利用ChatGPT编写JavaScript代码
发表时间: 2023-04-05 17:07
一个数组A,由100个小数组组成,每个小数组由7个数字组成,对数组A进行对比查询,小数组有3个及3个以上元素相同的,进行console.log
可以使用双重循环来对比查询,外层循环遍历每个小数组,内层循环遍历其余小数组,进行对比。需要注意的是,内层循环应该从外层循环的下一个小数组开始,避免重复对比。
以下是示例代码:
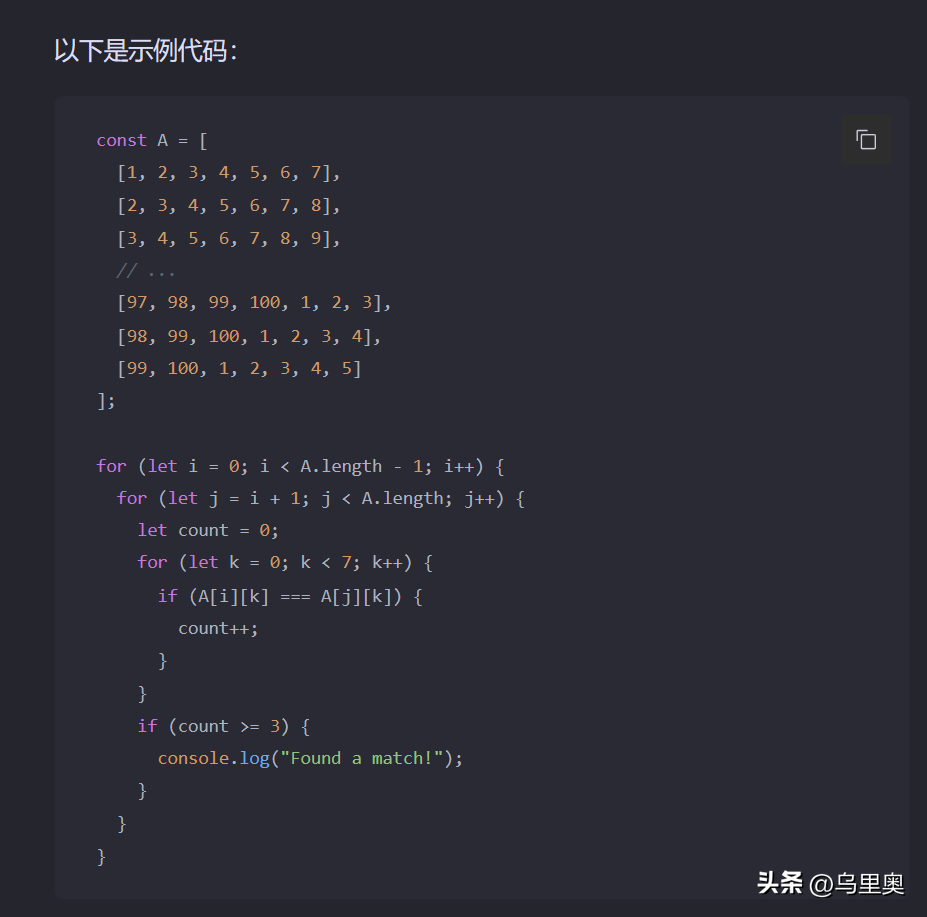
const A = [ [1, 2, 3, 4, 5, 6, 7], [2, 3, 4, 5, 6, 7, 8], [3, 4, 5, 6, 7, 8, 9], // ... [97, 98, 99, 100, 1, 2, 3], [98, 99, 100, 1, 2, 3, 4], [99, 100, 1, 2, 3, 4, 5]];for (let i = 0; i < A.length - 1; i++) { for (let j = i + 1; j < A.length; j++) { let count = 0; for (let k = 0; k < 7; k++) { if (A[i][k] === A[j][k]) { count++; } } if (count >= 3) { console.log("Found a match!"); } }}在上面的代码中,外层循环遍历了数组A中的所有小数组,内层循环从外层循环的下一个小数组开始遍历,对比查询是否有3个及以上元素相同的情况。如果有,则输出"Found a match!"。
有没有能提高效率的更好的方法
在大数据量的情况下,双重循环的方式会导致时间复杂度为O(n^3),效率较低。可以使用哈希表来提高效率,时间复杂度为O(n^2)。
具体方法是,遍历每个小数组,将其排序后转换为字符串作为哈希表的键值,将该小数组的索引作为值存入哈希表中。然后再遍历一遍数组A,对每个小数组进行排序后转换为字符串,查找哈希表中是否有相同的键值,若有,则输出"Found a match!"。
以下是示例代码:
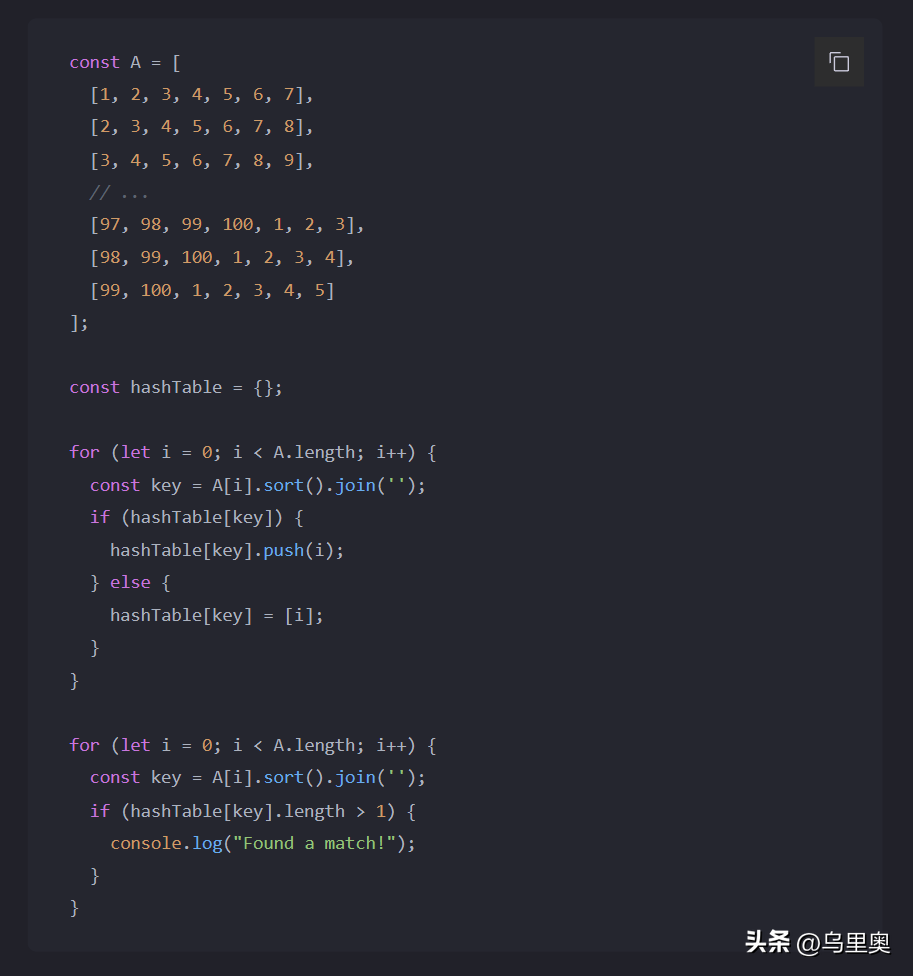
const A = [ [1, 2, 3, 4, 5, 6, 7], [2, 3, 4, 5, 6, 7, 8], [3, 4, 5, 6, 7, 8, 9], // ... [97, 98, 99, 100, 1, 2, 3], [98, 99, 100, 1, 2, 3, 4], [99, 100, 1, 2, 3, 4, 5]];const hashTable = {};for (let i = 0; i < A.length; i++) { const key = A[i].sort().join(''); if (hashTable[key]) { hashTable[key].push(i); } else { hashTable[key] = [i]; }}for (let i = 0; i < A.length; i++) { const key = A[i].sort().join(''); if (hashTable[key].length > 1) { console.log("Found a match!"); }}在上面的代码中,第一个循环遍历了数组A中的所有小数组,将其排序后转换为字符串作为哈希表的键值,将该小数组的索引作为值存入哈希表中。第二个循环再次遍历数组A,对每个小数组进行排序后转换为字符串,查找哈希表中是否有相同的键值,若有,则输出"Found a match!"。
使用哈希表的方式,可以将时间复杂度从O(n^3)降低到O(n^2),提高了效率。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号