大数据如何影响你的思考方式?
发表时间: 2018-07-10 10:57

正文开始之前,请大家先看一个案例:
一家公司希望了解自家产品的用户画像,于是他们在产品包装上印上自家小程序的二维码,然后想办法促使用户去扫码(比如扫码查真伪、扫码学习食用方法等)。一旦用户扫描二维码,公司就能从后台了解他们的基本信息,比如下图就是对用户年龄分布的统计结果:
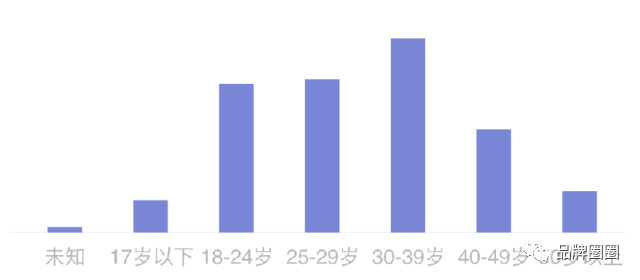
(PS:出于保密需要,这里暂且放一张P过的图来示意)
现在请问:哪个年龄段的人才是该产品的典型用户?
对于这个问题,我一共听到过三种答案:
那么,究竟哪种答案才更加正确呢?
我估计大部分人都会选第二种或者第三种吧?
最开始我也是这样解读的,认为该产品的典型用户就是“年轻人”。(若按照国家统计局的标准,也就是15—34岁的人)
不过说实话,这个结论还真挺让我惊讶。因为若根据我的常识来判断的话,它的典型用户应该是年纪稍大点的中年人才对。
该产品属于健康食品,主打“排毒”“减肥”“降三高”“治便秘”“抗酸”的功效(你先别笑它卖点太多不够聚焦,又不是走电视广告的路子),而这些功能属性,除“减肥”以外,我相信不少人都会跟我一样——若用常识来判断,它们应该更偏向中年人。
然而,数据结果却与常识判断相互矛盾…这时候,你到底该相信数据还是相信常识呢?
这是我最近在一个项目中遇到的一个问题,这个问题也的确让我纠结了一段时间。因为一方面有人说“数据是不会撒谎的”,而另一方面又有人说“做调研,常识才更加重要”…
不过,当我想起以前看到过的一段故事之后,问题就变得相对明朗了。
在二战期间,盟军的战斗机在战斗中损失惨重,于是盟军总部秘密召集了一批物理学家、数学家来专门研究“如何减少空军被击落的概率”。
当时军方统计了所有返航飞机的中弹位置,发现机翼部分中弹比较密集,而机身和机尾的中弹比较稀疏,因此当时普遍的建议便是:应加强机翼部分的防护。
然而,统计学家沃德却提出了一个完全相反的观点,他认为应加强机身和机尾部分。
沃德教授说:“所有的样本都是成功返航的飞机,也就是可能正是因为机翼遭到攻击,机身和机尾没有遭到密集的攻击,所以才使得这些飞机能够成功返航。”
后来又经过一系列有力的论证后,军方果真采用了他的建议。事后也证明这的确是无比正确的决策,有效降低了空军被击落的概率。

这个故事讲的就是所谓的「幸存者偏差」(Survivorship bias)
幸存者偏差是指:当取得资讯的渠道仅来自于幸存者时,此资讯可能会存在与实际情况不同的偏差。(因为死人不会说话)
那它跟之前用户画像的例子有什么关系呢?
关系很大。
虽然数据是不会撒谎的,但它只能展示出有数据(幸存者)的那部分信息,而无法展示没有数据(阵亡者)的那部分信息,它是片面的。
翻译到之前那个案例:如果仅凭扫过码的用户数据来判断产品的用户特征,其实是忽略了那些使用了产品但没有扫码的用户的数据。毕竟,不是所有用了产品的人都一定会扫码。
而这里有很多可能的因素会影响结果,比如:
总之,永远不可能得到完整的数据样本。
因此,回到文章最开始的问题——哪个年龄段的人才是该产品的典型用户?
准确的答案应该是:无法仅通过该数据就得出结论。
是的,到目前为止,我依然更偏向于相信常识——认为中年人才是它的典型用户。(估摸着至少也是30岁以上)
柏拉图曾在《理想国》的第七篇中,讲了一个著名的比喻——洞穴之喻(Allegory of the Cave)
设想有个很深的洞穴,洞里有一些囚徒,他们生来就被锁链束缚在洞穴之中,他们背向洞口,头不能转动,眼睛只能看着洞壁。
在他们后面砌有一道矮墙,墙和洞口之间燃烧着一堆火,一些人举着各种器物沿着墙往来走动,如同木偶戏的屏风。当人们扛着各种器具走过墙后的小道,火光便把那些器物的影像投射到面前的洞壁上。
由于这些影像是洞中囚徒们唯一能见的事物,他们便以为这些影像就是这个世界真实的事物。

在现实生活中,数据就像该比喻中印在壁洞上的影像——它试图利用低维的事物,去给人们描绘一个高维的东西。如果将洞壁的影像进行数据化处理,哪怕技术再先进,收集的数据再多,都难以让洞穴人感知到一个真实的世界,因为他们看到的世界都被“降维处理”了。
而另一方面,常识又是什么?
不可否认的是:常识跟数据一样,都是片面的。并且每个人的常识都不尽相同,质量参差不齐。
不过这里想说的重点是:相比于数据,常识能从更多得多的角度去分析一个事物。
因为人类的大脑很奇妙,它能把很多看似无关的事物联系在一起。而这一点,是任何计算机都很难以数据的形式做到的。
举个最简单的例子:人们可通过观察“一根筷子折得断,十根筷子折不断”的现象,悟出一个与之毫不相关的道理——团结就是力量。而同一个现象如果交给计算机去处理,那最后的结果就肯定只能与“材料”“扭矩”和“力度”等相关…

再比如迈克·亚当斯曾做过的一项研究,他发现:美国大学生期中考试临近时,奶奶去世的可能性是平时的10倍,而期末考试时是平时的19倍。(数据来自各高校收到的请假邮件和推迟交论文的申请)
若单看数据,你也许会认为学生的学术压力会对奶奶的健康造成影响(的确有科学家对此做过研究…);但若用常识去思考,那就很简单了——为躲避考试,学生们编造了“奶奶去世”的请假借口。
这就是常识与数据的区别——常识是多维的,数据是单维的。
数据真正的价值并不在于其统计或计算结果,而在于人们能对其做出正确的解读。不过这很困难,尤其当你面对的是残缺的数据。
就像我以前举过的一个例子:
据《2017社会大学英雄榜》显示,国内登上胡润百富榜的2000多位资产超二十亿的富豪中,有一半的人都是低学历。(PS,低学历是指本科以下的学历)
请问:从这条新闻中你能读出什么结论?
我想肯定有很多人会认为:学历的高低跟收入的确没什么关系。
然而,这种解读是错的。
正确的解读方式是什么呢?
应该是:中国在2016年末大约有13.8亿人口,其中本科及以上的只有3800万,本科以下则有13.42亿——低学历的人本来就比高学历的人多得多(35倍),而它们进入榜单的人数基本相同。因此,拥有高学历的人进入百富榜的概率,是低学历的35倍。
在这个例子中,所有的数据都是真实的。但如果你只看到一部分数据,而没有看到其他数据,那就很容易被数据给坑了,得出错误的结论。
当然,要想得出更加准确的结论,这里还需挖掘更多的数据。比如:
在这些富豪中,高学历的收入与低学历的收入的总体对比情况…
嗯,如果你不是专门学统计的,相信在加入这么多因素之后,一定会崩溃掉…不过你也不用慌,因为大部分情况下,你根本就没有机会能知道这么详尽的数据。
包括以数据著称的新零售。为什么大部分新零售项目仍然在亏钱?其实就是因为它们的规模还没有达到一定的量,数据的维度依然比较单一,“算”出来的东西依然不够精准,所以效率的提升也就很有限了。
文章读到这里,你也许会在心里嘀咕:小云兄你写这篇文章,是不是想告诉我们数据是没有用的呢?如果数据的结果都不够准确,那什么才是准确的呢?
首先,这里并不是说数据没有用,即使它是片面的。
所谓的要客观看问题,并不是指你一定要掌握了所有数据之后才能下定论,而是要在下定论之前,尽量多方面了解一些数据和信息,无论它们本身多片面。
多了解一点,犯错的几率就会小一点,多看到一面,你离客观的真相就更接近一点,这就是进步。
千万不要试图一下子解决所有的问题,或者以为一下子就得到准确的答案,因为这本身就是一种错误的价值观,或者说痴人说梦。(所以你也不用纠结“什么才是准确的”了,根本就不存在)
知道自己还有不知道的,并在问题中不断前进,这才是真正科学发展的思想。
相反的,如果仅凭单方面数据就武断得出结论,并且笃定得不行,那无论数据样本有多大,你的结论和真实情况都很可能是天差地别的。
作者:小云兄
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号