如何利用资源队列对AnalyticDB PostgreSQL进行有效管理?
发表时间: 2021-05-19 10:40
AnalyticDB PostgreSQL版(简称ADB PG)是阿里云数据库团队基于PostgreSQL内核(简称PG)打造的一款云原生数据仓库产品。在数据实时交互式分析、HTAP、ETL、BI报表生成等业务场景,ADB PG都有着独特的技术优势,在金融、物流、泛互联网等行业都有广泛的应用,是传统数仓上云、去O去T、替换自建Greenplum的标杆云上数据仓库产品。
数据仓库产品是数据分析系统的重要组件之一,各类线上业务对数据仓库产品的稳定性、可用性具有很高的要求。缺乏有效的资源管理机制会导致数据库产品的稳定性下降,发生例如连接数打满OS限制、内存不足、进程卡死等问题,从而影响产品的可用性。
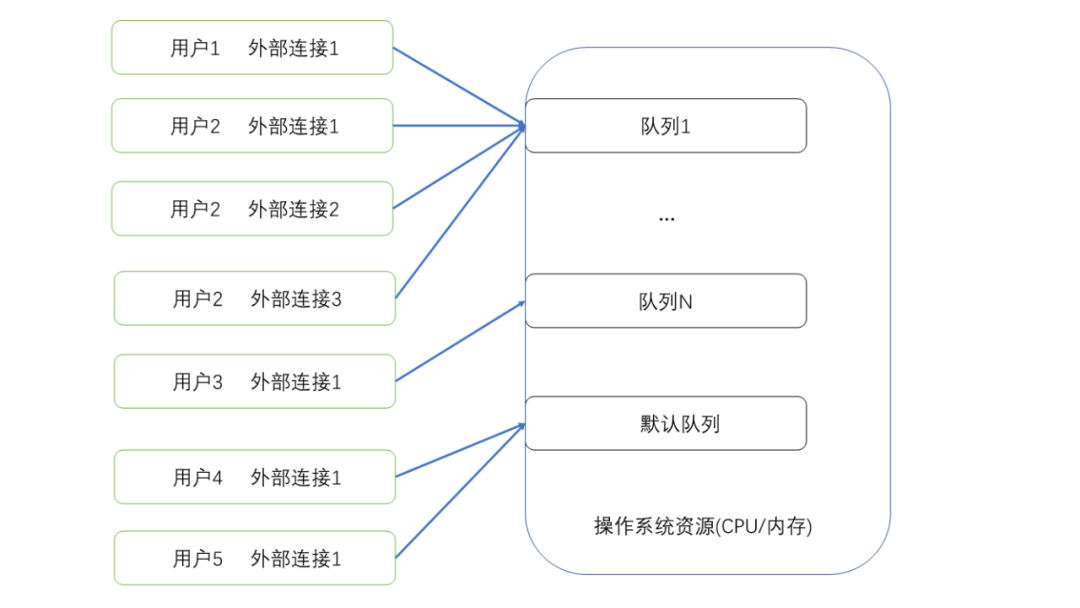
Resource Queue(资源队列)是ADB PG的一种资源管理方式,能够对数据库的CPU、内存等资源进行限制,对多租户资源限制、保障数据库稳定运行具有一定的作用。顾名思义,Resource Queue以队列形式对运行在数据库集群上的SQL进行资源管理。对于每个用户,他的所有连接只能归属于一个队列。而对于每个队列能够管理多个用户的连接。没有显示指定资源队列的用户,会归属于默认资源队列管理。通过限制每个队列的资源总量,我们可以达到限制某类业务或者某个用户使用的资源总量的目的。
我们以ADB PG某在线交易平台类客户A为例,介绍Resource Queue的使用。客户A基于ADB PG构建数据仓库,日常运行三类业务:以交易数据入库为代表的实时类业务;用于支撑决策分析的报表类业务;以及用于实时大屏展示的可视化类业务。我们根据三类业务的不同特点,按如下策略配置资源队列。
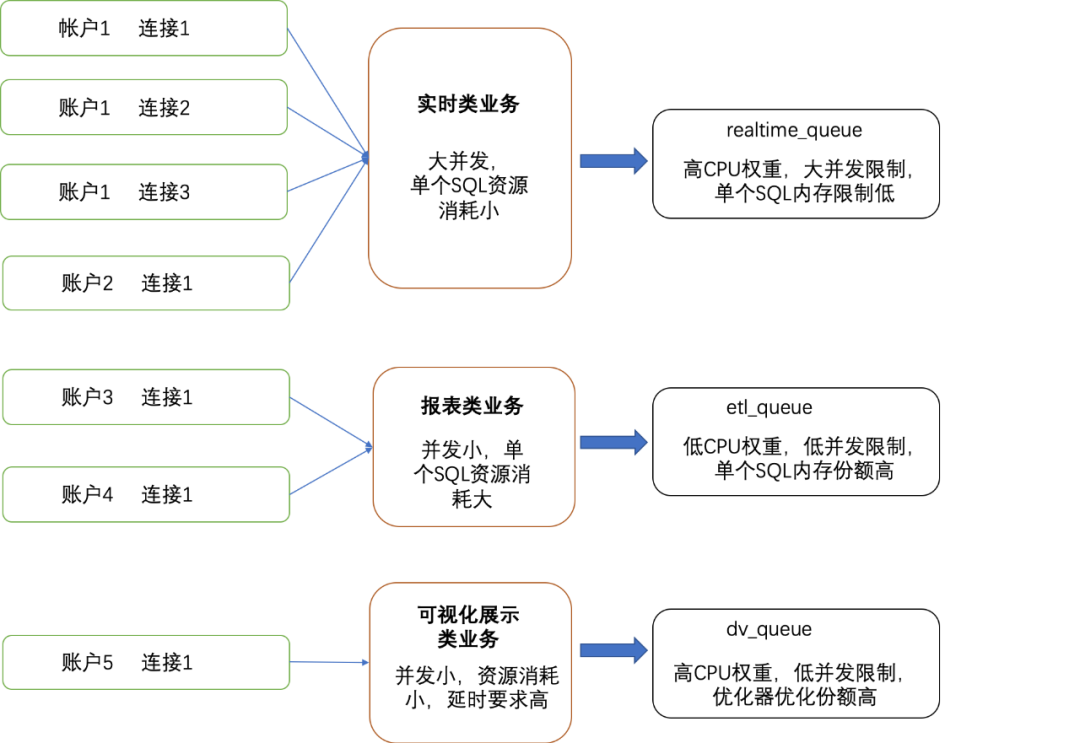
客户A的实时类业务的典型代表是,交易数据经Kafka->Flink->ADB PG链路实时写入ADB PG。这类业务的典型特点是,峰值并发比较大,单个SQL资源消耗小。在进行资源队列限制前,业务高峰期经常发生突然提高的并发查询打满数据库连接,造成高可用探活查询执行失败,引发实例不可用。对于这类业务我们将其关联到一个高CPU权重、大并发限制(安全阈值内)、单个SQL内存份额低的队列。既保证数据的快速入库,又防止流量洪峰造成系统不稳定。
客户A的另一类典型业务是报表类、ETL类业务,这类业务会在实时类业务的低峰期进行调度,生成报表以提供决策支持。这类业务涉及的数据量较大,消耗内存量和产生的临时文件量大。对于这类业务,我们将其关联到低CPU权重、低并发限制,但是内存份额高的队列,在满足业务需要的同时,控制内存使用上限;
除此之外,客户还基于ADB PG数据仓库支持数据的实时可视化展示,这类可视化方案往往具有非常稳定的并发,但是对查询的延时具有一定的要求。对于这类业务,我们将其资源队列设定为高CPU权重,低并发限制,以及宽泛的优化器查询计划消耗份额,最大程度为其生成良好的查询计划,以保证业务稳定。
接下来,本文会具体介绍Resource Queue的使用方式、状态监控,以及它的实现机制。
Resource Queue支持通过SQL配置,支持进行四种类型的资源限制:并发限制、CPU限制、内存限制和查询计划限制。用户可以通过SQL在数据库内定义多个资源队列,并设置每个资源队列的资源限制。在一个数据库中,每个资源队列可以关联一个或多个数据库用户,而每个数据库用户只能归属于单个资源队列。
另外,并不是所有提交到资源队列的SQL都会受到队列限制的限制,数据库只会限制SELECT、SELECT INTO、CREATE TABLE AS SELECT、DECLARE CURSOR、INSERT、UPDATE 和DELETE这些类型SQL的资源利用。另外,在执行EXPLAIN ANALYZE命令期跑的SQL也会被资源队列排除。
资源队列支持的资源限制配置如下:
配置名 | 配置说明 |
MEMORY_LIMIT | 队列中所有查询所使用的内存总量。 |
ACTIVE_STATEMENTS | 队列中允许同时运行的查询数。超出该设置值的查询需要排队等待执行。 |
PRIORITY | 队列的CPU使用优先级,可以设置为以下级别:LOW、MEDIUM、HIGH 和MAX。默认值为MEDIUM,优先级越高的队列会被分配越高的CPU份额。 |
MAX_COST | 查询计划消耗限制。 |
通过SQL语句定义一个新的资源队列:
CREATE RESOURCE QUEUE etl WITH (ACTIVE_STATEMENTS=3, MEMORY_LIMIT='1GB', PRIORITY=LOW, MAX_COST=-1.0);ACTIVE_STATEMENTS:
队列中允许同时运行的查询数,即队列中允许并发查询的最大并发值。数据库允许超出ACTIVE_STATEMENTS数目、但是少于数据库最大连接数MAX_CONNECTIONS数目的链接连接到数据库,但是这部分SQL连接并不会立刻开始运行,而是排队等待。
MAX_COST:
查询计划Cost限制。数据库优化器会为每个查询计算Cost,如果该Cost总量超过了资源队列所设定的的MAX_COST的值,该查询就会被拒绝。ADB PG的默认配置为0,即不受限制。
Memory Limit:
ADB PG可以通过设置statement_mem来决定每条SQL在每个Segment上使用的内存上限。Memory Limit既没有默认值,也可以不指定。在MEMORY_LIMIT参数没有被配置时,一个资源队列中的一条SQL所允许的内存大小,由statement_mem参数决定:
资源队列中可以并行执行的查询数会受到该队列的可用内存限制。举个例子:对于队列etl,设置STATEMENTS=3, MEMORY_LIMIT=2.1G;那么在没有设置statement_mem的情况下,每个查询默认使用内存700MB。
SQL1进入队列,使用内存700MB,此时队列剩余内存1.4G;
SQL2进入队列,设置statement_mem为1.0GB,此时队列剩余内存为0.4GB;
此时,队列剩余内存无法满足SQL3的内存使用需求(默认700GB),那么虽然队列中并行查询数没有达到队列限制,SQL3依然无法执行,需要排队等待。
PRIORITY:
数据库运行的SQL会按照其所在资源队列的优先权设置来共享可用的CPU资源。当一个来自高优先权队列的语句进入到活动运行语句分组中时,它可以得到可用CPU中较高的份额,同时也会降低具有较低优先权设置队列中已经在运行的语句得到的份额。
查询的相对尺寸或复杂度不影响CPU的分配。如果一个简单的低代价的查询与一个大型的复杂查询同时运行,并且它们的优先权设置相同,它们将被分配同等份额的可用CPU资源。当一个新的查询变成活动时,CPU份额将会被重新计算,但是优先权相等的查询仍将得到等量的CPU。
例如,管理员创建三个资源队列:streaming、etl、prod,并相应地配置为以下优先权:
当数据库中只有etl队列中有查询1和2同时运行时,它们有相等份额的CPU,因为它们的优先权设置相等:
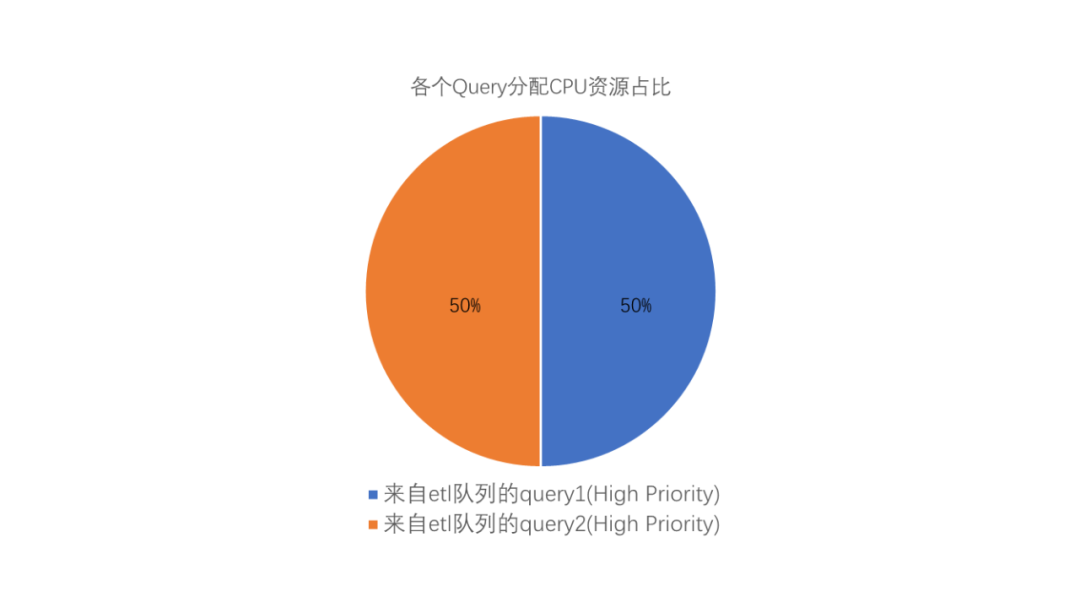
上图中显示的百分数都是近似值。高、低和中优先权队列的CPU使用并不总是准确地用这些比例计算出来。
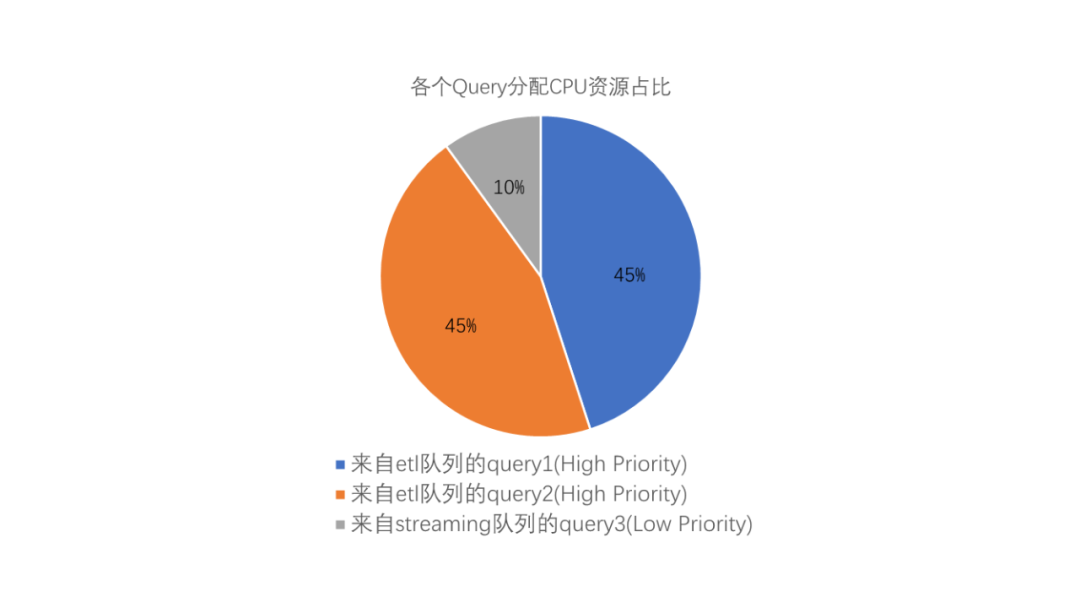
当一个streaming队列中的查询开始运行时,在etl队列中两个查询依然保持相等的CPU份额,而低优先级的query3则会以较低CPU份额运行。
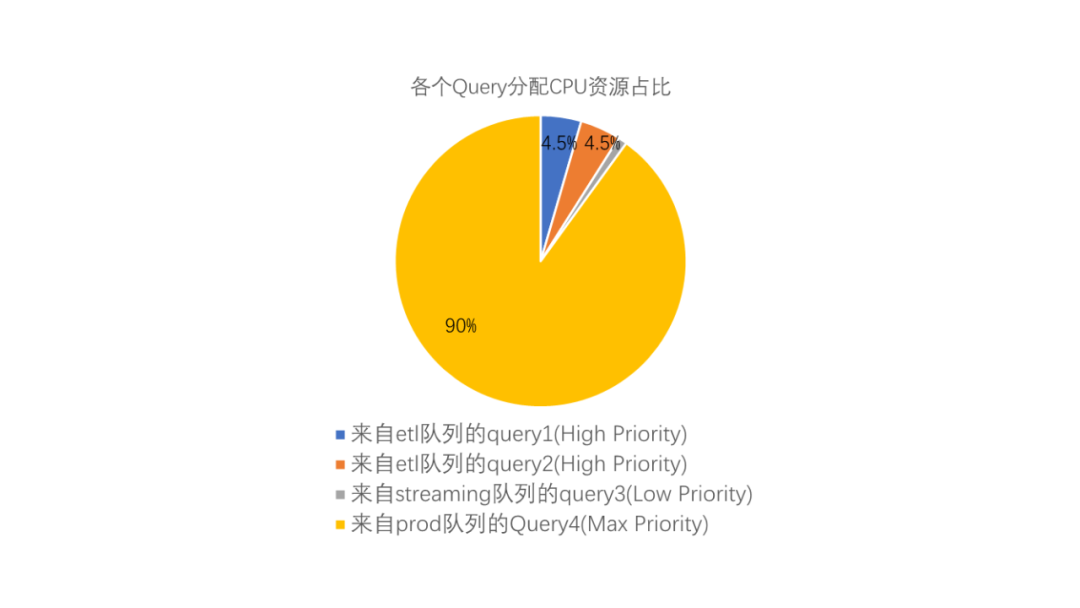
而当最高优先级队列prod中有查询进入队列之后,其CPU使用会被调整以说明其最大优先权设置。它可能是一个非常简单的查询,但直到它完成前,它都将要求最大份额的CPU。而其他查询的优先级则会被调整为较低的CPU份额。
3.1 创建资源队列
ADB PG允许用户使用SQL创建资源队列,并指定各类资源限制。使用CREATE RESOURCE QUEUE命令来创建新的资源队列。
创建带有并发限制的队列
带有ACTIVE_STATEMENTS设置的资源队列会限制指派给该队列的角色所执行的并发查询数量。
CREATE RESOURCE QUEUE etl WITH (ACTIVE_STATEMENTS=3);这意味着对于所有被分配到etl资源队列的角色,在任意给定时刻只能有三个活动查询被运行在这个系统上。如果这个队列已经有三个查询在运行并且一个角色在该队列中提交第四个查询,则第四个查询只有等到一个槽被释放出来后才能运行。
创建带有内存限制的队列
带有MEMORY_LIMIT设置的资源队列控制所有通过该队列提交的查询的总内存。在与ACTIVE_STATEMENTS联合使用时,每个查询被分配的默认内存量为:MEMORY_LIMIT /ACTIVE_STATEMENTS。
例如,要创建一个活动查询限制为10且总内存限制为2000MB的资源队列(每个查询将在执行时被分配200MB的Segment主机内存):
CREATE RESOURCE QUEUE etl WITH (ACTIVE_STATEMENTS=10, MEMORY_LIMIT='2000MB');另外gp_vmem_protect_limit参数会限制一个Segment上分配的内存总大小。该参数的优先级更高,如果这个参数超标,查询可能会被取消。
设置优先级
为了控制一个资源队列对可用CPU资源的消耗,用户可以指派一个合适的优先级。
ALTER RESOURCE QUEUE etl WITH (PRIORITY=LOW);ALTER RESOURCE QUEUE etl WITH (PRIORITY=MAX);3.2 指派角色(用户)到资源队列
一旦创建了一个资源队列,用户必须把角色(用户)指派到它们合适的资源队列。如果没有显式地把角色指派给资源队列,它们将进入默认资源队列pg_default。
使用ALTER ROLE或者CREATE ROLE命令来指派角色到资源队列。例如:
ALTER ROLE name RESOURCE QUEUE queue_name;CREATE ROLE name WITH LOGIN RESOURCE QUEUE queue_name;从资源队列移除角色
所有用户都必须被指派到资源队列。如果没有被显式指派到一个特定队列,用户将会进入到默认的资源队列pg_default。如果用户想要从一个资源队列移除一个角色并且把它们放在默认队列中,可以将该角色的队列指派改成none。例如:
ALTER ROLE role_name RESOURCE QUEUE none;3.3 修改资源队列
在资源队列被创建后,用户可以使用ALTER RESOURCE QUEUE命令更改队列限制,或使用DROP RESOURCE QUEUE命令移除一个资源队列。
修改资源队列配置
ALTER RESOURCE QUEUE命令更改资源队列的限制。要更改一个资源队列的限制,可以为该队列指定想要的新值。例如:
ALTER RESOURCE QUEUE etl WITH (ACTIVE_STATEMENTS=5);ALTER RESOURCE QUEUE etl WITH (PRIORITY=MAX);删除资源队列
DROP RESOURCE QUEUE命令可以删除资源队列。要删除一个资源队列,该队列不能有指派给它的角色,也不能有任何语句在其中等待。
DROP RESOURCE QUEUE etl;4.1 查看队列中的语句和资源队列状态
gp_toolkit.gp_resqueue_status视图允许用户查看一个负载管理资源队列的状态和活动。对于一个特定资源队列,它展示有多少查询在等待运行以及系统中当前有多少查询是活动的。要查看系统中创建的资源队列、它们的限制属性和当前状态:
SELECT * FROM gp_toolkit.gp_resqueue_status;
4.2 查看资源队列统计信息
如果想要持续跟踪资源队列的统计信息和性能,用户可以使用pg_stat_resqueues系统视图来查看在资源队列使用上收集的统计信息。
SELECT * FROM pg_stat_resqueues;4.3 查看指派到资源队列的角色
要查看指派给资源队列的角色,执行下列在pg_roles和
gp_toolkit.gp_resqueue_status系统目录表上的查询:
SELECT rolname, rsqname FROM pg_roles, gp_toolkit.gp_resqueue_status WHERE pg_roles.rolresqueue=gp_toolkit.gp_resqueue_status.queueid;4.4 查看资源队列的等待查询
用户可以看到所有资源队列的所有当前活跃的以及在等待的查询:
SELECT * FROM gp_toolkit.gp_locks_on_resqueue WHERE lorwaiting='true';如果这个查询不返回结果,那就意味着当前没有语句在资源队列中等待。
4.5 查看活动语句的优先权
查看当前正在被执行的语句并且提供优先权、会话ID和其他信息:
SELECT * FROM gp_toolkit.gp_resq_priority_statement;4.6 重置活动语句的优先权
用户可以使用函数gp_adjust_priority(session_id,statement_count,priority)调整当前正在被执行的语句的优先权。使用这个函数,用户可以提升或者降低任意查询的优先权。例如:
SELECT gp_adjust_priority(12, 10000, 'LOW');在这个函数的参数中,session_id代表会话id, statement_count代表要调整的SQL在session中的序号,priority是待调整的优先级。可以通过
gp_resq_priority_statement视图查询现有语句的上述信息。
select * from gp_toolkit.gp_resq_priority_statement;ADB PG数据库是MPP架构,整体分为一个或多个Master,以及多个segment,数据在多个segment之间可以随机、哈希、复制分布。在ADB PG中,Resource Queue的资源限制级别是语句级别,即在整条SQL执行的任何时刻,不管是否处于事务中,均会受到资源队列的限制。
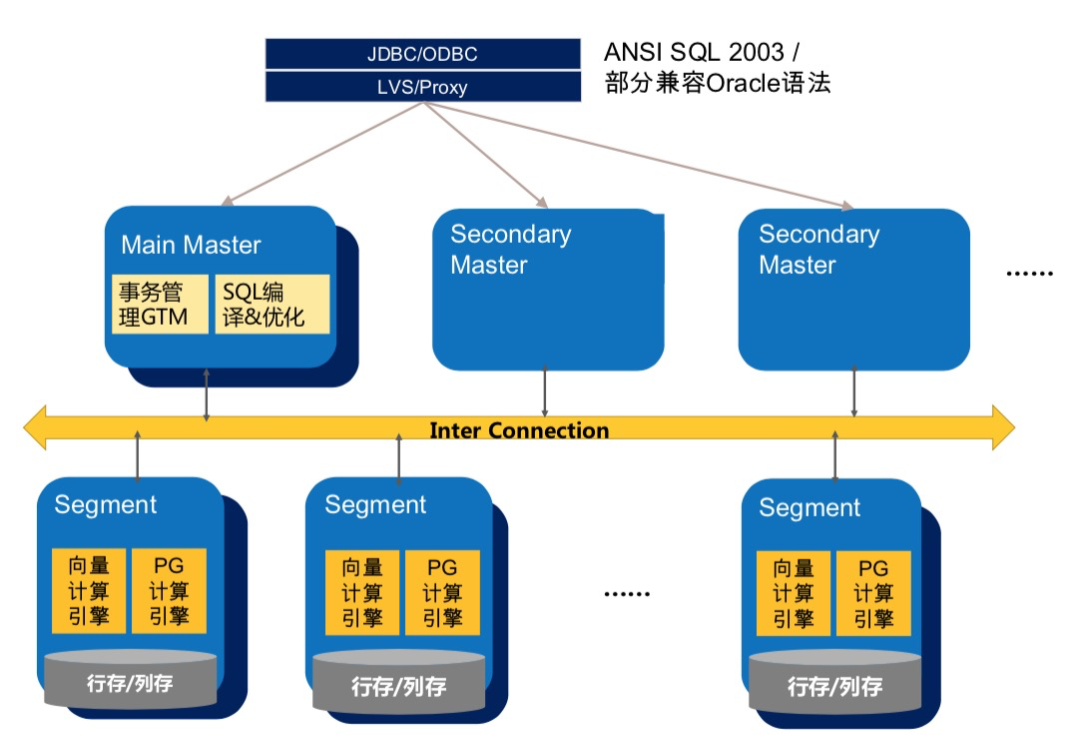
如上文所述,Resource Group支持对并发、CPU和内存等进行限制,本节会详细介绍对这些资源进行限制的实现细节。
5.1 并发限制
ADBPG数据库是多进程模型,分布式数据库的每个节点会启动多个子进程,各个子进程通过共享内存、共享信号量、共享消息队列的方式实现进程间通信。
Resource Queue基于分布式锁实现。在ADBPG中所有的SQL连接首先会到达Master节点,在经过解析、优化,到达执行器层面时,会首先尝试获取ResQueueLock类型的排他锁。
在单个ADB PG节点中,同一时间只能有一个进程获取到ResQueueLock类型的排他锁,而每个进程只会包含单个线程。
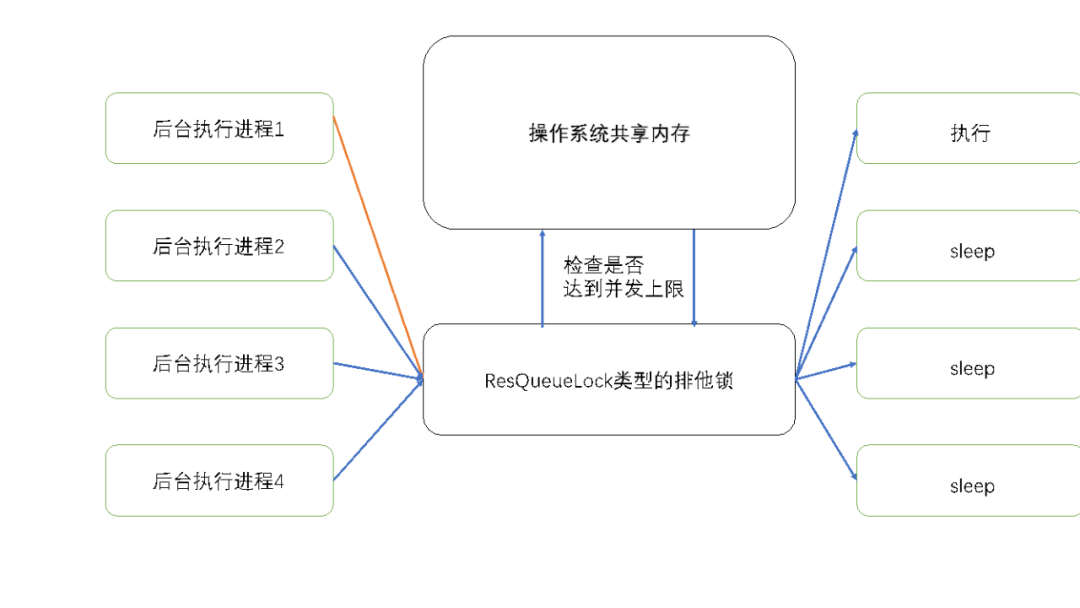
在获得ResQueueLock类型的排他锁之后,执行SQL的后台进程会读取及更新共享内存中的值,特别是队列中并发执行语句的计数值。若资源充足,则会在更新完共享内存中对应资源队列中的资源使用量之后,释放ResQueueLock,开始SQL的实际执行;
若资源不足,比如当前队列中正在运行的SQL数量已经达到了所设定的并发上限值,对应的后台进程则会sleep排队等待其他query执行完毕后释放资源。
5.2 内存限制
对于内存的限制的实现方式与对并发限制的实现方式大体是一致的,只是对于判断资源队列中是否有资源来运行提交的SQL的方式有一些区别。
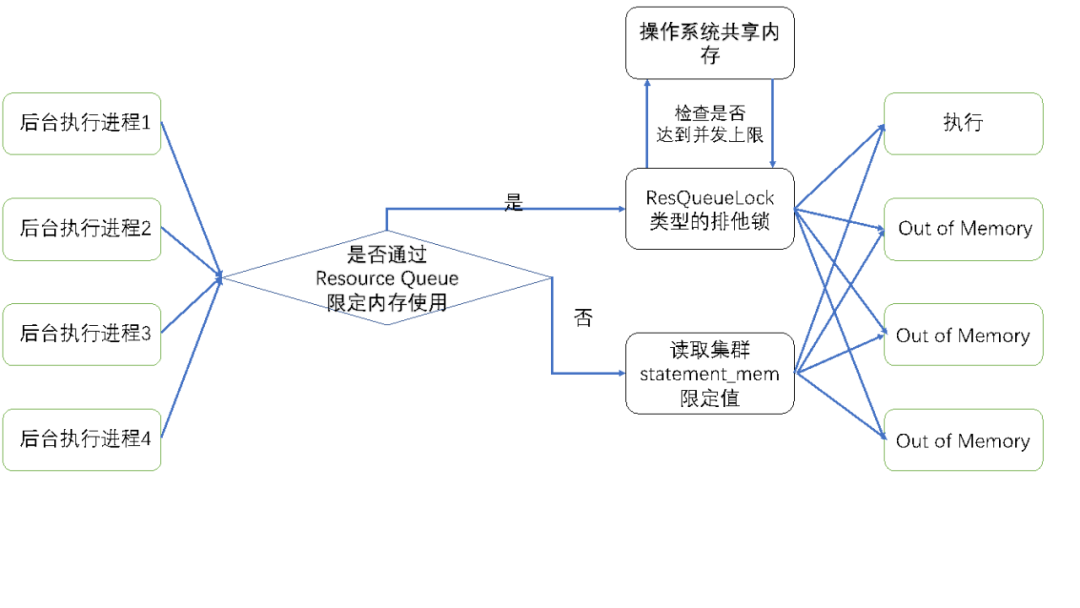
对于某个Resource Queue中的SQL,能够使用的内存上限计算如下:
1)如果没有设定resource queue的memory_limit值,那么直接取数据库的statement_mem值;
2)如果设定了resource queue的memory limit值,则根据所设定的resource queue的memory_limit值,计算资源组能够使用的内存总量;用总量除以resource queue设定的并发数,得到单条SQL所能利用的上限值。再将这个上限值与statement_mem取一个最大值,作为SQL最终使用的内存上限值。
5.3 CPU限制
Resource Queue的CPU限制是一个很有意思的实现。ADB PG专门为Resource Queue CPU限制的功能拉起了一个专门的进程:sweeper进程来监控各个后台进程的CPU使用,以及调节各个后台进程的CPU份额。
这个进程是一个与数据库高度独立的进程,它没有加载一些缓存、资源类的东西,也无法开启事务或者查系统表,它的活动就是不停的读写共享内存,计算各个进程的CPU使用,更改CPU分配份额。各个实际执行SQL的后台进程(backend)会根据所计算的CPU份额去休眠一定的时间,从而调节各个SQL实际的CPU使用率。
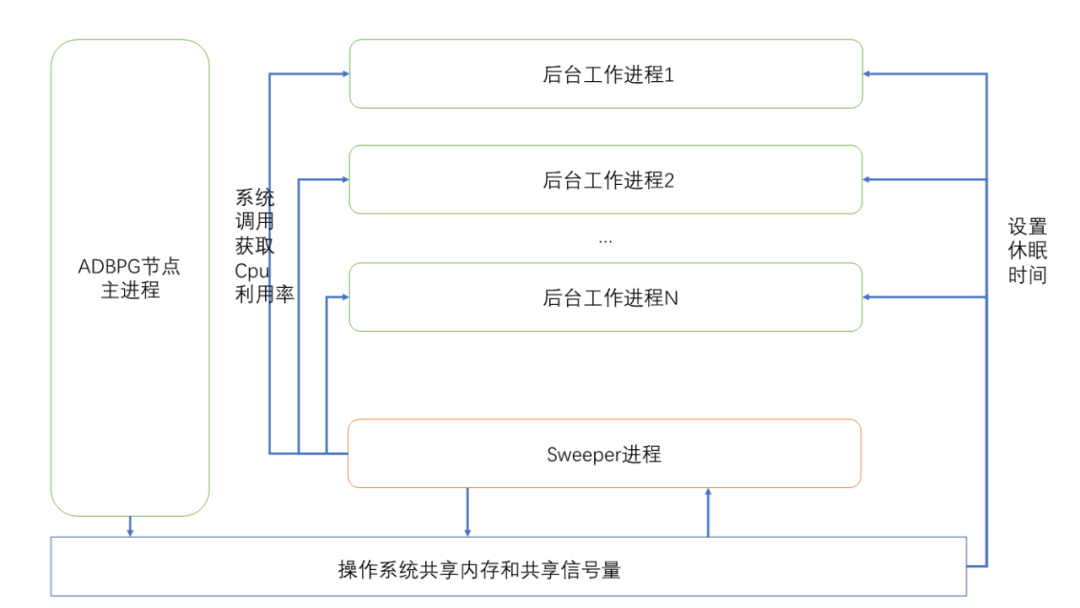
这个进程的主体流程如上,他的流程非常简单,就是不断地sweep和sleep。
各个实际执行SQL的backend进程在启动时,会在共享内存中注册一些状态,并在执行过程中执行系统调用getrusage等,更新CPU使用状态;sweeper进程会根据这些共享内存状态,以及所设定的资源队列CPU利用值,在共享内存中更新对应backend进程的CPU份额(targetCPU)。而在backend运行过程中,则会调用BackoffBackend,根据CPU份额来进行一段时间的休眠,从而调节整体的CPU利用率。
在运行过程中,分布式数据库的每个计算节点都会有一个sweeper进程来调节每个节点的CPU调用,使资源队列的CPU配置全局有效。
资源管理对于数据库集群的多租户管理、资源细粒度分配具有很重要的价值。Resource Queue能够对分布式数据库进行整体的资源管理和控制,在多租户隔离、保障数据库整体平稳运行具有一定的价值。
除了Resource Queue的资源管理方式外,ADB PG还支持 Resource Group 的资源管理方式,能够进行更精细的资源控制。Resource Group现已在专有云环境提供使用,后续会逐步在公有云提供能力。后续我们会介绍Resource Group的基本使用和最佳实践。
本文为阿里云原创内容,未经允许不得转载。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号