Meta推出最强开源模型,引领科技新潮流
发表时间: 2024-07-24 12:57
北京时间7月24日,Facebook母公司Meta Platforms Inc.发布了全新人工智能模型“Llama 3.1”,这是该公司目前为止推出的最强大开源模型,号称能够比肩最好的闭源模型。
与此同时,Meta的CEO马克·扎克伯格发表公开信,阐述了他为何支持AI开源。
扎克伯格称其为“艺术的起点”,表示Llama 3.1拥有大范围新的能力,包括改善推理以帮助处理复杂的数学问题或即时合成一整本书。
Meta公司在150多个涵盖多种语言的基准数据集上评估了性能,Llama 3.1模型在各个基准上皆有不错的表现。此外,还进行了广泛的人工评估,在真实场景中将Llama 3.1与竞争模型进行了比较。实验评估表明,Llama 3.1能够在一系列任务中与领先的基础模型相媲美,包括GPT-4、GPT-4o和Claude3.5Sonnet。

Llama 3.1 405B与其它模型多个基准的评估对比Meta官网
官方称,开发人员提高了模型对用户指令的响应能力、质量和详细指令遵循能力,同时确保高水平的安全性,使其能够跨功能扩展微调数据量。
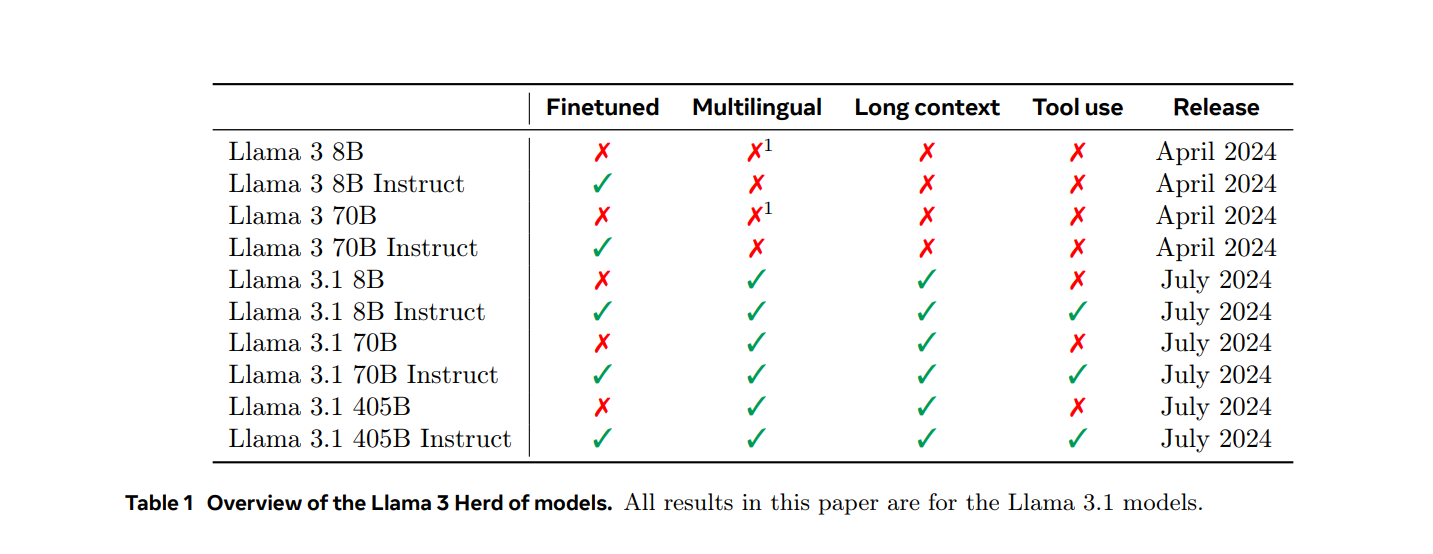
根据Meta发布信息,Llama 3.1模型包含4050亿个参数,是近年来参数规模最大的模型之一。这些模型支持多种语言,上下文长度显著增加,达到128K,使用最先进的工具,推理能力也更强。这使得我们的最新模型能够支持高级用例,例如长篇文本摘要、多语言对话代理和编码助手。
Llama 3.1模型对比Meta官网文件
作为Meta迄今为止最大的模型,Llama 3.1从16位(BF16)量化为8位(FP8)数字,有效降低了所需的计算要求并允许模型在单个服务器节点内运行,使用超过16000个H100 GPU进行训练,这是全球迄今为止性能最强大、参数规模最大的开源模型。
该模型主要用于为Meta内部和外部开发人员的聊天机器人提供支持,具备广泛的新功能,包括改进的推理能力,帮助解决复杂的数学问题或瞬间综合整本书的文本。它还具有生成式AI功能,可以通过文本提示生成图像。
同时,扎克伯格发表公开信《Open Source AI Is the Path Forward》,阐述了“开源为何对开发者、对Meta和对世界都有好处”。
自ChatGPT爆火以来,将其开源的呼声未曾断绝。可就在ChatGPT2发布之后,OpenAI选择了闭源发展。阿里云、智谱和清华EKG、百川智能等,选择了开源,华为则出于数据隐私和商业收益考虑,盘古大模型就选择了闭源,在这场全球大模型军备赛中,有关开源发展和闭源深耕的争论不止不休。
扎克伯格公开信中提出,Llama需要发展成为一个完整的生态系统,包括工具、效率提高、芯片优化和其他集成,这是仅依靠Meta自己使用做不到的;Llama有信心在高度竞争中保持优势,而成为行业标准的道路是一代又一代地保持竞争力、高效和开放;最后,出售AI模型访问权限不是公司的商业模式。这意味着公开发布Llama不会削弱企业的收入、可持续性或投资研究的能力。
扎克伯格还指出,开源将确保全世界更多的人能够享受AI带来的好处和机会,权力不会集中在少数公司手中,并且该技术可以更均匀、更安全地应用于整个社会。
扎克伯格认为最好的策略是建立一个强大的开放生态系统,使得行业龙头公司与政府和盟友密切合作,以确保他们能够最好地利用最新进展,并在长期内实现可持续的先发优势。
关于中国,他在文中提到,“有些人认为,美国必须采用闭源,以防止中国获得这些模型”,但“这是行不通的,只会让美国及其盟友处于不利地位”。
据彭博社报道,扎克伯格还补充说,认为美国在人工智能方面会领先中国数年也是不现实的。但他指出,即使是数月的小幅领先,也可以随着时间的推移“累积”,让美国占据明显优势。
本文系观察者网独家稿件,未经授权,不得转载。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号