揭秘实测:OpenAI新模型o1做题能力惊艳,实战表现如何?
发表时间: 2024-09-18 15:43

今天凌晨,OpenAI 发布了 o1 系列模型,最大的特点是擅长推理。
模型的能力,一代比一代强,我们的测评,一次比一次难做。测评变成一件「毕恭毕敬」的事情,生怕提不出好问题(难不倒它),在让它推理之前,我们自己的脑子就快烧没了。
最重要的原因是:我们想知道,被寄予厚望的新一代模型,有没有应用到实际生活中的推理能力?以及要如何测出这样的能力?
秉承着这个想法,我们设计了一套考验 o1-preview 综合能力的「考卷」。
省流版结论如下:它擅长做题、搞研究,更像一个适合待在实验室的高材生,你现在还不能指望它成为生活里的助手。
热身:数学与逻辑能力强,速度还不慢
发布会的数据大家看了很多,尤其是新一代 o1 在各项任务上的评分,都有超乎以往的表现。比如 OpenAI 的官方文档里,特别提到 AIME 数学竞赛的考试中,o1 都能取得不错的表现。
快速查了一下,这个 AIME 比赛,考题长这样:
原题粘贴过去,看看究竟是怎么个超强表现。o1-preview 反应很迅速,上手就开始解题了。
对比一下官方答案完全正确。反应时间也比预计的快,只是思考过程,并不是默认展开。
所以除非手动下拉,否则从用户的观感上看,它就是自己卷成一团在跑计算,这是个交互设计上面可以提升的地方。
不过,对比 AIME 官方解答,o1-preview 的回答比较冗长——指望靠 GPT 开挂的中学生朋友,可别指望照抄,要自己思考呀。
逻辑推理题方面,我们沿用了一些「过往真题」:
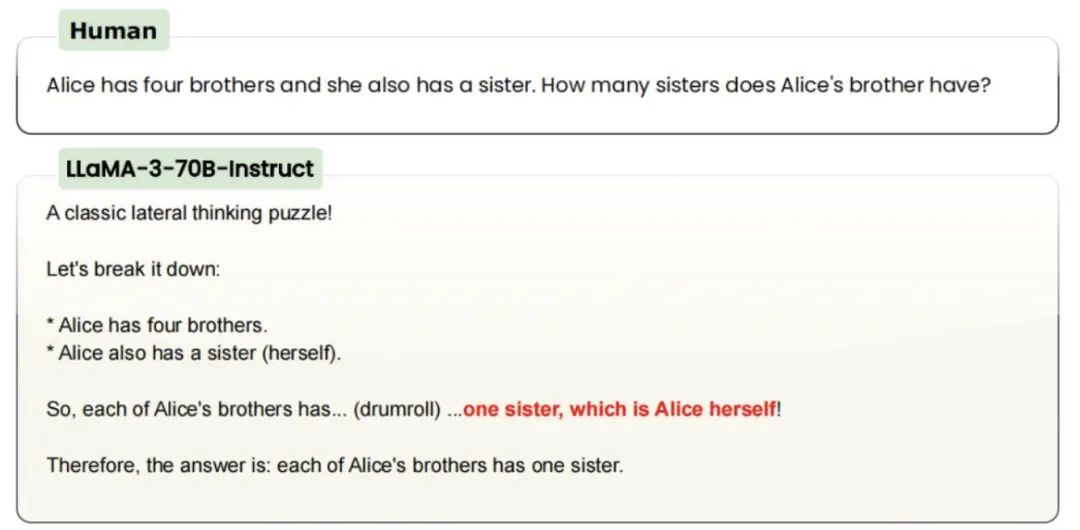
爱丽丝有 4 个兄弟,她还有 1 个姐妹。爱丽丝的兄弟有多少个姐妹?
你可能会奇怪,这不是很简单吗?——答案是 2,加上爱丽丝自己。
不出意外,o1-preview 很快答对了,甚至没告诉我思考多久,快到有种「就这?几秒」的感觉。
不过,今年 6 月,开源 AI 研究机构 LAION 发现,GPT-3.5/4、Claude、Gemini、Llama、Mistral 都没能答对这类题目,某种程度上连小学生的推理能力都不如。
直到现在,GPT-4o 也还是答错了。
可以说,o1-preview 的推理能力的确提高了。
进阶考验:情景推理慢于GPT-4o,但更准确
接着是测试 LLM 模型的经典必考:海龟汤问题。
一名男人发现自己少贴了一张邮票,随后便去世了。请问发生了什么事?
海龟汤是一种推理游戏,出题人给出简短、模糊的故事背景,由玩家自己主动提问。出题人只会回答「是」和「不是」,然后玩家根据出题人的回答,结合自己的推导,给出故事的真相。
我给了 o1-preview 五次提问的机会,然后让 o1-preview 尝试推理真相。每一次提问,o1-preview 都考虑了十几秒,层层递进。
但没想到,才问了 3 个问题,o1-preview 就迫不及待地给出推理了。
不得不说,非常接近真相。
这道题的标准答案是,男人寄送定时炸弹给仇人,但因为少贴了邮票,炸弹又被退回,结果一爆炸,炸死了自己。
o1-preview 的方向是对的,稍显缺乏了一些准确和完整,少了一些细节,但很接近正确答案。非要挑刺的话,可能是没有遵循我的提示词指令提问五次。
不过,和 AI 玩推理游戏很有意思,可惜目前新模型的额度有限,o1-preview 每周 30 条,o1-mini 每周 50 条,为了避免浪费宝贵的提问次数,下面的又一道海龟汤题目,我要求 o1-preview 一次性提 8 个问题,然后根据我的回答直接给出答案。
这次它的表现相当令人惊讶:o1-preview 只思考了 10 秒,提出的问题全部直击要害,真相呼之欲出。
比较搞笑的地方是,大家可以点开看看 o1-preview 这短短的十秒里都想了什么——我的同事忍不住吐槽:这 AI 戏也太多了吧。
等我一次性回答「是」和「不是」后,o1-preview 又花了 13 秒给出答案,基本就是标准答案。
以后再玩这种推理游戏,要严防死守有人掏出手机,用 AI 作弊。
相同的问题给到 GPT-4o,长处是一如既往,够快,几乎是实时的,但思维更跳脱。
答案嘛,稍微有偏离,而且看上去对自己的答案不是很自信的样子。
压轴大题:自作主张教人剁手,上得厅堂下不了厨房
普通用户最关心的,肯定不是新模型的「卷面能力」,谁闲着没事儿会突发奇想,打开手机算个鸡兔同笼啊?
比「卷面能力」更有用的,是处理生活实际问题,而且不是应用题,是正经八百生活中会碰到的计算问题。
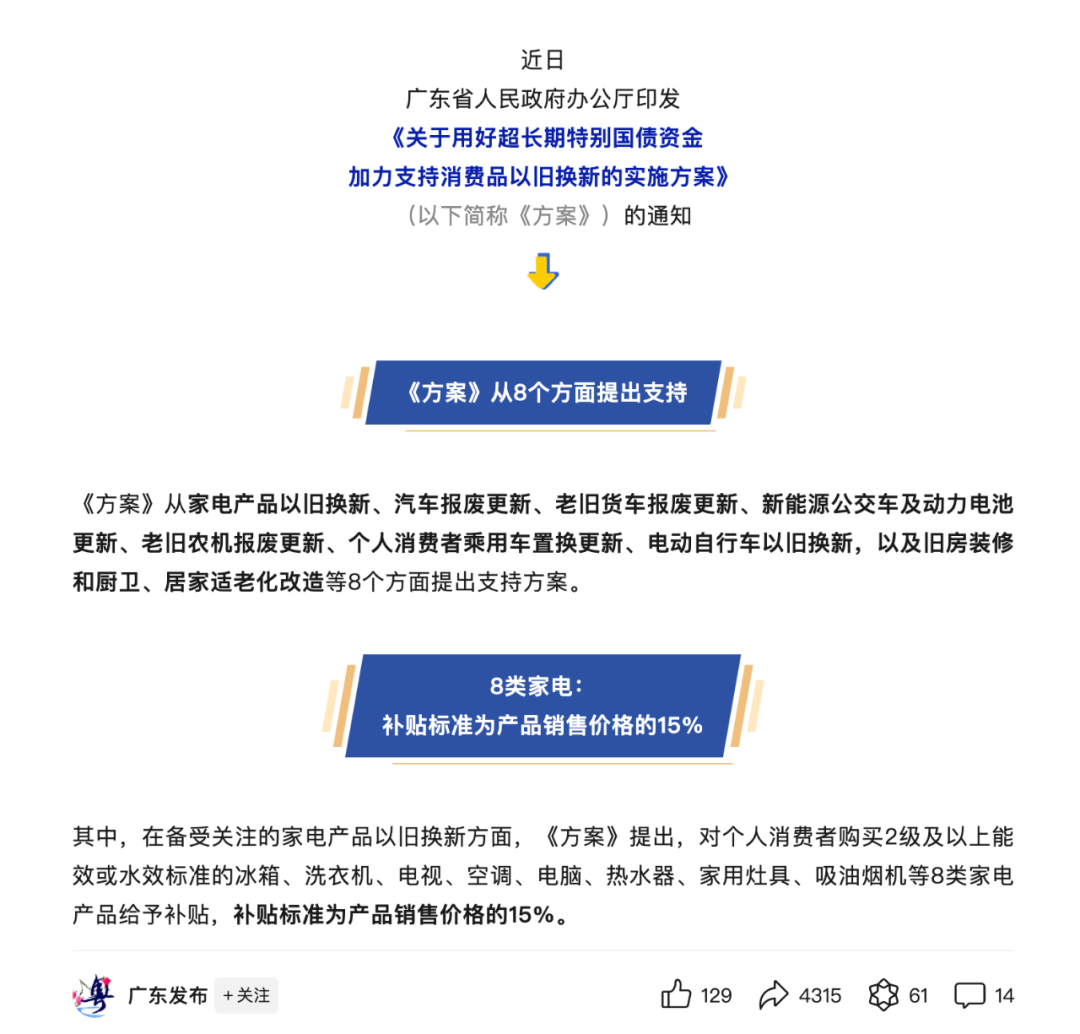
眼下,多地都在派发电子消费补贴,国家对各类消费电子产品,最高可以补贴 2000元。
官方发布很简单,但实际用起来就不是了。只能以旧换新?有什么地址限制?哪里领券?有没有最低消费?
来,让 o1-preview 过来帮我算一下,到底可以薅到多少羊毛。
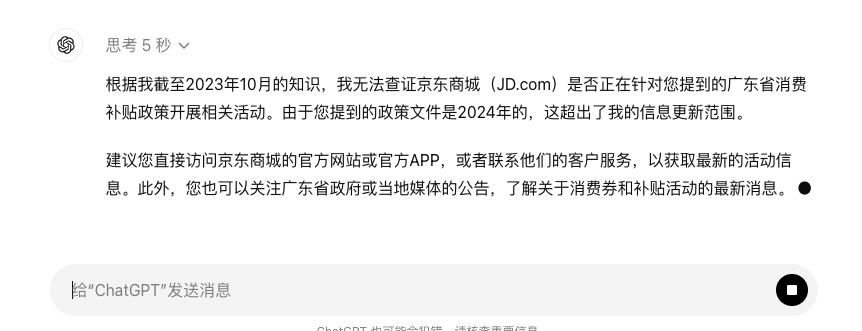
比较遗憾的是,o1-preview 的知识库截止到去年十月,对新政策没办法实时反应。
行吧,那就先手动录入一下,在输入广东省官方给的细节之后,它反应速度非常快,直接「自作主张」地把各种常见优惠都算进去了。
但都是「假设」,做不得数。在搜集了一些实际优惠政策之后,我们手动录入 prompt:
我需要买一台新电脑,现在有一万左右的预算,想买一台最新款的 MacBook Air。现在京东有优惠活动。条件如下:
1.政府补贴,按照标价减免 20%,2000 元封顶
2.苹果自己有满 7000 减 1400 元的优惠
3.苹果电脑可以以旧换新,但需要根据旧机品相定价。详细的品相信息已经列在下面
因为不能浏览网页,它自己设定价格为 9499 元,但不一定反映出实际上电商的挂牌价。
另外则是旧机价格的判断,京东给出的报价是 3300 元。
京东估价
同样的旧机,多跑几次提示词,每次 o1-preview 都会给不同的报价,仅供参考,其中 3400 元是和京东报价最接近的一次。
o1-preview 估价
更关键的是,这些写在提示词里的信息都要我们自己去找和整理,AI 没能节省多少时间。
买东西时算优惠价,就是日常生活里最实际的数学场景了,谁能忘记被双十一支配的恐惧。
而且算优惠的难点在于更广泛的推理:单纯的加减,犯不着找一个 AI 来做,电商平台自己会帮用户算好,购物车里一勾就是了。
真正烧脑的,就是「规划」一个最优惠的路线,这涉及到很多问题:
同一时期哪家电商在做优惠?用户是否具备参与优惠活动的资格?外部补贴的能否作用在这家电商?例如这次的国家补贴,是要看用户领取资格的,在京东用了就不能在天猫用。
甚至,一些线下店也参与补贴活动,但是前提是在线上领取之后线下使用。
说实话,这种繁琐场景特别需要一个助理,可需要的是一个脑筋灵活的真·智能助手,而不是一个僵板的做题家。
「考试」总结:做题虽好,仍要走入现实
不管是我们自己做的测评,还是许多网友都已经有的测评,甚至包括官方的演示文档,都有非常强烈的「做题」感。
做数学题、做阅读理解题、做填空题。
这世界还是变成了大家想要的样子:新的模型降临人间,第一件事是做题。
做题当然是很好的摸底模型能力的方式,然而做题的毛病也非常明显:很真空,不知道这么强的做题能力,到底有啥用。
甚至在自媒体赛博禅心的技术面测评中,API 端口的表现也非常差强人意,进一步限制了实际应用。他认为这次更新,比较像是工程上的优化,而非底层能力的迭代。
像极了专四专六级考高分,出国却依然寸步难行、开不了口的我(不是)。
老实说,这是一个用户预期的问题,切记:OpenAI 眼中的推理,并不只是计算能力。
计算的确是「推理」里重要的一部分,但不是全部,尤其是当谈到真正介入实际应用的推理能力,计算就仅仅是非常小的一部分。
这也是为什么在这次的官方文档里,有一个小节在解释「思维链」:通过模拟人类的思维过程,帮助模型逐步分解复杂问题。
这项能力的提升,在 o1-preview 应对数学和推理题的过程中,都得到了体现。
只是,要说它能全面模仿人类的思维过程,暂时还称不上:人类不仅会拆分步骤来思考,更会综合性、全局性的来思考。
走向 AGI 的道路,已有曙光,但仍然漫长。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12














 鲁公网安备37020202000738号
鲁公网安备37020202000738号