谷歌与OpenAI联手,破解神经网络「黑盒子」的秘密
发表时间: 2019-06-21 15:20
雷锋网 AI 科技评论按:现代神经网络经常被吐槽为「黑盒子」。尽管它们在各类问题上都取得了成功,但我们仍无法直观地理解它们是如何在内部做出决策的。随着人工智能系统被应用到更多重要的场景中,更好地了解其内部决策过程将有助于研究者能够及时发现其中的缺陷和错误。对此,谷歌 AI 研究院与 OpenAI 一起合作提出了能够弄清这个「黑盒子」里面到底有什么的新方法——激活图集。谷歌在博客上发布文章介绍了这一意义重大的成果,雷锋网 AI 科技评论编译如下。
神经网络已成为图像相关计算任务中的实际标准,目前已被部署在多种场景中:从自动标记图像库中的照片到自动驾驶系统,我们都能看到神经网络的身影。鉴于机器学习系统的在执行方面的准确性比不使用机器学习、直接由人为设计的系统更好,机器学习系统开始变得无处不在。但是,由于这些系统所了解的基本信息都是在自动训练过程中学习到的,因此我们对于网络处理其给定任务的整个过程的了解,有时仍然隔着一层纱。
近期,经过与 OpenAI 同事的通力合作,我们在发表的《用激活图集探索神经网络》论文中(「Exploring Neural Networks with Activation Atlases」,论文地址:
https://distill.pub/2019/activation-atlas)论文中,描述了一种新技术,旨在帮助回答「给定一张图像时,图像分类的神经网络能“看到”什么」的问题。激活图集提供了一种融入卷积视觉网络的新方法,为网络的隐藏层内部提供了一个全局的、层级化和可解释的概念综述。我们认为,激活图集揭示了机器针对图像学到的字母表,即一系列简单、基础的概念,它们被组合并重组进而形成更复杂得多的视觉概念。同时,我们还开源了部分 jupyter notebooks 的代码,以期帮助开发者们开始制作自己的激活图集。
InceptionV1 视觉分类网络其中一层的激活图的详细视图。它展示了网络用于对图像进行分类的许多视觉检测器,例如不同类型的水果状纹理,蜂窝图案和类似织物的纹理。
下面显示的激活图集是根据在 ImageNet 数据集上训练的卷积图像分类网络 Inceptionv1 构建的。通常,给分类网络输入一张图像,然后令其标记出该图像属于 1000 个预定类别中的哪一类,例如「意大利面」,「通气管」或「煎锅」。为此,我们通过一个约十层的网络来评估图像数据,该网络每层由数百个神经元组成,且对于不同类型的图块,每个神经元在图像块的激活程度不同。某层中的一个神经元可能对「狗耳朵」图像块的激活程度更大,而另一层的另一个神经元可能会对高对比度的「垂直线」图像更敏感。
我们从一百万张图像的神经网络的每个层中收集到了内部激活图,并构建了一套激活图集。这些激活图由一组复杂的高维向量表示,通过 UMAP 投影到有用的二维布局中,其中 UMAP 是一种保持原始高维空间局部结构的降维技术。
这就需要组织激活向量,并且因为激活图太多而无法一目了然,所以我们也需要将它们整合成一个更易于管理的数量。为此,我们在之前创建的 2D 布局上提前绘制好了网格。对于网格中的每个单元格,我们对位于其边界内的所有激活取均值,并使用特征可视化来创建图标表示。
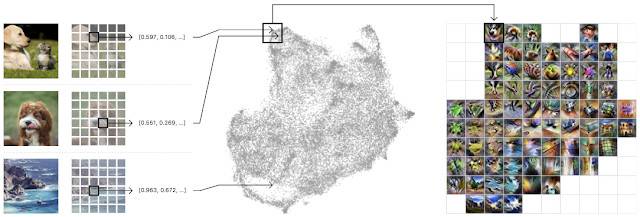
左:通过网络输入一组一百万张随机图像,每个图像收集一个随机空间激活图。中间:通过 UMAP 提供激活以将其降维到二维。然后绘制,相似的激活图彼此临近。右:然后我们绘制一个网格,对一个单元格内的激活取均值,并对平均激活做特征转置。
下面我们可以看到仅一层神经网络的激活图集(请记住,这些分类模型可以有六个或更多层)。它显示了在该层,网络在做图像分类时学到的一般视觉概念。这张图集第一眼看上去气势如虹——感觉很多东西在一起涌过来!这种多样性反映了模型所演化出来的各种视觉抽象和概念。

总览多层(mixed4c)Inceptionv1 网络中其中一层的的激活图集。它大约是整个网络的一半。

在这个细节中,我们可以看到不同类型的叶子和植物的探测器

在这里,我们可以看到不同的水,湖泊和沙洲探测器。

在这里,我们看到不同类型的建筑物和桥梁。
正如我们前面提到的,该网络中还有更多层。让我们看一下这个层之前的层,并深入网络中探索视觉概念是如何变得更加细化的(每个层在前一层的激活顶部构建其激活)。

在前面的一层——mixed4a 中,有一个模糊的「哺乳动物」区域。

通过网络的下一层,mixed4b,动物和人类已被分离开,中间出现了一些水果和食物。

通过层 mixed4c,这些概念被进一步细化并区分为小「半岛」。
在这里,我们已经看到了从一层发展到另一层的全局构架,但每个概念在层的发展过程中也变得更加具体和复杂。如果我们聚焦于有助于特定分类的三层区域,比如「白菜」,我们可以清楚地看到这一点。

左图:与其他图层相比,这个早期图层发特征非常不突出。中心:在中间层,图像完全与叶子类似,但它们可以是任何类型的植物。右图:在最后一层,图像非常明显像卷心菜,它们的叶子弯曲成圆形球。
这里还有另一个值得注意的现象:当你从一层到另一层移动时,不仅概念被细化,还会出现旧概念组合之外的新概念。
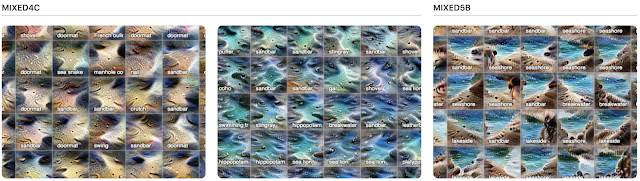
您可以看到,在 mixed4c(左和中)中,沙子和水是完全不同的概念,两者都有被分类为「沙洲」的明显属性。将其与后一层(右),mixed5b 进行对比,以上两种概念似乎被融合为了一个激活图。
除了放大特定图层整个激活图集的某些区域外,我们还可以在 ImageNet 中仅为 1000 个类中的一类创建特定图层的图集。下面将展示网络分类任务中的常用概念和探测器,例如「红狐狸」。

这里,我们可以更清楚地看到网络正在用什么标准来分类「红狐狸」。他们有尖尖的耳朵,被红色的皮毛包围的白色嘴鼻,以及繁茂树木或雪域的背景。

这里,我们可以看到「瓦屋顶」探测器的许多不同尺度和角度。

对于「野山羊」,我们看到了角和棕色皮毛的探测器,还有我们可能会发现这些动物的环境,如岩石山坡。

像瓦片屋顶的探测器一样,「朝鲜蓟」也有许多不同大小的探测器,用于探测朝鲜蓟的纹理,但我们也有一些紫色的花探测器,它们可能是检测朝鲜蓟植物的花朵。
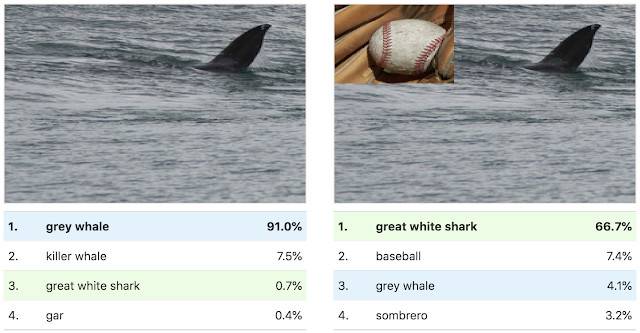
这些图集不仅揭示了模型中细微的视觉抽象概念,而且还揭示了高层次的误解。例如,通过查看「大白鲨」的激活图集,我们可以看到水和三角形的鳍(正如预期的那样),但我们也会看到看起来像棒球的东西。这暗示了这个研究模型所采用的捷径,它将红色棒球与大白鲨的张开嘴混合在一起。

我们可以用棒球图像的补丁来测试这一点,以将模型的特定图像的分类从「灰鲸」切换为「大白鲨」。
我们希望激活图集能成为一种使机器学习更易于理解且解释性更强的技术的有用工具。为了帮助开发者入门,我们还发布了部分 jupyter notebooks 代码(
https://github.com/tensorflow/lucid#
activation-atlas-notebooks),通过单击 colab(
https://colab.research.google.com/) 就能立即在浏览器中执行程序。它们创建的基础就是之前发布的工具包 Lucid,其中包括了许多其他可解释性可视化技术的代码。很期待各位能有所发现!
via:
https://ai.googleblog.com/2019/03/exploring-neural-networks.html雷锋网
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号