如何在3秒内用Python处理分析128张Excel表格?| 附数据集
发表时间: 2019-11-06 17:43
有不少旁友想要了解怎么用Python提升处理数据的效率,或者说怎么用Python自动处理多张Excel表格,于是乎便有了本文。这篇文章算是Python数据分析实战的第二个独立案例。

案例背景
在另一个平行世界,有一家专注于户外运动的巨头公司。既然是巨头,为了更加亲切,我们就叫他大头吧。大头的旗下有20个品牌,这些品牌涉及到128个类目(细分行业),涉及范围之广令人咋舌,可谓遍地开花。
平行世界的小Z就是这家巨无霸的数据分析师,今天刚来公司就接到了一个需求——下班前务必筛选出近一年销售额总额TOP5的品牌以及对应的销售额。
近一年?TOP5?
WOC,这么简单的需求也算需求?直接排个序不就好了。
还一天时间,不急不急,先来一杯咖啡,再看看新闻。

一眨眼的功夫,时间来到了17:30,小Z觉得今天的需求可以开动了,做完之后还能简单分析一下,应该能赶在18:00整点下班。
当他打开同事共享给他的表格文件,他才体会到,绝望,原来这么远,又这么近。

业务部门的同事总共发来了128张表,每一份表格对应着一个细分行业的数据,像什么各类户外服装、垂钓装备、救生装备应有尽有。
每张表,以月的维度(2018年9月-2019年8月,近一年)记录着每个品牌的日期、访客、客单、转化、所属类目(细分行业)等数据:
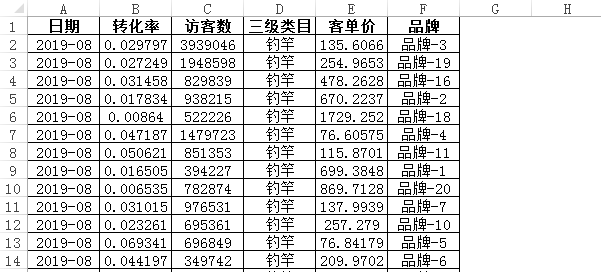
注:不要问为啥表格数据存储这么奇葩,因为在平行世界,就是要任性,毕竟复杂的表格才能体现出Python的高效
小Z开始盘算,最终需求是要筛选出近一年销售额总和排名前5的品牌,这一摊子数据,对单独的一张表进行分类汇总,能够得到该细分行业各品牌的销售额,想要得到所有行业的销售额总和,得分类汇总128次,最后对128次结果再次合并。
“这个任务看上去很艰巨,不过,考验的主要是体力。”小Z一眼就“看穿”了事情的本质。同时脑海中蹦出了“红军不怕远征难”几个红彤彤的大字。接着,他带上耳机,打开了唐朝乐队的“国际歌”,在双重buff的加持下,开始了表格的远征。

果然是个处理数据的好手,小Z右手食指在鼠标上飞速跳动,以90秒一张表格的速度疯狂推进。按照这个速度,不考虑疲劳值对速度的拖累,大概3.2个小时就能够完成任务。
国际歌循环到第10遍,小Z有些气馁,第20遍,开始感到绝望。

就在行将放弃之际,他想起了Python的潘大师(Pandas),虽然最近刚学还不是很熟练,但事到临头,黑暗中的一缕微光,那就是唯一的希望,小Z决定用Pandas来尝试解决问题。
他明白,用Python解决批量问题的核心,在于梳理并解决单个问题,然后批量循环。

单个表格处理
首先,导入模块,打开单个表格:
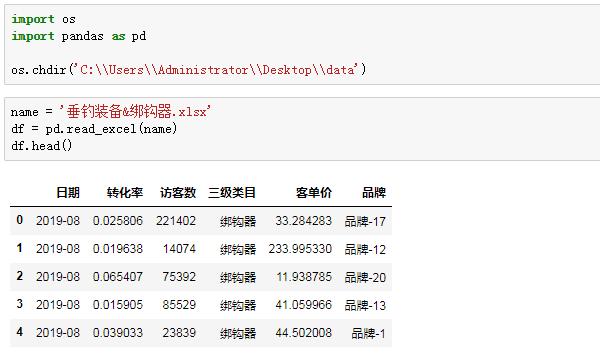
接着,是要汇总不同品牌在这个细分行业下的销售额,我们要汇总的是各品牌近一年(2018年9月-2019年8月)的销售额,先看看日期是否正确:

正要汇总销售额,小Z发现没有销售额的字段,但销售额是可以通过访客数*转化率*客单价三者的乘积来计算的:
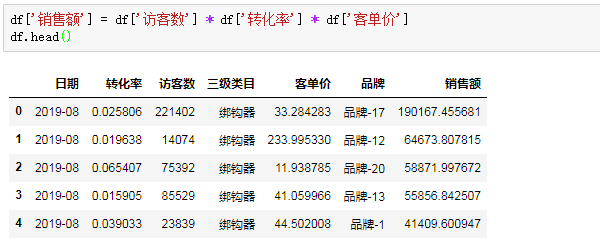
按品牌来汇总销售额,得到近一年各品牌销售额合计:

这里有个细节,最终小Z要汇总的是所有细分行业的销售额,对于单独行业的销售额,应该加一个区分的标签以防覆盖,而打开时候的文件名,具有天然的区分和防覆盖优势,但要注意去掉文件的后缀。

OK,单个表格处理完成,我们把这一系列操作推而广之即可。

批量循环执行
小Z用os.listdir方法来遍历文件名,批量循环访问并处理文件,同时引入time计时,打算看一看,面对128张表,Python完成这些操作到底能够比手动快多少:

WOC,整个过程一气呵成,不到3秒,平均一张表格0.02秒!真香!
为了确保数据正常,来预览一下:

这一串看起来很奇怪的销售额,是pandas自作主张把实际销售额变成了科学记数法形式来展示,要还原数值,需要更改一下原始的设置:
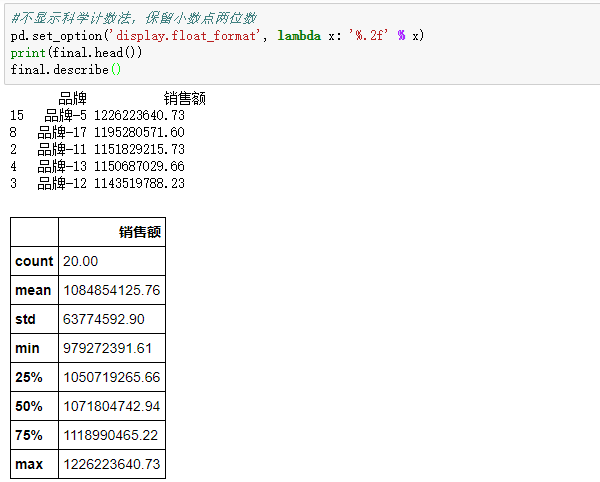
OK,无论是习惯还是法理,都得到了我们希望的结果——近一年销售TOP5品牌及其对应的销售额。从数据结果来看,大头公司下的20个品牌全面开花,以品牌5为先锋,一年销售高达12.26亿,排名最后的品牌体量也达到了9.79亿元,平均单品牌销售10.85亿元。

总结
本文以一个简单又复杂的场景切入,简单是需求本身非常简单,而复杂则是基础数据涉及到的表格多而杂。代码和逻辑本身浅显易懂,主要为了抛出一块砖,敲开批量处理表格的思维藩篱,以引出同志们实践中,在合适场景下用Python来化繁为简的玉。案例中表格共128张,大家可以自己尝试和探索更有趣的分析。
https://github.com/seizeeveryday/DA-cases/tree/master/Python%2Bexcel
作者:周志鹏,2年数据分析,深切感受到数据分析的有趣和学习过程中缺少案例的无奈,遂新开公众号「数据不吹牛」,定期更新数据分析相关技巧和有趣案例(含实战数据集),欢迎大家关注交流。
声明:本文为作者投稿,版权归作者个人所有。
【END】
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号