减少服务器的费用。
Tensorflow.js 的目的就是为了简化这些问题,为前端工程师提供所有可以实现的这些功能,我们的目标是提供很多已有的模型给大家去用。而且这些模型是开源的,你可以随便用。

五大模型
Tensorflow.js 提供五类模型:图像分类、物体识别、姿态识别、语音命令识别、文字分类。直接用 NPM 安装,或者直接通过 JavaScript 也可以把它装上,放到网页里。
1、姿态识别

姿态识别模型在小程序里可以跑,它提供的是人的五官的坐标、四肢关节的坐标,它有多种不同的精度和速度优化版本,通过安装不同的版本可以在不同的设备上去跑。
2、人物分割

它可以帮你做背景虚化,或者是人的各个部分的分类,比如头部、躯干、四肢。还可以做很多有意思的事情,且针对不同的设备有不同的精度。
3、高分辨率的面部跟踪

这是我们即将推出的一种模型叫 FaceMesh,大概有 400 个关键点在人的脸上,并且提供的是一个三维的人脸模型。
4、语音命令识别
我们曾经让一个渐冻症病人跟机器交互,用激光点按各个键,交互速度非常慢,渐冻症病人不能说话,但是他可以发出一些声音,他的声音是有不同意义的,我们通过这个模型对他们做了个性化的交互方式。让他们很容易地用不同的声音,比如说“我要有一个披萨”,它通过不停地训练来增加词汇量。
5、文字模型
在文字模型中,支持如语气分析、毒性语言检测、智能回复,我们希望给大家做一些好用的、能用的模型。
6、转移学习
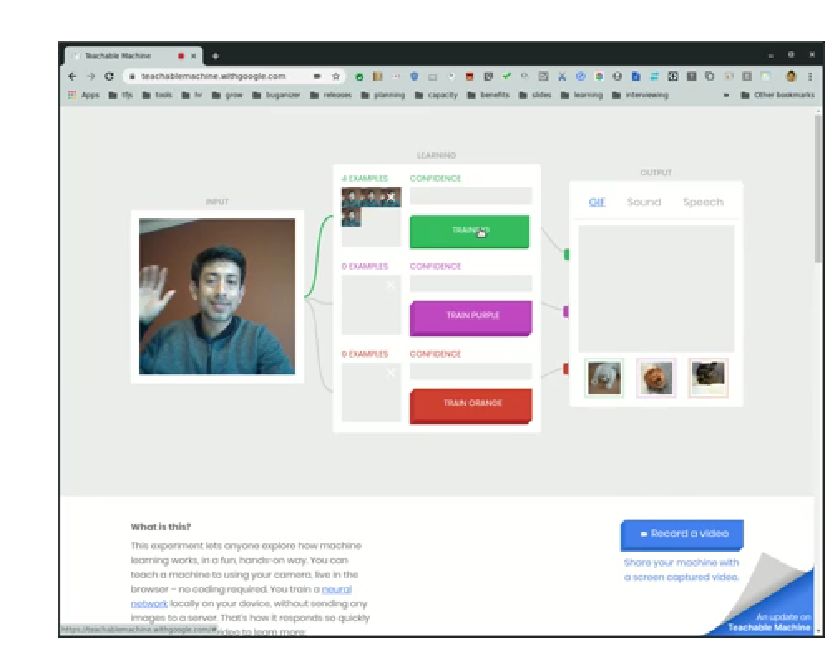
在示例里,我的同事做了 3 个不一样的动作,通过截取视频的图片开始实时训练这个模型,训练速度非常快,大概是几毫秒、几十毫秒,现在他以非常高的精确度来识别 3 个不同的动作,一是招手,第二个是摇头,第三个是把手放在嘴旁边。
7、支持多平台
Tensorflow.js 支持多平台:无线端(微信小程序、React Native)、服务器端(Node.js);台式机(Electron)、浏览器(谷歌浏览器、火狐浏览器、safari浏览器)。
下面给大家讲一个例子,在谷歌搜索引擎上,有一个它的Logo的图片,我们把这图片转成了一个游戏。这是为了纪念十八世纪的巴赫,他做出来的曲子非常有节奏。所以我们做了一个模型:玩家可以在一个声部编一个曲,最终通过机器模型形成了完整的四声部的协奏曲。
这个模型是 CoCoNet,玩家总在线时间 78 年,分享超过 5 千万创作,大概是最大用户生成的交响乐库了。它用到的技术是 Tensorflow.js 和谷歌的 TPU。
有些用户手机并不快,所以要到服务端,如果手机性能不错的话完全可以在手机上执行。还能节约 50% 服务器费用,因为充分运用用户的 GPU,可以想象,如果是一个很大的项目,可以节省的费用有多大的。

Tensorflow.js 遇见微信小程序
最近微信做了一个大学生小程序大赛,这是得奖同学做的一个手语识别项目。它首先能够手势识别,对一个手势能认知,并且得到它的含义。

下面是整体句子的识别,它在简单的 CNN 模型上实现了 RNN 的语义模型,这好像是花了一个星期做出来的。
下面看看小程序在美妆领域的应用,和 ModiFace 合作推出了阿曼尼的美妆小程序。这个小程序在端上做美妆的过程中遇到很多挑战:
1、不可能把用户的图片实时传到服务端进行实时跟踪,实时得到结果,必须在端上才能实现,至少要达到 10FPS 才能有连续的感觉。
2、微信对于插件的 JavaScript files 有 2MB 的限制,加载模型也有延时的问题。
3、模型是自主开发的,有他们特定的算子、特定的框架。另外,手机多样性也导致他们很难来满足这些需求。
他们在考虑模型框架和其他部分的结合方面做了很多选择和尝试,也看了不同的框架,最后选择 Tensorflow.js。
我们通过模型和框架的结合来以上问题得到解决:
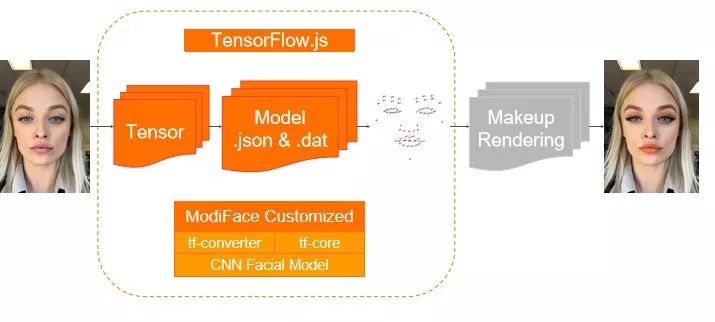
优化结果:
1、ModiFace 虚拟试妆插件共 1.8MB,其中 JavaScript 文件是 983KB,Model Files 是 829KB。ModiFace 虚拟试妆插件运行速度为 25FPS。
模型运行时间是 30ms,渲染时间是 10ms。
其实并不是一定要在服务端才能实现这个 ML,现在通过这个平台,很多模型都可以在端上实行。
很多同学可能觉得这个不适合才上手 ML 的同学,但是我们把这些都简化出来了,大家可以想象,原来数据库也要有好多安装复杂的步骤,后来为什么都没了?因为工具给大家解决了大部分问题。

流程图
给大家举个例子,假设产品经理要求你这个星期做出墨镜试戴 AR 的网站,你很生气地想,这周末要加班了。
我现在给你一个流程图参考,看看能不能帮你少加几天班。
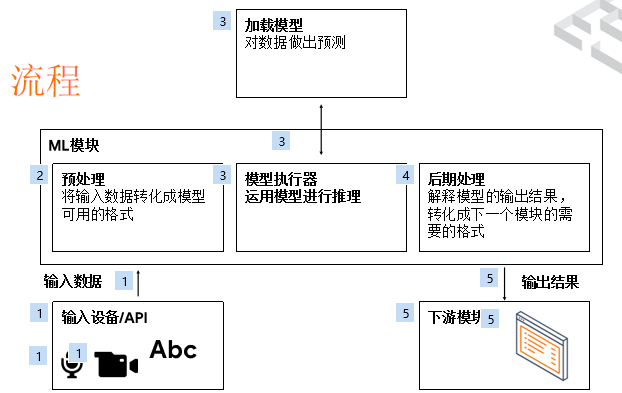
流程图是这样的,一般情况下有一个输入,输入可以来自很多小程序具有的 API,然后对于一个 ML 的执行环境来说,它必须把输入格式转化成 Tensor,转化成模型可以消费的模式,选择一个正确的模型或者创建一个模型,通过这个模型执行得到一个推理结果。
推理结果后期处理有时也是非常复杂的,因为模型本身不是给前端开发者用的,ML 工程师并不是很在乎前端用户怎么用,所以你还要做很多工作把这个结果解释出来。
因为 ML 只是一个模块,对于整个应用来说只是一部分,不能提供完整的解决方案,所以往往把输出结果给下一个模块去执行。
从这个流程图分析一下怎么解决做 AR 网站的问题:
1、预处理
抓取视频数据,然后把它们转化成模型可以用的结构。Tensorflow.js 提供数据API,支持 Camera、Audio、Image、CSV等。
2、模型选择
选择一个模型或者创造一个模型是很难的,因为需要实时识别人脸,实时的测人脸关键点,判断出人脸的朝向,知道他抬头/低头/朝左/朝右脸的朝向要有3D的判断。
于是我们推出 Facemesh,实时人脸关键点检测及跟踪模型,速度非常快,可以检测唇、眉毛、眼睛等,还可以做很多事情。
另外,后期处理也很复杂,即使给你一个三维的点,你也不知道摄像头在坐标系里在哪,如何把三维模型放到人脸的座标系里,这也不是那么简单,因为这跟摄像头的结构,是透视型摄像头还是平行摄像头有关系。最终还要渲染3D模型,这要求速度要够快。
Facemesh 的速度能做到 10ms 的推理速度,并且提供 3D 坐标转换的 API。
Three.js 超级高速 WebGL 渲染模型在小程序里也是可以跑的。
回到 AR 网站,现在是不是可以解决你的问题了?
通过数据 API 可以抓取数据,Tensorflow.js 平台运行速度非常快,Facemesh 3D 坐标转化API将带来非常简化的工作,最后把输出结果交给Three.js 去渲染。
代码举例:
这是一个加载模型,load 调用模型,输出的结果是非常易于理解的输出结果,而不是用 Tensor 给你显示的结果。

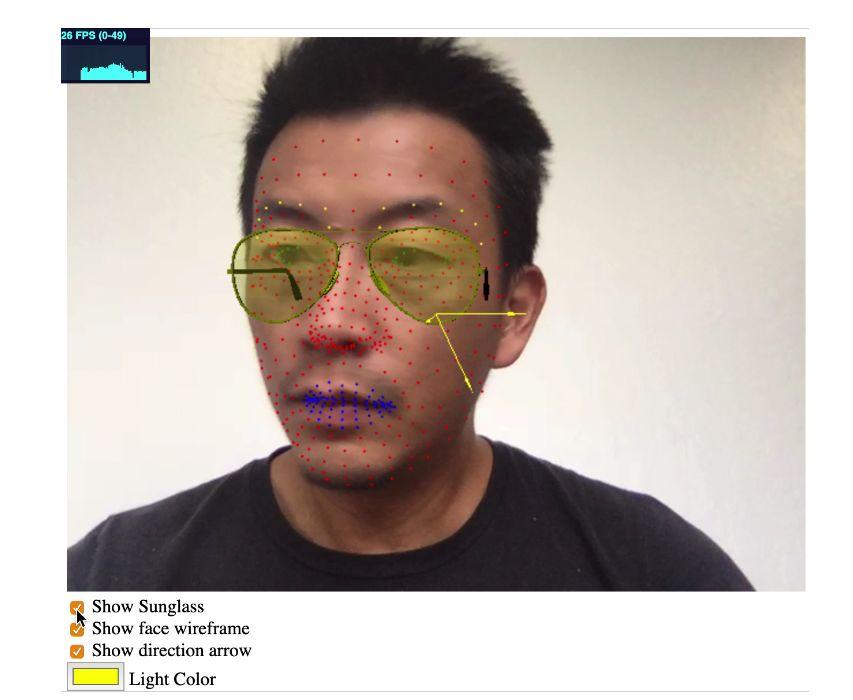
这段是渲染的步骤,把模型输出的结果到 3D 模型上去渲染,最后结果是什么样?400 个点的渲染,它能够检查主要的位置,这是3维朝向的渲染,把三维眼镜放在人脸上,速度在 40 帧/秒左右,包括执行和渲染,这个例子不是小程序。

Tensorflow.js技术架构
最后给大家分享下 Tensorflow.js 为什么速度这么快?
1、这是用JavaScript做,但是和 Tensorflow 兼容,提供三个不同层次的 API:先是模型,可以直接在模型上调用,开发者不用了解创建模型和加速模型。如果希望自己创建模型就用 Layers API。还有 Core API,这跟Tensorflow 的 CAPI 是一致的。
2、后端分两种情况:
(1)在客户端直接支持 WebGL,可以无缝加速。
(2)在服务端主要提供 Node.j s的支持,直接跑在 Tensorflow 的 CPU、GPU 上,还有 Headless GL。

性能分析
在服务端,Tensorflow.js 的速度基本和 Python 是一致的,这是高端的GPU,速度是八毫秒,我们在 CPU 甚至还稍微快一点。
由于在 JavaScript 这个层面,在端上基本没有别的系统跟 Tensorflow.js 进行比较,所以我们选择跟原生系统进行比较。
在iPhone上Tensorflow.js运行的速度是22.8毫秒,是一个标准的MobileNetV2 1.0-224 的模型执行时间。另外,在安卓上,Tensorflow.js 渲染稍微落后,安卓 CPU 大概是 50 毫秒,Tensorflow.js 是 100 毫秒,安卓的 GPU 是 12 毫秒,Tensorflow.js 也在尽量去拉近这个距离,这是我们接下来的研发主要方向,希望能提升速度,特别是在安卓方面。

Tensorflow.js 未来研发方向
Tensorflow.js 在未来的研发方向是:
1、我们将寻找好用的场景给大家提供完整的解决方案。
2、Tensorflow.js 将支持 AutoML,这是在谷歌云的一个服务,可以自动寻找最佳的结构,去解决已有的定制模型。
3、在 Node.js 上发力,目标是提供全栈在服务端加强学习训练、部署的平台。假如公司是用 Node.js,为什么还要用 Python?我们希望把这个门槛降低,让开发者训练模型,并且融入到已有的环境里,这也是针对中小型企业的,因为大企业可能已经有这些平台了。
4、用最新的技术提供更新的优化,例如 WASM、WebGPU 等。
5、支持更多的 JavaScript 运行平台,将和支付宝小程序、谷歌小程序合作。
Tensorflow.js 大概是一年前推出的开源项目,目前发展很快,大概 700K 的NPM 下载,5M CDN 的点击,11K GitHub Stars,贡献者超过 120 人。
俞玶简介:Google Brain 工程师,TensorFlow.js 项目负责人。他致力于将深度学习引入到 Web 和其他 JavaScript 开发平台。他曾担任谷 Google Attribution 平台的技术负责人。俞玶是清华大学理学学士,UMCP 理学硕士。
【END】
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号