掌握Node.js:一起来学习stream吧
发表时间: 2022-07-18 07:26

流(streams)是大多数 Node.js 应用程序所依赖的主要特性之一,尤其是在处理 HTTP 请求、读/写文件和进行套接字通信时。流是可预测的,因为我们在使用流时总是可以预料到数据、错误和结束事件。
本文将教 Node 开发者如何使用流来有效地处理大量数据。 这是 Node 开发人员在处理大型数据源时面临的典型现实挑战,一次处理这些数据可能不可行。
流的类型:
以下是 Node.js 中的四种主要流类型:
什么时候使用流?
当我们处理太大而无法读入内存和整体处理的文件时,流便会派上用场。
例如,如果您正在开发一个视频会议/流媒体应用程序,该应用程序需要以较小的块传输数据以启用大容量 Web 流媒体,同时避免网络延迟,则考虑 Node.js 流是一个不错的选择。
让我们看一个典型的例子:
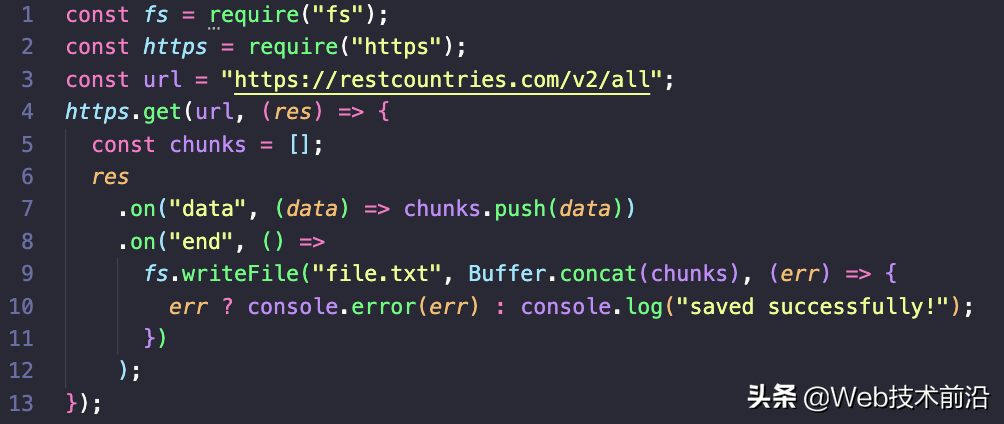
在这里,所有数据都被推入一个数组。 当触发data事件并且触发end事件时,表明我们已经完成接收数据,我们继续使用 fs.writeFile 和 Buffer.concat 方法将数据写入文件。这段代码的主要缺点是如果数据过大时,内存会分配不足,因为所有数据在写入磁盘之前都存储在内存中。所以流是我们读取写入大量数据时更有效的方法。
Node.js fs 模块公开了一些本机 Node Stream API,可用于流。我们将介绍可读、可写和转换流。
可写流
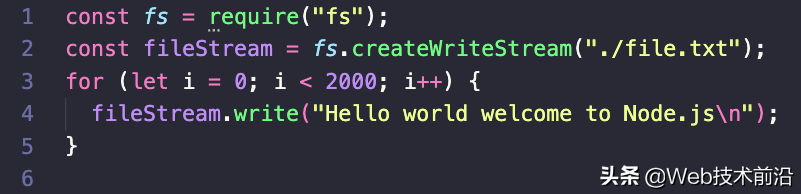
可写流是使用 createWriteStream() 方法创建的,该方法需要写入文件的路径作为参数。运行上面的代码片段将在你的当前目录中创建一个名为 file.txt 的文件,其中包含 2,000 行 Hello world welcome to Node.js。
可读流
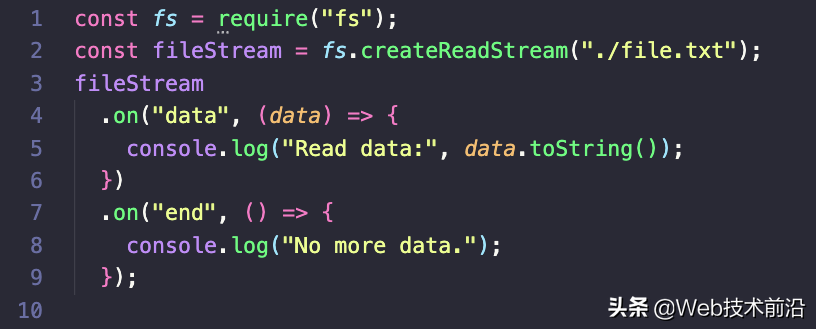
在这里,数据事件处理程序将在每次读取数据块时执行,而结束事件处理程序将在没有更多数据时执行。运行上面的代码片段将记录 2,000 行 Hello world welcome to Node.js 字符串,从 ./file.txt 到控制台。
转换流
转换流具有可读和可写的特性。 它允许处理输入数据,然后以处理后的格式输出数据。要创建转换流,我们需要从 Node.js 流模块中导入 Transform 类。 转换流构造函数接受一个包含数据处理/转换逻辑的函数:
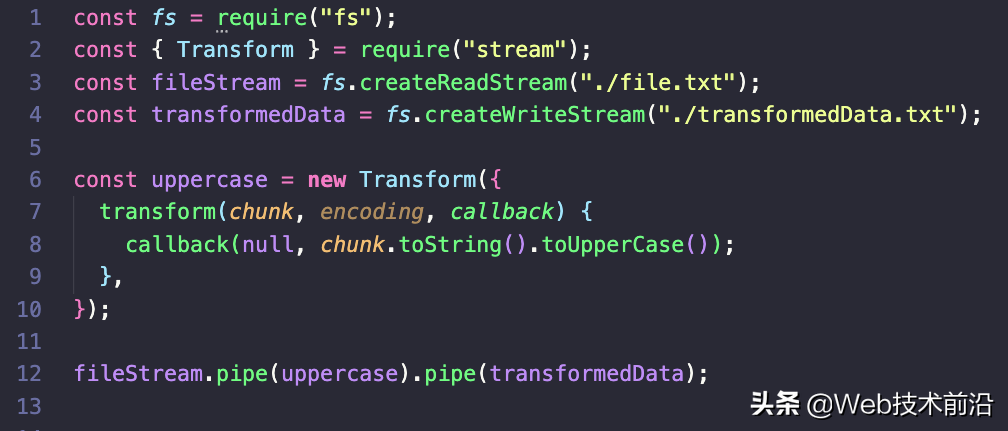
在这里,我们创建了一个新的转换流,其中包含一个需要三个参数的函数:第一个是数据块,第二个是编码(如果块是字符串,它会派上用场),然后是一个回调,它被调用 转化的结果。运行上述代码段会将 ./file.txt 中的所有文本转换为大写,然后将其写入transformData.txt。如果我们运行此脚本并打开生成的文件,我们会看到所有文本都已转换为大写。
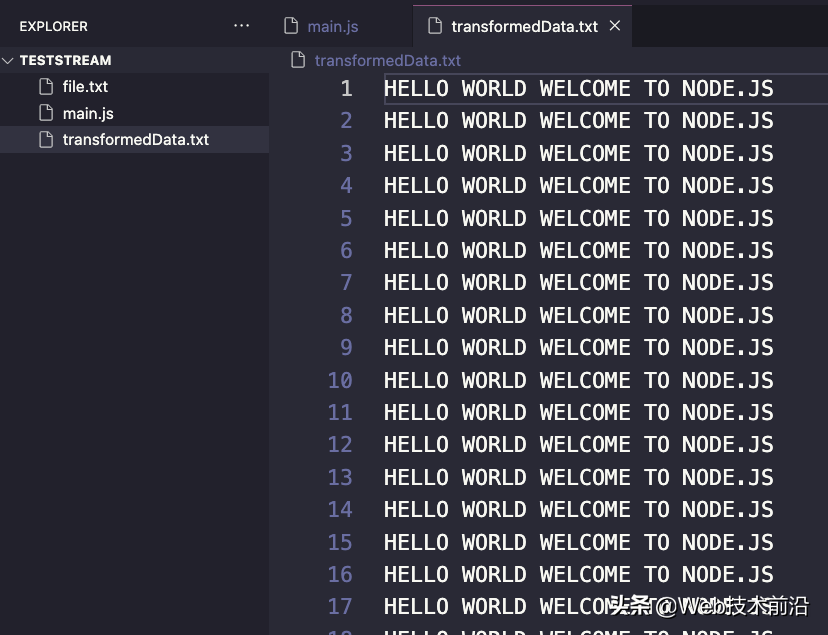
管道流
管道流是用于将多个流连接在一起的重要技术。 当我们需要将复杂的处理分解为更小的任务并按顺序执行它们时,它会派上用场。 Node.js 为此提供了一个原生管道方法:

错误处理
使用管道错误处理:
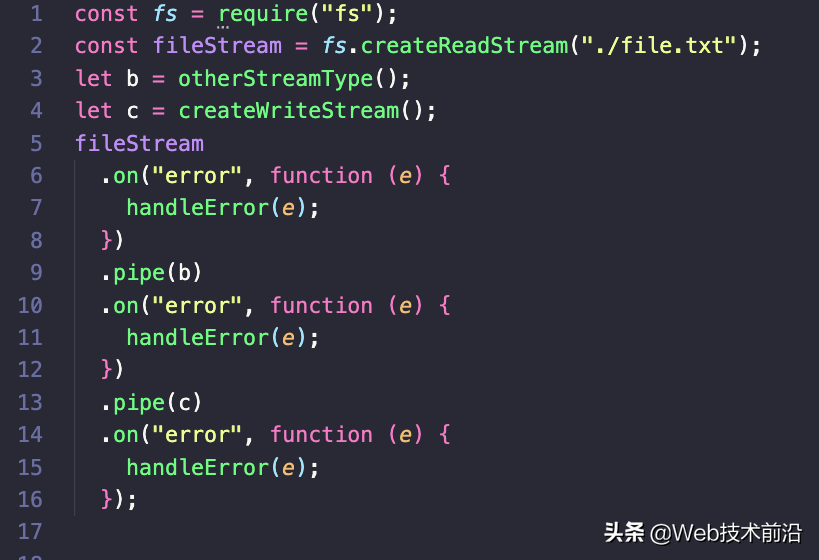
如上面的代码片段所示,我们必须为每个创建的管道创建一个错误事件处理程序。 有了这个,我们可以跟踪错误的上下文,这在调试时很有用。 这种技术的缺点是它的冗长。
使用pipeline处理错误
Node 10 引入了 Pipeline API 来增强对 Node.js 流的错误处理。 管道方法接受任意数量的流,后跟一个回调函数,用于处理管道中的任何错误,并在管道完成后执行:
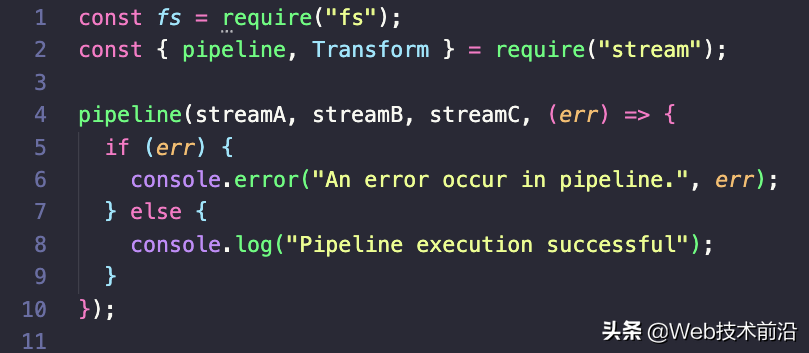
使用pipeline时,应按需要执行的顺序依次传递一系列流。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号