张宏江:AIGC将重塑所有产业,自动驾驶的未来已在眼前 |钛媒体T-EDGE 2023
发表时间: 2023-12-03 09:53

美国工程院外籍院士、北京智源人工智能研究院学术顾问委员会主任 张宏江
12月1日,距离ChatGPT正式上线正好整整一周年,钛媒体2023 T-EDGE全球创新大会再次邀请美国工程院外籍院士、北京智源人工智能研究院学术顾问委员会主任张宏江发表了关于AIGC的主题演讲。
而就在一年前的钛媒体2022T-EDGE上,张宏江第一时间向业内做出了《ChatGPT和AIGC:人工智能(Al)大模型发展和机遇》的主题演讲(详见钛媒体此前报道《关于ChatGPT爆火,张宏江这篇分享讲透了,大模型正成为AI浪潮的重要拐点》),引发了全行业的巨大关注。
在张宏江的带领下,智源研究院也屡次成为国际AI届最受关注的中国AI大模型研究机构,推出了“中国首个+世界最大”悟道大模型,也是在中国最早引领开展大模型研究的机构,成为这一领域的“黄埔军校”。
一年过去后,ChatGPT已经从最初的行业爆火,演变成了全社会爆火,而张宏江一年前的前瞻性判断,也早已在这一年得到了验证。今年12月1日,张宏江在钛媒体2023T-EDGE的加州分会场,发表了《AI 大模型驱动产业新范式》的演讲,进一步向我们讲述了AIGC接下来可能对各大产业的影响。
张宏江表示,ChatGPT是人类第三波 AI 浪潮的“分水岭”,迎来了“人工智能的 iPhone 时刻”。随着GPT-3.5、GPT-4等技术迭代,人类首次迎来一个能够精确理解语言逻辑的AI系统。
“如今的OpenAI,不只是一家纯粹的 AI 技术公司,而且还是一家 AI 平台公司。”张宏江在钛媒体2023T-EDGE上表示。
张宏江还在演讲中提到,“奇点”已经到来。AI 大模型作为基础平台,将会系统性推动所有产业进入新范式,成为下一个时代的“超级入口”,重写所有软件应用和产业,提升每个领域的生产力。同时,没有Al大模型的平台公司不再会是平台公司,新的产品、商业模式、盈利模式和创业机会也将到来。此外,利用GPT Copilot等技术作为未来的组织形式,公司效率极大提升,组织形式也将发生根本变化。
“大模型将重塑所有的产业,提升所有领域的生产力,并在不断改进和自主化现有的模型下,有望改变整个产业形态。”张宏江强调,未来1.5年-2年,人类或将可以看到大规模商业落地曙光。
当然,张宏江也坦言,大模型“幻觉”是目前比较重要的问题之一。尽管最新GPT-4在“幻觉”方面有了很大改善,相较ChatGPT提升40%,但“幻觉”率依然能达到10%-14%左右。所以,未来企业和开发者需要持续改善大模型技术能力,从而推动其在产业场景中真正落地。
“我想强调的是,我们不要觉得今年我们有了一个大模型,在某些应用场景里已经做得很不错了,从而忽略我们需要在通用大模型能力上的持续投入、持续改善和持续开发。否则,也许再过6个月、12个月,很多依赖大模型的应用将会因为无法达到用户的期望值从而被用户放弃。”张宏江表示,所有的软件公司都必须拥抱大模型,包括软件工具、应用服务等类型企业,都需要启用大模型重写软件。
展望未来,张宏江引述OpenAI的一项研究表示,80%美国人的工作都将受到 AI 技术影响,尤其是音频生成、图像生成等创造力的工作也将会被 AI 取代,这意味着高工资的“白领”群体受影响会更大。同时,AI 超过了85%或90%的人类考生水平,从而将让法学、医学等专业领域发展受到 AI 影响。
“大模型一定会对工作、人类未来产生影响。”张宏江提到,过去60年,人们经历了“信息”、“智能”系统两个时代,而未来人们还将同时拥有感知、理解、推理和自主驱动能力。AI 大模型不仅会替代“白领”工作,而且会驱动机器人、自动驾驶等领域的技术能力和体验能力的提升。
“未来,人们将迎来‘自主智能’的世界。”张宏江在结尾表示。
12月1日-3日,2023T-EDGE大会以「新视野 新链接」为主题,邀请了近百位来自不同国家,不同领域的国际创新领袖分享嘉宾,设置了四十余场现场讨论,从新一轮全球AI革命浪潮、产业链重塑、新一轮企业再全球化浪潮、全球化下的产业创新升级和投资新趋势等维度,共同回顾过去一年的洞察与发展,展望未来的创新趋势与经济新格局。
各位钛媒体朋友们,大家早上好。非常高兴参加2023年钛媒体T-EDGE全球创新大会。
我今天想跟大家分享一下,大模型如何驱动产业的新的范式,如何改变整个人工智能(AI)产业链。
我今天的讲座分成三个部分:
第一,我很快地回顾一下GPT所带来的大模型热潮,跟大家分享一下我在这背后的观察与思考;
第二,我会花更多的时间,在大模型如何驱动产业新范式,如何改变今天的 AI 产业,如何为所有应用带来新的开发模式;
最后,和大家分享一下我对于大模型技术的展望,尤其是大模型将怎么改变技术发展趋势和人们的生活。
首先我们回顾一下,近70年前发展到现在,AI 技术共经历了三波浪潮。
在十五年前,我们进入了以深度学习为代表的第三波 AI 浪潮,发展至三年前,无论是企业应用还是算法,其实都已经到了一个瓶颈,尤其在产业方面,三年前就看到了投资 AI 技术的比例到达低点。
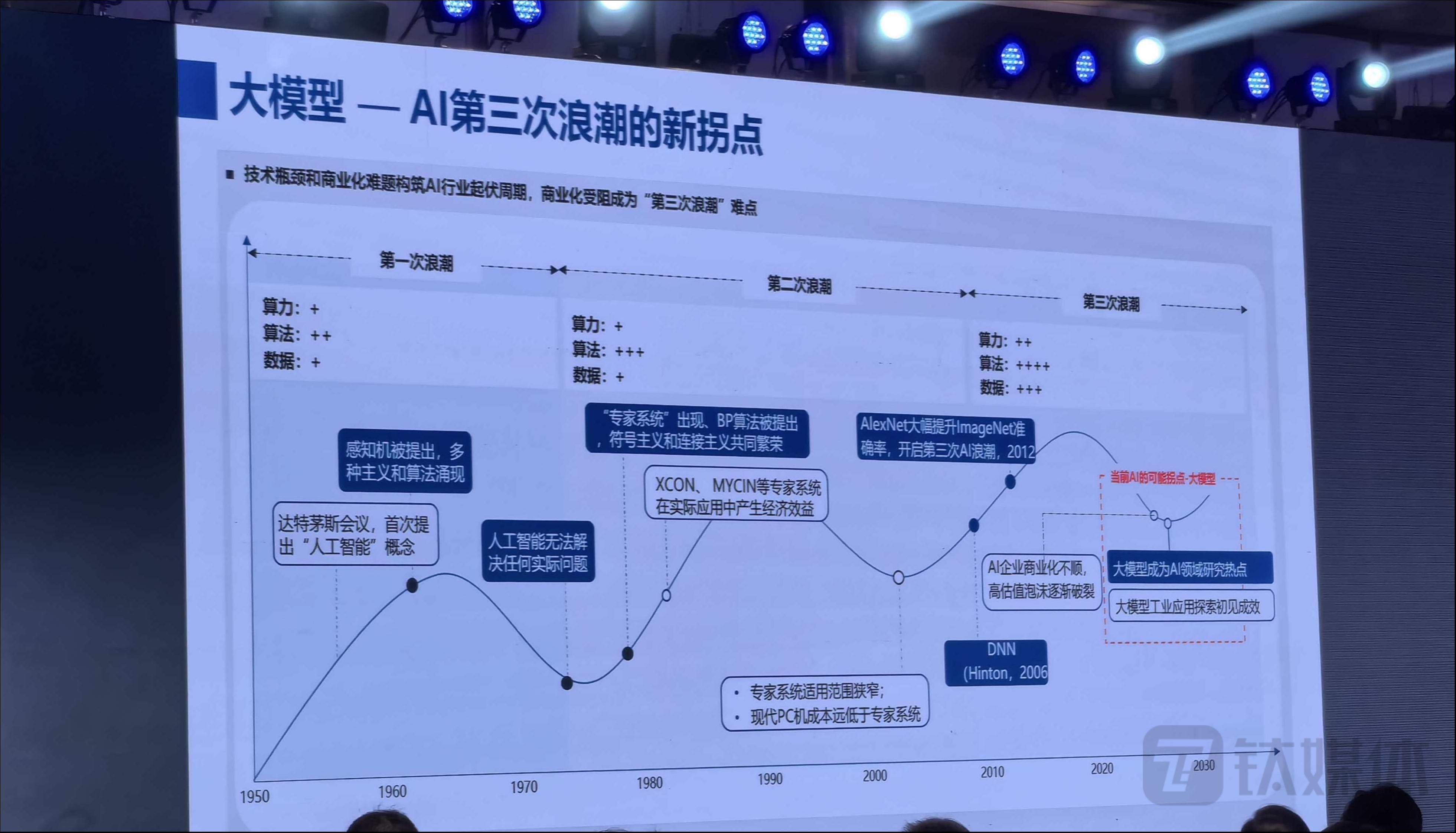
这页PPT其实是我三年前做的。当时我们看到Transformer所带来的一系列新的 AI 算法、AI 架构,尤其是GPT3.0大模型所引发的新技术进步。因此,当时,我们认为,大模型会成为 AI 第三次浪潮的一个新拐点。
如今,我们看到ChatGPT于2022年底发布后,风靡全球,真正成为这一波 AI 浪潮的分水岭,迎来了“人工智能的 iPhone 时刻”。
如果我们回忆一下移动互联网几十年的发展。虽然从2002年之前(20世纪90年代)就开始研发智能手机,但真正进入广泛应用,进入真正意义上的移动互联网时代,实际上是以乔布斯在2007年发布第一代iPhone为标志事件。再往前看类似的就是PC互联网时代,网景浏览器的诞生,我想在座的很多朋友可能那个时候还没出生。
iPhone的出现,标志着移动互联网的普及和快速发展。而今天ChatGPT的出现,正是新一轮 AI 快速发展的新拐点。
从数据来看,ChatGPT发布五天之后,用户达到100万,两个月内月活跃用户达到1亿人。今天,ChatGPT平台也有几亿人活跃用户,成为历史上发展最快的消费级应用。
无论是iPhone、抖音,这些明星产品,用户量破亿都需要一段长期过程,而ChatGPT只用了两个月。一方面,说明了技术发展的加速,另一方面也标志着人类技术发展进入了一个非常重要的拐点。
那么,为什么GPT所代表的新一轮大模型进步如此之重要?GPT-4或ChatGPT是否标志着AGI(通用人工智能)时代来临了?
在这里,我想借助一份微软研究院发表的题为“AGI(通用人工智能)的火花:GPT-4的早期实验”系统性研究论文,来看几个例子,说明大模型的魔力,来说明今天以大模型为标志打的AGI 技术已经在许多方面接近人的智能,或者说是跟人一样的智能能力。那么,如何定义人工智能?
该研究提到,人的 IQ 智力测试主要包括六个方面:推理、规划、解决问题、抽象的思考、理解复杂的想法以及多模态与跨学科计算机中组合学习能力,这是人类智能的六大特点。而该团队设计了一系列问题来考GPT-4,包括视觉、编码、数学等问题,最终结论是:GPT-4是具有通用智能能力的。

有两个点,让我们对这一通用智能能力更加坚定。
首先,利用GPT-4,已经可以调用非常复杂的工具。人最独特的就是具有调用工具的能力,而GPT-4恰恰做到了这一点,
譬如,这周我打算和朋友Luke一起到Contoso餐厅约一次晚餐,GPT接到这个指令之后调用日历、Email应用给Luke,分别发送信息问她哪天有空并自动反馈给日历,最终确定了周三晚上6点在Contoso餐厅见面,一切都通过GPT模型自动化完成。
第二个例子是,OpenAI的总裁在TED大会进行了一个现场演示,打算大会结束后吃一顿美味大餐,并让GPT给他一些菜品推荐等建议。GPT-4 不仅给了他推荐出一些意大利风格的西餐,而且调用了DALL·E工具,把这些菜画出来。
另外,我们知道,在 AI 领域,自然语言处理和理解是一个“圣杯”。人类智能的一个核心区别在于,人有语言,可以写文字,能够通过语言描述自己的体验、经历和虚拟一些故事。
判断AI智能水平的经典图灵测试,本质上是人机对话测试——即当人们和机器多次对话时,如果无法区别是人还是机器在进行回答,就意味着通过图灵测试,具有人类智能。而ChatGPT,GPT-4恰恰通过了图灵测试,意味着AGI具备了人的智能能力。
这种突破意味着,从古至今,世界首次拥有一个能够精确理解人类语言逻辑的AI系统。这个系统不仅仅是简单的应用学习,而是建立在语义理解的基础上,具备推理和创造能力的 AI 系统。更可怕的是,随着GPT-4模型的性能升级,自然语言逻辑能力亦随之增强,意味着 AI 系统更具备通用 AI 能力。
那么,这是否也意味着“奇点”已经来临?
2016年,DeepMind阿尔法狗(AlphaGo)让所有人都很吃惊,利用 AI 技术AlphaGo打败了韩国围棋冠军李世石。从某种意义上,AI 系统具备了一些所谓的“上帝视角”。AlphaGo的下一代系统AlphaZero不再从人类棋谱里面训练,而是利用棋子布局和规则等数据与强化学习结合,从而赢得目标,其能力超越了人类,也就具备了“上帝视角”。
当人类看到 GPT 学习能力如此之强、演化速度如此之快,学习能力超越了人类的时刻,确实振奋于奇点已来。
谈完对GPT-4或大模型技术观察和思考之后,下面来看一下大模型如何改变智能产业,或者是几乎所有的产业。
首先我说一下大模型。
如果只是把大模型或未来多模态模型作为一种技术(工具),其实是低估了这次技术突破。而实际上,大模型作为 AI 基础平台,将会系统性推动整个产业进入新的范式。
第一、它(大模型)决定了下一个超级入口。GPT不仅是 AI 模型,而且是超级计算机,或是一个超级系统,重构了用户和用户之间的交互、软件的执行以及计算本身。模型就是产品,人机交互已经变得如此之容易。如果加上多模态的数据,如图像或视频,就能提升人与机器之间的多媒介交互能力。
第二、AI 模型将重写所有软件应用。今天大模型已经具备了这样一个能力,未来在软件中,大模型将会无处不在。但凡是需要智力的地方,大模型都能够发挥它的作用,从而将重塑所有的产业,提升所有领域的生产力,并在不断改进和自主化现有的模型下,有望改变整个产业的形态。
第三、没有AI大模型的平台公司不再会是平台公司。这意味着,未来将会有新的平台、新的产品、新的赢家/输家,也意味着有新的商业模型和创业机会,而且初创企业、企业生态系统也会因此重写,新的生态会形成。
第四,谈到效率的改善,一旦有了 AI 大模型,公司效率极大提升,组织形式将发生根本变化。未来,公司不仅有专业人员,还有Copilot(副驾驶),当大模型可以调用工具的时候,Copilot和Copilot之间彼此互相交互,人做事的效率会有很大提高,最终Copilot慢慢形成一种Auto-pilot,使得公司的组织形式不再是简单把计算机当做工具,而是变成由Copilot主导的未来公司的组织形式,从而对于产业带来更多变化。
其次,下面再往里面看。
首先,大模型将是 AI 应用的新的平台,会带来新生态。
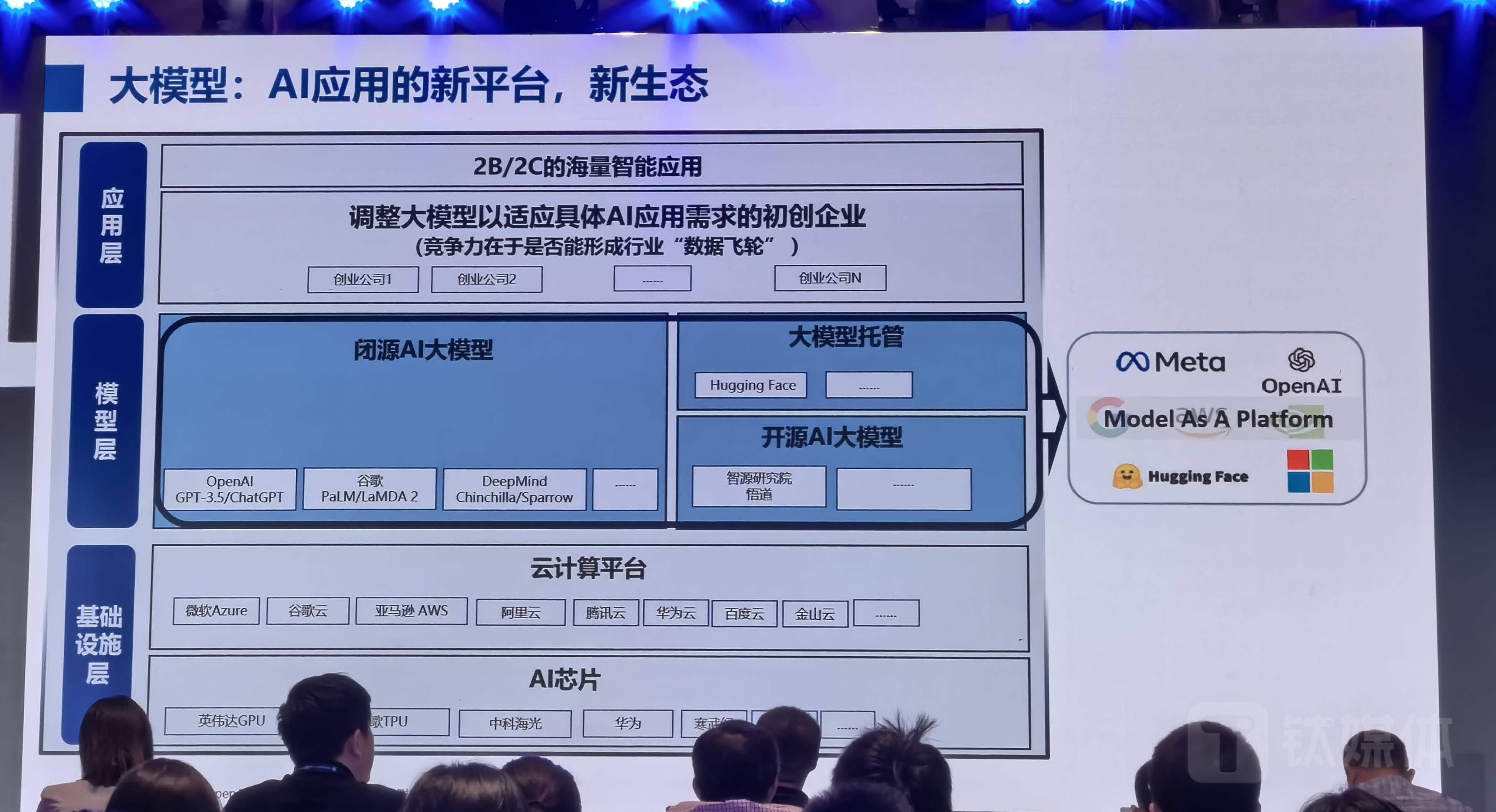
大模型产业链中,最基础、最底层的还是 AI 芯片,无论英伟达的GPU(图形处理器)芯片,还是其他的GPU,在此之上又一个云计算平台大模型。而在这个平台上,无论是闭源还是开源大模型,最后都会落地到场景,形成更垂直的运用。
这里我列了几家美国公司例子。比如,OpenAI等公司目前都具备了大模型能力,也把大模型能力往外输出。今年看,模型即服务(MaaS,Model as a Service),而未来,模型或将成为一种新的发展趋势,从而将成为这些公司的市场竞争力。
最近举行的OpenAI首届开发者日上,奥特曼(Sam Altman)公布了一系列新的模型、功能和模式。很明显看到,GPT-4不仅是一个模型,而且还是一个新的平台,和GPT-4对话就可以生成新的工具,从大模型驱动变成了大模型产生各种软件开发模式,从而可能将改变整个 AI 生态。
因此,如今的OpenAI,不只是一家纯粹的 AI 技术公司,而且还是一家 AI 平台公司。
我认为,所有的软件公司都必须拥抱大模型,必须得启用大模型来重写软件。不止是大公司,甚至小到做软件工具、应用服务等类型的小企业,都需要拥抱大模型。如今,大家都在焦虑看着,下一步OpenAI还会推出什么样的应用,从而影响人类发展方向。这正是大模型作为一个新的平台的力量所在。
第二个我想分享的是,大模型作为基础平台,会系统性推动AI产业进入新范式。
实际上,过去15年深度学习技术发展过程中,所有应用场景开发的模型都是小模型,比如做安防应用开发人脸识别专属模型,做股票分析 AI 系统会做小垂直模型。那么如今,有了大模型之后,我们进入到从此前的专用模型,到通用模型新的 AI 时代,你不再需要为一个新的 App 开发一个模型,而是要用通用大模型经过微调、对齐,就能满足你的需要,从而大大提高软件开发能力。同时,未来,模型编程也会逐步变成自动化,开发成本大大降低。
我想给大家举一个例子。最近我和以前一个微软的同事聊起来,过去几个月他看到 ChatGPT 模型的出现非常激动,并且基于 GPT模型,只用了三个人做了一系列 App产品。。
我当时问他,你们三个人完成的这么一系列App,如果没有GPT的帮助,需要多少软件工程师才能完成这么大的开放量?他们的回答是120个人。
我认为这个估算可信性很高。他是一位已经在软件工程领域耕耘了二十多年的专业人士,从软件工程师做到软件架构师,再成为软件开发管理者。从管几个人到几十个人,到几百个人到几千人,对软件开发非常熟悉
从前需要120人次的软件研发工作,现在只需三个人加上GPT就能够完成。有效利用 GPT,可以设计出非常优秀的架构、用户界面和写作产品。
因此,大模型不止带来了新的智能应用开发模式,同时也会大大提升开发效率。
第三点我想讲的是,AIGC(生成式人工智能)技术演化推动孪生、编辑、创作三大前沿能力发展。
我们认为,大模型已经解决了数字人、虚拟创作等技术难题,下面的问题就是不断优化,使得它效率更好,整个内容更加让我们满意,和人的价值观对齐更好。我们认为,这些都已经算是相当成熟的技术被应用于市场上,比如文生图、文字内容创造、写代码、音频生成等。
今年我们可以看到,很多音频生成都开始用大模型来做,比如赵本山说英文、让外国人说中文等。这些音频生成、语言翻译、图像生成技术都很成熟,因为过去大模型技术本身不断改进,使得这些应用已经进入“成熟期”。
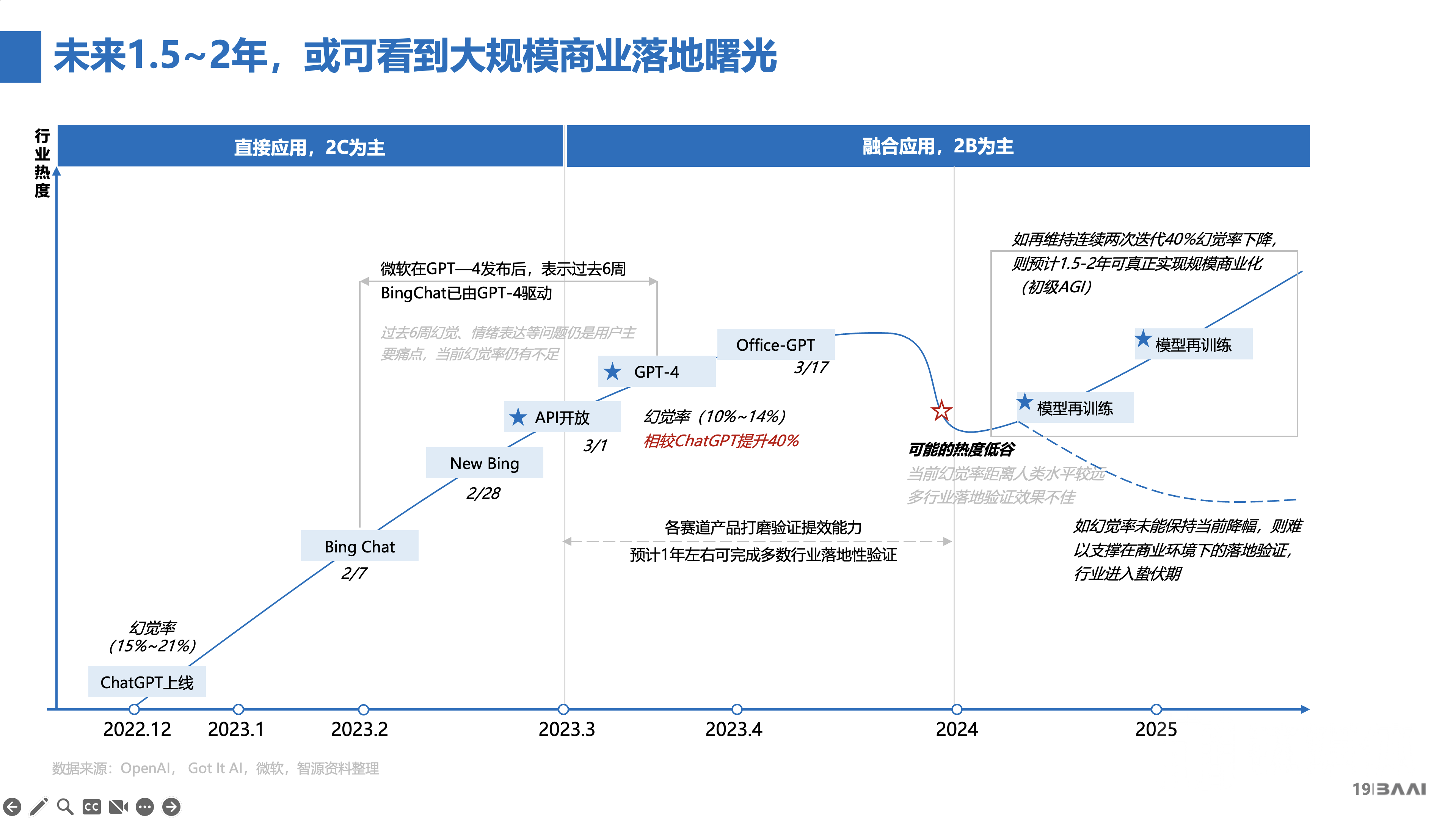
但是,大模型技术还有一个很重要的——“幻觉”率的问题。无论是GPT-3.5还是GPT-4,幻觉率大概能有15%-20%,当然GPT-4有了很大改善(大概5%的改善),相较ChatGPT提升40%,但幻觉率依然有10%-14%左右,这还要加上其他性能等。
所以,我们需要持续改善大模型技术能力,从而在大模型加持下,才能将预期的应用真正的产业落地,真正的达到或超越用户的期望值。如果我们不能够将大模型技术持续改善,就可能出现以前技术瓶颈时期所经历的同样问题。换句话说,就是技术虽然有了很大的突破,但真正落地的时候,仍需要不断解决客户实际而具体的问题,当 AI 技术从高点落地而不能的时候,会使产业进入一个“萧条期”。只有当我们的模型不断改善,才能够达到或超越用户的期望值。
我想强调的是,我们不要觉得今年我们有了一个大模型,在某些应用场景里已经做得很不错了,从而忽略我们需要在通用大模型能力上的持续投入、持续改善和持续开发。否则,也许再过6个月、12个月,很多依赖大模型的应用将会因为无法达到用户的期望值从而被用户放弃。
第四、下面来看一下利用大模型,哪些行业应用已经非常成熟了。大模型将催生哪些新物种?
实际上,比如内容文案、内容创作、会议记录、客服、代码生成等,过去5年、10年间聊天机器人产品一直无法过关,而今天有了大模型、自然语言技术提升,这些行业已经在快速成熟。在过去移动互联网市场突飞猛进过程中,创造了比PC互联网大很多的机会空间,催生了一系列原生应用,例如短视频、滴滴打车、抖音,这些 App 是在PC互联网无法实现的产品。
所以,未来我们能不能够找到大模型原生应用,这是推广大模型应用的时候需要解决的一个核心问题,比如可以考虑人性化交互、图像效果升级改变等,从而催生 AI 原生应用。
第五点,AI 大模型将带来新科学的新范式。
作为一直从事 AI 研究的从业者,我希望未来 AI 大模型能够带来科学研究的新范式。今年我们知道,AI for science(科学智能)领域已经是大家的公示,当一系列新技术的出现,比如DeepMind的 AlphaFold 2预测了所有蛋白质结构。因此,未来我们不仅可看到结构的预测、药品的设计、材料的设计,而且还会看到 AI 将会成为人类非常好的研究助理,甚至最终成为很好的研究者,让 AI 帮助我们研究、设计新的 AI 系统。
这就是我们看到大模型带来的新科学的新范式。除了AlphaFold2之外,更深层次说,大模型可以推动生命科学的发展,比如后续一系列可以期待的新的工具、新的应用,预测大分子结构,以及未来一系列新的生物分子结构的预测。所以,这就是未来我们可以预见到的大模型在科学方面的新应用。
所以,这就是未来我们可以预见到的大模型在科学方面的新应用。
刚才,我讲到大模型对于产业的应用,以及大模型的威力所在。那么最后,我们展望一下未来。
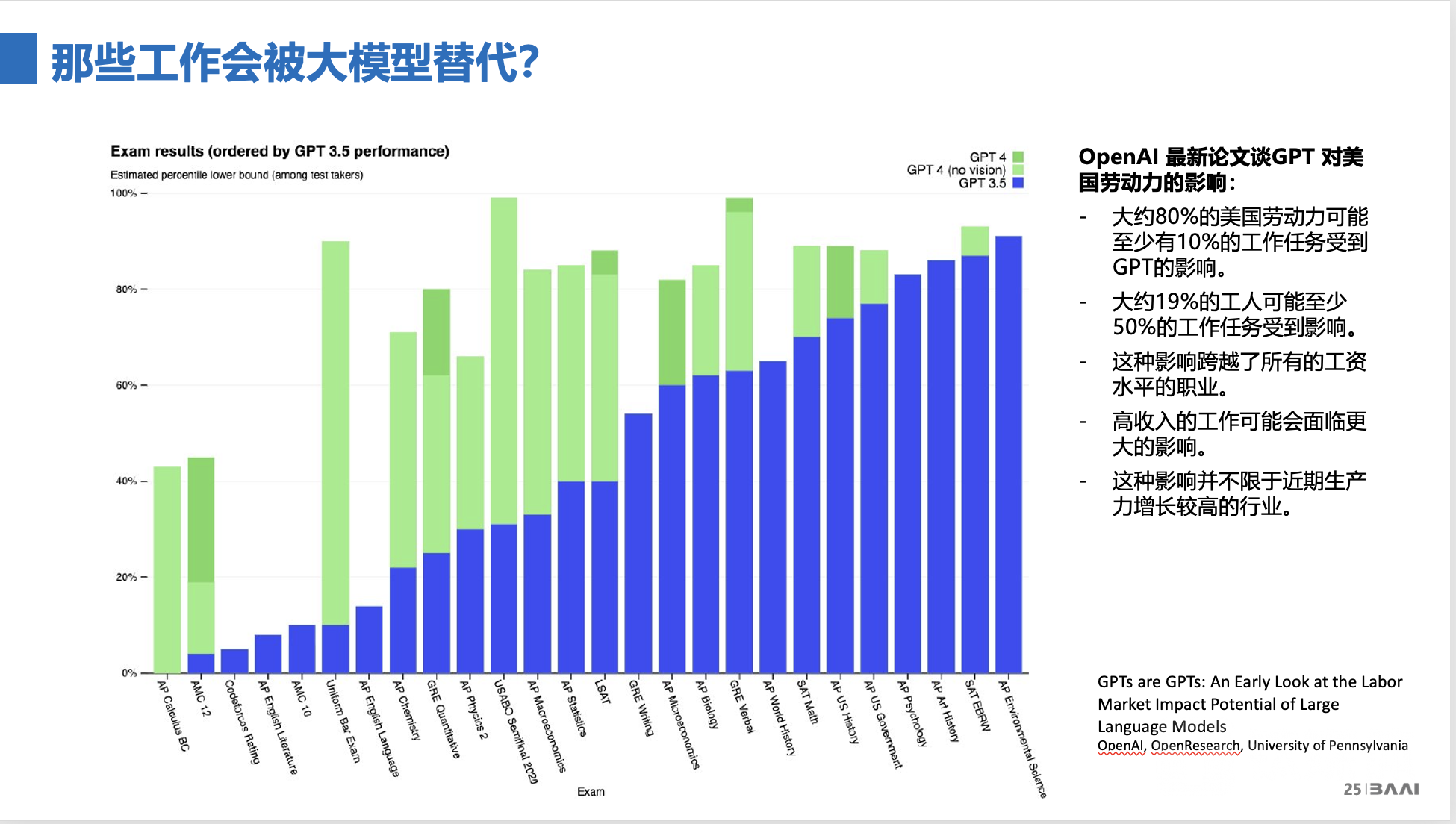
AI 到底能影响多少人的工作?今年3月,OpenAI和美国宾夕法尼亚大学的相关研究人员联合发表了一篇论文,分析了 GPT 对美国劳动力的影响。
结论是,大约80%的美国劳动力,至少他们的工作中间有10%会受到影响;此外有约19%的人,其工作任务受影响的比例超过50%。与此同时,这种影响跨越了所有的工资范围,不止是低工资人群,而且一年赚两、三万美金的高工资人群受 AI 影响会更大,那意味着“白领”群体的影响会更大。
具体有哪些领域会受到影响?我用这张GPT-4和GPT3.5在美国标准考试的结果图片来解释。你可以看到,大学、研究生、法学院、医学院入学考试中,GPT-3.5都可以通过这种标准测试,但分数不是那么高;而如今用GPT-4考这类测试,大部分情况下能超过85%的参考人,某些领域正确率甚至达到90%,也就是说,AI 超过了85%或90%的人类考生,即超过了人类的平均数。
那么可想而知,在这些标准考试所代表的这些工作领域中,绝大多数工作一定会被大模型所取代,至少80%吧,这将会让人们对未来更加焦虑。所以,大模型一定会对工作、人类未来产生影响。
我想分享一下奥特曼(Sam Altman)团队的观点,第一,未来大模型不仅是语言模型,更是多模态模型,会打开新的局面;第二,未来 AI 对产业、对于工作的影响深远,AI 会代替未来许多工作。相对于此前认知的低技能工作开始替代,如今我们却能看到,内容生成这种创造性工作也会 AI 所取代,原来希望 AI 技术可以扫地、做做饭、洗衣服、叠衣服、抢垃圾,结果却最早替代绘画、写作、作曲等创造性工作。
那么这是否意味着,未来 AI 技术不能替代“体力活”?答案是否定的。下面,我们先看两个例子:波士顿动力的机器人,以及谷歌用大模型驱动的未来机器人手臂。
首先是没有大模型加持下的机器人形态。
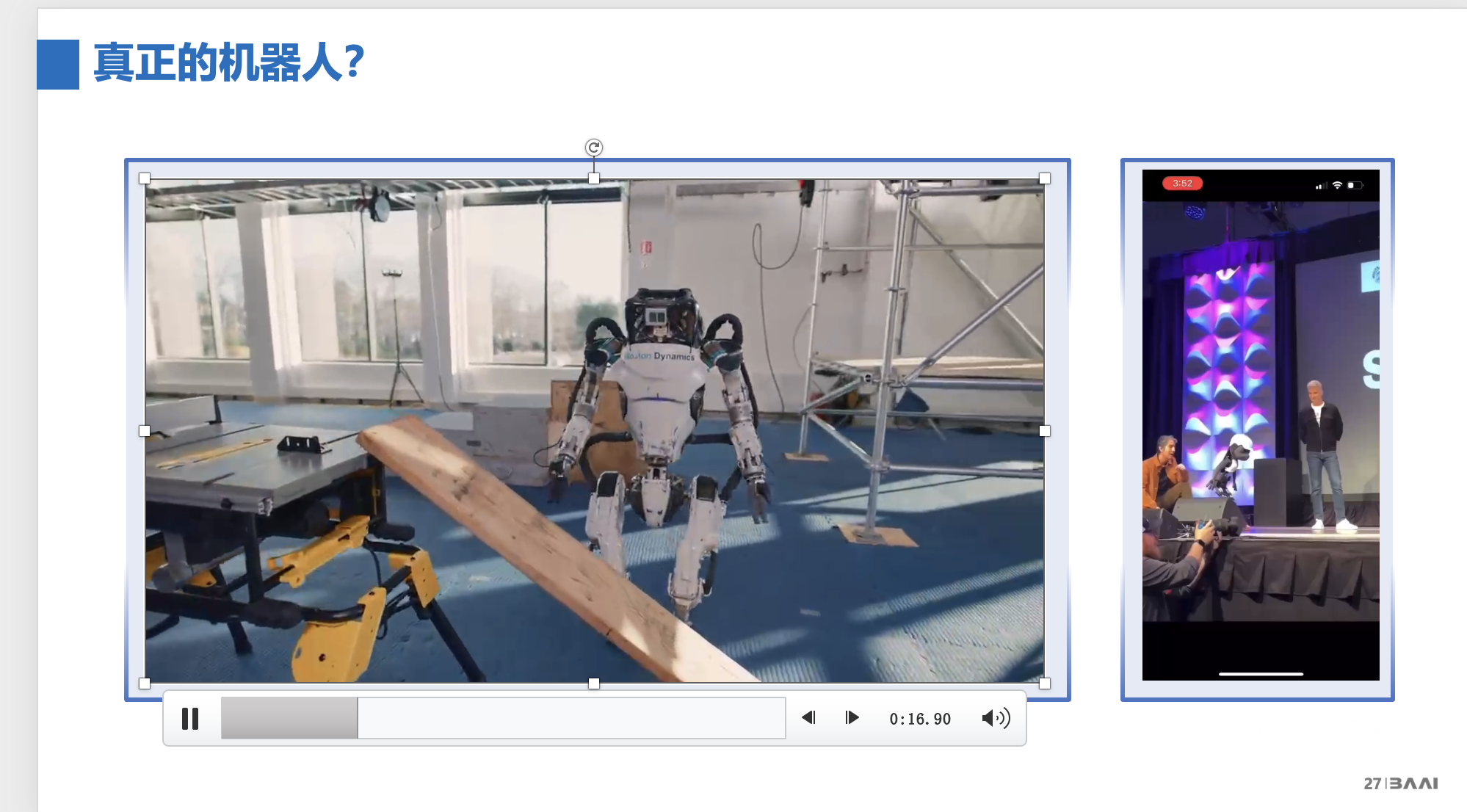
左边这个波士顿动力(Boston Dynamics)机器人视频中,没有大模型技术,机器人的所有动作都是实现编程好的,并不具备识别或自我规划的能力;而右边的机器人摔倒之后只是有一个智能的起立,随后需要人主动分开才能很好坐上肩膀中。
我想跟大家说,这两个机器人很棒,但他们没有自我规划的能力,不能识别这个场景所做事情。这就是今天没有大模型驱动的机器人的状态。
其次,谈到未来的机器人技术能力,最近谷歌公布的机器人模型RT-2视频,结合了基于GPT模型的新的工作能力和规划能力,这属于新的技术创新。
此前,机器人只是能够听从人们的单一指令,如输入把可乐瓶扔掉。而今天,基于大模型能力,新的机器人可以把文字命令转化成一系列的动作,其不仅能听懂复杂指令,而且还能把指令进行思考,并做自我规划能力。比如人指令机器人抓住桌面上“已经灭绝的动物”,随后机器人就思考哪些动物属于已经灭绝的动物,最后根据规划把恐龙抓了出来。
这就是多模态大模型与机器人之间的结合。未来的机器人不仅识别周围环境,还能自我识别目标,并利用大模型推理,最终识别目标。换句话说,今天人类拥有的机器人已经有“理解”的能力,而这个能力来源于大模型。
再次,我们下面看智源研究院团队作的一项研究工作。
我们培训了一个机械手臂类型的机器人,使其能够开门。实验过程中,在没有大模型的情况下,机械手只能执行被教给它的特定动作,如开抽屉门或拿起锅盖,所以当机械手面临微波炉门时,它遇到了新的场景和问题:它无法用门把手打开微波炉的门;但由于拥有多模态大模型,机械手能够根据微波炉手册的描述,重新规划行为,按下底部按钮来打开微波炉。
需要指出的是,这个过程中,机械手并没有被人告知要按按钮,而是通过大模型进行推理和思考得出解决方案。这表明,未来的机器人将通过大模型进行少量训练后,能够做出以前未经过训练的动作,而这些知识都来自于大模型。
所以,从另一个角度来看,大模型是机器人行业的一个“分水岭”,当机器人拥有大模型,尤其是多模态大模型的能力,从而可以思考、推理、规划更多的工作任务,对此有了事物的更多可能性。

最后我们谈谈,如果机器人利用大模型能做到更多的工作能力,未来自动驾驶是否也能具备更多自我规划和推理能力?
我们认为,随着大模型的加持,自动驾驶行业也将会被“重写”。
实际上,人在开车的时候,并非所有的场景都已经在考驾照的老师指导下学习过,但人们可以在各地正常按交规驾驶。那么看今天的自动驾驶,只是能够在一个地点需要数据训练之后才能开车,比如北京的亦庄、上海浦东等地。我认为,未来基于GPT大模型技术,这件(每个新城市都需要三个月的重新训练)事情将不需要再做了,未来的自动驾驶应该会被大模型“重写”,基于大模型的自动驾驶技术具备自我推理、自我规划等能力,从而今天所说的新的极端情况(corner case)、新的路况不再成为自动驾驶系统在一个地方落地的障碍。
那么可以想象,在虚拟世界中模拟自动驾驶的过程,可以解决很多数据量不够等问题,这事一个非常有意义的研究,这也是智源研究院推动的一个新的研究。
总结来说,在大模型技术加持下,未来的机器人将从通用走向多智能体agent下的“行动智能”(自主智能)时代。
此次演讲的最后,我们回顾一下整个IT技术发展的60年,主要分以下三个阶段。
第一代是“信息”系统时代。无论是互联网,还是IT系统,都是在获取信息、收集信息,传输和处理信息;
第二代是“智能”系统时代。我们不再只是收集信息,而是将把信息变成智能,从而帮助我们形成智能系统;
未来我们将会进入第三个时代:行动智能时代。当你能够感知世界、理解世界,推理世界之后,未来世界还将拥有自主的驱动行动能力。当然,这也是机器人的未来、自动驾驶的未来。
有了这些之后,AI 不止会替代很多人类的所谓“白领”工作,未来整个人类所从事的行为,都会被 AI 软件或未来机器人所取代,这就是未来的“自主智能”世界。谢谢大家。(本文独家首发钛媒体App)
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号